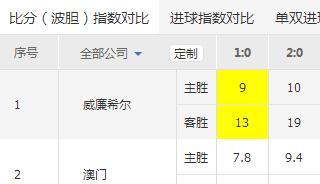
我想采集到下面這個黃色格子里的內容.但是網頁上面這2行是相當于1行的.
內容是:<td><span class="bd_btm">9</span>13</td>
我用xpath://table[@class='pub_table']/tbody[1]/tr[2]/td[4]采集出來是913,
試了N次,都不能單獨的采集出來13.我只想采集13,這個應該怎么修改啊?
這個是網址:http://odds.500.com/fenxi/bifen-869554.shtml
就是 表格左上角的 9 和13
uj5u.com熱心網友回復:
內容你都采集得到了,然后用個正則提取出來不就好了嗎?uj5u.com熱心網友回復:
謝謝老師回復,我就是不會正則啊.
uj5u.com熱心網友回復:
import re
content = '<td><span class="bd_btm">9</span>13</td>'
NumberArray = re.findall(r'</span>(\d+)<', str(content))
print(NumberArray[0])
uj5u.com熱心網友回復:
感謝老師,辛苦了!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/134028.html