問題描述:
問題類似于老虎機(單臂賭博機),不同之處是它有k個控制桿,每次動作選擇相當于拉動老虎機的一個控制桿,我們希望通過強化學習的方法,讓智能體能夠通過重復地選擇學習,來最大化最終的獎金值,
 復現結果:
復現結果:
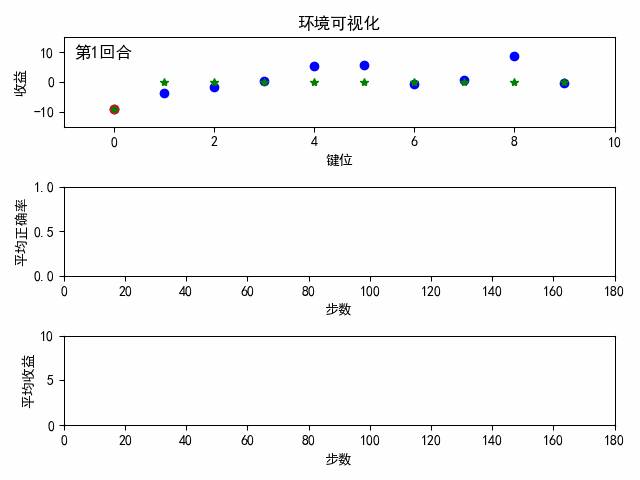
環境可視化:藍色為各個按鍵的真實收益;綠色為智能體對按鍵的估計收益;紅色為智能體的選擇,
代碼實作
1、環境搭建:
import numpy as np
global value
value = np.array([0.0]*10, dtype=float) #初始化全域變數
q = np.array([-8,-5,-2,1,5,6,1,2,8,0]) # 固定生成收益初始值
#q = np.random.normal(0, 5, 10) # 正態隨機收益初始值
qq = np.random.normal(0, 0.01, 10)
print(q)
def env2():
for i in range(0, 10):
global value
value[i] = np.random.normal(q[i]+qq[i], 1, 1)
return value
2、gif制作
import numpy as np
import random
import matplotlib.pyplot as plt
import matplotlib.animation as animation # 繪制動圖的庫
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正確顯示中文
plt.rcParams['axes.unicode_minus'] = False # 正確顯示正負號
from env import env1,env2 # 匯入自己撰寫的環境
# 超引數
EPSILON = 0.1 # epsilon-貪心
global n
n = 180 # 步長
K = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) # 存盤action
# 全域變數宣告及其初始化
global actions_q # 環境中10個action的實際收益
actions_q = np.array([0.0] * 10, dtype=float)
global actions_Q # 智能體對10個action的估計收益
actions_Q = np.array([0.0] * 10, dtype=float)
global value_total # 過去獲得的總收益
value_total = 0
global actions_num # 存盤10個action選擇到的次數
actions_num = np.array([0] * 10, dtype=int)
global right_num # 存盤選對的次數
right_num = 0
# 動圖描述
fig, (ax0, ax1, ax2) = plt.subplots(3, 1)
ln1, = ax0.plot([], [], "bo", animated=True) # 繪制環境value變化量
ln2, = ax0.plot([], [], "ro", animated=True) # 繪制選擇的action
ln3, = ax0.plot([], [], "g*", animated=True) # 繪制智能體預測的Q值
text_pt = ax0.text(-0.8, 8, '', fontsize=12) # 寫入文字
x, y1, y2 = [], [], []
ln4, = ax1.plot([], [], "-", animated=True) # 繪制智能體預測的Q值
ln5, = ax2.plot([], [], "-", animated=True) # 繪制智能體預測的Q值
def init(): # 畫布坐標軸范圍初始化
global n
ax0.set_title("環境可視化")
ax0.set_xlabel("鍵位")
ax0.set_ylabel("收益")
ax0.set_xlim(-1, 10)
ax0.set_ylim(-15, 15) # 環境可視化
ax1.set_ylabel("平均正確率")
ax1.set_xlabel("步數")
ax1.set_xlim(0, n)
ax1.set_ylim(0, 1) # 平均正確率
ax2.set_ylabel("平均收益")
ax2.set_xlabel("步數")
ax2.set_xlim(0, n)
ax2.set_ylim(0, 10) # 平均收益
plt.tight_layout()
return ln1, ln2, ln3, ln4, ln5, text_pt,
def update(frame): # 回合更新
global actions_q
actions_q = env2() # 獲取現在環境中的真實收益(陣列形式)
global actions_Q
if np.random.uniform() > EPSILON: # 90%的概率 greedy
arr_aa = np.array(actions_Q, dtype=float)
action = np.argmax(arr_aa) # 從估計值中選擇最大的動作為action
# print("貪婪,選擇了:")
# print(action)
else:
action = random.choice(K) # 隨機選擇action
# print("隨機,選擇了:")
# print(action)
global actions_num
actions_num[action] += 1 # 存盤各個action被選擇的次數
arr_aa = np.array(actions_q, dtype=float)
action_right = np.argmax(arr_aa) # 實際上收益最大的action
if (action == action_right):
global right_num
right_num += 1
global value_total
value_total += actions_q[action] # 存盤
ln1.set_data(K, actions_q) # 繪制環境中真實收益值
ln2.set_data(action, actions_q[action]) # 標記本回合選擇的action
ln3.set_data(K, actions_Q) # 繪制智能體的估計值
text_pt.set_text("第%d回合" % (frame)) # 繪制回合數
x.append(frame) # 將每次傳過來的n追加到xdata中
y1.append(right_num / frame)
ln4.set_data(x, y1)
y2.append(value_total / frame)
ln5.set_data(x, y2)
R = actions_q[action] # 環境中的真實收益
num = actions_num[action] # 第num次選擇這個動作
# 方法一:平均收益法更新估計值
actions_Q[action] = actions_Q[action] + (R - actions_Q[action]) / float(num)
# 方法二:固定步長法更新估計值
# actions_Q[action] = actions_Q[action] + 0.1*(actions_q[action]-actions_Q[action])
return ln1, ln2, ln3, ln4, ln5, text_pt,
# 繪制影片
anim = animation.FuncAnimation(fig, update, np.arange(1, n), interval=10, blit=True, init_func=init)
# 存盤為gif動圖
# anim.save("1.gif", writer='pillow')
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/126491.html
標籤:其他