情景
有一張表,里面是學生及其對應課程的成績,要查出大于學生的所有課程平均值的課程,
表的結構

解決方法
我想到兩種sql,如下
第一種
查出每個學生對應的 平均值再與原表連接,然后查詢條件就比較該課程成績分數和平均值
select t1.student_id,course_id
from t_mark t1,
(
SELECT student_id,AVG(mark) avg
from
t_mark
group by student_id
) t2
where t1.student_id = t2.student_id
and t1.mark > t2.avg
第二種
每次在查詢條件使用子查詢查出該學生的課程平均值比較
select t1.student_id,course_id
from t_mark t1
where t1.mark>
(select AVG(mark)
from t_mark t2
where t2. student_id = t1.student_id)
比較兩種sql
填充資料
為了有足夠資料進行比較,寫一個存盤程序給3000個學生插入3條成績資料
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_to_mark`()
BEGIN
#Routine body goes here...
DECLARE i INTEGER;
SET i = 1;
WHILE i<=3000 DO
INSERT INTO t_mark
(student_id,course_id,mark)
VALUES
(i,1,RAND()*70+30),
(i,2,RAND()*70+30),
(i,3,RAND()*70+30);
set i = i+1;
END WHILE;
END
插入成功
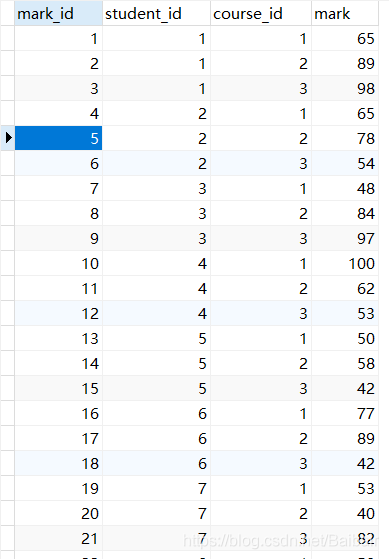
查詢比較
第一種
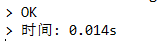
第二種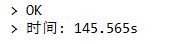
差距相當大,通過執行計劃,看到第二個子查詢是一個相關子查詢(DEPENDENT SUBQUERY),第二個sql子查詢中的引數是需要依賴外部查詢,因此會對每個student_id 執行一次子查詢,資料大時效率很低,
結論
還是使用第一種比較好,不知是否有更高效的查詢sql歡迎評論 ~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/128500.html
標籤:AI
上一篇:關于達夢DM8資料庫的引數修改