求助各位大佬!小弟用urllib爬取雪球網的股票資料的時候出現了一個解碼的問題,始終想不明白原因是什么。
我獲取到的bytes格式的資料是這樣的:
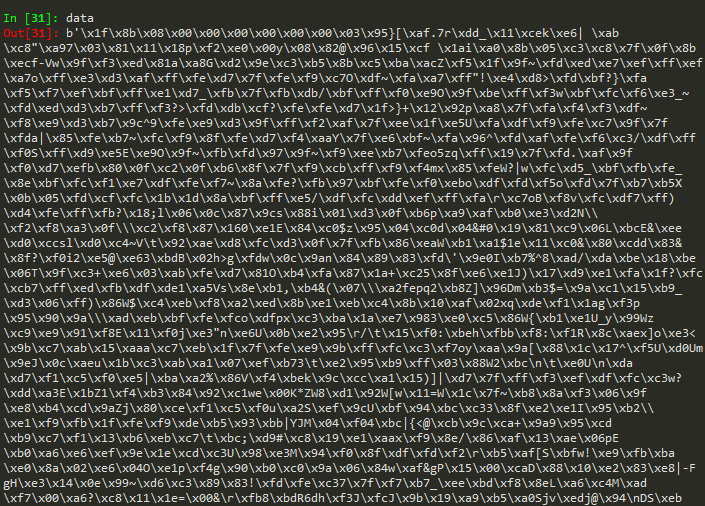
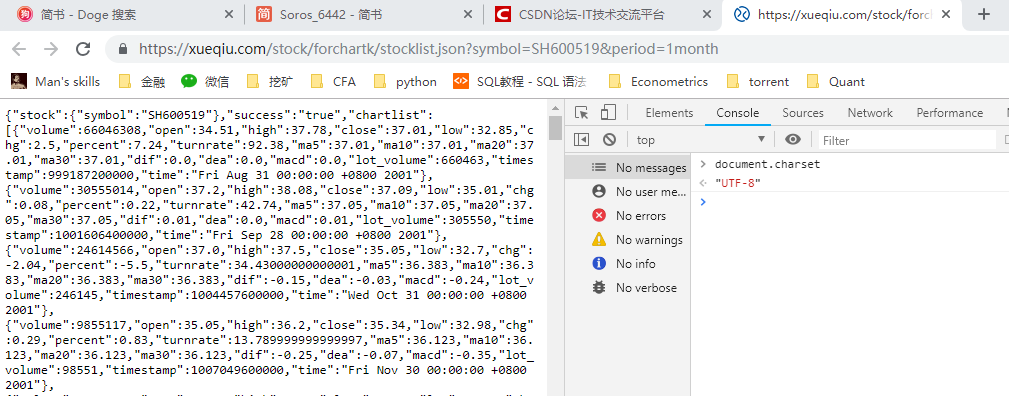
選擇解碼格式之前我還特意到原始網頁上看了看,顯示編碼格式是UTF-8,一切正常,原始網頁顯示的內容也沒有問題。
可是當我回到python上一輸入解碼的指令時,程式就報錯了……
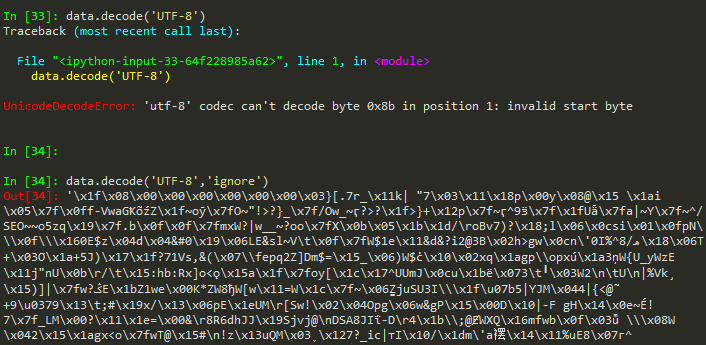
網上看到有說把第二個引數設定為'ignore'的,嘗試之后出現一堆亂碼,看來UTF-8的確不能解碼,問題出在哪里呢?
請各位大佬指點迷津!
uj5u.com熱心網友回復:
你這個出現的問題可以考慮一下回傳的內容的編碼方式是什么列印一下response.ecoding,看一下是不是utf-8,,還要看一下你請求時headers里面的引數是不是有一個accept引數,和瀏覽器的比較一下是不是一樣的
uj5u.com熱心網友回復:
你的程序是正確的,只是在控制臺輸出時,控制臺編碼和你運行環境編碼不一致代碼前加上這個試試
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/134002.html
上一篇:用python爬取vue專案中的cookie資料,啥都抓不到,大神們有遇到這個問題的有嗎?我就自己爬自己寫的專案,也不知道怎么爬,求給個思路