源資料:
"1";"00360C3360EEA3EF8648017CE3488F6A";"2018-12-27 10:45:02";"118.8207540";"32.3732720";"161389467";"27"
"1";"00360C3360EEA3EF8648017CE3488F6A";"2018-12-27 10:45:53";"118.8194490";"32.3605400";"84343044";"27"
"1";"00360C3360EEA3EF8648017CE3488F6A";"2018-12-27 10:46:24";"118.8196860";"32.3586430";"84343046";"27"
"1";"00360C3360EEA3EF8648017CE3488F6A";"2018-12-27 10:48:57";"118.8257510";"32.3325110";"9866397";"27"
提取代碼:
import pandas as pd
table = pd.read_csv('userdata_31_clean.csv',sep = ',',encoding = 'utf-8')
len=table.shape[0] #第二維長度
ind=pd.Series(list(range(len))) #創建一個一維串列陣列
data=https://bbs.csdn.net/topics/pd.DataFrame(index=(range(len)),columns=('id','time','jd','wd')) #data中加入一行資料
j=-1
for i in table.iloc[:,0]: #使用iloc方法提取table讀到的資料中的第0列并用i遍歷
a=i.split(';') #列用“;”對i中資料進行分割
c=[a[0],a[2],a[3],a[4]] #創建一個陣列由。。組成
data.values[j]=c #以行添加
j=j+1
print(data.head()) #列印data的頭
#data['id']=data['id'].astype('str')
ind=data['id'].drop_duplicates() #對ID去重
for i in ind:
data1=data.loc[data['id']==i,:] #提取data["id"]=i的行
name='userdata_'+i+'.csv' #建立i變化的檔案
data1.to_csv(name,index=False,encoding="gbk") #存盤data1于name檔案,非布爾型別
提取的結果:
id,time,jd,wd
1,"""2018-12-27 10:46:24""","""118.8196860""","""32.3586430"""
1,"""2018-12-27 10:48:57""","""118.8257510""","""32.3325110"""
1,"""2018-12-27 10:49:02""","""118.8254230""","""32.3306620"""
1,"""2018-12-27 10:49:07""","""118.8275570""","""32.3325600"""
1,"""2018-12-27 10:54:40""","""118.7770990""","""32.2727000"""
怎樣洗掉資料提取后多余的""""""或如何修改代碼使得提取后的資料中不帶""""""??
uj5u.com熱心網友回復:
請看代碼,加一個lambda 運算式或者一個函式,在讀csv 檔案時,替換"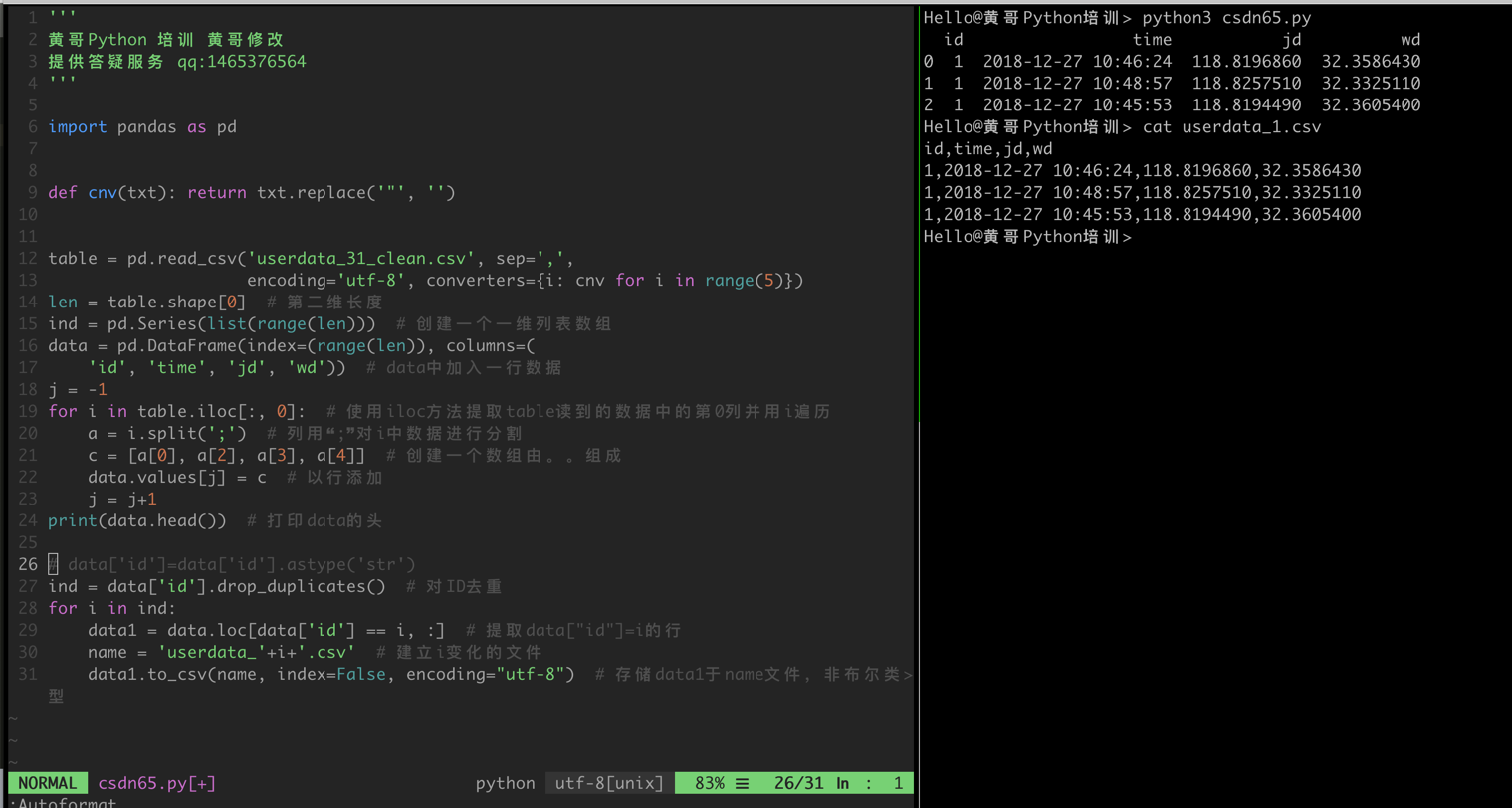
uj5u.com熱心網友回復:
直接替換掉,或者eval,也可以正側uj5u.com熱心網友回復:
很感謝各位前輩的指導,問題已經解決!轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/120446.html