目錄
- 1. Scrapy 基礎知識
- 1.1 Scrapy 簡介
- 1.2 Scrapy 安裝和配置
- 1.3 Scrapy Shell 抓取 Web 資源
- 2. 用 Scrapy 撰寫網路爬蟲
- 2.1 創建和使用 Scrapy 工程
- 2.2 Pycharm 中除錯 Scrapy 原始碼
- 2.3 在 Pycharm 中使用擴展工具運行 Scrapy 工具
Scrapy 是一個非常優秀的爬蟲框架,通過
Scrapy 框架,可以非常輕松地實作強大的爬蟲系統,我們只需要將精力放在抓取規則以及如何處理抓取的資料上即可,本文通過實戰來介紹
Scrapy 的入門知識以及一些高級應用,
1. Scrapy 基礎知識
1.1 Scrapy 簡介
Scrapy 是適用于 Python 的一個快速、高層次的螢屏抓取和 web抓取框架,用于抓取web站點并從頁面中提取結構化的資料,Scrapy 用途廣泛,可以用于資料挖掘、監測和自動化測驗,Scrapy 主要是包括如下 6 個部分,
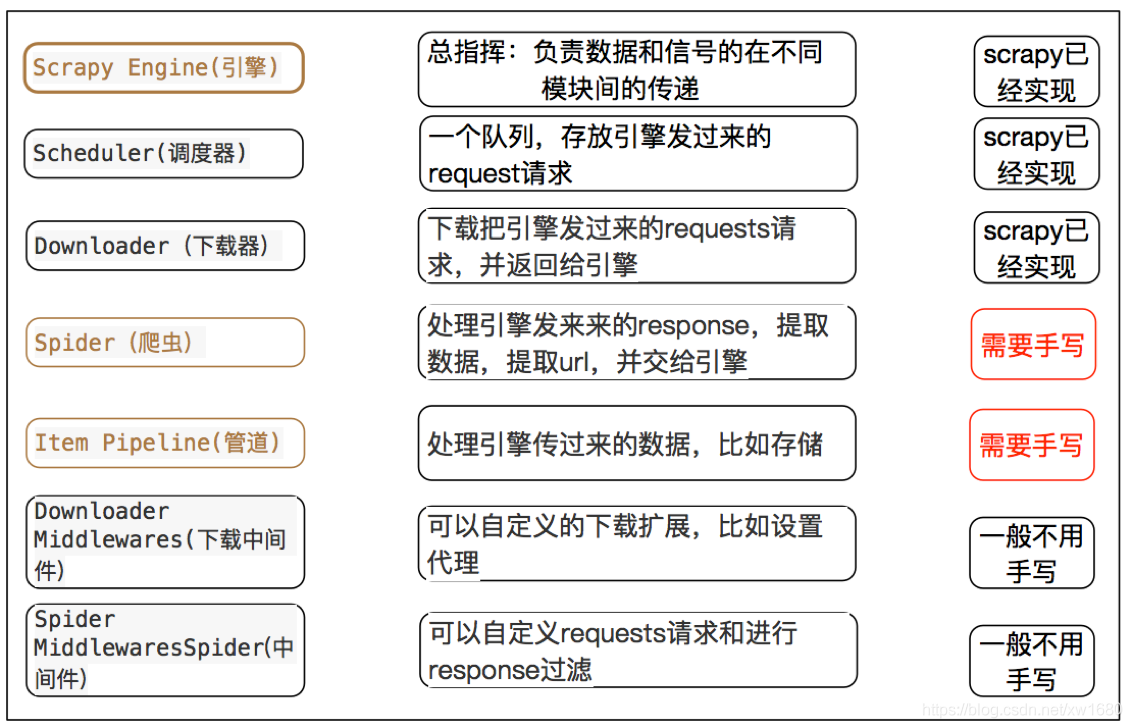
- Scrapy Engine (Scrapy引擎):用來處理整個系統的資料流,觸發各種事件,
- Scheduler (調度器):從
URL佇列中取出一個URL, - Downloader (下載器):從 Internet 上下載 Web 資源,
- Spiders (網路爬蟲):接收下載器下載的原始資料,做進一步的處理,例如,使用
Xpath提取感興趣的資訊, - Item Pipeline (專案管道):接收網路爬蟲傳過來的資料,以便做進一步處理,例如:存入資料庫,存入文本檔案,
- 中間件:整個
Scrapy框架有很多中間件,如下載器中間件、網路爬蟲中間件等,這些中間件相當于過濾器,夾在不同部分之間截獲資料流,并進行特殊的加工處理,
