洛谷 P1377 [TJOI2011]樹的序 (單調佇列優化建BST
鏈接
題意分析
本題思路很簡單,根據題意,我們利用所給的Bst生成序將Bst建立起來,然后輸出該BST的先序遍歷即可;
但,如果我們不加優化,建BST的時間復雜度在最劣情況下將達到O(n^2),顯然,在1e5的資料下是過不去的,所以我們考慮利用利用單調佇列優化來建BST;
演算法思路
BST建樹本質上便是按照權值將新加入節點插入到對應的位置,該程序受插入順序
影響
我們考慮可以將讀入的生成序列的下標變成權值,本身權值變為下標
for(int i=1;i<=n;i++){
x=read();
a[x]=i;
}
因為權值為1-n的序列,我們將該陣列從1-n遍歷,本質便是按權值從小到大遍歷(如
果權值不是1-n的序列,將其離散化即可)
我們按該方式維護一個單調佇列,當一個新數進佇列后不在向前更新時,我們便將
該節點插到單調佇列中它左側節點的右子樹中,原因很簡單,該節點左側的節點先
入佇列,說明左側權值一定比該節點小,故將該點插入到左側節點的右子樹上,假設
該節點進佇列程序中壓掉了節點,則將該節點插入到被它壓掉的最后一個節點的左
子樹上,我們用此方法便可以在O(n)的時間復雜度下建成一顆bst了,建樹代碼如下
int tot=0;
int pos=0;
for(int i=1;i<=n;i++){
tot=pos;
while(pos&&a[q[pos]]>a[i]){
pos--;
}
if(pos){
r[q[pos]]=i;
}
if(pos<tot){
l[i]=q[pos+1];
}
q[tot=++pos]=i;
}
為什這樣建樹可以建出正確的bst呢?
我們舉個例子
比如3 2 4 1這個序列
排序后變為了1(4) 2(2) 3(1) 4(3)
括號內為權值,括號外為下標
第一步,插入1(4)
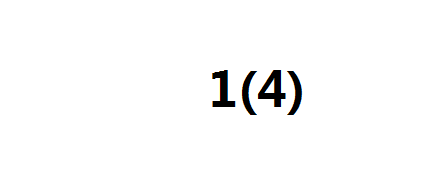
第二步,插入2(2)因為在單調佇列中我們將其壓掉了所以,將1(4)a插入到2(2)的左子樹中
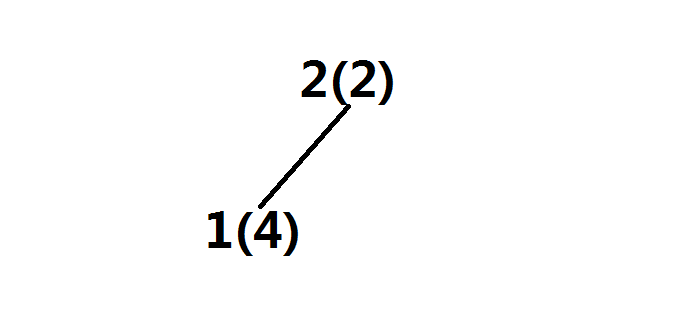
第三步
同理
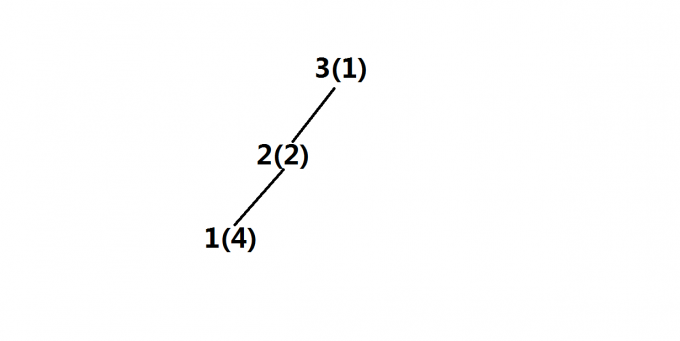
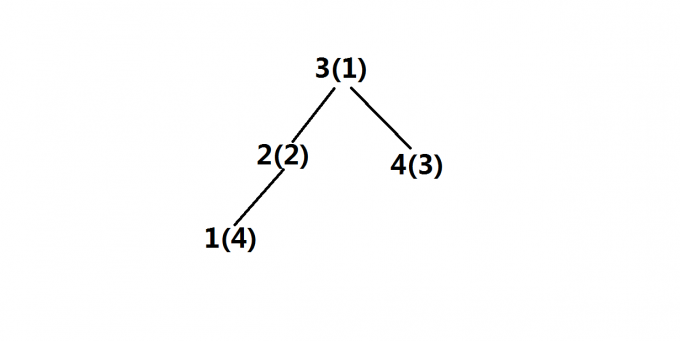
第四步,目前單調佇列中只有3(1)新點4(3)進入后無法壓掉3(1)便放在3(1)的左子樹中
