爬蟲結果運行不出來?這是為什么?這是什么反爬蟲?請大哥大姐指導~謝謝啦~
import requests
from bs4 import BeautifulSoup
headers = {
'origin': 'https://m.maizuo.com',
'referer': 'https://m.maizuo.com/v5/?co=mzmovie',
'user-agent': "Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0"}
url = 'https://m.maizuo.com/v5/?co=mzmovie#/films/nowPlaying'
#被解釋網址
res = requests.get(url,headers=headers)
#獲取資料
print(res.status_code)
#獲取網址的狀態
bs = BeautifulSoup(res.text,'html.parser')
#解釋資料
soups = bs.find_all(class_="nowPlayingFilm-item")
#查找class="nowPlayingFilm-item"所有這個類
for soup in soups:
movie_name = soup.find(class_="name")
print(movie_name)
uj5u.com熱心網友回復:
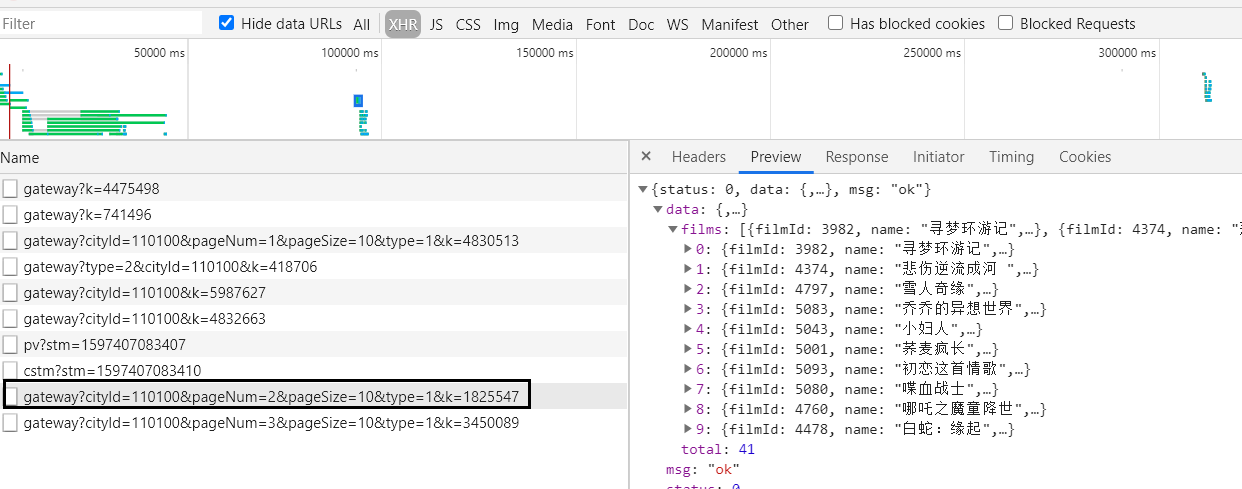
這只是普通的異步加載,意思就是先加載網頁框架,再加載資料填充,你只是獲取了最初始的資料。你應該關注如圖所示的請求。
并且,headers還遠遠不夠,直接從該網站把headers弄下來。
import requests
header = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Host': 'm.maizuo.com',
'Pragma': 'no-cache',
'Referer': 'https://m.maizuo.com/v5/?co=mzmovie',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'X-Client-Info': '{"a":"3000","ch":"1002","v":"5.0.4","e":"1597407020374774551281665","bc":"110100"}',
'X-Host': 'mall.film-ticket.film.list',
'X-Requested-With': 'XMLHttpRequest',
'X-Token': 'undefined',
}
url = 'https://m.maizuo.com/gateway?cityId=110100&pageNum=2&pageSize=10&type=1&k=1825547'
req = requests.get(url, headers=header)
print(req.content.decode('utf8'))
uj5u.com熱心網友回復:
效果如圖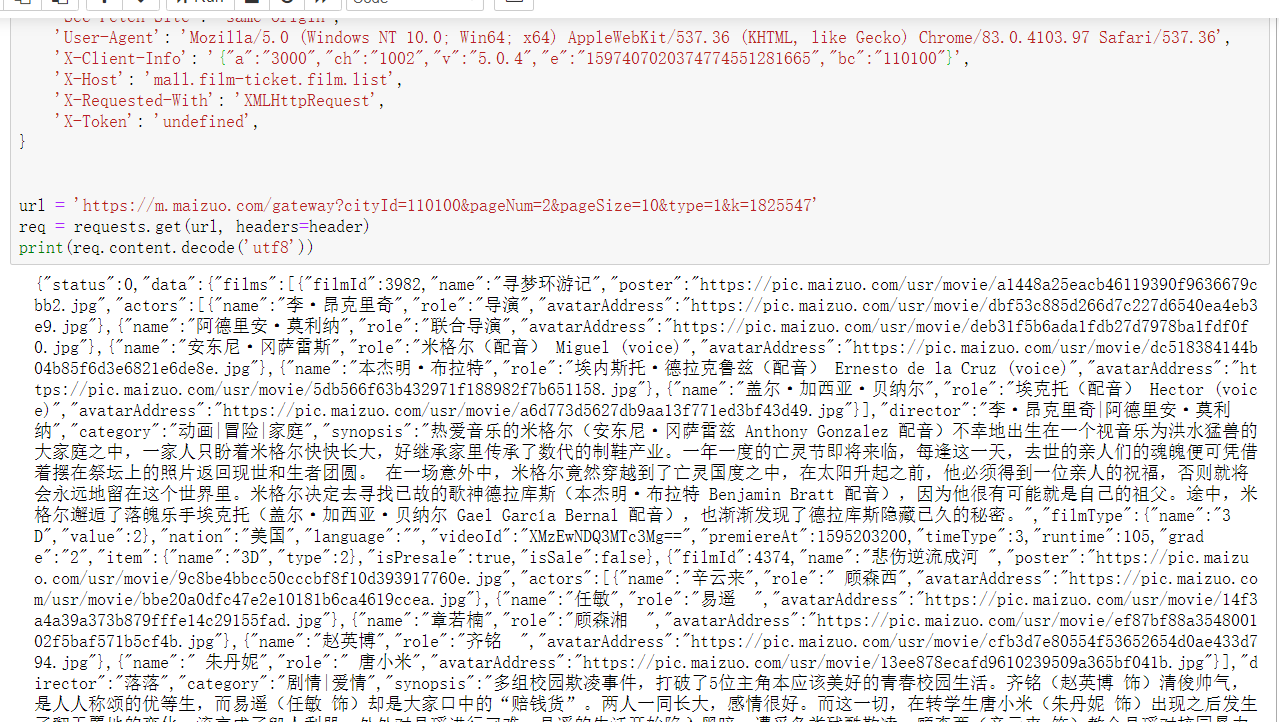
uj5u.com熱心網友回復:
感謝老哥,弄好啦uj5u.com熱心網友回復:
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import json