以上各部分的作業流程可以使用下圖所示的流程描述,
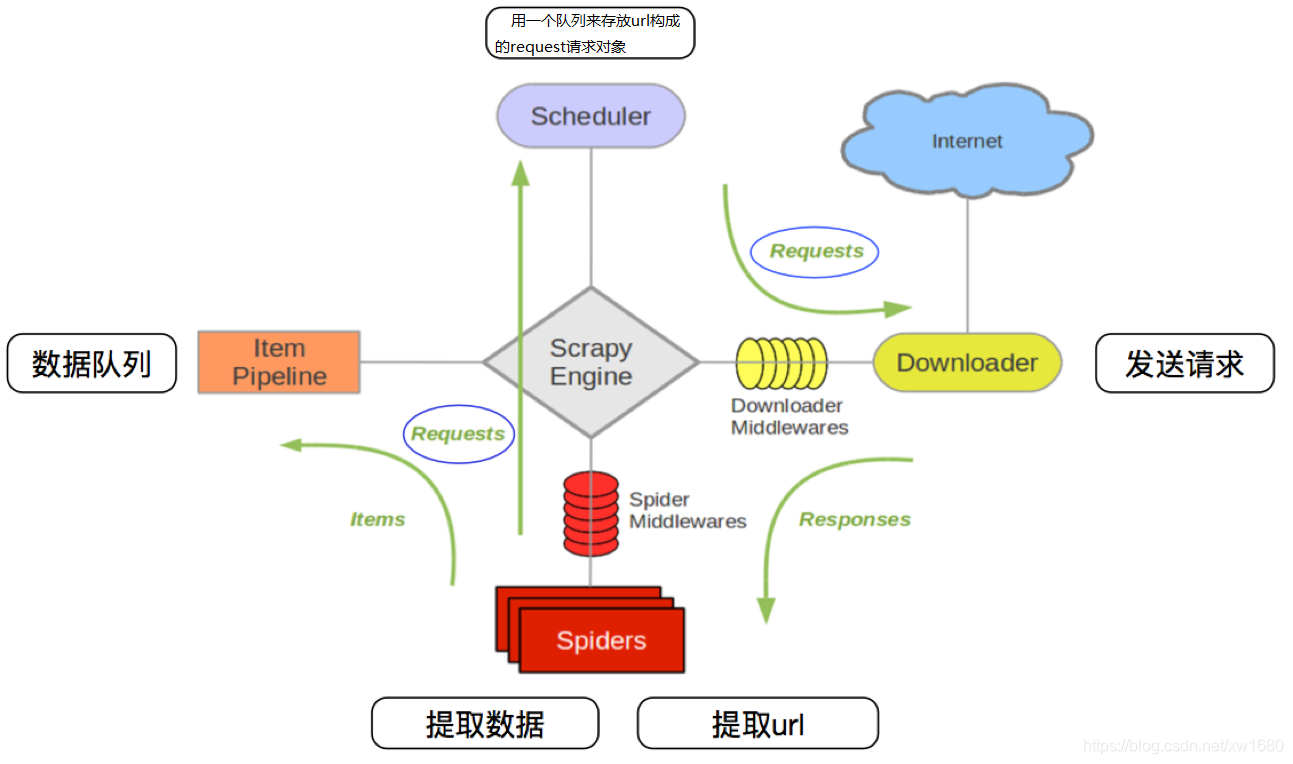
其流程可以描述如下:
- 爬蟲中起始的
URL構造成Requests物件 ? 爬蟲中間件 ? 引擎 ? 調度器 - 調度器把
Requests? 引擎 ? 下載中間件 ? 下載器 - 下載器發送請求,獲取
Responses回應 ? 下載中間件 ? 引擎 ? 爬蟲中間件 ? 爬蟲 - 爬蟲提取
URL地址,組裝成Requests物件 ? 爬蟲中間件 ? 引擎 ? 調度器,重復步驟2 - 爬蟲提取資料 ? 引擎 ? 管道處理和保存資料
注意:
- 圖中中文是為了方便理解后加上去的
- 圖中
綠色線條的表示資料的傳遞 - 注意圖中中間件的位置,決定了其作用
- 注意其中引擎的位置,所有的模塊之前相互獨立,只和引擎進行互動
Scrapy 中每個模塊的具體作用:
1.2 Scrapy 安裝和配置
Scrapy檔案地址
在使用 Scrapy 前需要安裝 Scrapy ,如果讀者使用的是 Anaconda Python 開發環境,可以使用下面的命令安裝 Scrapy,
conda install scrapy
如果讀者使用的是標準的 Python 開發環境,可以使用下面的命令安裝 Scrapy,
# windows 安裝命令如下 加上 --user 防止用戶權限不夠:
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com Scrapy
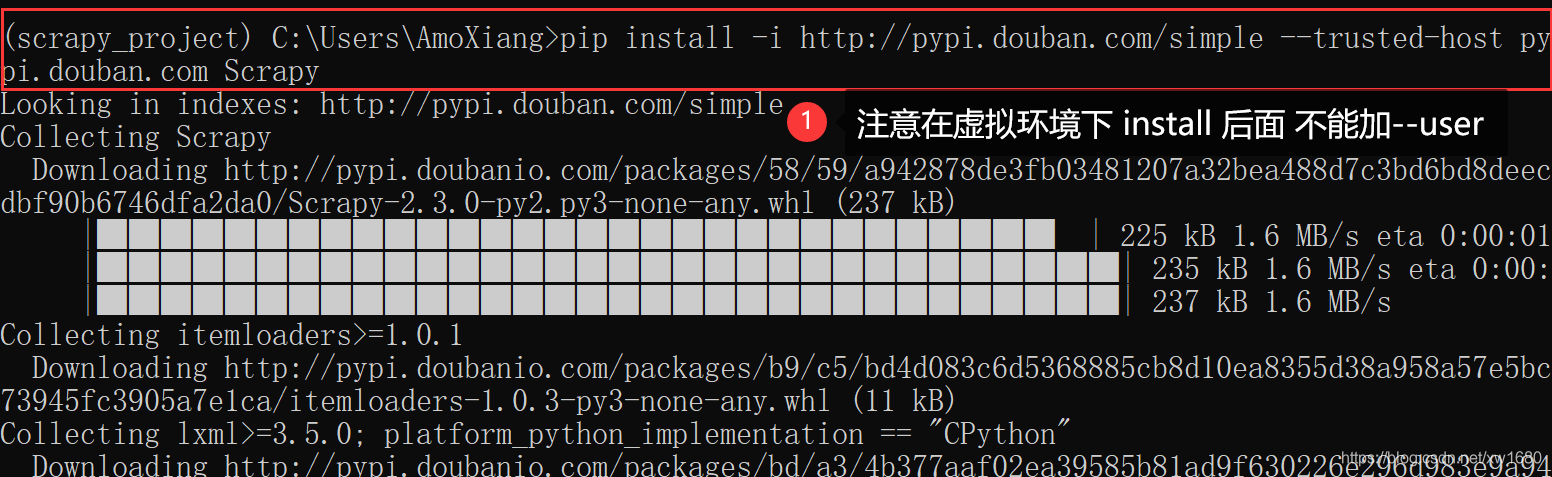
建議在所有平臺上的虛擬環境中安裝 Scrapy,筆者這里以 Windows 為例,如下:
(1) 創建新的虛擬環境