建樹完畢,我們按權值加入,每進入一個點便插入到目前的合適位置,當更優的點
出現時,倘若恰好將此點壓掉,我們便將上一個點與該點的連接關系斷開,將新節
點插入到這兩個節點之間,如下圖
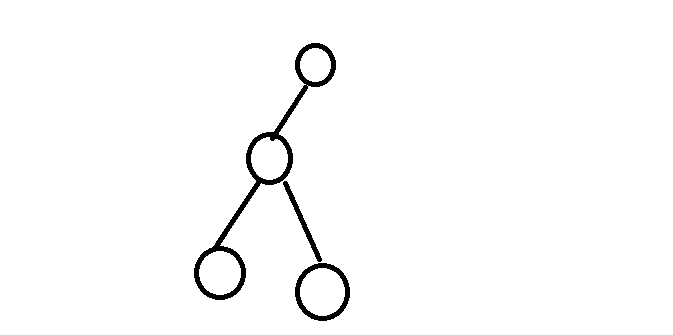
紅色為新加入節點
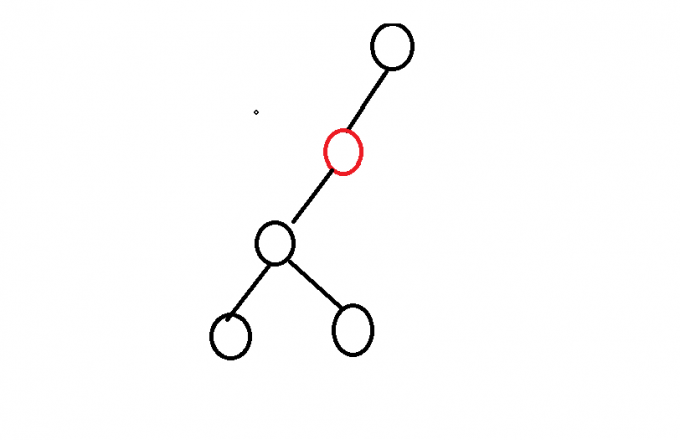
為什么后續加入的節點不會插到以經壓入的節點下呢?得益于我們加入節點是按權值從小到大加入的
比如說上圖,既然紅色節點已經入佇列了,能紅色節點的子樹中插入的節點一定小于紅色節點的權值,但已經沒有了
這就是整個演算法的思路
完整代碼如下
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<algorithm>
using namespace std;
const int maxn=1e6+10;
inline int read(){
int ret=0;
int f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-'){
f=-f;
}
ch=getchar();
}
while(ch>='0'&&ch<='9'){
ret=ret*10+(ch^'0');
ch=getchar();
}
return ret*f;
}
int q[maxn];
int l[maxn];
int r[maxn];
int a[maxn];
int n;
void dfs(int ro){
if(!ro){
return ;
}
cout<<ro<<" ";
dfs(l[ro]);
dfs(r[ro]);
return ;
}
int main(){
n=read();
int x;
for(int i=1;i<=n;i++){
x=read();
a[x]=i;
}
int tot=0;
int pos=0;
for(int i=1;i<=n;i++){
tot=pos;
while(pos&&a[q[pos]]>a[i]){
pos--;
}
if(pos){
r[q[pos]]=i;
}
if(pos<tot){
l[i]=q[pos+1];
}
q[tot=++pos]=i;
}
dfs(q[1]);
return 0;
}
完結撒花!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/128849.html
標籤:其他