GIMP源代碼鏈接:https://gitlab.gnome.org/GNOME/gimp/-/archive/master/gimp-master.zip
GEGL相關代碼鏈接:https://gitlab.gnome.org/GNOME/gegl/-/archive/master/gegl-master.zip
最近因為要研究下色溫演算法,順便下載了最新的GIMP軟體,色溫演算法倒是找到了(有空單獨來講下),也順便看看GIMP都有些什么更新,嗯,更新還是蠻多的,界面UI上有很多改動,有些已經改的面目全非了,隨便瞄了一下Enhance選單,發現里面有一個Nosie Reduction演算法,試了下,還有點效果,于是在github上下載了GIMP的源代碼,可是在源代碼里搜索相關的關鍵詞確沒有發現任何的相關代碼,后來才發現很多東西都有個GEGL關鍵詞,結果一百度,原來他是一個單獨的軟體包,于是有下載了GEGL的源代碼,終于在gegl-master\operations\common\里面看到了noise-reduction.c檔案,
其核心的代碼如下:
static void noise_reduction (float *src_buf, /* source buffer, one pixel to the left and up from the starting pixel */ int src_stride, /* stridewidth of buffer in pixels */ float *dst_buf, /* destination buffer */ int dst_width, /* width to render */ int dst_height, /* height to render */ int dst_stride) /* stride of target buffer */ { int c; int x,y; int dst_offset; #define NEIGHBOURS 8 #define AXES (NEIGHBOURS/2) #define POW2(a) ((a)*(a)) /* core code/formulas to be tweaked for the tuning the implementation */ #define GEN_METRIC(before, center, after) \ POW2((center) * 2 - (before) - (after)) /* Condition used to bail diffusion from a direction */ #define BAIL_CONDITION(new,original) ((new) > (original)) #define SYMMETRY(a) (NEIGHBOURS - (a) - 1) /* point-symmetric neighbour pixel */ #define O(u,v) (((u)+((v) * src_stride)) * 4) int offsets[NEIGHBOURS] = { /* array of the relative distance i float * pointers to each of neighbours * in source buffer, allows quick referencing. */ O( -1, -1), O(0, -1), O(1, -1), O( -1, 0), O(1, 0), O( -1, 1), O(0, 1), O(1, 1)}; #undef O dst_offset = 0; for (y=0; y<dst_height; y++) { float *center_pix = src_buf + ((y+1) * src_stride + 1) * 4; dst_offset = dst_stride * y; for (x=0; x<dst_width; x++) { for (c=0; c<3; c++) /* do each color component individually */ { float metric_reference[AXES]; int axis; int direction; float sum; int count; for (axis = 0; axis < AXES; axis++) { /* initialize original metrics for the horizontal, vertical and 2 diagonal metrics */ float *before_pix = center_pix + offsets[axis]; float *after_pix = center_pix + offsets[SYMMETRY(axis)]; metric_reference[axis] = GEN_METRIC (before_pix[c], center_pix[c], after_pix[c]); } sum = center_pix[c]; count = 1; /* try smearing in data from all neighbours */ for (direction = 0; direction < NEIGHBOURS; direction++) { float *pix = center_pix + offsets[direction]; float value = https://www.cnblogs.com/Imageshop/p/pix[c] * 0.5 + center_pix[c] * 0.5; int axis; int valid; /* check if the non-smoothing operating check is true if * smearing from this direction for any of the axes */ valid = 1; /* assume it will be valid */ for (axis = 0; axis < AXES; axis++) { float *before_pix = center_pix + offsets[axis]; float *after_pix = center_pix + offsets[SYMMETRY(axis)]; float metric_new = GEN_METRIC (before_pix[c], value, after_pix[c]); if (BAIL_CONDITION(metric_new, metric_reference[axis])) { valid = 0; /* mark as not a valid smoothing, and .. */ break; /* .. break out of loop */ } } if (valid) /* we were still smooth in all axes */ { /* add up contribution to final result */ sum += value; count ++; } } dst_buf[dst_offset*4+c] = sum / count; } dst_buf[dst_offset*4+3] = center_pix[3]; /* copy alpha unmodified */ dst_offset++; center_pix += 4; } } }
這個代碼看上去比較混亂,沒辦法,大型軟體沒有哪一個代碼看上去能讓人省心的,而且也不怎么講究效率,我測驗了一個3K*2K的彩色圖,在GIMP里大概在4S左右處理完成,屬于很慢的了,看這個代碼,也知道大概有width * height * 3 * 8 * 4 * Iter個回圈,計算量確實是相當的大,
我試著嘗試優化這個演算法,
優化的第一步是弄明白演算法的原理,在GIMP的UI界面上可當滑鼠停留在Noise Reduction選單上時,會出現Anisotroic smoothing operation字樣,所以初步分析他是屬于各項異性擴散類的演算法,稍微分析下代碼,也確實是,明顯這屬于一個領域濾波器,對每一個像素,求取其3*3領域內的累加值,但是3*3領域的權重并不是平均分布或者是高斯分布,而是和領域的值有關的,如果領域的值是一個邊緣點,他將不參與到累加中,權重為0,否則權重為1,
具體一點,對于領域里的任何一點,我們先求取其和中心點的平均值,對應 float value = https://www.cnblogs.com/Imageshop/p/pix[c] * 0.5 + center_pix[c] * 0.5; 這條陳述句,然后計算這個值在2個45度對角線及水平和垂直方向的梯度(4個梯度值)是否比中心點在四個方向的梯度都小,如果都小,說明這個領域點不屬于邊緣點,可以往這個方向擴散,把他計入到統計值中,如果有任何一個方向小了,則不參與最終的計算,
上面的程序可以看成是標準的各項異性擴散的特殊在特殊處理,他具有各項異性擴散的特性,也具有一些特殊性,
下一步,稍微分析下最簡單的優化方法,第一,我們知道,在大回圈里一般不建議嵌套入小的回圈,這樣是很低效的,我們觀察到上面代碼里的
for (c=0; c<3; c++) /* do each color component individually */
這個陳述句主要是為了方便表達3通道的處理的方便,但是其實三通道之間的處理時沒有任何聯系的,對于這樣的演算法,很明顯,我們可以一次性當然處理R G B R G B R G B ,而不需要像GIMP這個代碼這樣按照 RRR GGG BBB這樣的順序來寫,GIMP這種寫法浪費了很多CPU的CACHE,畢竟R和G和B在記憶體類分布本來就是連續的,這樣就減少了一個小回圈,
第二個優化的點是,對于普通的影像資料,我們可以考慮不用浮點數來處理,畢竟上述計算里只有*0.5這樣的浮點操作,我們考慮將原先的影像資料放大一定的倍數,然后用整形來玩,在處理完后,在縮小到原來的范圍,比如使用short型別應該就足夠了,我把資料放大16倍或者32倍,甚至8倍應該都能獲得足夠的精度,
第三個優化點,程式中是使用的Pow來判斷梯度的大小的,其實可以不用,直接使用絕對值的結果和Pow是完全一樣的,而絕對值的計算量比pow要小很多,對于整數則更為如此(還可以不考慮pow資料型別的改變,比如short的絕對值還是short型別,但是其pow可能就需要用int來表示了,這在SIMD優化會產生不同的結果),
