基本性質
? 優先級佇列,也叫二叉堆、堆(不要和記憶體中的堆區搞混了,不是一個東西,一個是記憶體區域,一個是資料結構),
? 堆的本質上是一種完全二叉樹,分為:
-
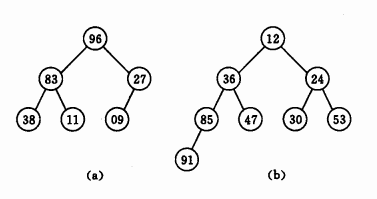
最小堆(小根堆):樹中每個非葉子結點都不大于其左右孩子結點的值,也就是根節點最小的堆,圖(a),
-
最大堆(大根堆):樹中每個非葉子結點都不小于其左右孩子結點的值,也就是根節點最大的堆,圖(b),
基本操作
均以大根堆為例
存盤方式
? 堆本質上是一顆完全二叉樹,使用陣列進行存盤,從\(a[1]\)開始存盤,這樣對于下標為\(k\)的結點\(a[k]\)來說,其左孩子的下標為\(2*k\),右孩子的下標為\(2*k+1\),,且不論 \(k\) 是奇數還是偶數,其父親結點(如果有的話)就是 $\left \lfloor k/2 \right \rfloor $,
向上調整
? 假如我們向一個堆中插入一個元素,要使其仍然保持堆的結構,應該怎么辦呢?
? 可以把想要添加的元素放在陣列的最后,也就是完全二叉樹的最后一個結點的后面,然后進行向上調整(heapinsert),向上調整總是把欲調整結點與父親結點比較,如果權值比父親結點大,那么就交換其與父親結點,反復比較,直到到達堆頂或父親結點的值較大為止,向上調整示意圖如下:

代碼如下,時間復雜度為\(O(logn)\):
void heapinsert(int* arr, int n) {
int k = n;
//如果 K 結點有父節點,且比父節點的權值大
while (k > 1 && arr[k] > arr[k / 2]) {
//交換 K 與父節點的值
swap(arr[k / 2], arr[k]);
k >>= 1;
}
}
這樣添加元素就很簡單了
void insert(int* arr, int n, int x) {
arr[++n] = x;//將x置于陣列末尾
heapinsert(arr, n);//向上調整x
}
向下調整
? 假如我們要洗掉一個堆中的堆頂元素,要使其仍然保持堆的結構,應該怎么辦呢?
? 移除堆頂元素后,將最后一個元素移動到堆頂,然后對這個元素進行向下調整(heapify),向下調整總是把欲調整結點 \(K\) 與其左右孩子結點比較,如果孩子中存在權值比當前結點 \(K\) 大的,那么就將其中權值最大的那個孩子結點與結點 \(K\),反復比較,直到到結點 \(K\) 為葉子結點或結點 \(K\) 的值比孩子結點都大為止,向下調整示意圖如下:

代碼如下,時間復雜度也是\(O(logn)\):
void heapify(int* arr, int k, int n) {
//如果結點 K 存在左孩子
while (k * 2 <= n) {
int left = k * 2;
//如果存在右孩子,并且右孩子的權值大于左孩子
if (left + 1 <= n && arr[left] < arr[left + 1])
left++; //就選中右孩子
//如果節點 K 的權值已經大于左右孩子中較大的節點
if (arr[k] > arr[left])
break;
swap(arr[left], arr[k]);
k = left;
}
}
這樣洗掉堆頂元素也就變得很簡單了
void deleteTop(int* arr, int n) {
arr[1] = arr[n--];//用最后一個元素覆寫第一個元素,并讓n-1
heapify(arr, 1, n);
}
建堆
自頂向下建堆
自頂向下建堆的思想是,從第 \(i=1\) 個元素開始,對其進行向上調整,始終使前 \(i\) 個元素保持堆的結構,時間復雜度 \(O(nlogn)\)
void ArrayToHeap(int *a,int n) {
for (int i = 1; i <= n; i++) {
heapinsert(a, i);
}
}
自底向上建堆
自底向上建堆的思想是,從底 $i=\left \lfloor n/2 \right \rfloor $ 個元素開始,對其進行向下調整,始終讓后 \(n-i\) 個元素保持堆的結構,
void ArrayToBheap(int *a, int n) {
int i = n / 2;
for (; i >= 1; i--) {
heapify(a, i, n);
}
}
? 如果僅從代碼上直觀觀察,會得出構造二叉堆的時間復雜度為\(O(nlogn)\)的結果,當然這個上界是正確的,但卻不是漸近界,可以觀察到,不同結點在運行 heapify 的時間與該結點的樹高(樹高是指該結點到最底層葉子結點的值,不要和深度搞混了)相關,而且大部分結點的高度都很小,利用以下性質可以得到一個更準確的漸近界:
- 一個高度為 \(h\) 含有 \(n\) 個元素的堆,有 \(h=\lfloor logn\rfloor\) ,最多包含 \(\lceil \frac{n}{2^{k+1}} \rceil\) 高度為 \(k\) 的結點
【可以畫顆樹試一下,具體證明請看演算法導論】
在一個高度為 \(h\) 的結點上運行 heapify 的代價為 \(O(h)\),我們可以將自頂向下建堆的總復雜度表示為
這個式子
