目錄
- 時間復雜度
- 常用資料結構操作與演算法的復雜度
- 輸入規模較小時的情況
- 參考
博客:blog.shinelee.me | 博客園 | CSDN
時間復雜度
如何評估一個演算法的計算時間?
一個演算法的實際運行時間很難評估,當時的輸入、CPU主頻、記憶體、資料傳輸速度、是否有其他程式在搶占資源等等,這些因素都會影響演算法的實際運行時間,為了公平地對比不同演算法的效率,需要脫離開這些物理條件,抽象出一個數學描述,在所有這些因素中,問題的規模往往是決定演算法時間的最主要因素,因此,定義演算法的時間復雜度\(T(n)\),用來描述演算法的執行時間隨著輸入規模的增長將如何變化,增長速度是怎樣的,
在輸入規模較小時,運行時間本來就少,不同演算法的差異不大,所以,時間復雜度通常關注的是輸入規模\(n\)較大時運行時間的變化趨勢,稱之為漸進復雜度,采用大O記號,表示漸進上界,對于任意的\(n >> 2\),若有常數\(c\)和函式\(f(n)\)滿足
\[T(n) \leq c \cdot f(n) \]則記作
\[T(n) = O(f(n)) \]可以簡單地認為,\(O(f(n))\)表示運行時間與\(f(n)\)成正比,比如\(O(n^2)\)表示運行時間與輸入規模的平方成正比,這樣講雖然并不嚴謹,但一般情況下無傷大雅,
在\(n\)很大時,常數\(c\)變得無關緊要,不同演算法間的比較主要關注\(f(n)\)部分的大小,比如,在\(n >> 100\)時,\(n^2\)要比\(100n\)大得多,因此重點關注\(n^2\)和\(n\)增長速度的差異即可,
不同時間復雜度的增長速度對比如下,圖片來自Big-O Cheat Sheet Poster,
