作者|SUNIL RAY
編譯|Flin
來源|analyticsvidhya
介紹
如果你要問我機器學習中2種最直觀的演算法——那就是k最近鄰(kNN)和基于樹的演算法,兩者都易于理解,易于解釋,并且很容易向人們展示,有趣的是,上個月我們對這兩種演算法進行了技能測驗,
如果你不熟悉機器學習,請確保在了解這兩種演算法的基礎上進行測驗,它們雖然簡單,但是功能強大,并且在工業中得到廣泛使用,此技能測驗將幫助你在k最近鄰演算法上進行自我測驗,它是專為你測驗有關kNN及其應用程式的知識而設計的,
超過650人注冊了該測驗,如果你是錯過這項技能測驗的人之一,那么這篇文章是測驗問題和解決方案,這是參加考試的參與者的排行榜,
- https://datahack.analyticsvidhya.com/contest/skilltest-k-nearest-neighbor-knn/#LeaderBoard
有用的資源
這里有一些資源可以深入了解該主題,
- 機器學習演算法的基本知識(帶有Python和R代碼):R語言進行Logistic回歸的簡單指南
- https://www.analyticsvidhya.com/blog/2017/09/common-machine-learning-algorithms/
- K-最近鄰(kNN)演算法
- https://www.analyticsvidhya.com/blog/2018/03/introduction-k-neighbours-algorithm-clustering/
技能測驗問答
1) k-NN演算法在測驗時間而不是訓練時間上進行了更多的計算,
A)真
B)假
解決方案:A
該演算法的訓練階段僅包括存盤訓練樣本的特征向量和類別標簽,
在測驗階段,通過分配最接近該查詢點的k個訓練樣本中最頻繁使用的標簽來對測驗點進行分類——因此需要更高的計算量,
2)假設你使用的演算法是k最近鄰演算法,在下面的影像中,____將是k的最佳值,
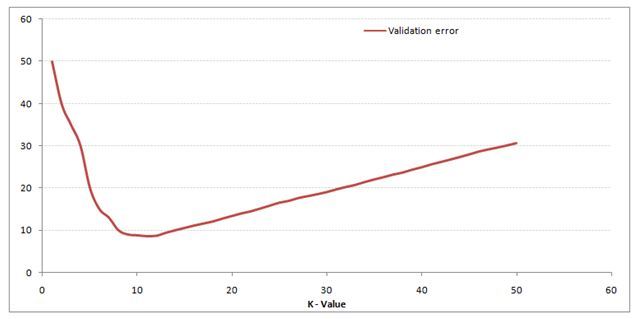
A) 3
B) 10
C) 20
D) 50
解決方案:B
當k的值為10時,驗證誤差最小,
3)在k-NN中不能使用以下哪個距離度量?
A) Manhattan
B) Minkowski
C) Tanimoto
D) Jaccard
E) Mahalanobis
F)都可以使用
解決方案:F
所有這些距離度量都可以用作k-NN的距離度量,
4)關于k-NN演算法,以下哪個選項是正確的?
A)可用于分類
B)可用于回歸
C)可用于分類和回歸
解決方案:C
我們還可以將k-NN用于回歸問題,在這種情況下,預測可以基于k個最相似實體的均值或中位數,
5)關于k-NN演算法,以下哪個陳述是正確的?
- 如果所有資料的比例均相同,則k-NN的效果會更好
- k-NN在少數輸入變數(p)下作業良好,但在輸入數量很大時會遇到困難
- k-NN對所解決問題的函式形式沒有任何假設
A)1和2
B)1和3
C)僅1
D)以上所有
解決方案:D
以上陳述是kNN演算法的假設
6)下列哪種機器學習演算法可用于估算分類變數和連續變數的缺失值?
A)K-NN
B)線性回歸
C)Logistic回歸
解決方案:A
k-NN演算法可用于估算分類變數和連續變數的缺失值,
7)關于曼哈頓距離,以下哪項是正確的?
A)可用于連續變數
B)可用于分類變數
C)可用于分類變數和連續變數
D)無
解決方案:A
曼哈頓距離是為計算實際值特征之間的距離而設計的,
8)對于k-NN中的分類變數,我們使用以下哪個距離度量?
- 漢明距離
- 歐氏距離
- 曼哈頓距離
A)1
B)2
C)3
D)1和2
E)2和3
F)1,2和3
解決方案:A
在連續變數的情況下使用歐氏距離和曼哈頓距離,而在分類變數的情況下使用漢明距離,
9)以下哪個是兩個資料點A(1,3)和B(2,3)之間的歐幾里得距離?
A)1
B)2
C)4
D)8
解決方案:A
sqrt((1-2)^ 2 +(3-3)^ 2)= sqrt(1 ^ 2 + 0 ^ 2)= 1
10)以下哪個是兩個資料點A(1,3)和B(2,3)之間的曼哈頓距離?