(2) 在虛擬環境中安裝 Scrapy
安裝完后,輸入下面的陳述句,如果未拋出例外,說明 Scrapy 已經安裝成功,
1.3 Scrapy Shell 抓取 Web 資源
Scrapy 提供了一個 Shell 相當于 Python 的 REPL 環境,可以用這個 Scrapy Shell 測驗 Scrapy 代碼,在 Windows 中打開黑視窗,執行 scrapy shell 命令,就會進入 Scrapy Shell,
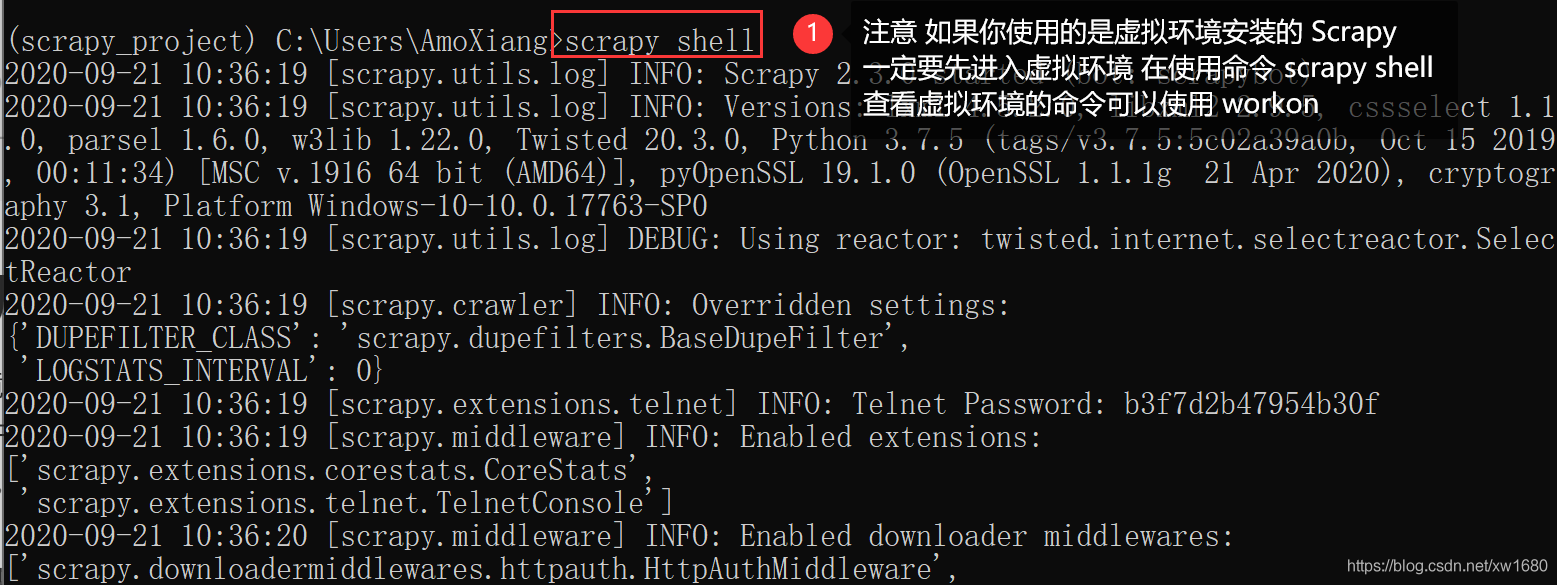
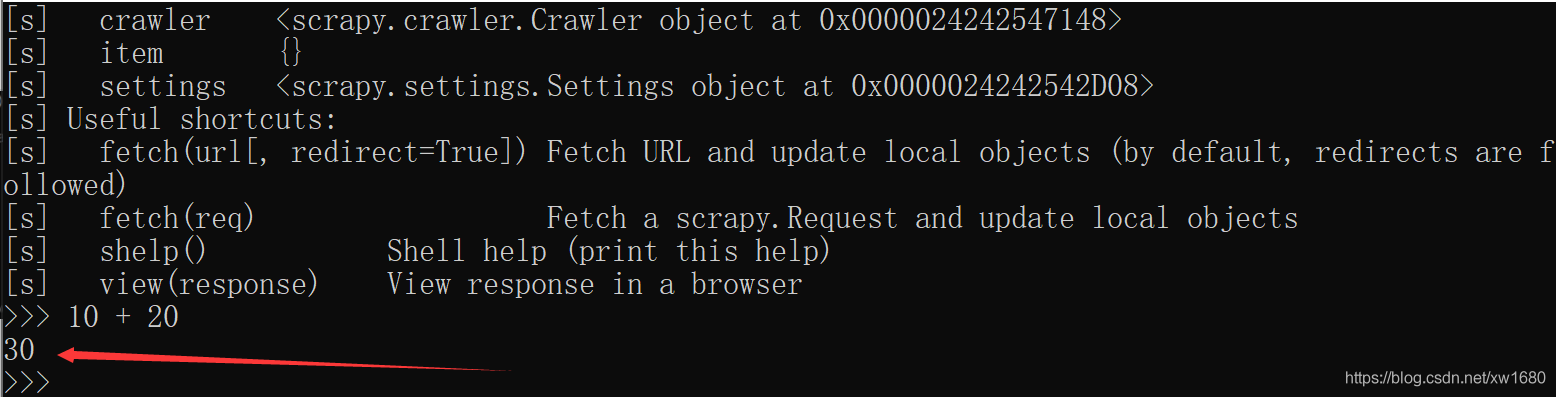
Scrapy Shell 和 Python 的 REPL 環境差不多,也可以執行任何的 Python 代碼,只是又多了對 Scrapy 的支持,例如,在 Scrapy Shell 中輸入 10 + 20,然后回車,會輸出 30,如下圖所示:
Scrapy 主要是使用 Xpath 過濾 HTML 頁面的內容,那么什么是 XPath 呢? 也就是類似于路徑的過濾 HTML 代碼的一種技術,關于 XPath 的內容后面再詳細討論,這里不需要了解 XPath 的細節,因為 Chrome 可以根據 HTML 代碼的某個節點自動生成 Xpath ,
現在先體驗什么叫XPath,啟動 Chrome 瀏覽器,進入 淘寶首頁 然后在頁面右鍵選單中單擊 檢查 命令,在彈出的除錯視窗中選擇第一個 Elements 標簽頁,最后單擊 Elements 左側黑色箭頭的按鈕,將滑鼠放到淘寶首頁的導航條 聚劃算 上,如下圖所示,

這時,Elements 標簽頁中的 HTML 代碼會自動定位到包含 聚劃算 的標簽上,然后在右鍵選單中單擊如下圖所示的 Copy ? Copy Xpath命令,就會復制當前標簽的 Xpath,