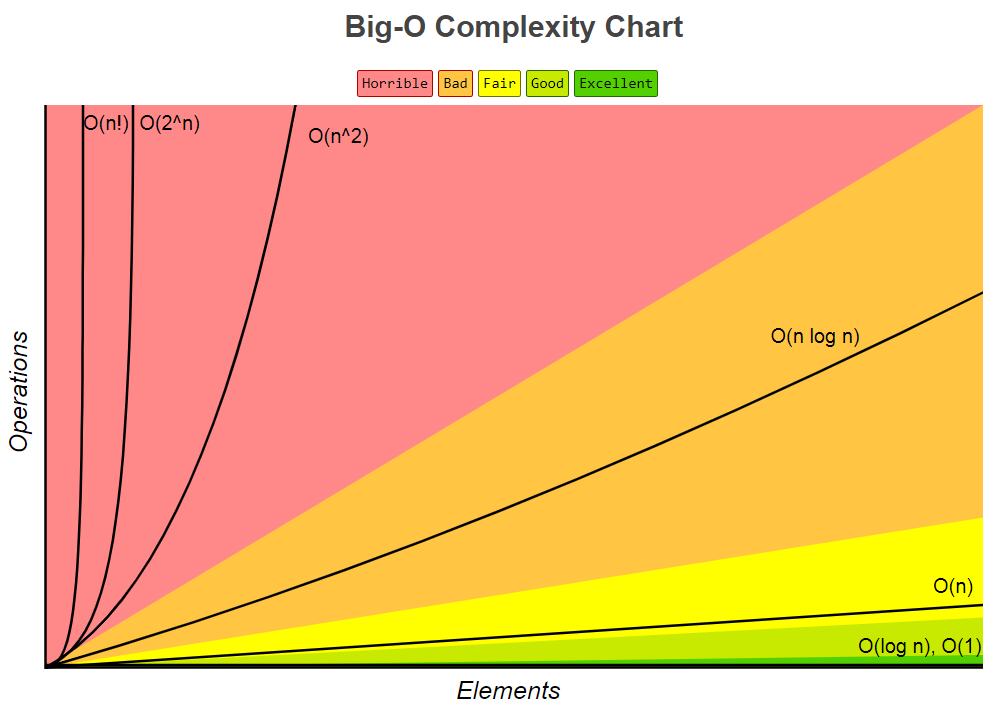
除了大\(O\)記號,還有大\(\Omega\)記號和\(\Theta\)記號,分別表示下界和確界,
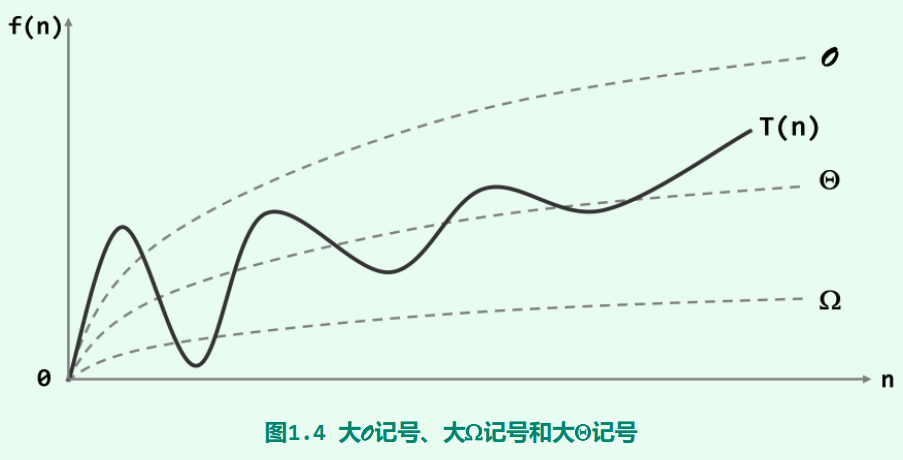
\[\Omega(f(n)) : \ c\cdot f(n) \leq T(n) \\\Theta(f(n)) : \ c_1 \cdot f(n) \leq T(n) \leq c_2 \cdot f(n) \]他們的關系如下圖所示,圖片截自鄧俊輝-資料結構C++描述第三版
常用資料結構操作與演算法的復雜度
下面匯總摘錄了常用資料結構操作和排序演算法的復雜度,來源見參考,其中包含最壞時間復雜度、平均時間復雜度以及空間復雜度等,對于排序演算法還含有最好時間復雜度,
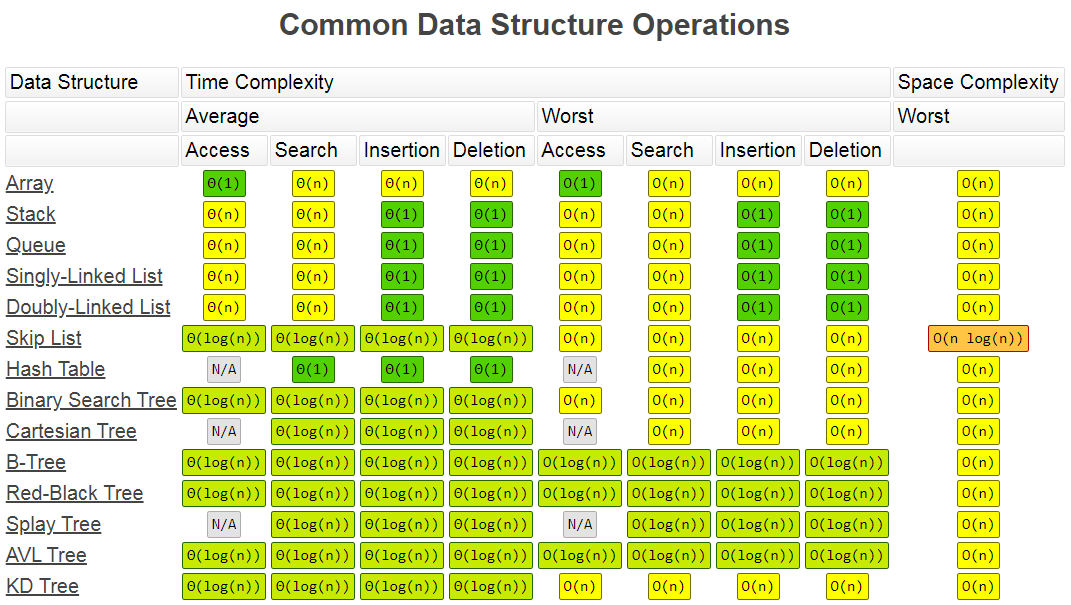
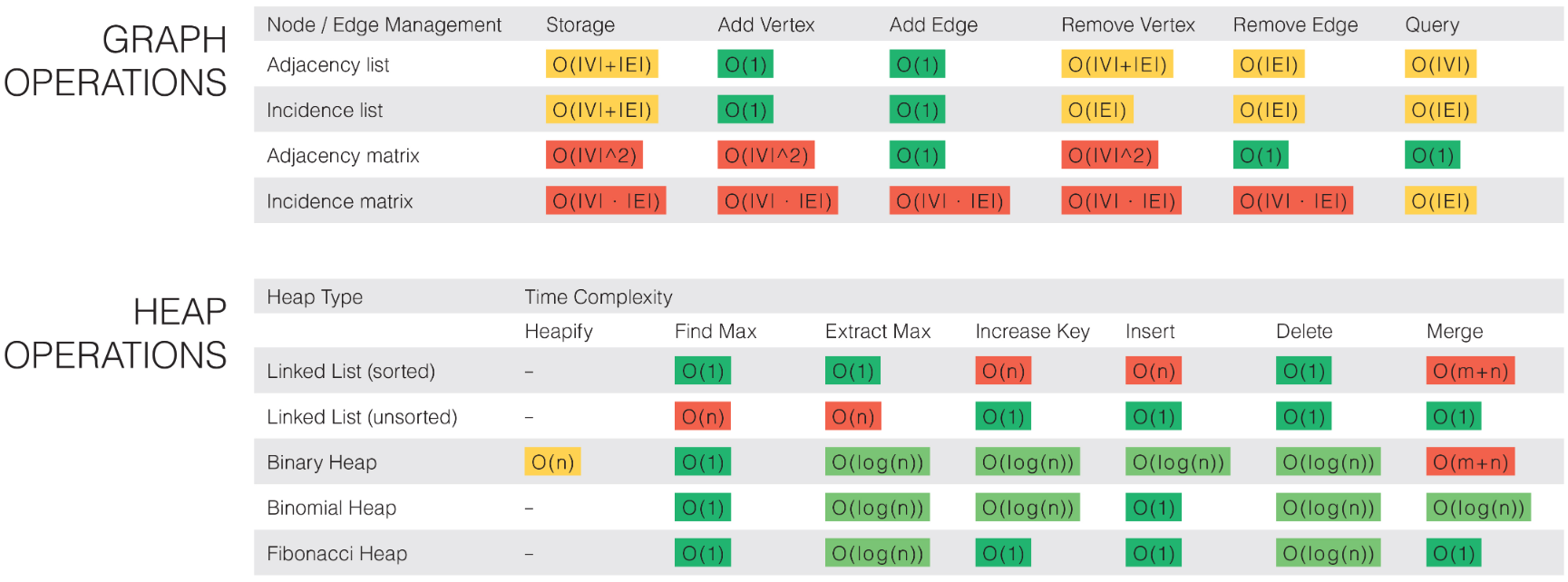
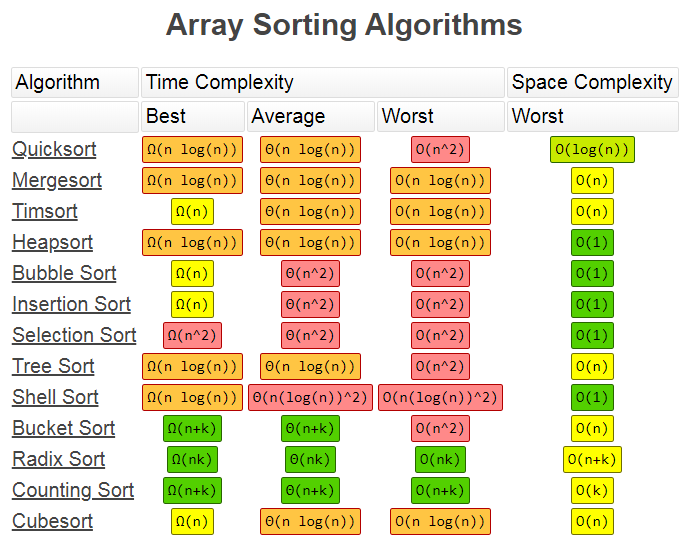
附帶上鏈接:
Array Stack Queue Singly-Linked List Doubly-Linked List Skip List Hash Table Binary Search Tree Cartesian Tree B-Tree Red-Black Tree Splay Tree AVL Tree KD Tree