urls_1 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=1&pageSize=10&type=1&k=7899773'
urls_2 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=2&pageSize=10&type=1&k=1925194'
urls_3 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=3&pageSize=10&type=1&k=7338125'
urls_4 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=4&pageSize=10&type=1&k=979749'
urls_5 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=5&pageSize=10&type=1&k=3650839'
urls = [urls_1, urls_2, urls_3, urls_4, urls_5]
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'X-Client-Info': '{"a":"3000","ch":"1002","v":"5.0.4","e":"1597373545337880782209026","bc":"421100"}',
'X-Host': 'mall.film-ticket.film.list',
'X-Requested-With': 'XMLHttpRequest',
'X-Token': 'undefined'
}
for url in urls:
response = requests.get(url=url,headers=headers)
html = response.content.decode("utf-8")
page = json.loads(html)["data"]["films"]
for data in page:
film_name = data["name"]
if "actors" in data:
a = list()
for d in data["actors"]:
film_actor = d["name"] + "-" + d["role"]
a.append(film_actor)
film_info = data["synopsis"]
print("電影名稱:{},{},簡介:{}".format(film_name, a, film_info))
else:
film_actor = data["director"]
print("電影名稱:{},{},簡介:{}".format(film_name, film_actor, film_info))

我也弄出來了

uj5u.com熱心網友回復:
嗯,作業日每天掛著csdn,django、scrapy、requests、資料處理(re、xpath、BeautifulSoup)、PyQt5....各種亂七八糟的python問題歡迎邀請回答。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/13272.html