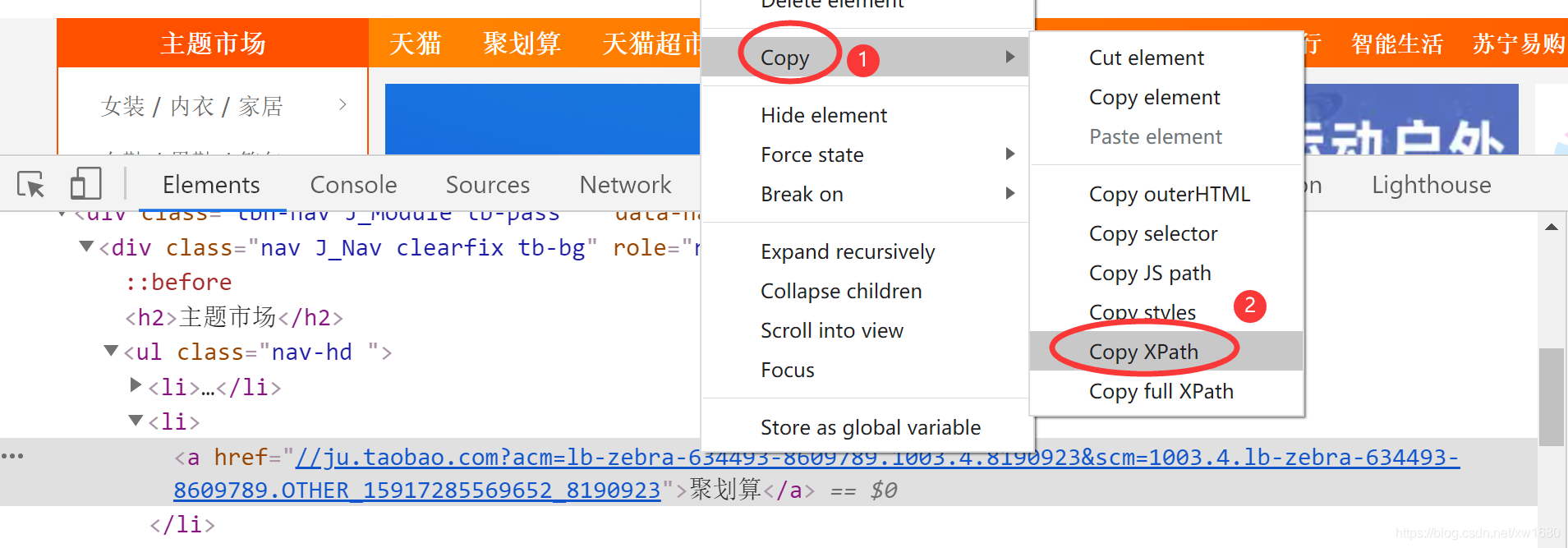
很明顯,包含 聚劃算 文本的是一個 a 標簽,復制的 a 標簽的 Xpath 如下:
/html/body/div[3]/div/ul[1]/li[2]/a
根據這個 XPath 代碼就可以基本猜出 XPath 到底是怎么回事,XPath 通過層級的關系,最終指定了 a 標簽,其中 li[....] 這樣的標簽表示父標簽不止有一個 li 標簽,[...] 里面是索引,從 1 開始,
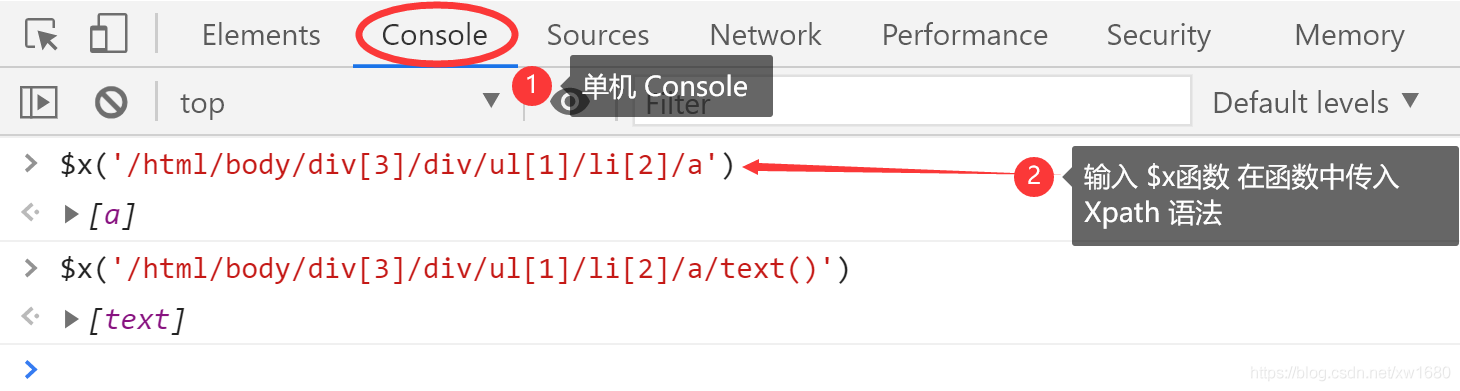
現在可以在 Chrome上測驗一下這個 XPath,單擊 Console 標簽頁,在 Console 中輸人如下的代碼會過濾出包含 聚劃算 的 a 標簽,
$x('/html/body/div[3]/div/ul[1]/li[2]/a')
如果要過濾出 a 標簽里包含的 聚劃算 文本,需要使用 XPath 的 text 函式,
$x('/html/body/div[3]/div/ul[1]/li[2]/a/text()')
下圖是在 Console 中執行的結果,這里就不展開了,因為Chrome 會列出很多輔助資訊,這些資訊大多用處不大,
為了在 Scrapy Shell 中測驗,需要使用下面的命令重新啟動 Scrapy Shell,
scrapy shell https://www.taobao.com
在 Scrapy Shell 中要使用 response.xpath 方法測驗 Xpath ,
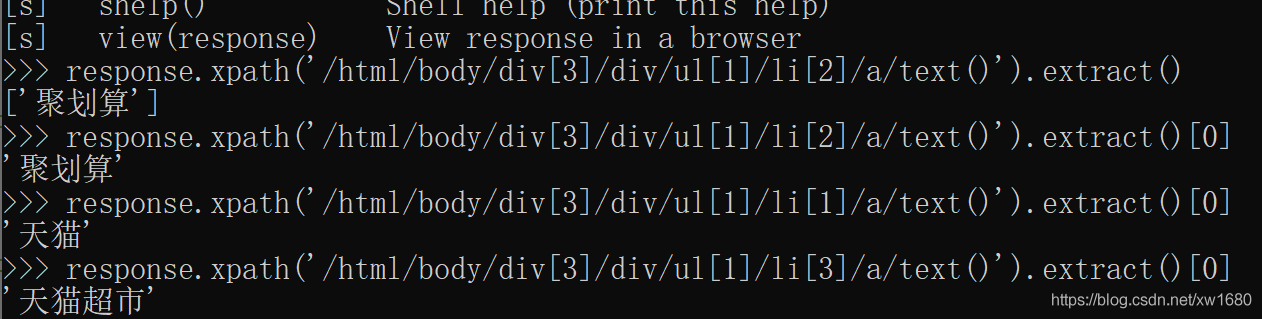
response.xpath('/html/body/div[3]/div/ul[1]/li[2]/a/text()').extract()
