博主從華中科技大學碩士畢業,曾浪跡于華為、百度大廠,是一個對技術有追求,正在苦苦針扎在架構師道路的程式員,如果你也有熱愛技識訓者懷有當架構師的理想不妨關注我,讓我們一路同行,見證彼此的努力,微信搜索公眾號"愛笑的架構師",等你~
本文有1萬5千字,預計閱讀時間為30分鐘,建議先收藏再看,以防走丟,
1、什么是Redis,Redis有哪些特點?
Redis全稱為:Remote Dictionary Server(遠程資料服務),Redis是一種支持key-value等多種資料結構的存盤系統,可用于快取,事件發布或訂閱,高速佇列等場景,支持網路,提供字串,哈希,串列,佇列,集合結構直接存取,基于記憶體,可持久化,
特點1:豐富的資料型別
我們知道很多資料庫只能處理一種資料結構:
-
傳統SQL資料庫處理二維關系資料;
-
MemCached資料庫,鍵和值都是字串;
-
檔案資料庫(MongoDB)是由Json/Bson組成的檔案,
當然不是他們這些資料庫不好,而是一旦資料庫提供資料結構不適合去做某件事情的話,程式寫起來就非常麻煩和不自然,
Redis雖然也是鍵值對資料庫,但是和Memcached不同的是:Redis的值不僅可以是字串,它還可以是其他五中資料機構中的任意一種,通過選用不同的資料結構,用戶可以使用Redis解決各種各樣的問題,使用Redis,你碰到一個問題,首先會想到是選用那種資料結構把哪些功能問題解決掉,有了多樣的資料結構,方便你解決問題,
特點2:記憶體存盤
資料庫有兩種:一種是硬碟資料庫,一種是記憶體資料庫,
硬碟資料庫是把值存盤在硬碟上,在記憶體中就存盤一下索引,當硬碟資料庫想訪問硬碟的值時,它先在記憶體里找到索引,然后再找值,問題在于,在讀取和寫入硬碟的時候,如果讀寫比較多的時候,它會把硬碟的IO功能堵死,
記憶體存盤是講所有的資料都存盤在記憶體里面,資料讀取和寫入速度非常快,
特點3:持久化功能
將資料存盤在記憶體里面的資料保存到硬碟中,保證資料安全,方便進行資料備份和恢復,
2、Redis有哪些資料結構?
Redis是key-value資料庫,key的型別只能是String,但是value的資料型別就比較豐富了,主要包括五種:
-
