為啥結果是None~,請求幫助~
import requests
from bs4 import BeautifulSoup
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'DEVICE_ID=1597277947293599669387265; gr_user_id=1b21fbe6-1c03-4d9a-a924-835a3d1e6d7c; ac641e22637cd956_gr_last_sent_cs1=undefined; __secdyid=d7a86ea66fcaa4cd6ad69b9ab40e62f36764419b37d985d5021597277947; grwng_uid=0ebbdd43-a43e-429d-afd6-0c334debeda6; acw_tc=76b20fef15977077971756612e37a995a65eb44444b84cc7e26a5d8064351a; co=mzmovie; ac641e22637cd956_gr_session_id=6269cefa-9ba5-40c2-8f70-de7833d85f8a; ac641e22637cd956_gr_last_sent_sid_with_cs1=6269cefa-9ba5-40c2-8f70-de7833d85f8a; ac641e22637cd956_gr_cs1=undefined; ac641e22637cd956_gr_session_id_6269cefa-9ba5-40c2-8f70-de7833d85f8a=true; COOKIE_CITY_ID=110100; COOKIE_CITY_NAME=%E5%8C%97%E4%BA%AC; COOKIE_BUSINESS_CITY=110100; COOKIE_SERVICE_TIME=1597707858',
'Host': 'm.maizuo.com',
'Referer': 'https://m.maizuo.com/v5/?co=mzmovie',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': '#DingXin DX_2.3.0.42076/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.7) Gecko YHZ_Client_Test/2.3.0.42076',
'X-Client-Info': '{"a":"3000","ch":"1002","v":"5.0.4","e":"1597277947293599669387265","bc":"110100"}',
'X-Host': 'mall.film-ticket.film.list',
'X-Requested-With': 'XMLHttpRequest',
'X-Token': 'undefined',
}
res = requests.get('https://m.maizuo.com/v5/#/films/nowPlaying',headers=headers)
bs = BeautifulSoup(res.text,'html.parser')
movie_babai = bs.find(class_="nowPlayingFilm-item")
print(movie_babai)
為啥結果是None~,請求幫助~
uj5u.com熱心網友回復:
你不是發過了嗎,都說了你的url不對,這里面的url是異步加載的,也就是內容是點擊網頁之后內容是用css加載出來的,不是靜態的,所以獲取不到,需要從控制臺分析出最真實的urluj5u.com熱心網友回復:
代碼是這個,還沒刪
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import json
urls_1 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=1&pageSize=10&type=1&k=7899773'
urls_2 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=2&pageSize=10&type=1&k=1925194'
urls_3 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=3&pageSize=10&type=1&k=7338125'
urls_4 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=4&pageSize=10&type=1&k=979749'
urls_5 = 'https://m.maizuo.com/gateway?cityId=440300&pageNum=5&pageSize=10&type=1&k=3650839'
urls = [urls_1, urls_2, urls_3, urls_4, urls_5]
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'X-Client-Info': '{"a":"3000","ch":"1002","v":"5.0.4","e":"1597373545337880782209026","bc":"421100"}',
'X-Host': 'mall.film-ticket.film.list',
'X-Requested-With': 'XMLHttpRequest',
'X-Token': 'undefined'
}
for url in urls:
response = requests.get(url=url,headers=headers)
html = response.content.decode("utf-8")
page = json.loads(html)["data"]["films"]
for data in page:
film_name = data["name"]
if "actors" in data:
a = list()
for d in data["actors"]:
film_actor = d["name"] + "-" + d["role"]
a.append(film_actor)
film_info = data["synopsis"]
print("電影名稱:{},{},簡介:{}".format(film_name, a, film_info))
else:
film_actor = data["director"]
print("電影名稱:{},{},簡介:{}".format(film_name, film_actor, film_info))
uj5u.com熱心網友回復:
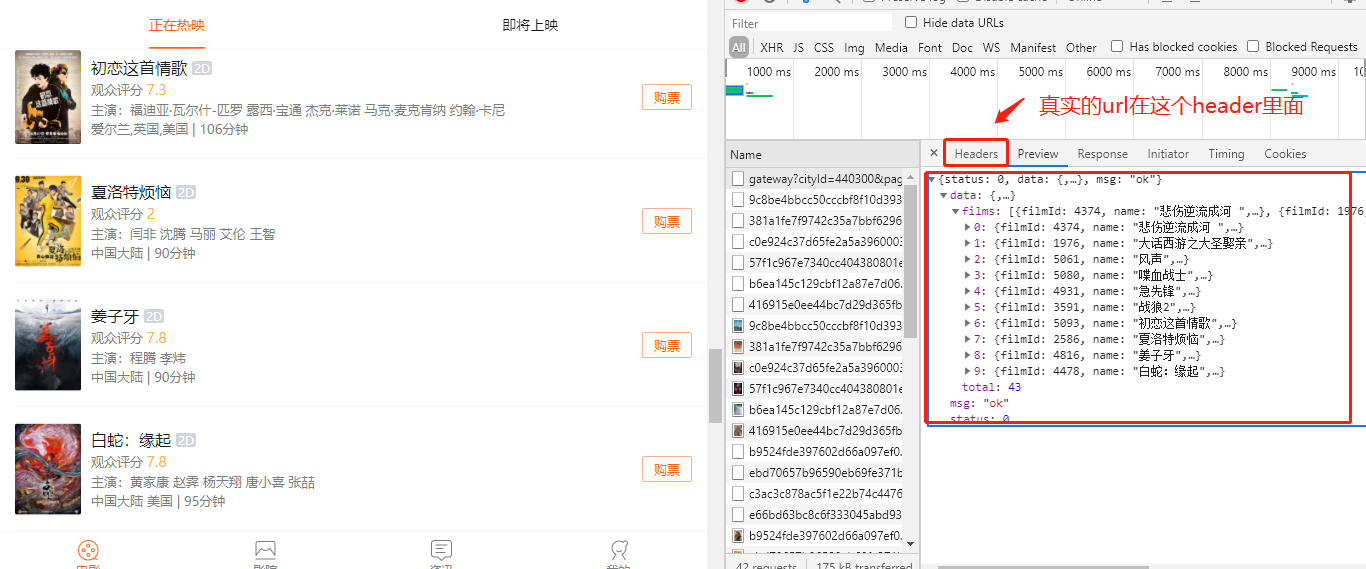
這個爬蟲主要還是分析哪個才是真實的url
uj5u.com熱心網友回復:
哦,明白了。原理之前沒有懂,
uj5u.com熱心網友回復:
兩次發帖不結貼等于耍牛虻啊
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/13325.html