上面的代碼輸出的是一個串列,如果要直接回傳 聚劃算 ,需要使用下面的代碼:
response.xpath('/html/body/div[3]/div/ul[1]/li[2]/a/text()').extract()[0]
從包含 聚劃算 的 a 標簽周圍的代碼可以看出,li[1] 表示 天貓,li[3] 表示 天貓超市,所以使用下面兩行代碼,可以分別得到 天貓 和 天貓超市,
# 輸出 "天貓"
response.xpath('/html/body/div[3]/div/ul[1]/li[1]/a/text()').extract()[0]
# 輸出 "天貓超市"
response.xpath('/html/body/div[3]/div/ul[1]/li[3]/a/text()').extract()[0]
在 Scrapy Shell 中輸入上面 4 條陳述句的輸出結果 如下圖所示:
2. 用 Scrapy 撰寫網路爬蟲
2.1 創建和使用 Scrapy 工程
Scrapy 框架提供了一個 scrapy 命令用來建立 Scrapy 工程,可以使用下面的命令建立一個名為 myscrapy 的 Scrapy 工程,
scrapy startproject myscrapy
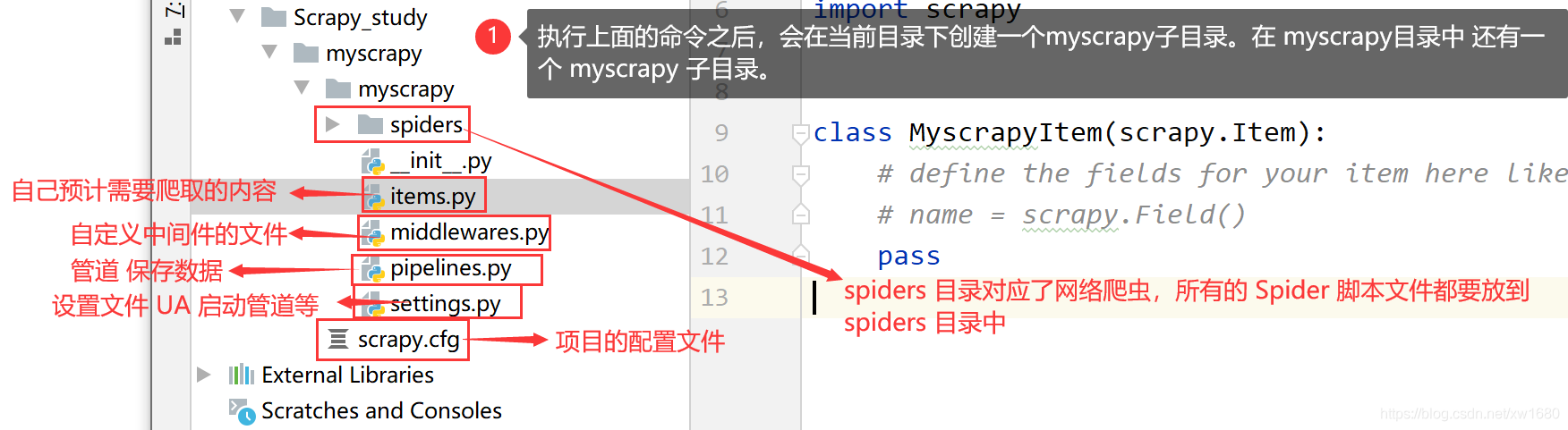
通過命令創建出爬蟲檔案,爬蟲檔案為主要的代碼作業檔案,通常一個網站的爬取動作都會在爬蟲檔案中進行撰寫,命令如下:
cd myscrapy
scrapy genspider first_spider www.jd.com

生成的目錄和檔案結果如下:
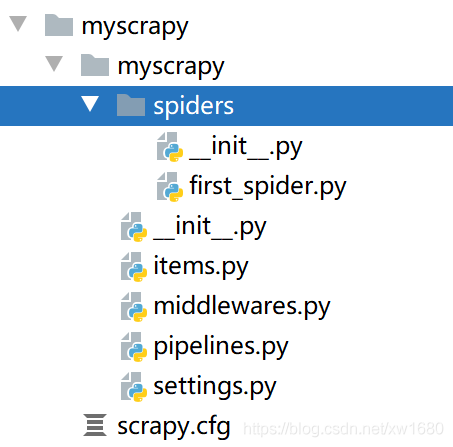