String
-
Hash
-
List
-
Set
-
Sorted Set
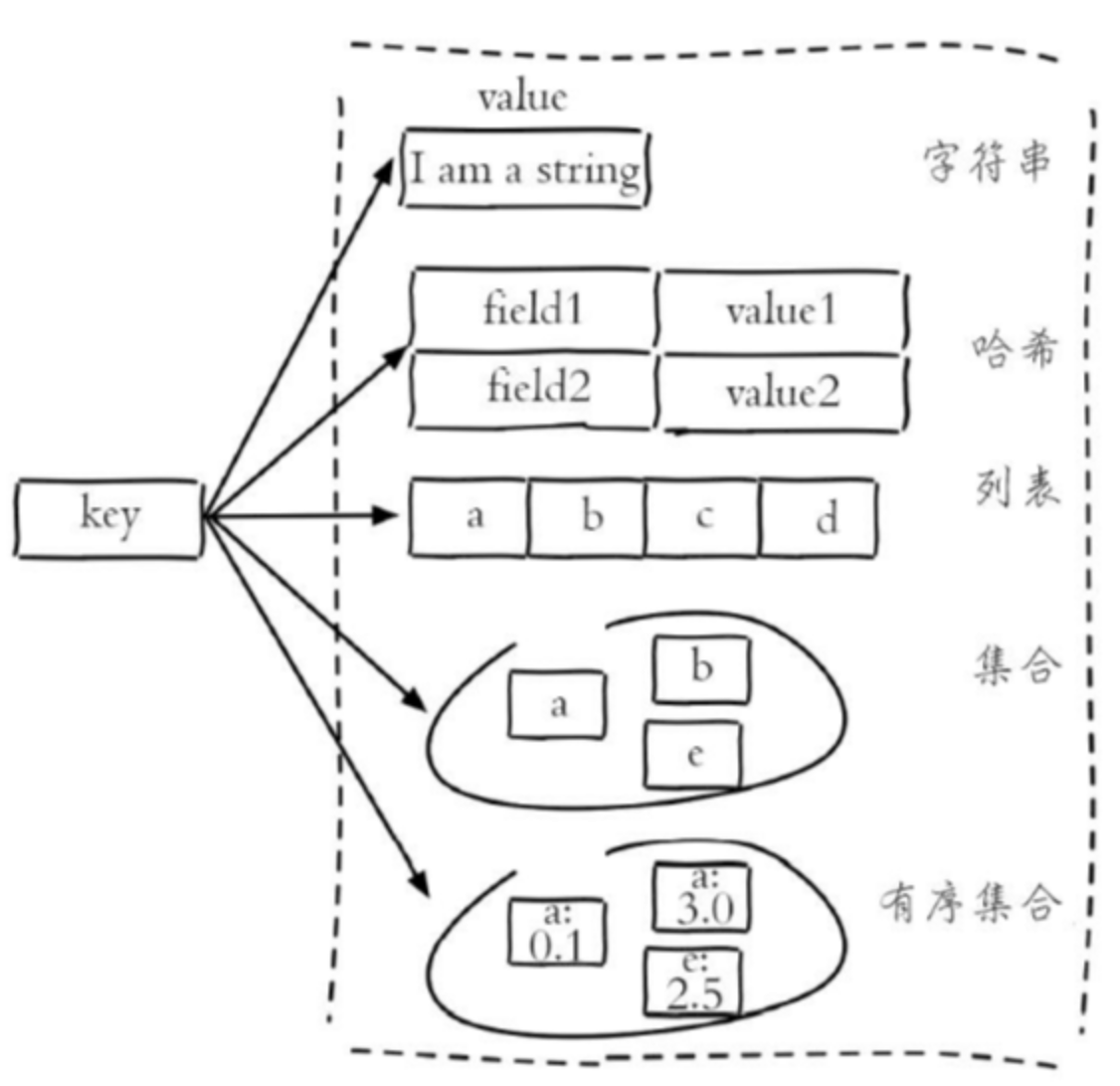
(1)String字串
語法
SET KEY_NAME VALUE
string型別是二進制安全的,意思是redis的string可以包含任何資料,比如jpg圖片或者序列化的物件, string型別是Redis最基本的資料型別,一個鍵最大能存盤512MB,
(2)Hash哈希
語法
HSET KEY_NAME FIELD VALUE
Redis hash 是一個鍵值(key=>value)對集合, Redis hash是一個string型別的field和value的映射表,hash特別適合用于存盤物件,
(3)List串列
語法
//在 key 對應 list 的頭部添加字串元素
LPUSH KEY_NAME VALUE1.. VALUEN
//在 key 對應 list 的尾部添加字串元素
RPUSH KEY_NAME VALUE1..VALUEN
//對應 list 中洗掉 count 個和 value 相同的元素
LREM KEY_NAME COUNT VALUE
//回傳 key 對應 list 的長度
LLEN KEY_NAME
Redis 串列是簡單的字串串列,按照插入順序排序, 可以添加一個元素到串列的頭部(左邊)或者尾部(右邊)
(4)Set集合
語法
SADD KEY_NAME VALUE1...VALUEn
Redis的Set是string型別的無序集合, 集合是通過哈希表實作的,所以添加,洗掉,查找的復雜度都是O(1),
(5)Sorted Set有序集合
語法
ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUEN
Redis zset 和 set 一樣也是string型別元素的集合,且不允許重復的成員, 不同的是每個元素都會關聯一個double型別的分數,
redis正是通過分數來為集合中的成員進行從小到大的排序,
zset的成員是唯一的,但分數(score)卻可以重復,
3、一個字串型別的值能存盤最大容量是多少?