第四個優化點是 for (axis = 0; axis < AXES; axis++)這個小回圈我們應該把它直接展開,
第五點,我們還可以考慮我在其他文章里提到的支持Inplace操作的方式,這樣noise_reduction這個函式的輸入和輸出就可以是同一個記憶體,
第六點還有小點上的演算法改進,比如一些中間計算沒必要重復進行,有些可以提到外部來等,
綜合上面的描述,我整理除了一個優化的C語言版本的程式,如下所示:
void IM_AnisotropicDiffusion3X3(short *Src, short *Dest, int Width, int Height, int SplitPos, int Stride) { int Channel = Stride / Width; short *RowCopy = (short *)malloc((Width + 2) * 3 * Channel * sizeof(short)); short *First = RowCopy; short *Second = RowCopy + (Width + 2) * Channel; short *Third = RowCopy + (Width + 2) * 2 * Channel; memcpy(Second, Src, Channel * sizeof(short)); memcpy(Second + Channel, Src, Width * Channel * sizeof(short)); // 拷貝資料到中間位置 memcpy(Second + (Width + 1) * Channel, Src + (Width - 1) * Channel, Channel * sizeof(short)); memcpy(First, Second, (Width + 2) * Channel * sizeof(short)); // 第一行和第二行一樣 memcpy(Third, Src + Stride, Channel * sizeof(short)); // 拷貝第二行資料 memcpy(Third + Channel, Src + Stride, Width * Channel* sizeof(short)); memcpy(Third + (Width + 1) * Channel, Src + Stride + (Width - 1) * Channel, Channel* sizeof(short)); for (int Y = 0; Y < Height; Y++) { short *LinePD = Dest + Y * Stride; if (Y != 0) { short *Temp = First; First = Second; Second = Third; Third = Temp; } if (Y == Height - 1) { memcpy(Third, Second, (Width + 2) * Channel * sizeof(short)); } else { memcpy(Third, Src + (Y + 1) * Stride, Channel * sizeof(short)); memcpy(Third + Channel, Src + (Y + 1) * Stride, Width * Channel * sizeof(short)); // 由于備份了前面一行的資料,這里即使Src和Dest相同也是沒有問題的 memcpy(Third + (Width + 1) * Channel, Src + (Y + 1) * Stride + (Width - 1) * Channel, Channel * sizeof(short)); } for (int X = 0; X < SplitPos * Channel; X++) { short LT = First[X], T = First[X + Channel], RT = First[X + 2 * Channel]; short L = Second[X], C = Second[X + Channel], R = Second[X + 2 * Channel]; short LB = Third[X], B = Third[X + Channel], RB = Third[X + 2 * Channel]; short LT_RB = LT + RB, RT_LB = RT + LB; short T_B = T + B, L_R = L + R, C_C = C + C; short Dist1 = IM_Abs(C_C - LT_RB), Dist2 = IM_Abs(C_C - T_B); short Dist3 = IM_Abs(C_C - RT_LB), Dist4 = IM_Abs(C_C - L_R); int Sum = C_C, Amount = 2; short LT_C = LT + C; if ((IM_Abs(LT_C - LT_RB) < Dist1) && (IM_Abs(LT_C - T_B) < Dist2) && (IM_Abs(LT_C - RT_LB) < Dist3) && (IM_Abs(LT_C - L_R) < Dist4)) { Sum += LT_C; Amount += 2; } short T_C = T + C; if ((IM_Abs(T_C - LT_RB) < Dist1) && (IM_Abs(T_C - T_B) < Dist2) && (IM_Abs(T_C - RT_LB) < Dist3) && (IM_Abs(T_C - L_R) < Dist4)) { Sum += T_C; Amount += 2; } short RT_C = RT + C; if ((IM_Abs(RT_C - LT_RB) < Dist1) && (IM_Abs(RT_C - T_B) < Dist2) && (IM_Abs(RT_C - RT_LB) < Dist3) && (IM_Abs(RT_C - L_R) < Dist4)) { Sum += RT_C; Amount += 2; } short L_C = L + C; if ((IM_Abs(L_C - LT_RB) < Dist1) && (IM_Abs(L_C - T_B) < Dist2) && (IM_Abs(L_C - RT_LB) < Dist3) && (IM_Abs(L_C - L_R) < Dist4)) { Sum += L_C; Amount += 2; } short R_C = R + C; if ((IM_Abs(R_C - LT_RB) < Dist1) && (IM_Abs(R_C - T_B) < Dist2) && (IM_Abs(R_C - RT_LB) < Dist3) && (IM_Abs(R_C - L_R) < Dist4)) { Sum += R_C; Amount += 2; } short LB_C = LB + C; if ((IM_Abs(LB_C - LT_RB) < Dist1) && (IM_Abs(LB_C - T_B) < Dist2) && (IM_Abs(LB_C - RT_LB) < Dist3) && (IM_Abs(LB_C - L_R) < Dist4)) { Sum += LB_C; Amount += 2; } short B_C = B + C; if ((IM_Abs(B_C - LT_RB) < Dist1) && (IM_Abs(B_C - T_B) < Dist2) && (IM_Abs(B_C - RT_LB) < Dist3) && (IM_Abs(B_C - L_R) < Dist4)) { Sum += B_C; Amount += 2; } short RB_C = RB + C; if ((IM_Abs(RB_C - LT_RB) < Dist1) && (IM_Abs(RB_C - T_B) < Dist2) && (IM_Abs(RB_C - RT_LB) < Dist3) && (IM_Abs(RB_C - L_R) < Dist4)) { Sum += RB_C; Amount += 2; } LinePD[X] = Sum / Amount; } } free(RowCopy); }
呼叫函式
int IM_ReduceNoise(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int SplitPos, int Strength) { int Channel = Stride / Width; if ((Src =https://www.cnblogs.com/Imageshop/p/= NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER; if ((Channel != 1) && (Channel != 3)) return IM_STATUS_INVALIDPARAMETER; Strength = IM_ClampI(Strength, 1, 10); SplitPos = IM_ClampI(SplitPos, 0, Width); int Status = IM_STATUS_OK; short *Temp = (short *)malloc(Height * Stride * sizeof(short)); if (Temp == NULL) return IM_STATUS_OUTOFMEMORY; for (int Y = 0; Y < Height * Stride; Y++) { Temp[Y] = Src[Y] << 3; } for (int Y = 0; Y < Strength; Y++) { IM_AnisotropicDiffusion3X3(Temp, Temp, Width, Height, SplitPos, Stride); } for (int Y = 0; Y < Height * Stride; Y++) { Dest[Y] = Temp[Y] >> 3; } free(Temp); return IM_STATUS_OK; }
是不是看起來比上面的GIMP得要舒服些,而且中間也大概只要原始影像2倍的一個臨時記憶體了,在速度和記憶體占用方面都前進了很多,
我測驗前面提到的那副3K*2K的影像,耗時要7S多,但是我測驗表面GIMP用了多核的,如果論單核,我這里的速度要比他快2倍多,
