一個才接觸爬蟲的小白 想請教一下大佬們,為什么我根據書上的代碼寫出來的Spider爬取不到任何資料。
結果如下:
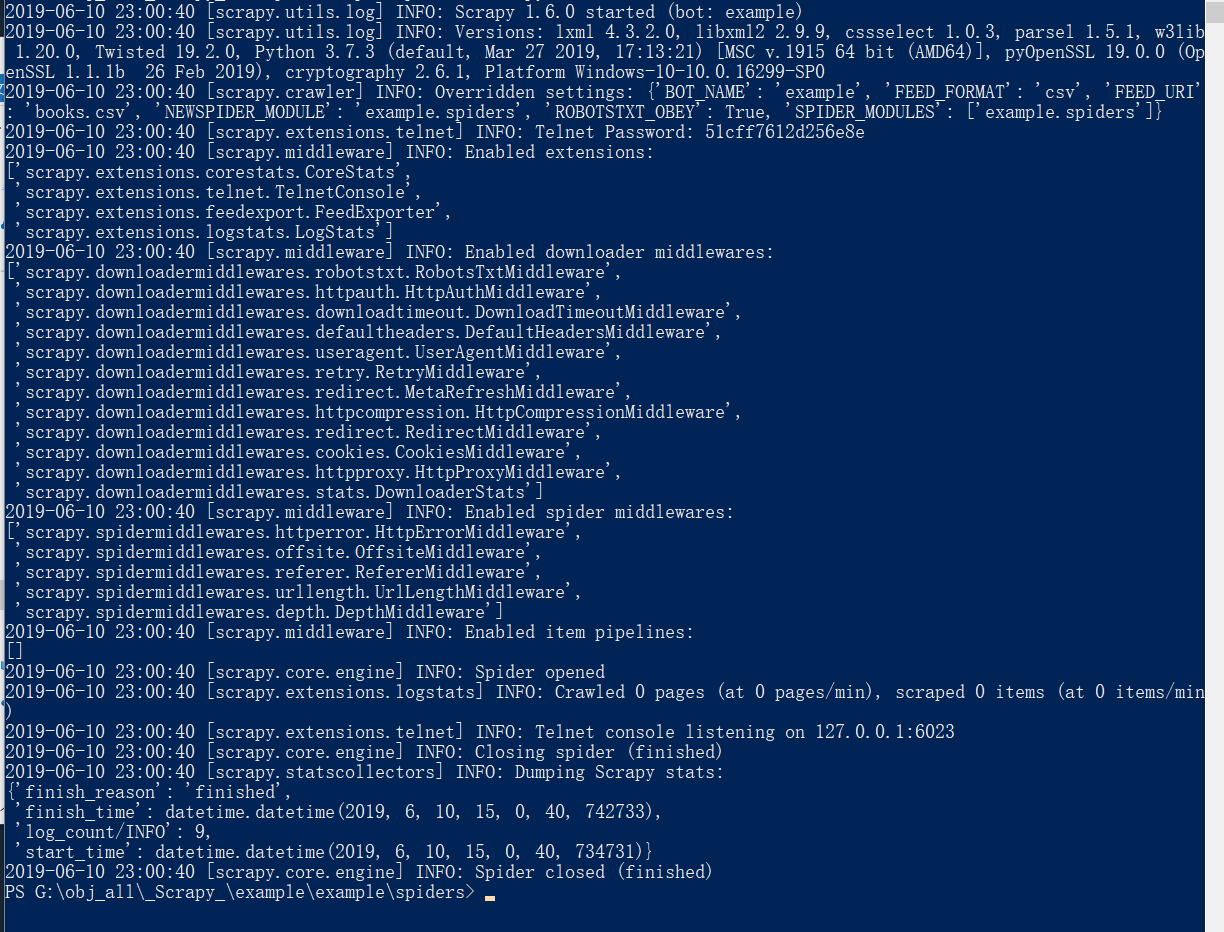
代碼如下:
# -*- coding:utf-8 -*-
import scrapy
class BookSpider(scrapy.Spider):
#每一個爬蟲的唯一標識
name = "books"
#定義爬蟲爬取的起始點,起始點可以是多個,這里只有一個
start_url = ['http://books.toscrape.com/']
def parse(self, response):
#提取資料
#每一本書的資料再<"article.product_pod">中,我們使用 css()方法找到所在這樣的article元素,并依次迭代
for book in response.css('article.product_pod'):
#書名資訊在article>h3>a元素的title屬性里
#例如:<a title = "A Light in the Attic">A Light in the...</a>
name = book.xpath('./h3/a/@title').extract_first()
#書價資訊在<p class="price_color">的TEXT中
#例如:<p class="price_color">¥51.77</p>
price = book.css('p.price_color::text').extract_first()
yield {
'name': name,
'price': price,
}
#提取鏈接
#下一頁的url在url.pager>li.next>a里面
#例如:<li class ="next"><href = "catalogue/page-2.html">next</a></li>
next_url = response.css('url.pager li.next a::attr(href)').extract_first()
if next_url:
#如果找到下一頁的URL,得到絕對路徑,構造新的Request物件
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse)
PS:書上的另外幾個例子也是這樣 爬取不到任何結果 多次核對代碼沒有發現錯誤,大佬們幫我看看是不是我安裝的Scrapy框架有問題,或者是其他什么原因,感謝各位大佬了(爬取網址:http://books.toscrape.com/)
uj5u.com熱心網友回復:
從代碼看這只是其中的spider部分,你的pipeline,item和settings檔案都有設定或是寫內容嗎,尤其是pipeline和items里。看你現在的spider里沒有對name和price 進行列印,那么yield后有在pipeline中接收和保存嗎,這些先都檢查一下再試試看。可以在yield前對name和price先列印一下看看有沒有結果
uj5u.com熱心網友回復:
沒有設定,書上的例子就只是撰寫了spider部分,其他部分沒有涉及。uj5u.com熱心網友回復:
沒有設定,書上的例子就只是撰寫了spider部分,其他部分沒有涉及。
uj5u.com熱心網友回復:
那就對了,其實資料可能已經抓取到了,只是沒有對結果做任何輸出也沒有任何保存操作,所以看不到結果。
你可以先在yield前print一下name和price看一下結果
也可以參考一下下面的菜鳥教程連接,把其它部分完善一下。
https://www.runoob.com/w3cnote/scrapy-detail.html
uj5u.com熱心網友回復:
print了 沒用啊但是...items也想那篇文章里面設定了,還是一樣的結果,枯遼。uj5u.com熱心網友回復:
print了 沒用啊但是...items也想那篇文章里面設定了,還是一樣的結果,枯遼。
uj5u.com熱心網友回復:
大佬們,求解答,都這么簡單的代碼了,還抓取不到資料,是哪里的問題呢?# -*- coding: utf-8 -*-
import scrapy
class Itcast1000Spider(scrapy.Spider):
name = 'itcast1000'
allowed_domains = ['itcast.com']
start_urls = ['http://itcast.cn/']
def parse(self, response):
content = response.xpath("/html/head/title/text()")
title = content.extract_first()
print(title)
uj5u.com熱心網友回復:
兄弟你解決了嗎uj5u.com熱心網友回復:
-----------------------
allowed_domains = ['itcast.com']
start_urls = ['http://itcast.cn/']
-----------------------
修改allowed_domains = ['itcast.cn']
兩者的域要一致
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/128846.html
上一篇:[爬蟲,scrapy]:scrapy下的yield scrapy.Request()無回應的問題
下一篇:矩形覆寫