查詢官方檔案(https://redis.io/topics/data-types)可以看到String型別的value值最多支持的長度為512M,所以正確的答案是512M,

圖片
4、能說一下Redis每種資料結構的使用場景嗎?
(1)String的使用場景
字串型別的使用場景:資訊快取、計數器、分布式鎖等等,
常用命令:get/set/del/incr/decr/incrby/decrby
實戰場景1:記錄每一個用戶的訪問次數,或者記錄每一個商品的瀏覽次數
方案:
常用鍵名: userid:pageview 或者 pageview:userid,如果一個用戶的id為123,那對應的redis key就為pageview:123,value就為用戶的訪問次數,增加次數可以使用命令:incr,
使用理由:每一個用戶訪問次數或者商品瀏覽次數的修改是很頻繁的,如果使用mysql這種檔案系統頻繁修改會造成mysql壓力,效率也低,而使用redis的好處有二:使用記憶體,很快;單執行緒,所以無競爭,資料不會被改亂,
實戰場景2:快取頻繁讀取,但是不常修改的資訊,如用戶資訊,視頻資訊
方案:
業務邏輯上:先從redis讀取,有值就從redis讀取,沒有則從mysql讀取,并寫一份到redis中作為快取,注意要設定過期時間,
鍵值設計上:
直接將用戶一條mysql記錄做序列化(通常序列化為json)作為值,userInfo:userid 作為key,鍵名如:userInfo:123,value存盤對應用戶資訊的json串,如 key為:"user:id:name:1", value為"{"name":"leijia","age":18}",