在 spiders 目錄中建立了一個 first_spider.py 腳本檔案,這是一個 Spider 程式,在該程式中會指定要抓取的 Web 資源的 URL,示例代碼如下:
import scrapy
class FirstSpiderSpider(scrapy.Spider):
name = 'first_spider' # Spider的名稱 需要該名稱啟動Scrapy
allowed_domains = ['www.jd.com']
start_urls = ['http://www.jd.com/'] # 指定要抓取的Web資源的 URL
# 每抓取一個URL對應的 Web資源,就會呼叫該方法,通過response引數可以執行 Xpath過濾標簽
def parse(self, response):
# 輸出日志資訊
self.log('hello world')
現在從終端進到最上層的 myscrapy 目錄,然后執行下面的命令運行 Scrapy,
scrapy crawl first_spider
執行的結果如下圖所示:
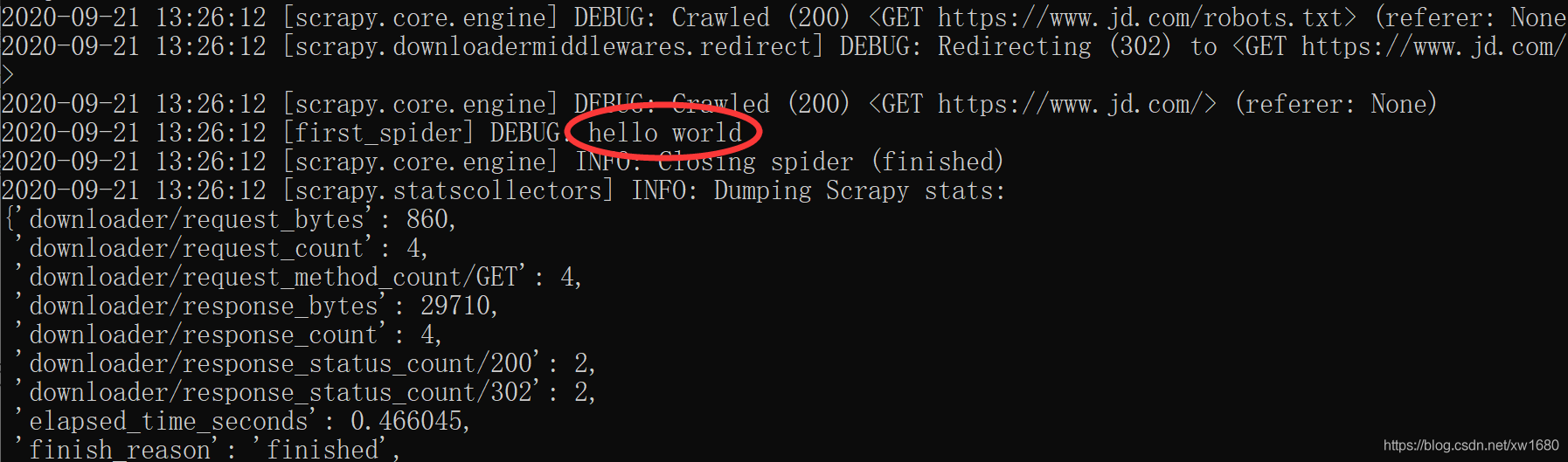
運行 Scrapy 后的輸出結果中的 Debug 訊息輸出了 hello world,這就表明了 parse 方法運行了,從而說明 URL 指定的 Web 資源獲取成功了,
2.2 Pycharm 中除錯 Scrapy 原始碼
為了直接能在 Python 工程中運行網路爬蟲及除錯,需要在 myscrapy 根目錄中建立一個 main.py(檔案名可以任意起) 檔案,然后輸入下面的代碼,
from scrapy.cmdline import execute
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# 如果要運行其他的網路爬蟲,只需修改上面代碼中字串里面的命令即可
