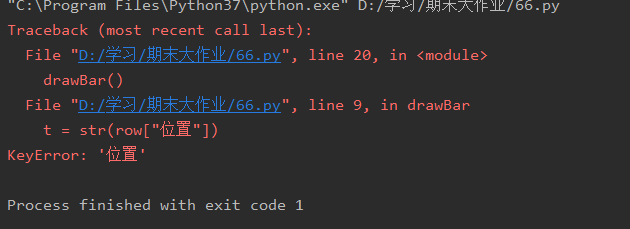
經測驗第二列第三列可以讀出且進行操作,唯獨第一列不可以,代碼如下:
import requests as rq
from bs4 import BeautifulSoup as BS
import jieba
import time
import sys
import matplotlib as plt
import matplotlib.pyplot as plt1
import random
import os
import csv
import imageio
import wordcloud
def getHtml():
# 設定請求頭防止被反爬蟲檢測
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Connection": "keep-alive"}
url_python_list = []
#url_java_list = []
#url_php_list = []
#if a.lower() == "python":
url_python = "https://www.lagou.com/zhaopin/Python/{}/?filterOption=2&sid=9f0a0fe0139a4177a5235849fc13c128" #python職位網址格式
url_java = "https://www.lagou.com/zhaopin/Java/{}/?filterOption=2&sid=fa689b8226cc43cda1fc58081041a81d" #java職位網址格式
url_python_list = [url_python.format(i) for i in range(1,3)] #生成前三十頁網址串列
test_web = "https://www.lagou.com/zhaopin/Python/1/?filterOption=2&sid=9f0a0fe0139a4177a5235849fc13c128"
#爬取前三十頁招聘資訊
for i in url_python_list:
rs = rq.get(i,headers = headers)
statusCode = rs.status_code
if statusCode == 200:
print("爬取網頁{}成功".format(i))
rs.encoding = 'uft-8'
#return rs.text
getdata(rs.text)
else:
print("爬取網頁{}失敗".format(i))
return "Failed to get url html"
x = random.randint(5,10) #設定隨機sleep秒數,防止每次請求時間間隔相同而被反爬蟲檢測(二層保險)
time.sleep(x)
def getdata(html):
soup = BS(html,"html.parser") #得到html
salary_information = soup.find_all("span",{"class":"money"}) #得到薪水資訊
address_information = soup.find_all("span",{"class":"add"}) #得到公司地址資訊
position_information = soup.find_all("h3") #得到崗位資訊
salary_list = []
address_list = []
position_list = []
information_list = []
# 生成薪水串列
for salary in salary_information:
sal = salary.text
salary_list.append(sal)
# 生成地址串列
for address in address_information:
add = address.text
address_list.append(add)
# 生成崗位需求串列
for position in position_information:
pos = position.string
position_list.append(pos)
# 生成資訊總串列
for i in range(len(position_list)):
information_list.append([address_list[i],position_list[i],salary_list[i]])
writetxt(information_list)
return information_list
#寫入檔案函式
def writetxt(txtList,fileName="information.txt"):
openWay = 'a' if os.path.exists(fileName) else 'w' #如果檔案名已經存在則追加文本,否不存在創建新檔案
with open(fileName,openWay,encoding='utf-8') as fp:
for x in txtList:
line = list(map(str,x))
line = "^".join(line)+'\n'
fp.write(line)
print("{}檔案寫入成功".format(fileName))
#寫入csv檔案函式
def txt_to_csv(fileCSV,fileTXT='information.txt'):
dataList = []
with open(fileTXT, 'r',encoding="utf-8") as fp:
lines = fp.readlines()
for line in lines:
line = line.strip() # 去除\n
row = line.split('^') # 拆分資料
dataList.append(row) # 串列化
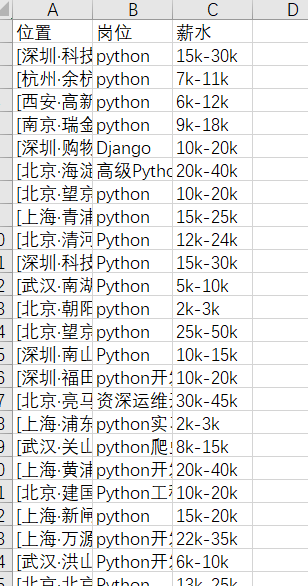
dataList.insert(0,["位置","崗位","薪水"])
with open(fileCSV, 'w', newline='',encoding="utf-8-sig") as fp:
writer = csv.writer(fp)
writer.writerows(dataList)
print('{}檔案寫入成功'.format(fileCSV))
return dataList
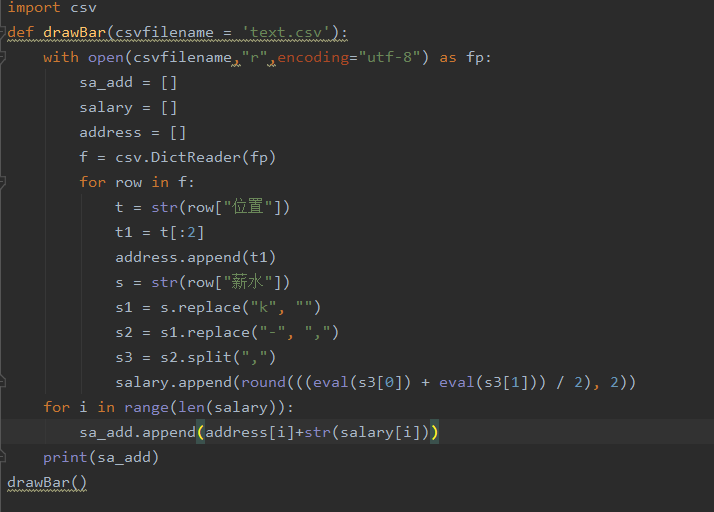
def drawBar(csvfilename = 'text.csv'):
with open(csvfilename,"r",encoding="utf-8") as fp:
sa_add = []
salary = []
address = []
f = csv.DictReader(fp)
for row in f:
# s = str(row["薪水"])
# s1 = s.replace("k","")
# s2 = s1.replace("-",",")
# s3 = s2.split(",")
# salary.append(round(((eval(s3[0])+eval(s3[1]))/2),2))
t = str(row["位置"])
t1 = t[:2]
address.append(t1)
for i in range(len(salary)):
sa_add.append(address[i]+str(salary[i]))
#def drawPie():
#def drawScatter():
x = getHtml()
y = txt_to_csv("text.csv"
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/121670.html
上一篇:開源一個內網穿透工具