實戰場景3:限定某個ip特定時間內的訪問次數
方案:
用key記錄IP,value記錄訪問次數,同時key的過期時間設定為60秒,如果key過期了則重新設定,否則進行判斷,當一分鐘內訪問超過100次,則禁止訪問,
實戰場景4:分布式session
我們知道session是以檔案的形式保存在服務器中的;如果你的應用做了負載均衡,將網站的專案放在多個服務器上,當用戶在服務器A上進行登陸,session檔案會寫在A服務器;當用戶跳轉頁面時,請求被分配到B服務器上的時候,就找不到這個session檔案,用戶就要重新登陸,
如果想要多個服務器共享一個session,可以將session存放在redis中,redis可以獨立于所有負載均衡服務器,也可以放在其中一臺負載均衡服務器上;但是所有應用所在的服務器連接的都是同一個redis服務器,
(2)Hash的使用場景
以購物車為例子,用戶id設定為key,那么購物車里所有的商品就是用戶key對應的值了,每個商品有id和購買數量,對應hash的結構就是商品id為field,商品數量為value,如圖所示:
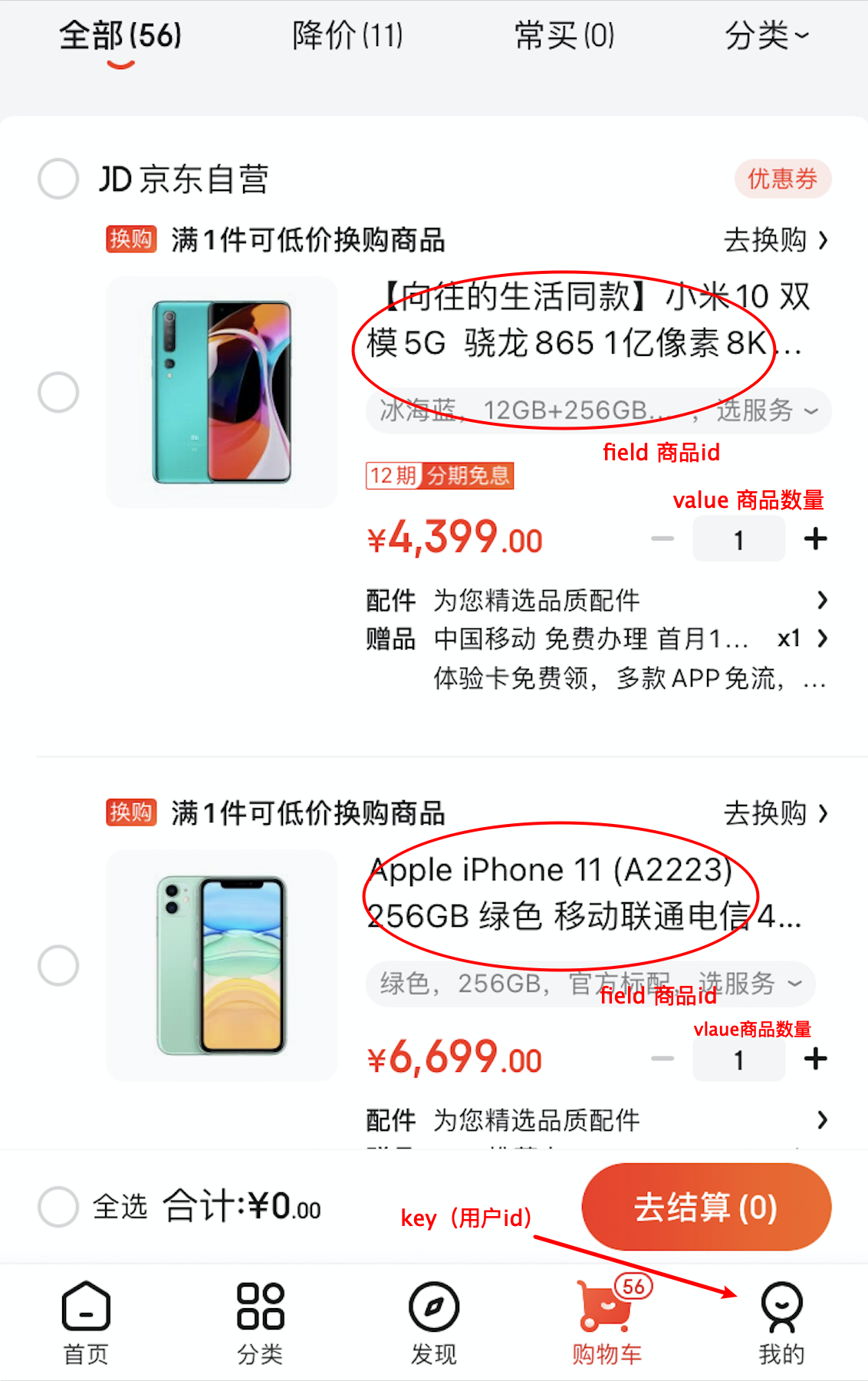
如果將商品id和商品數量序列化成json字串,那么也可以用上面講的string型別存盤,下面對比一下這兩種資料結構:
| 對比項 | string(json) | hash |
|---|---|---|
| 效率 | 很高 | 高 |
| 容量 | 低 | 低 |