execute(["scrapy", "crawl", "first_spider"])
現在執行 main.py 腳本檔案,會在 PyCharm 中的 Run 輸入下圖所示的資訊,從輸出的日志資訊中同樣可以看到 hello world,
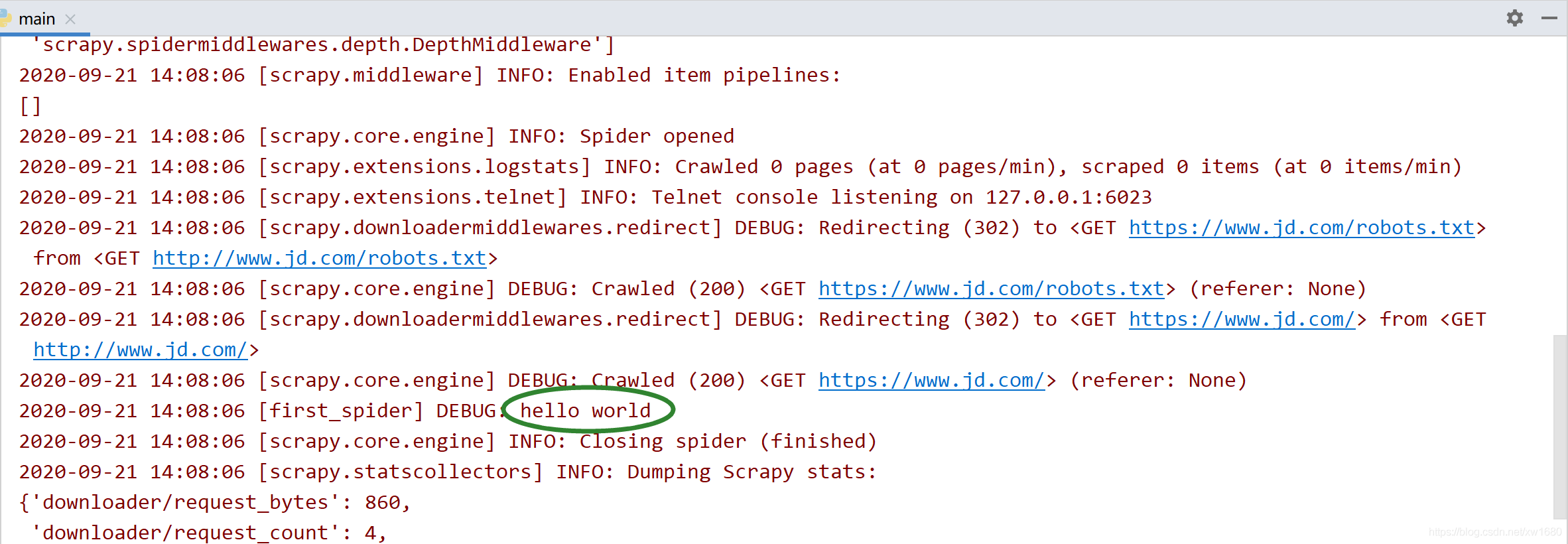
2.3 在 Pycharm 中使用擴展工具運行 Scrapy 工具
在 2.2 中撰寫了一個 main.py 檔案用于運行 Scrapy 程式,其實本質上也是執行 scrapy 命令來運行 Scrapy 程式,不過每創建一個 Scrapy 工程,都要撰寫一個 main.py 檔案放到 Pycharm 工程中用于運行 Scrapy 程式顯得很麻煩,為了在 Pycharm 中更方便地運行 Scrapy 程式,可以使用 Pycharm 擴展工具通過 scrapy 命令運行 Scrapy 程式,
PyCharm 擴展工具允許在 Pycharm 中通過單擊命令執行外部命令,首先單擊 Pycharm 的 File ? Settings 命令打開 Settings 對話框,
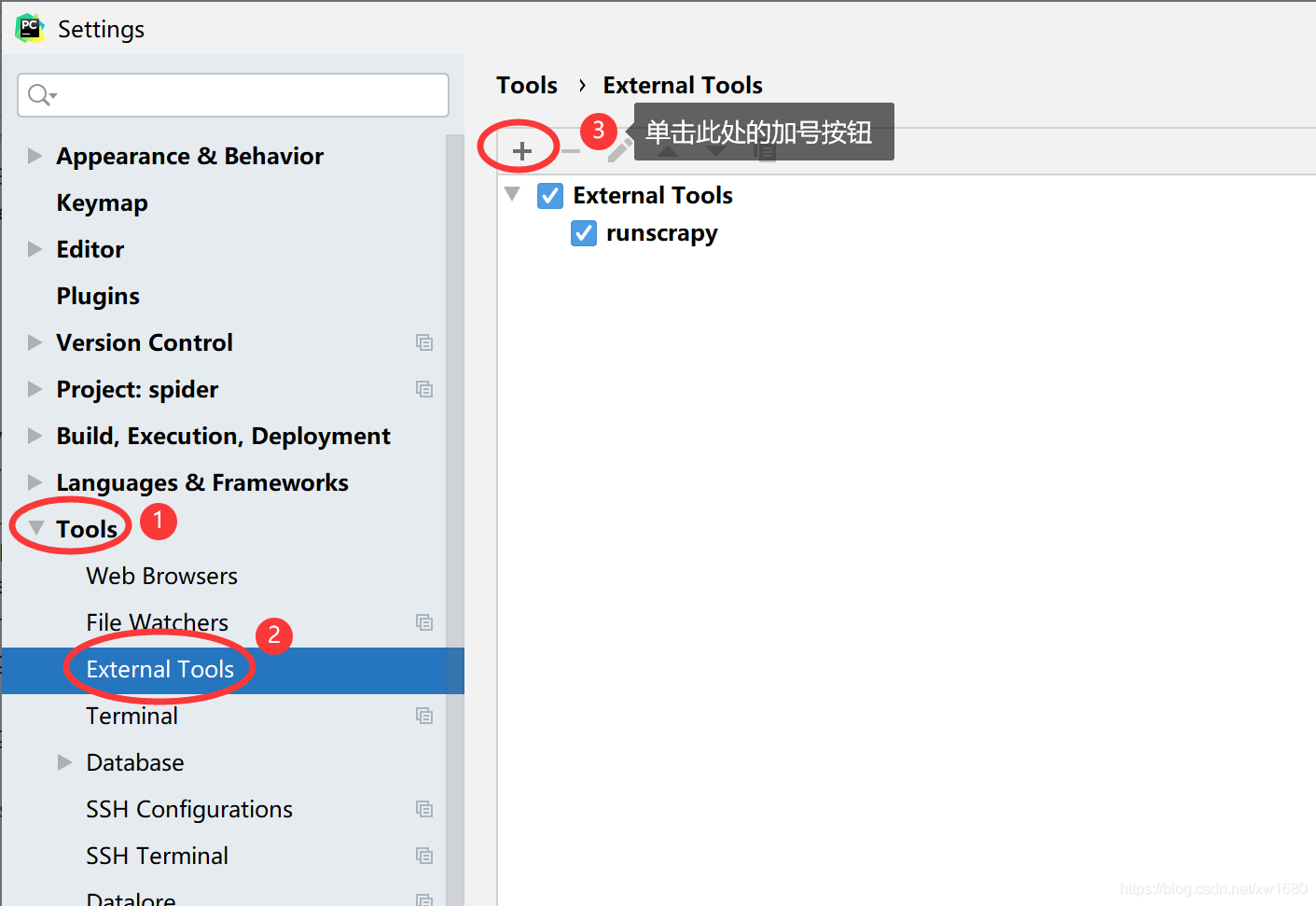
在左側單擊 Tools ? External Tools 節點,會在右側顯示擴展工具串列,如下圖所示:
單擊之后會彈出下圖所示的 Create Tool 對話框,
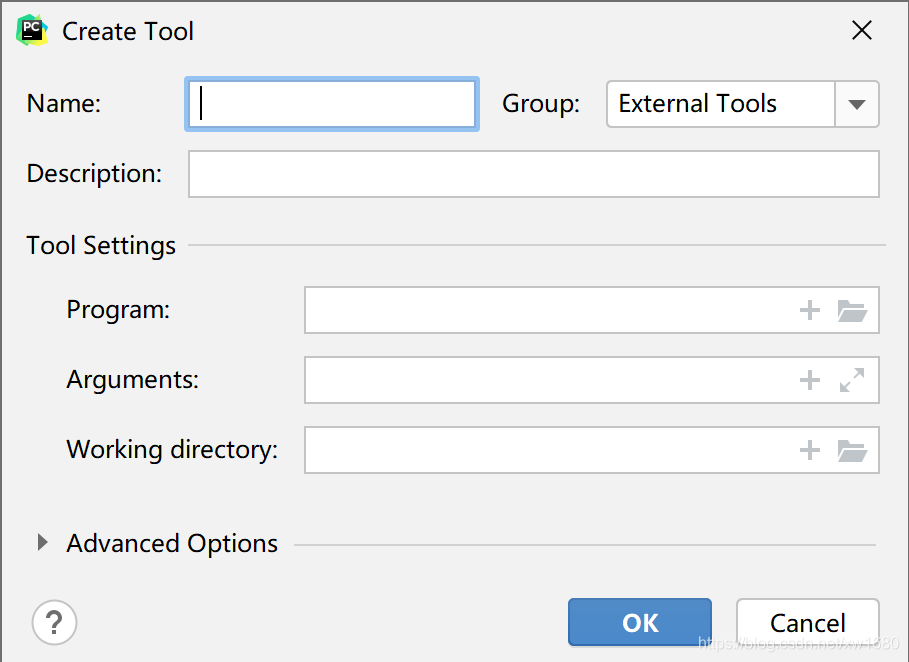
在 Create Tool 對話框中通常需要填寫如下的內容:
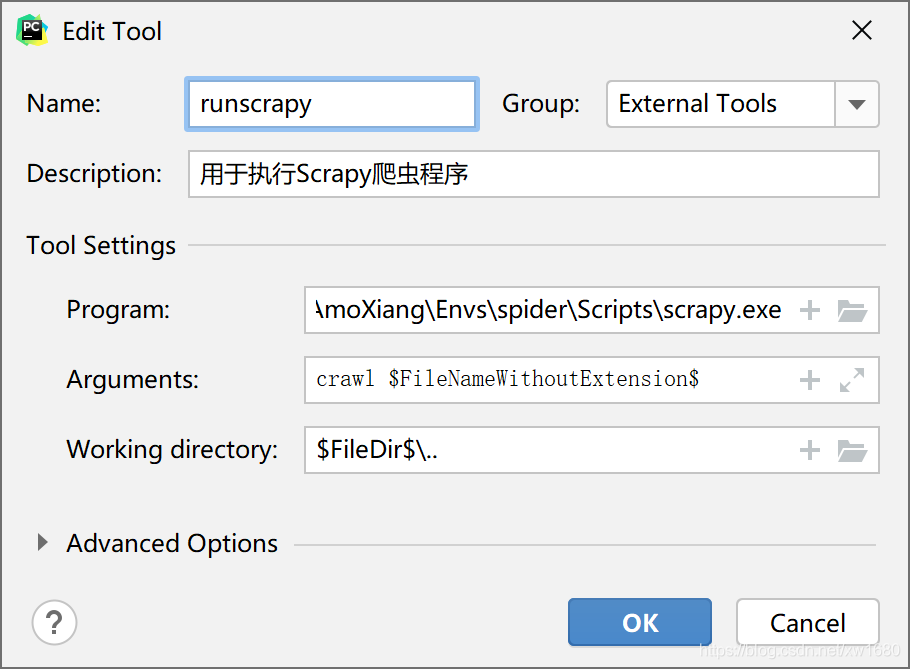
