分類演算法之邏輯回歸(Logistic Regression)
1.二分類問題
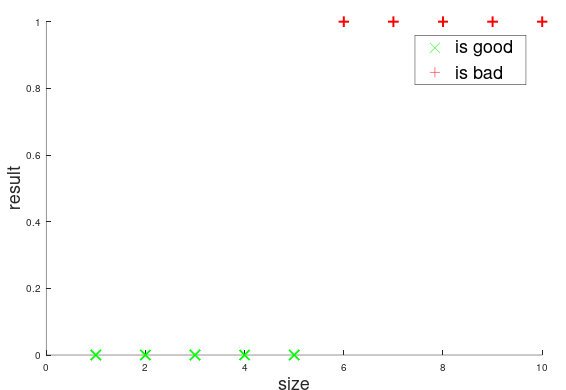
現在有一家醫院,想要對病人的病情進行分析,其中有一項就是關于良性\惡性腫瘤的判斷,現在有一批資料集是關于腫瘤大小的,任務就是根據腫瘤的大小來判定是良性還是惡性,這就是一個很典型的二分類問題,即輸出的結果只有兩個值----良性和惡性(通常用數字0和1表示),如圖1所示,我們可以做一個直觀的判定腫瘤大小大于5,即為惡心腫瘤(輸出為1);小于等于5,即為良性腫瘤(輸出為0),
2.分類問題的本質
分類問題本質上屬于有監督學習,給定一個已知分類的資料集,然后通過分類演算法來讓計算機對資料集進行學習,這樣計算機就可以對資料進行預測,以腫瘤的例子來說,已有資料集如圖1所示,現在要對一個病人的病情進行診斷,那么計算機只需要將該病人的腫瘤大小和5進行比較,然后就可以推斷出是惡性還是良性,分類問題和回歸問題有一定的相似性,都是通過對資料集的學習來對未知結果進行預測,區別在于輸出值不同,回歸問題的輸出值是連續值(例如房子的價格),分類問題的輸出值是離散值(例如惡性或者良性),既然分類問題和回歸問題有一定的相似性,那么我們能不能在回歸的基礎上進行分類呢?答案是可以的,一種可行的思路是,先用線性擬合,然后對線性擬合的預測結果值進行量化,即將連續值量化為離散值,
3.分類問題的假設函式
分類問題雖然和回歸問題有一定的類似,但是我們并不能直接使用回歸問題中的假設函式作為分類問題的假設函式,還是以圖1的例子為例,如果我們采用一元線性函式(即\(h(x) = \theta_0+\theta_1x\))去進行擬合的話,結果可能是這樣子的:$h_\theta(x) = \dfrac{5}{33}x-\frac{1}{3} $,體現在圖片中就是:
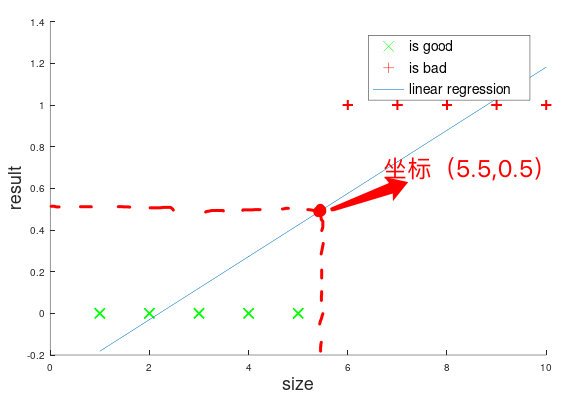
這樣,你可能會做這樣的一個判斷:對于這個線性擬合的假設函式,給定一個腫瘤的大小,只要將其帶入假設函式,并將其輸出值和0.5進行比較,如果大于0.5,就輸出1;小于0.5,就輸出0,在圖1的資料集中,這種方法確實可以,但是如果將資料集更改一下,如圖3所示,此時線性擬合的結果就會有所不同:
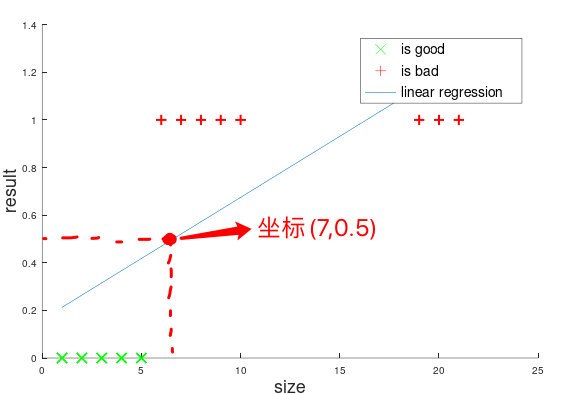
如果采用相同的方法,那么就會把大小為6的情況進行誤判為良好,所以,我們不能單純地通過將線性擬合的輸出值與某一個閾值進行比較這種方式來進行量化,對于邏輯回歸,我們的量化函式為Sigmoid函式(也稱Logistic函式,S函式),其數學運算式為:\(S(x) = \dfrac{1}{1+e^{-x}}\) ,其影像如圖4:
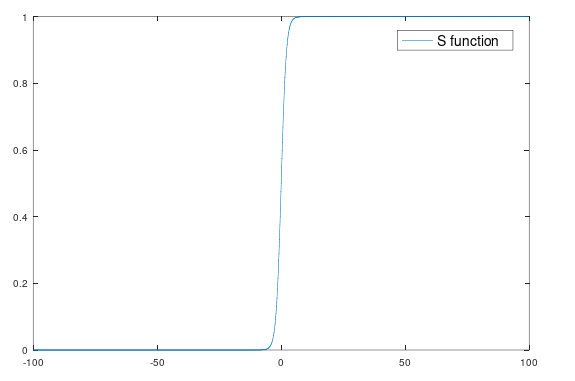
可以看到S函式的輸出值就是0和1,在邏輯回歸中,我們采用S函式來對線性擬合的輸出值進行量化,所以邏輯回歸的假設函式為:
\[h_\theta(x)=\dfrac{1}{1+e^{-\theta^Tx}}=\dfrac{1}{1+e^{-\sum_{i=0}^n\theta_ix_i}} \tag{3.1} \]其中,\(x\)為增廣特征向量(1*(n+1)維),\(\theta\)為增廣權向量(1*(n+1)維),這個假設函式所表示的數學含義是:對于特定的樣本\(x\)與引數矩陣\(\theta\),分類為1的概率(假設y只有0和1兩類),也就即\(h_\theta(x) = P(y=1|x;\theta)\),根據其數學意義,我們可以這樣認為:如果\(h_\theta(x)>0.5\),則判定y = 1;如果\(h_\theta(x)<0.5\),則判定y = 0,
4.邏輯回歸的代價函式(Cost Function)
代價函式(成本函式),也就是損失函式,在邏輯回歸中,代價函式并不是采用均方誤差(主要原因是,邏輯回歸的均方誤差并不是一個凸函式,并不方便使用梯度下降法),而是通過極大似然法求解出來的一個函式,其數學運算式為:
\[J(\theta)= \dfrac{1}{m}\sum_{i=1}^m[-yln(h_\theta(x))-(1-y)ln(1-h_\theta(x))] \tag{4.1} \]這個函式看起來有點復雜,我們將它一步步進行拆分來理解,我們將每個樣本點與假設函式之間的誤差記為\(Cost(h_\theta(x),y)=-yln(h_\theta(x))-(1-y)ln(1-h_\theta(x))\),這樣代價函式就可以理解為誤差的均值,下面我們再詳細看一下這個誤差函式,由于y的取值只能是0或者1,我們可以將誤差函式寫成分段函式的形式:
\[Cost(h_\theta(x),y)=\begin{cases} -ln(h_\theta(x)),\quad &y = 1 \\ -(1-y)ln(1-h_\theta(x)), &y=0 \end{cases} \tag{4.2} \]4.2式和4.1式是等價的,依據4.2式,不難得出:當y=1時,如果判定為y=1(即\(h_\theta(x) = 1\)),誤差為0;如果誤判為y=0(\(即h_\theta(x) = 0\)),誤差將會是正無窮大,當y=0時,如果判定為y=0(即\(h_\theta(x) = 0\)),誤差為0;如果誤判為y=1(即\(h_\theta(x) = 1\)),誤差將會是正無窮大,(注意:\(h_\theta(x) = 1\)表示y等于1的概率為1,等價于認為y=1;\(h_\theta(x) = 0\)表示y等于1的概率為0,等價于認為y=0)
如果用矩陣來表示代價函式,就是:
\[J(\theta)=-\dfrac{1}{m}Y^Tln(h_\theta(X))-(E-Y)^Tln(E-h_\theta(X)) \tag{4.3} \]其中\(Y\)為樣本真實值組成的列向量(m*1維),\(X\)為增廣樣本矩陣((1+n)*m維),E為全1列向量(m*1維),