| 靈活性 | 低 | 高 |
| 序列化 | 簡單 | 復雜 |
總結一下:
當物件的某個屬性需要頻繁修改時,不適合用string+json,因為它不夠靈活,每次修改都需要重新將整個物件序列化并賦值;如果使用hash型別,則可以針對某個屬性單獨修改,沒有序列化,也不需要修改整個物件,比如,商品的價格、銷量、關注數、評價數等可能經常發生變化的屬性,就適合存盤在hash型別里,
(3)List的使用場景
串列本質是一個有序的,元素可重復的佇列,
實戰場景:定時排行榜
list型別的lrange命令可以分頁查看佇列中的資料,可將每隔一段時間計算一次的排行榜存盤在list型別中,如QQ音樂內地排行榜,每周計算一次存盤再list型別中,訪問介面時通過page和size分頁轉化成lrange命令獲取排行榜資料,
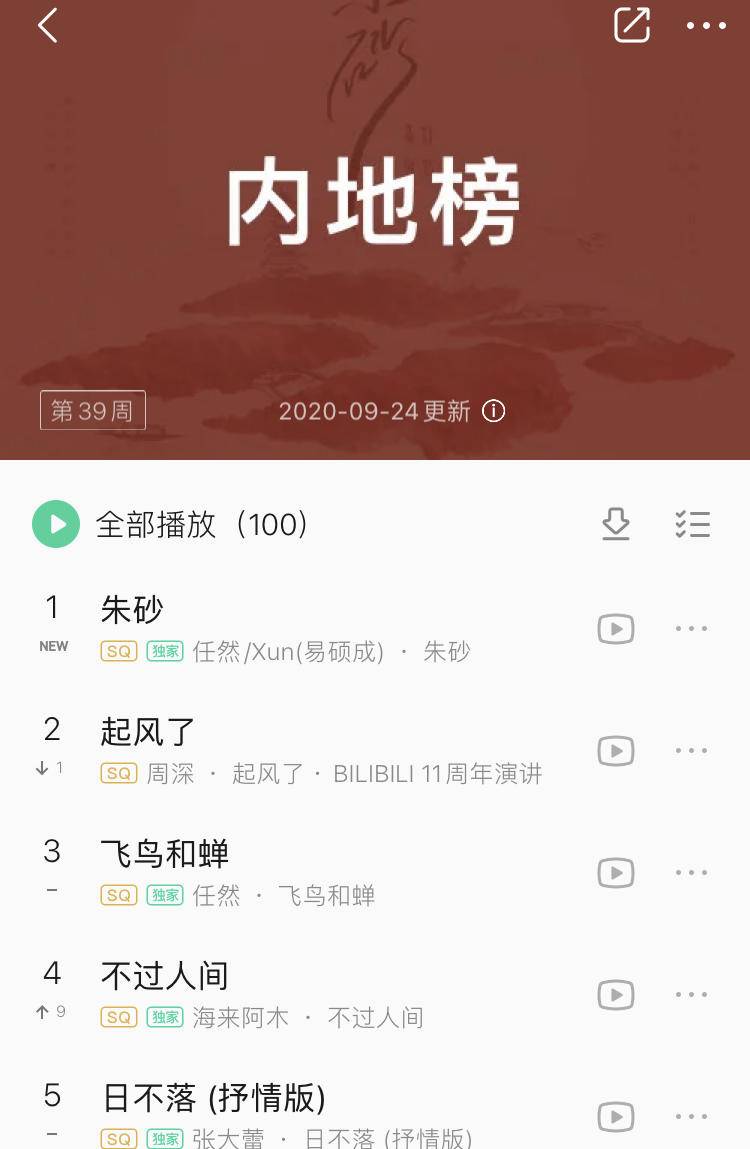
但是,并不是所有的排行榜都能用list型別實作,只有定時計算的排行榜才適合使用list型別存盤,與定時計算的排行榜相對應的是實時計算的排行榜,list型別不能支持實時計算的排行榜,下面介紹有序集合sorted set的應用場景時會詳細介紹實時計算的排行榜的實作,
(4)Set的使用場景
集合的特點是無序性和確定性(不重復),
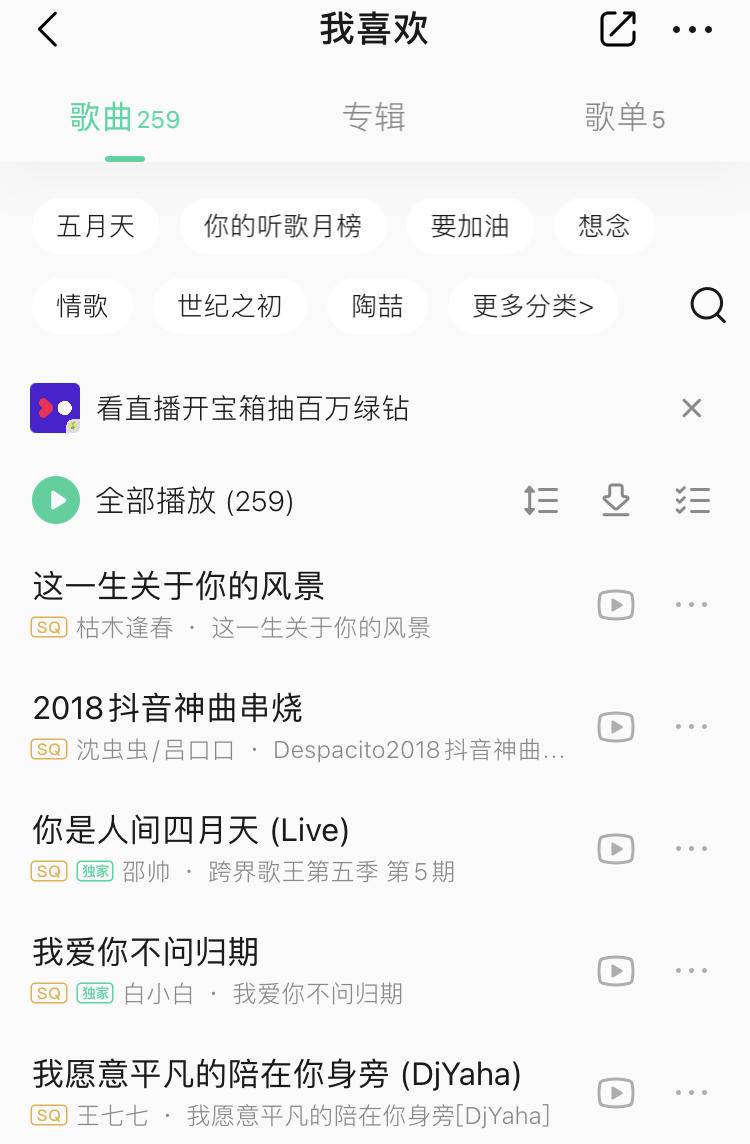
實戰場景:收藏夾
例如QQ音樂中如果你喜歡一首歌,點個『喜歡』就會將歌曲放到個人收藏夾中,每一個用戶做一個收藏的集合,每個收藏的集合存放用戶收藏過的歌曲id,