A)1
B)2
C)4
D)8
解決方案:A
sqrt(mod((1-2))+ mod((3-3)))= sqrt(1 + 0)= 1
內容:11-12
假設你給出了以下資料,其中x和y是2個輸入變數,而Class是因變數,

以下是散點圖,顯示了2D空間中的上述資料,
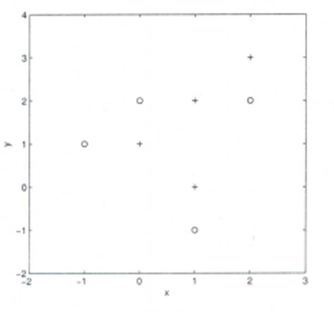
11)假設你要使用3-NN中的歐氏距離來預測新資料點x = 1和y = 1的類別,該資料點屬于哪個類別?
A)+ 類
B)– 類
C)不能判斷
D)這些都不是
解決方案:A
所有三個最近點均為 + 類,因此此點將歸為+ 類,
12)在上一個問題中,你現在要使用7-NN而不是3-KNN,以下x = 1和y = 1屬于哪一個?
A)+ 類
B)– 類
C)不能判斷
解決方案:B
現在,此點將歸類為 – 類,因為在最近的圓圈中有4個 – 類點和3個 + 類點,
內容13-14:
假設你提供了以下2類資料,其中“+”代表正類,“-”代表負類,
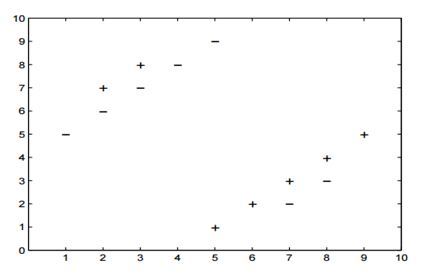
13)k-NN中k的以下哪個k值會最小化留一法交叉驗證的準確性?
A)3
B)5
C)兩者都相同
D)沒有一個
解決方案:B
5-NN將至少留下一個交叉驗證錯誤,
14)以下哪一項是k = 5時不進行交叉驗證的準確性?
A)2/14
B)4/14
C)6/14
D)8/14
E)以上都不是
解決方案:E
在5-NN中,我們將有10/14的交叉驗證精度,
15)關于k-NN中的k,根據偏差,以下哪一項是正確的?
A)當你增加k時,偏差會增加
B)當你減少k時,偏差會增加
C)不能判斷
D)這些都不是
解決方案:A
大K表示簡單模型,簡單模型始終被視為高偏差
16)關于方差k-NN中的k,以下哪一項是正確的?
A)當你增加k時,方差會增加
B)當你減少k時,方差會增加
C)不能判斷
D)這些都不是
解決方案:B
簡單模型將被視為方差較小模型
17)以下兩個距離(歐幾里得距離和曼哈頓距離)已經給出,我們通常在K-NN演算法中使用這兩個距離,這些距離在點A(x1,y1)和點B(x2,Y2)之間,
你的任務是通過查看以下兩個圖形來標記兩個距離,關于下圖,以下哪個選項是正確的?

A)左為曼哈頓距離,右為歐幾里得距離
B)左為歐幾里得距離,右為曼哈頓距離
C)左或右都不是曼哈頓距離
D)左或右都不是歐幾里得距離
解決方案:B
左圖是歐幾里得距離的作業原理,右圖是曼哈頓距離,
18)當你在資料中發現噪聲時,你將在k-NN中考慮以下哪個選項?
A)我將增加k的值
B)我將減少k的值
C)噪聲不能取決于k
D)這些都不是
解決方案:A
為了確保你進行的分類,你可以嘗試增加k的值,
19)在k-NN中,由于維數的存在,很可能過度擬合,你將考慮使用以下哪個選項來解決此問題?
- 降維
- 特征選擇
A)1
B)2
C)1和2
D)這些都不是
解決方案:C
在這種情況下,你可以使用降維演算法或特征選擇演算法
20)以下是兩個陳述,以下兩個陳述中哪一項是正確的?
- k-NN是一種基于記憶的方法,即分類器會在我們收集新的訓練資料時立即進行調整,
- 在最壞的情況下,新樣本分類的計算復雜度隨著訓練資料集中樣本數量的增加而線性增加,
A)1
B)2
C)1和2
D)這些都不是
解決方案:C
21)假設你給出了以下影像(左1,中2和右3),現在你的任務是在每個影像中找出k-NN的k值,其中k1代表第1個圖,k2代表第2個圖,k3是第3個圖,
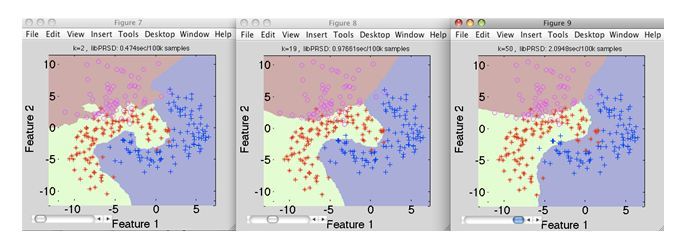
A)k1 > k2 > k3
B)k1 < k2
C)k1 = k2 = k3
D)這些都不是
解決方案:D
k值在k3中最高,而在k1中則最低
22)在下圖中,下列哪一個k值可以給出最低的留一法交叉驗證精度?