Quicksort Mergesort Timsort Heapsort Bubble Sort Insertion Sort Selection Sort Tree Sort Shell Sort Bucket Sort Radix Sort Counting Sort Cubesort
以及 Data Structures in geeksforgeeks,
輸入規模較小時的情況
漸進復雜度分析的是輸入規模較大時的情況,輸入規模較小時呢?
在輸入規模較小時,就不能輕易地忽略掉常數\(c\)的作用,如下圖所示,圖片來自Growth Rates Review,復雜度增長快的在輸入規模較小時可能會小于復雜度增長慢的,
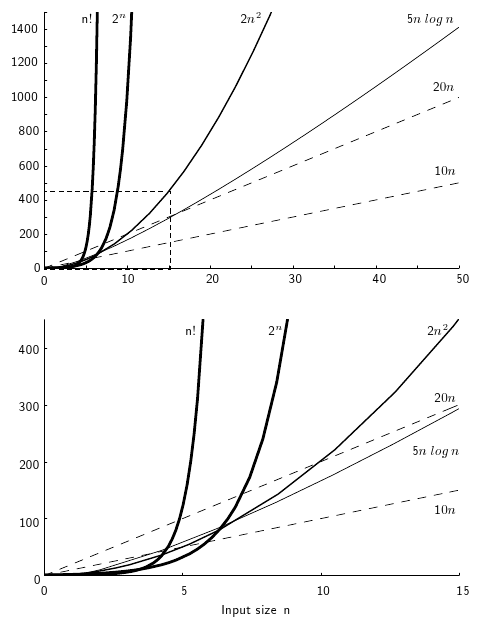
所以在選擇演算法時,不能無腦上看起來更快的高級資料結構和演算法,還得具體問題具體分析,因為高級資料結構和演算法在實作時往往附帶額外的計算開銷,如果其帶來的增益無法抵消掉隱含的代價,可能就會得不償失,
這同時也給了我們在代碼優化方向上的啟示,
- 一是從\(f(n)\)上進行優化,比如使用更高級的演算法和資料結構;
- 還有是對常數\(c\)進行優化,比如移除回圈體中不必要的索引計算、重復計算等,
以上
參考
- Big-O Cheat Sheet Poster
- Know Thy Complexities
- 鄧俊輝-資料結構C++描述第三版
- Growth Rates Review
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/121126.html
標籤:其他
上一篇:CodeForces - 1007A (思維+雙指標)
下一篇:歸并排序