key為用戶id,value為歌曲id的集合,
(5)Sorted Set的使用場景
有序集合的特點是有序,無重復值,與set不同的是sorted set每個元素都會關聯一個score屬性,redis正是通過score來為集合中的成員進行從小到大的排序,
實戰場景:實時排行榜
QQ音樂中有多種實時榜單,比如飆升榜、熱歌榜、新歌榜,可以用redis key存盤榜單型別,score為點擊量,value為歌曲id,用戶每點擊一首歌曲會更新redis資料,sorted set會依據score即點擊量將歌曲id排序,
5、Redis如何做持久化的?能說一下RDB和AOF的實作原理嗎?
什么是持久化?
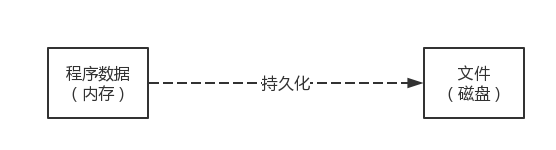
持久化(Persistence),即把資料(如記憶體中的物件)保存到可永久保存的存盤設備中(如磁盤),持久化的主要應用是將記憶體中的物件存盤在資料庫中,或者存盤在磁盤檔案中、XML資料檔案中等等,
圖片
還可以從如下兩個層面簡單的理解持久化 :
-
應用層:如果關閉(shutdown)你的應用然后重新啟動則先前的資料依然存在,
-
系統層:如果關閉(shutdown)你的系統(電腦)然后重新啟動則先前的資料依然存在,
Redis為什么要持久化?
Redis是記憶體資料庫,為了保證效率所有的操作都是在記憶體中完成,資料都是快取在記憶體中,當你重啟系統或者關閉系統,之前快取在記憶體中的資料都會丟失再也不能找回,因此為了避免這種情況,Redis需要實作持久化將記憶體中的資料存盤起來,
Redis如何實作持久化?