Name:擴展工具的名稱,本例是runscrapy,也可以是任何其他的名字,Description:擴展工具的描述,可以任意填寫,相當于程式的注釋,Program:要執行的程式,本例是C:\Users\AmoXiang\Envs\spider\Scripts\scrapy.exe,指向scrapy命令的絕對路徑,讀者應該將其改成自己機器上的scrapy檔案的路徑Arguments:傳遞給要執行程式的命令列引數,本例是crawl $FileNameWithoutExtension$,其中$FileNameWithoutExtension$是PyCharm中的環境變數,表示當前選中的檔案名(不包含擴展名),如當前檔案名為first_spider.py,選中該檔案后,$FileNameWithoutExtension$的值就是first_spider,Working directory: 作業目錄,本例為$FileDir$/../..,其中$FileDir$表示當前選中檔案所在的目錄,由于Scrapy工程中所有的爬蟲代碼都在spiders目錄中,所以需要選中spiders目錄中的爬蟲腳本檔案(.py檔案),才能使用擴展工具運行爬蟲,對于用scrapy生成的Scrapy工程來說,spiders目
錄位于最內層,所以通常設定作業目錄向上反兩層,所以Working directory的值也可以是$FileDir$/..或$FileDir$,
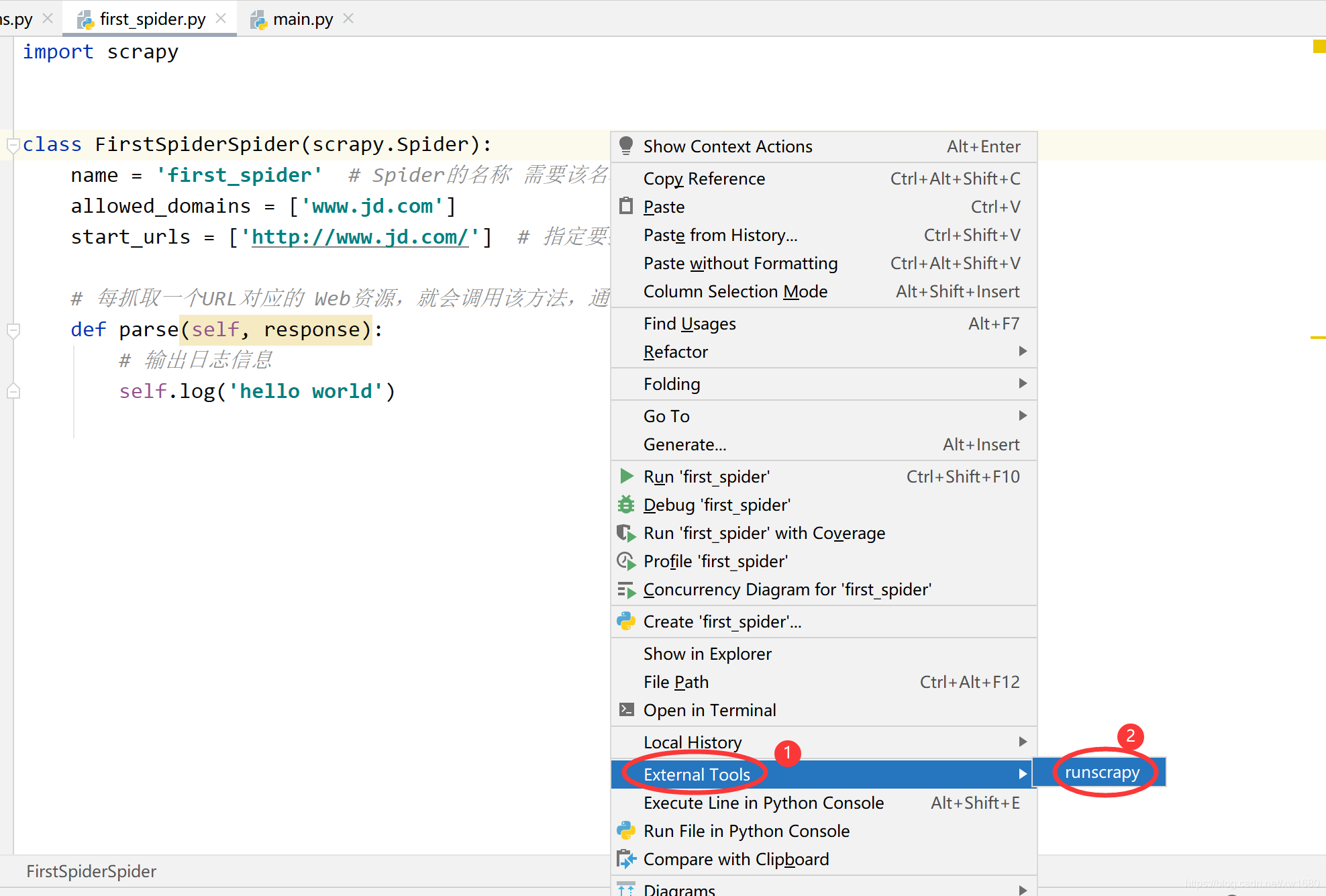
添加完擴展工具后,選擇 spiders 目錄中的一個爬蟲檔案,如 first_spider.py ,然后在右鍵選單中單擊 External Tools ? runscrapy 命令運行 first_spider.py,會在控制臺輸出和上面相同的資訊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/118058.html
標籤:其他