\[\sum ^{h} _{k=0}\frac {k}{2^{k}} \]其實就是求前 \(n\) 項和,高中數學的知識
\[T(k)=\frac{1}{2}+\frac{2}{2^2}+\frac{3}{2^3}+\cdots+\frac{k}{2^k}\\\frac{1}{2}T(k)=\frac{1}{2^2}+\frac{2}{2^3}+\frac{3}{2^4}+\cdots+\frac{k-1}{2^k}+\frac{k}{2^k+1}\\T(k)-\frac{1}{2}T(k)=\frac{1}{2}+\frac{1}{2^2}+\frac{1}{2^3}+\cdots+\frac{1}{2^k}-\frac{k}{2^{k+1}}\\\frac{1}{2}T(k)=\frac{\frac{1}{2}(1-(\frac{1}{2})^k)}{1-\frac{1}{2}}-\frac{k}{2^{k+1}}\\T(k)=2-\frac{1}{2^{k-1}}-\frac{k}{2^{k}} \]到這兒就需要求極限,高等數學的知識 \(\frac{1}{2^{k-1}}\) 當 \(k\) 趨于無窮大時極限是 \(0\),對 \(\frac{k}{2^{k}}\) 用洛必達法則極限也是 \(0\)
也就是說當 \(h\) 趨向于無窮大時,\(O(n\sum ^{h} _{k=0}\frac {k}{2^{k}})=O(n\cdot 2)\) ,去掉常數項,所以自底向上建堆復雜度為 \(O(n)\)
堆排序
堆排序的思想:假設一個大根堆有 \(n\) 個元素,每次把第 \(1\) 個元素,與第 \(n\) 個元素交換,對第一個元素進行向下調整(heapify),并使得 \(n=n-1\) ,直到 \(n=1\)
void heapSort(int* arr, int n) {
//先自底向上建堆
int i = n / 2;
for (; i >= 1; i--) {
heapify(arr, i, n);
}
for (int i = 50; i > 1; i--) {
swap(arr[1], arr[i]);
heapify(arr, 1, i - 1);
}
}
例題
尋找第K大元素
首先用陣列的前k個元素構建一個小根堆,然后遍歷剩余陣列和堆頂比較,如果當前元素大于堆頂,則把當前元素放在堆頂位置,并調整堆(heapify),遍歷結束后,堆頂就是陣列的最大k個元素中的最小值,也就是第k大元素,
void heapify(int* a, int index, int length) {
int left = index * 2 + 1;
while (left <= length) {
if (left + 1 <= length - 1 && a[left + 1] > a[left])left++;
if (a[index] > a[left])break;
swap(a[index], a[left]);
index = left;
}
}
void ArrayToBheap(int* a, int length) {
int i = length / 2 - 1;
for (; i >= 0; i--) {
heapify(a, i, length);
}
}
void FindKMax(int* a, int k, int length) {
ArrayToBheap(a, k);
for (int i = k; i < length; i++) {
if (a[i] > a[0]) a[0] = a[i];
heapify(a, 0, k);
}
}
時間復雜度\(O(n)\),只是舉個例子,
事實上對于這個問題是有更快的做法的,快速排序的思想,時間復雜度 \(O(logn)\)
int Search_K(int left, int right, int k) {
int i = left, j = right;
int p = rand() % (right - left + 1) + left;
int sign = a[p];
swap(a[p], a[i]);
while (i < j) {
while (i < j && a[j] >= sign)j--;
while (i < j && a[i] <= sign)i++;
swap(a[i], a[j]);
}
swap(a[i], a[left]);
if (i - left + 1 == k)return a[i];
if (i - left + 1 < k)return Search_K(i + 1, right, k - (i - left + 1));
else return Search_K(left, i - 1, k);
}
堆更多時候,因為它建堆\(O(n)\),調整\(O(logn)\),當需要有序得到某些資料,是要優于排序(\(O(nlogn)\))演算法的,而且如果資料規模是動態增加的,那堆就要完全優于排序演算法了,在C++的STL是有堆的實作的,叫做 priority_queue ,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/128440.html
標籤:其他
上一篇:HDU 1875 暢通工程再續
下一篇:如何構建虛樹