Redis官方提供了不同級別的持久化方式:
-
RDB持久化:能夠在指定的時間間隔能對你的資料進行快照存盤,
-
AOF持久化:記錄每次對服務器寫的操作,當服務器重啟的時候會重新執行這些命令來恢復原始的資料,AOF命令以redis協議追加保存每次寫的操作到檔案末尾,Redis還能對AOF檔案進行后臺重寫,使得AOF檔案的體積不至于過大,
-
不使用持久化:如果你只希望你的資料在服務器運行的時候存在,你也可以選擇不使用任何持久化方式,
-
同時開啟RDB和AOF:你也可以同時開啟兩種持久化方式,在這種情況下當redis重啟的時候會優先載入AOF檔案來恢復原始的資料,因為在通常情況下AOF檔案保存的資料集要比RDB檔案保存的資料集要完整,
這么多持久化方式我們應該怎么選?在選擇之前我們需要搞清楚每種持久化方式的區別以及各自的優劣勢,
RDB持久化
RDB(Redis Database)持久化是把當前記憶體資料生成快照保存到硬碟的程序,觸發RDB持久化程序分為手動觸發和自動觸發,
(1)手動觸發
手動觸發對應save命令,會阻塞當前Redis服務器,直到RDB程序完成為止,對于記憶體比較大的實體會造成長時間阻塞,線上環境不建議使用,
(2)自動觸發
自動觸發對應bgsave命令,Redis行程執行fork操作創建子行程,RDB持久化程序由子行程負責,完成后自動結束,阻塞只發生在fork階段,一般時間很短,
在redis.conf組態檔中可以配置:
save <seconds> <changes>
表示xx秒內資料修改xx次時自動觸發bgsave, 如果想關閉自動觸發,可以在save命令后面加一個空串,即:
save ""
還有其他常見可以觸發bgsave,如:
-
如果從節點執行全量復制操作,主節點自動執行bgsave生成RDB檔案并發送給從節點,
-
默認情況下執行shutdown命令時,如果沒有開啟AOF持久化功能則 自動執行bgsave,
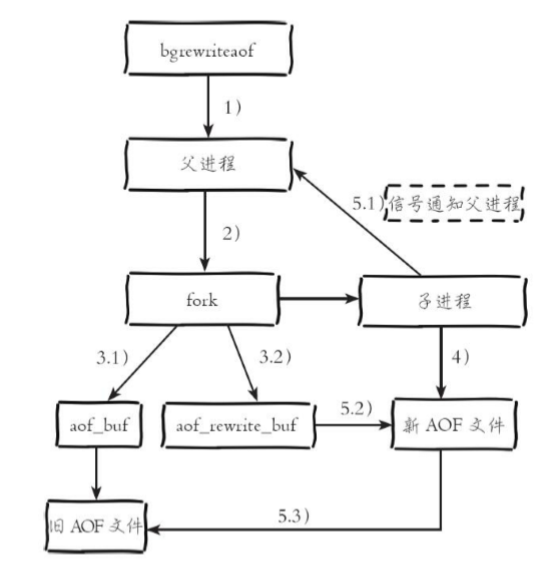
bgsave作業機制
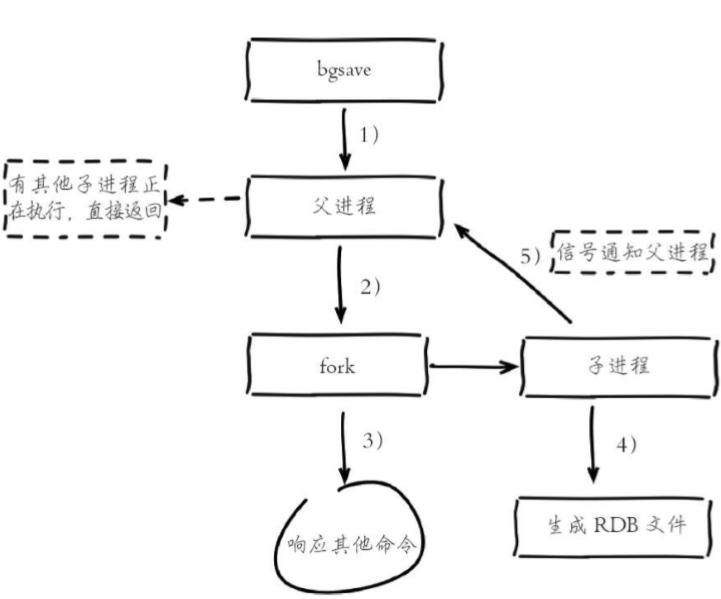
(1)執行bgsave命令,Redis父行程判斷當前是否存在正在執行的子進 程,如RDB/AOF子行程,如果存在,bgsave命令直接回傳,
(2)父行程執行fork操作創建子行程,fork操作程序中父行程會阻塞,通 過info stats命令查看latest_fork_usec選項,可以獲取最近一個fork操作的耗時,單位為微秒
(3)父行程fork完成后,bgsave命令回傳“Background saving started”資訊并不再阻塞父行程,可以繼續回應其他命令,