很明顯,這個速度是不可以接受的,我們需要繼續優化,
我還是老套路,使用SIMD指令做處理,看到上面的代碼,其實真的覺得好容易改成SIMD的,
short LT_RB = LT + RB, RT_LB = RT + LB;
short T_B = T + B, L_R = L + R, C_C = C + C;
short Dist1 = IM_Abs(C_C - LT_RB), Dist2 = IM_Abs(C_C - T_B);
short Dist3 = IM_Abs(C_C - RT_LB), Dist4 = IM_Abs(C_C - L_R);
這些加減絕對值都有完全對應的SSE指令, _mm_add_epi16、 _mm_sub_epi16、_mm_abs_epi16,基本上就是照著寫,
稍微復雜一點就是這里:
if ((IM_Abs(LT_C - LT_RB) < Dist1) && (IM_Abs(LT_C - T_B) < Dist2) && (IM_Abs(LT_C - RT_LB) < Dist3) && (IM_Abs(LT_C - L_R) < Dist4))
{
Sum += LT_C;
Amount += 2;
}
在C語言里,這里判斷會進行短路計算,即如果前一個條件已經不滿足了,后續的計算就不會進行,但是在SIMD指令里,是沒有這樣的機制的,我們只能全部計算,然后在通過某一種條件組合,
在合理,要實作符合條件就進行累加,不符合條件就不做處理的需求,我們需要稍作修改,即不符合條件不是不做處理,而是加0,加0對結果沒有影響的,主要借助下面的_mm_blendv_epi8來實作,
__m128i LT_C = _mm_add_epi16(LT, C); Flag1 = _mm_cmplt_epi16(_mm_abs_epi16(_mm_sub_epi16(LT_C, LT_RB)), Dist1); // 只能全部都計算,但還是能提速 Flag2 = _mm_cmplt_epi16(_mm_abs_epi16(_mm_sub_epi16(LT_C, T_B)), Dist2); Flag3 = _mm_cmplt_epi16(_mm_abs_epi16(_mm_sub_epi16(LT_C, RT_LB)), Dist3); Flag4 = _mm_cmplt_epi16(_mm_abs_epi16(_mm_sub_epi16(LT_C, L_R)), Dist4); Flag = _mm_and_si128(_mm_and_si128(Flag1, Flag2), _mm_and_si128(Flag3, Flag4)); Sum = _mm_adds_epu16(Sum, _mm_blendv_epi8(Zero, LT_C, Flag)); Amount = _mm_adds_epu16(Amount, _mm_blendv_epi8(Zero, Two, Flag));
注意到我們這里用到了_mm_adds_epu16,無符號的16位加法,這是因為我需要盡量的提速,因此需要減少型別轉換的次數,同時,我們看到在統計累加值時,我們并沒有求平均值,而是直接用的累加值,這樣理論上最大的累加值就是 255 * n * (8 + 1) * 2 < 65535, 這樣n最大能取15,但是15不是個好資料,在放大和縮小都不能用移位來實作,所以我最后取得放大系數為8,
另外,在最后還有個16位的整數的除法問題,這個沒有辦法,SSE指令沒有提供整數的除法計算方法,還只能轉換到浮點后,再次轉換回來,
這樣用SSE處理后,還是同一幅測驗影像,在同一臺PC上速度能提升到400ms(4次迭代),比之前的普通的C語言提高了約17倍的速度,
在現代CPU中,具有AVX2指令集已經是很普遍的了,單AVX2能同時處理256位元組的資料,比SSE還要多一倍,我也常使用AVX2進行優化處理,速度能達到250ms,相當于普通C語言的28倍之多(但是AVX編程里有很多坑,這些坑都拜AVX不是完全的按照SSE的線性擴展導致的,這個后續有時間我單獨提出),
經過測驗,1080P的影像使用4次迭代大約需要80ms,3次迭代55ms,2次迭代月40ms,也就是說前面的一些方法和縮小所使用的時間幾乎可以忽略,
選了幾幅有特點的圖進行了去燥測驗,其中分界線左側的位處理的效果,右側為未處理的,
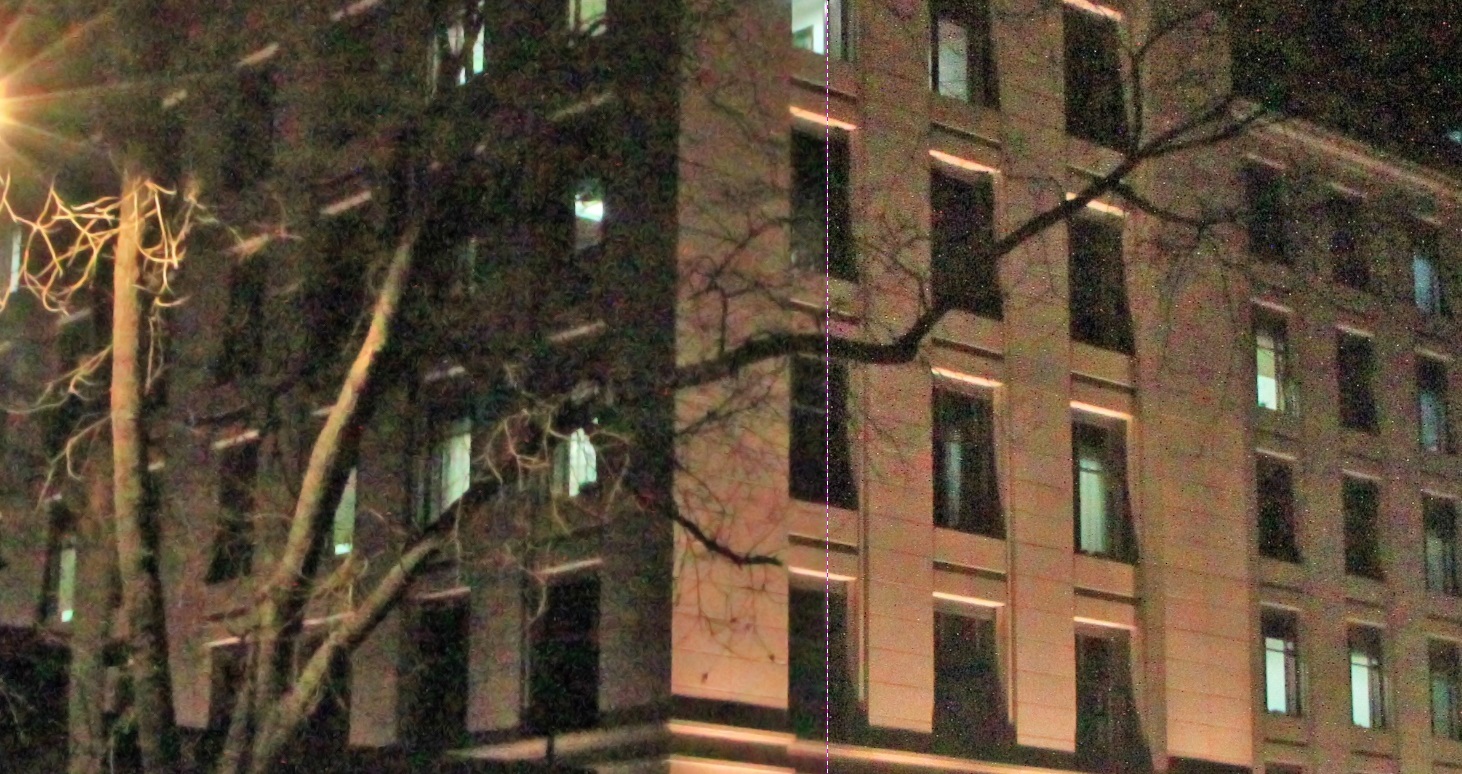


但是,這個演算法也還是不是很好,他對于影像容易出現輕微的油畫效果,對于一些細節特別豐富的影像非常明顯,比如下圖:

這個應該是不太可以接受的,也許可以通過修改部分權重的規則來改變這個現象,這個屬于后期研究的問題了,
另外,在GIMP里也提供了這個演算法的OPENCL實作,有興趣的可以源代碼里找一找,不曉得速度怎么樣,
本文Demo下載地址: http://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar,見其中的Denoise -> Anisotroic Diffusion 選單,
寫博不易,歡迎土豪打賞贊助,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/124302.html
標籤:其他