- 原文:The top data structures you should know for your next coding interview
- 譯者:Fundebug
本文采用意譯,著作權歸原作者所有

1976 年,一個瑞士計算機科學家寫一本書《Algorithms + Data Structures = Programs》,即:演算法 + 資料結構 = 程式,40 多年過去了,這個等式依然成立,
很多代碼面試題都要求候選者深入理解資料結構,不管你來自大學計算機專業還是編程培訓機構,也不管你有多少年編程經驗,有時面試題會直接提到資料結構,比如“給我實作一個二叉樹”,然而有時則不那么明顯,比如“統計一下每個作者寫的書的數量”,
什么是資料結構?
資料結構是計算機存盤、組織資料的方式,對于特定的資料結構(比如陣列),有些操作效率很高(讀某個陣列元素),有些操作的效率很低(洗掉某個陣列元素),程式員的目標是為當前的問題選擇最優的資料結構,
為什么我們需要資料結構?
資料是程式的核心要素,因此資料結構的價值不言而喻,無論你在寫什么程式,你都需要與資料打交道,比如員工工資、股票價格、雜貨清單或者電話本,在不同場景下,資料需要以特定的方式存盤,我們有不同的資料結構可以滿足我們的需求,
8 種常用資料結構
- 陣列
- 堆疊
- 佇列
- 鏈表
- 圖
- 樹
- 前綴樹
- 哈希表
1. 陣列
陣列(Array)大概是最簡單,也是最常用的資料結構了,其他資料結構,比如堆疊和佇列都是由陣列衍生出來的,
下圖展示了 1 個陣列,它有 4 個元素:
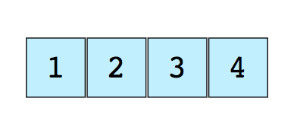
每一個陣列元素的位置由數字編號,稱為下標或者索引(index),大多數編程語言的陣列第一個元素的下標是 0,
根據維度區分,有 2 種不同的陣列:
- 一維陣列(如上圖所示)
- 多維陣列(陣列的元素為陣列)
陣列的基本操作
- Insert - 在某個索引處插入元素
- Get - 讀取某個索引處的元素
- Delete - 洗掉某個索引處的元素
- Size - 獲取陣列的長度
常見陣列代碼面試題
- 查找陣列中第二小的元素
- 查找第一個沒有重復的陣列元素
- 合并 2 個排序好的陣列
- 重新排列陣列中的正數和負數
2. 堆疊
撤回,即 Ctrl+Z,是我們最常見的操作之一,大多數應用都會支持這個功能,你知道它是怎么實作的嗎?答案是這樣的:把之前的應用狀態(限制個數)保存到記憶體中,最近的狀態放到第一個,這時,我們需要堆疊(stack)來實作這個功能,
堆疊中的元素采用 LIFO (Last In First Out),即后進先出,
下圖的堆疊有 3 個元素,3 在最上面,因此它會被第一個移除:
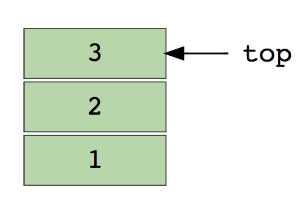
堆疊的基本操作
- Push?—? 在堆疊的最上方插入元素
- Pop?— 回傳堆疊最上方的元素,并將其洗掉
- isEmpty?—? 查詢堆疊是否為空
- Top?—? 回傳堆疊最上方的元素,并不洗掉
常見的堆疊代碼面試題
- 使用堆疊計算后綴運算式
- 使用堆疊為堆疊中的元素排序
- 檢查字串中的括號是否匹配正確
3. 佇列
佇列(Queue)與堆疊類似,都是采用線性結構存盤資料,它們的區別在于,堆疊采用 LIFO 方式,而佇列采用先進先出,即FIFO(First in First Out),
下圖展示了一個佇列,1 是最上面的元素,它會被第一個移除:

佇列的基本操作
- Enqueue?—? 在佇列末尾插入元素
- Dequeue?—? 將佇列第一個元素洗掉
- isEmpty?—? 查詢佇列是否為空
- Top?—? 回傳佇列的第一個元素
常見的佇列代碼面試題
- 使用佇列實作堆疊
- 倒轉佇列的前 K 個元素
- 使用佇列將 1 到 n 轉換為二進制
4. 鏈表
鏈表(Linked List)也是線性結構,它與陣列看起來非常像,但是它們的記憶體分配方式、內部結構和插入洗掉操作方式都不一樣,
鏈表是一系列節點組成的鏈,每一個節點保存了資料以及指向下一個節點的指標,鏈表頭指標指向第一個節點,如果鏈表為空,則頭指標為慷訓者為 null,
鏈表可以用來實作檔案系統、哈希表和鄰接表,
下圖展示了一個鏈表,它有 3 個節點:

鏈表分為 2 種:
- 單向鏈表
- 雙向鏈表
鏈表的基本操作
- InsertAtEnd?—? 在鏈表結尾插入元素
- InsertAtHead?—? 在鏈表開頭插入元素
- Delete?—? 洗掉鏈表的指定元素
- DeleteAtHead?—? 洗掉鏈表第一個元素
- Search?—? 在鏈表中查詢指定元素
- isEmpty?—? 查詢鏈表是否為空
常見的佇列代碼面試題
- 倒轉 1 個鏈表
- 檢查鏈表中是否存在回圈
- 回傳鏈表倒數第 N 個元素
- 移除鏈表中的重復元素
5. 圖
圖(graph)由多個節點(vertex)構成,節點之間闊以互相連接組成一個網路,(x, y)表示一條邊(edge),它表示節點 x 與 y 相連,邊可能會有權值(weight/cost),
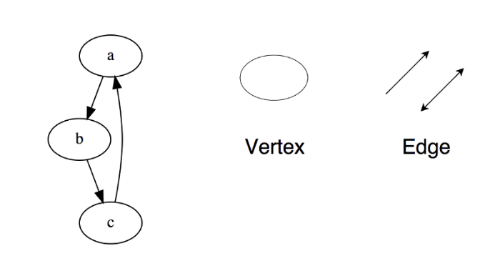
圖分為兩種:
- 無向圖
- 有向圖
在編程語言中,圖有可能有以下兩種形式表示:
- 鄰接矩陣(Adjacency Matrix)
- 鄰接表(Adjacency List)
遍歷圖有兩周演算法
- 廣度優先搜索(Breadth First Search)
- 深度優先搜索(Depth First Search)
常見的圖代碼面試題
- 實作廣度優先搜索
- 實作深度優先搜索
- 檢查圖是否為樹
- 統計圖中邊的個數
- 使用 Dijkstra 演算法查找兩個節點之間的最短距離
6. 樹
樹(Tree)是一個分層的資料結構,由節點和連接節點的邊組成,樹是一種特殊的圖,它與圖最大的區別是沒有回圈,
樹被廣泛應用在人工智能和一些復雜演算法中,用來提供高效的存盤結構,
下圖是一個簡單的樹以及與樹相關的術語:
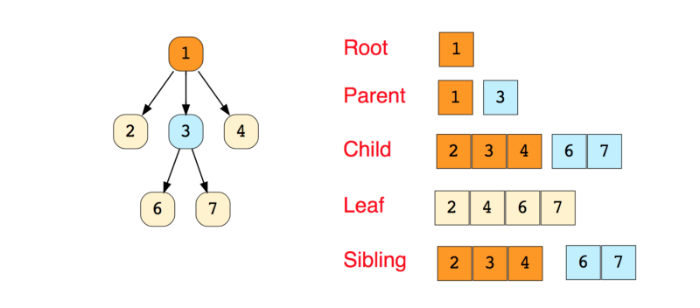
樹有很多分類:
- N 叉樹(N-ary Tree)
- 平衡樹(Balanced Tree)
- 二叉樹(Binary Tree)
- 二叉查找樹(Binary Search Tree)
- 平衡二叉樹(AVL Tree)
- 紅黑樹(Red Black Tree)
- 2-3 樹(2–3 Tree)
其中,二叉樹和二叉查找樹是最常用的樹,
常見的樹代碼面試題
- 計算樹的高度
- 查找二叉平衡樹中第 K 大的元素
- 查找樹中與根節點距離為 k 的節點
- 查找二叉樹中某個節點所有祖先節點
7. 前綴樹
前綴樹(Prefix Trees 或者 Trie)與樹類似,用于處理字串相關的問題時非常高效,它可以實作快速檢索,常用于字典中的單詞查詢,搜索引擎的自動補全甚至 IP 路由,
下圖展示了“top”, “thus”和“their”三個單詞在前綴樹中如何存盤的:
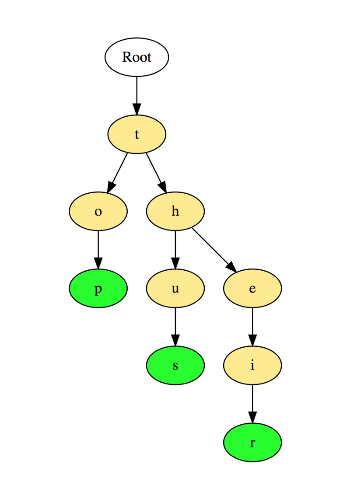
單詞是按照字母從上往下存盤,“p”, “s”和“r”節點分別表示“top”, “thus”和“their”的單詞結尾,
常見的樹代碼面試題
- 統計前綴樹表示的單詞個數
- 使用前綴樹為字串陣列排序
8. 哈希表
哈希(Hash)將某個物件變換為唯一識別符號,該識別符號通常用一個短的隨機字母和數字組成的字串來代表,哈希可以用來實作各種資料結構,其中最常用的就是哈希表(hash table),
哈希表通常由陣列實作,
哈希表的性能取決于 3 個指標:
- 哈希函式
- 哈希表的大小
- 哈希沖突處理方式
下圖展示了有陣列實作的哈希表,陣列的下標即為哈希值,由哈希函式計算,作為哈希表的鍵(key),而陣列中保存的資料即為值(value):
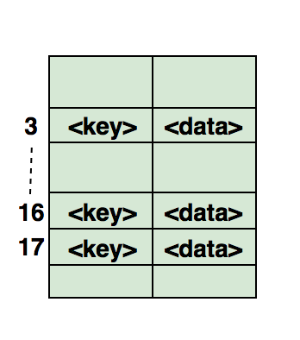
常見的哈希表代碼面試題
- 查找陣列中對稱的組合
- 確認某個陣列的元素是否為另一個陣列元素的子集
- 確認給定的陣列是否互斥
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/122744.html
標籤:其他
上一篇:微信多開腳步
下一篇:給那些抱怨的低能程式員