照著書上運行了一下。第一次運行時能爬到內容,
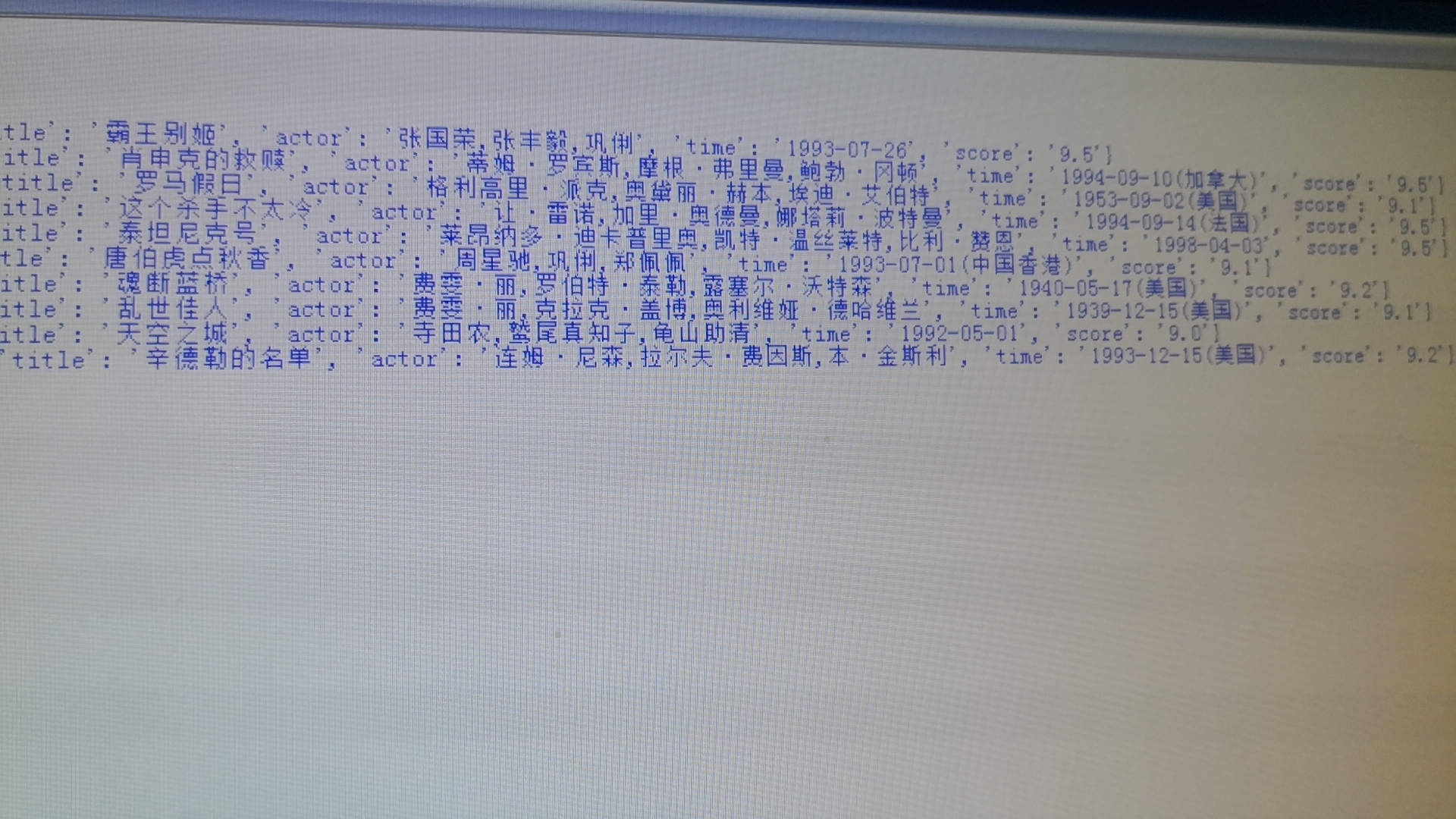
第二次及以后再運行時一直顯示restart看不到內容了,
 。
。import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="https://bbs.csdn.net/topics/(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/126266.html
上一篇:PTA 線性表 7-1 約瑟夫環(Josephus)問題(by Yan) (100分) 按出列次序輸出每個人的編號
下一篇:零基礎掌握Python入門到實戰