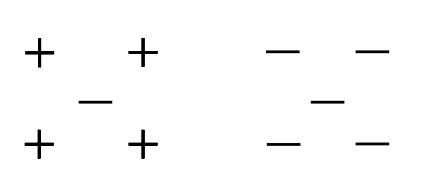
A)1
B)2
C)3
D)5
解決方案:B
如果將k的值保持為2,則交叉驗證的準確性最低,你可以自己嘗試,
23)一家公司建立了一個kNN分類器,該分類器在訓練資料上獲得100%的準確性,當他們在客戶端上部署此模型時,發現該模型根本不準確,以下哪項可能出錯了?
注意:模型已成功部署,除了模型性能外,在客戶端沒有發現任何技術問題
A)可能是模型過擬合
B)可能是模型未擬合
C)不能判斷
D)這些都不是
解決方案:A
在一個過擬合的模塊中,它似憾訓在訓練資料上表現良好,但它還不夠普遍,無法在新資料上給出相同的結果,
24)你給出了以下2條陳述句,發現在k-NN情況下哪個選項是正確的?
- 如果k的值非常大,我們可以將其他類別的點包括到鄰域中,
- 如果k的值太小,該演算法會對噪聲非常敏感
A)1
B)2
C)1和2
D)這些都不是
解決方案:C
這兩個選項都是正確的,并且都是不言而喻的,
25)對于k-NN分類器,以下哪個陳述是正確的?
A) k值越大,分類精度越好
B) k值越小,決策邊界越光滑
C) 決策邊界是線性的
D) k-NN不需要顯式的訓練步驟
解決方案:D
選項A:并非總是如此,你必須確保k的值不要太高或太低,
選項B:此陳述不正確,決策邊界可能有些參差不齊
選項C:與選項B相同
選項D:此說法正確
26)判斷題:可以使用1-NN分類器構造2-NN分類器嗎?
A)真
B)假
解決方案:A
你可以通過組合1-NN分類器來實作2-NN分類器
27)在k-NN中,增加/減少k值會發生什么?
A) K值越大,邊界越光滑
B) 隨著K值的減小,邊界變得更平滑
C) 邊界的光滑性與K值無關
D) 這些都不是
解決方案:A
通過增加K的值,決策邊界將變得更平滑
28)以下是針對k-NN演算法給出的兩條陳述,其中哪一條是真的?
- 我們可以借助交叉驗證來選擇k的最優值
- 歐氏距離對每個特征一視同仁
A)1
B)2
C)1和2
D)這些都不是
解決方案:C
兩種說法都是正確的
內容29-30:假設你已經訓練了一個k-NN模型,現在你想要對測驗資料進行預測,在獲得預測之前,假設你要計算k-NN用于預測測驗資料類別的時間,
注意:計算兩個觀測值之間的距離將花費時間D,
29)如果測驗資料中有N(非常大)的觀測值,則1-NN將花費多少時間?
A)N * D
B)N * D * 2
C)(N * D)/ 2
D)這些都不是
解決方案:A
N的值非常大,因此選項A是正確的
30)1-NN,2-NN,3-NN所花費的時間之間是什么關系,
A)1-NN > 2-NN > 3-NN
B)1-NN < 2-NN < 3-NN
C)1-NN ~ 2-NN ~ 3-NN
D)這些都不是
解決方案:C
在kNN演算法中,任何k值的訓練時間都是相同的,
總體分布
以下是參與者的分數分布:
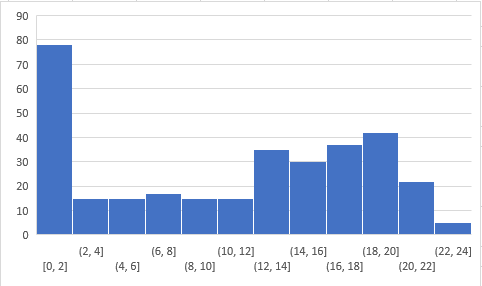
你可以在此處(https://datahack.analyticsvidhya.com/contest/skilltest-logistics-regression/#LeaderBoard) 訪問分數,超過250人參加了技能測驗,獲得的最高分是24,
原文鏈接:https://www.analyticsvidhya.com/blog/2017/09/30-questions-test-k-nearest-neighbors-algorithm/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/128862.html
標籤:其他