5.邏輯回歸使用梯度下降法
邏輯回歸的代價函式和線性回歸的損失函式一樣,都是凸函式,所以我們可以采用梯度下降法來求引數矩陣\(\theta\)使得代價函式\(J(\theta)\)取得最小值,其具體演算法與線性回歸中的梯度下降法(可以參考我的另一篇博客線性回歸之梯度下降法)并沒有太大區別,只是對應的偏導有所不同,邏輯回歸的代價函式的偏導為:
\[\dfrac{\partial J(\theta)}{\theta_i} = \dfrac{1}{m}\sum_{j=1}^m(h_\theta(x^{(j)})-y^{(j)})x_i^{(j)} = \dfrac{1}{m}\sum_{j=1}^m(\dfrac{1}{1+e^{-\sum_{i=0}^n\theta_ix_i^{(j)}}}-y^{(j)})x_i^{(j)}\quad (i=0,1,\dots,n)\tag{5.1} \]對應的引數更新規則為:
\[\theta_i = \theta_i-\alpha\dfrac{\partial J(\theta)}{\theta_i} = \theta_i-\alpha\dfrac{1}{m}\sum_{j=1}^m(h_\theta(x^{(j)})-y^{(j)})x_i^{(j)}\quad (i=0,1,\dots,n)\tag{5.2} \]如果用矩陣表示就是:
\[\dfrac{\partial J(\theta)}{\theta} = \dfrac{1}{m}X^T(h_\theta(X)-Y),\quad \theta=\theta-\alpha\dfrac{1}{m}X^T(h_\theta(X)-Y) \tag{5.3} \]其中,\(\alpha\)為迭代步長,
6.多元邏輯回歸
對于多元邏輯回歸,一種可行的思路是將其簡化為二元,例如,如果資料集的分類包含1,2,3這三個類別,如果現在要判斷一個樣本是不是類1,我們可以將資料集看作是兩類----即1類和非1類(將類2和類3),這樣我們就可以求得針對類1的假設函式\(h^{(1)}_\theta(x)\),同理還有\(h^{(2)}_\theta(x)\)和\(h^{(3)}_\theta(x)\),這樣我們的判定規則就變為:
\[if \quad max\{h^{(i)}_\theta(x)\} = h^{(j)}_\theta(x), then \quad y = j\quad(i,j=1,2,3) \tag{6.1} \]7.小結
雖然邏輯回歸中帶有“回歸”二字,但其實它是一個分類演算法,邏輯回歸的思想和模式識別中的判別函式非常相似,兩者可以結合起來進行學習,
參考鏈接:
邏輯回歸原理小結
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/128444.html
標籤:其他
上一篇:如何構建虛樹
下一篇:資料結構篇——并查集