#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author:albert time:2019/9/3
import requests,json,time,csv
from fake_useragent import UserAgent #獲取userAgent
from datetime import datetime,timedelta
?
def get_content(url):
'''獲取api資訊的網頁源代碼'''
ua = UserAgent().random
try:
data = requests.get(url,headers={'User-Agent':ua},timeout=3 ).text
return data
except:
pass
def Process_data(html):
'''對資料內容的獲取'''
data_set_list = []
#json格式化
data_list = json.loads(html)['cmts']
for data in data_list:
data_set = [data['id'],data['nickName'],data['userLevel'],data['cityName'],data['content'],data['score'],data['startTime']]
data_set_list.append(data_set)
return data_set_list
?
if __name__ == '__main__':
start_time = start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 獲取當前時間,從當前時間向前獲取
# print(start_time)
end_time = '2019-07-26 08:00:00'
?
# print(end_time)
while start_time > str(end_time):
#構造url
url = 'http://m.maoyan.com/mmdb/comments/movie/1211270.json?_v_=yes&offset=0&startTime=' + start_time.replace(
' ', '%20')
print('........')
try:
html = get_content(url)
except Exception as e:
time.sleep(0.5)
html = get_content(url)
else:
time.sleep(1)
comments = Process_data(html)
# print(comments[14][-1])
if comments:
start_time = comments[14][-1]
start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + timedelta(seconds=-1)
# print(start_time)
start_time = datetime.strftime(start_time,'%Y-%m-%d %H:%M:%S')
print(comments)
#保存資料為csv
with open("comments_1.csv", "a", encoding='utf-8',newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(comments)
?
以上是在網上看到的代碼 但是運行以后會有如下情況,哪位大神可以幫助我一下
 馬上要交期末作業了
馬上要交期末作業了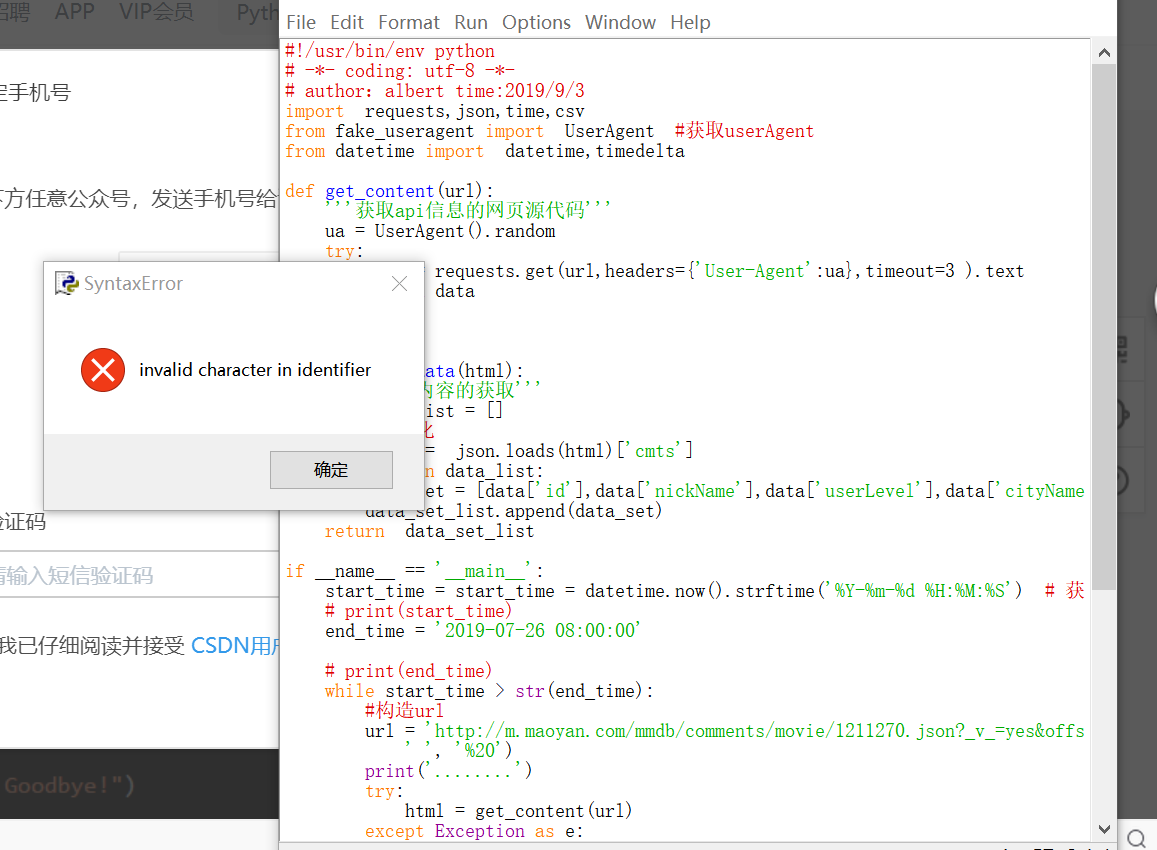
uj5u.com熱心網友回復:
現在資料已經出來了 有大佬知道怎么用這份資料進行相關可視化操作嗎(比如餅圖、地區分布圖等等)轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/121616.html
標籤:非技術區
上一篇:Logstash 推送到elasticsearch 時不時出現[WARN ][logstash.filters.json ] Parsed JSON
下一篇:中國紅客官網疑似遭受攻擊