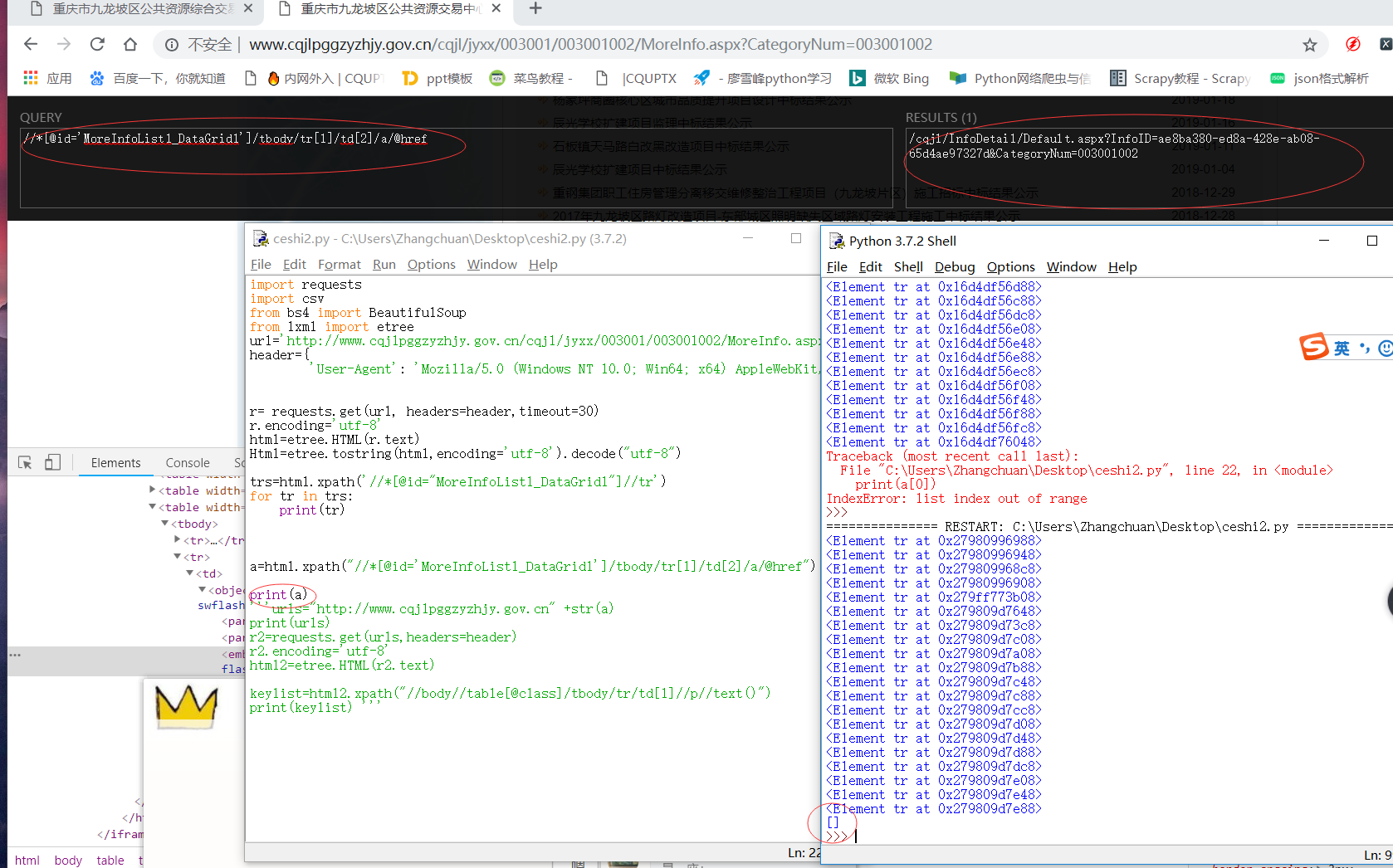
以下圖片是我寫的測驗:不知道為什么下面一個xapth取不到內容回傳的是一個空的串列
但是xpath是正確的啊,
這是全代碼,希望大佬指正
import requests
uj5u.com熱心網友回復:
愁了好久了 純粹自學沒人指點啊
uj5u.com熱心網友回復:
經過etree處理過的網頁結構標簽會變么?xpath跟原來瀏覽器上匹配的xpath不一樣了
uj5u.com熱心網友回復:
參考 樓主 chuan er的回復: 以下圖片是我寫的測驗:不知道為什么下面一個xapth取不到內容回傳的是一個空的串列 import requests
博主你的問題解決了嗎?遇到了跟博主相同的問題
uj5u.com熱心網友回復:
我知道xpath不要再瀏覽器上直接復制,尤其xpath中出現tbody的你需要洗掉,瀏覽器會規范這個html檔案,因此xpath中會出現莫名其妙的一些路徑,標簽,這跟程式獲得的html資源不一樣。
uj5u.com熱心網友回復:
參考 3 樓 qq_44305513 的回復: Quote: 參考 樓主 chuan er的回復: 以下圖片是我寫的測驗:不知道為什么下面一個xapth取不到內容回傳的是一個空的串列 import requests 不要直接復制xpath 自己寫
uj5u.com熱心網友回復:
我今天遇到差不多的問題,根據一個博主的提示,把“tbody”洗掉就運行成功了!
附上原博主網址 https://blog.csdn.net/qq_35425070/article/details/87697898
uj5u.com熱心網友回復:
我也有這樣的問題,和你的情況一樣
uj5u.com熱心網友回復:
參考 7 樓 jgdabc的回復: 我也有這樣的問題,和你的情況一樣
我知道xpath不要再瀏覽器上直接復制,尤其xpath中出現tbody的你需要洗掉,瀏覽器會規范這個html檔案,因此xpath中會出現莫名其妙的一些路徑,標簽,這跟程式獲得的html資源不一樣。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/13213.html
標籤:其他
上一篇:筆記本電腦出現問題
下一篇:Matlab2018a 安裝啟動出現這個問題failed to initialize Java