(4)子行程創建RDB檔案,根據父行程記憶體生成臨時快照檔案,完成后對原有檔案進行原子替換,執行lastsave命令可以獲取最后一次生成RDB的 時間,對應info統計的rdb_last_save_time選項,
(5)行程發送信號給父行程表示完成,父行程更新統計資訊,具體見 info Persistence下的rdb_*相關選項,
-- RDB持久化完 --
AOF持久化
AOF(append only file)持久化:以獨立日志的方式記錄每次寫命令, 重啟時再重新執行AOF檔案中的命令達到恢復資料的目的,AOF的主要作用是解決了資料持久化的實時性,目前已經是Redis持久化的主流方式,
AOF持久化作業機制
開啟AOF功能需要配置:appendonly yes,默認不開啟,
AOF檔案名 通過appendfilename配置設定,默認檔案名是appendonly.aof,保存路徑同 RDB持久化方式一致,通過dir配置指定,
AOF的作業流程操作:命令寫入 (append)、檔案同步(sync)、檔案重寫(rewrite)、重啟加載 (load),
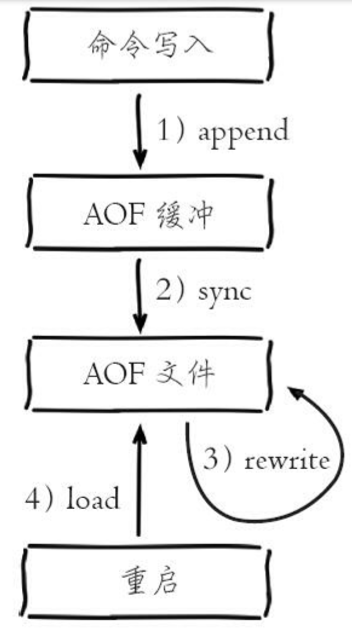
(1)所有的寫入命令會追加到aof_buf(緩沖區)中,
(2)AOF緩沖區根據對應的策略向硬碟做同步操作,
AOF為什么把命令追加到aof_buf中?Redis使用單執行緒回應命令,如果每次寫AOF檔案命令都直接追加到硬碟,那么性能完全取決于當前硬碟負載,先寫入緩沖區aof_buf中,還有另一個好處,Redis可以提供多種緩沖區同步硬碟的策略,在性能和安全性方面做出平衡,
(3)隨著AOF檔案越來越大,需要定期對AOF檔案進行重寫,達到壓縮的目的,
(4)當Redis服務器重啟時,可以加載AOF檔案進行資料恢復,
AOF重寫(rewrite)機制
重寫的目的:
-
減小AOF檔案占用空間;
-
更小的AOF 檔案可以更快地被Redis加載恢復,
AOF重寫可以分為手動觸發和自動觸發:
-
手動觸發:直接呼叫bgrewriteaof命令,
-
自動觸發:根據auto-aof-rewrite-min-size和auto-aof-rewrite-percentage引數確定自動觸發時機,
auto-aof-rewrite-min-size:表示運行AOF重寫時檔案最小體積,默認 為64MB,
auto-aof-rewrite-percentage:代表當前AOF檔案空間 (aof_current_size)和上一次重寫后AOF檔案空間(aof_base_size)的比值,
自動觸發時機
當aof_current_size>auto-aof-rewrite-minsize 并且(aof_current_size-aof_base_size)/aof_base_size>=auto-aof-rewritepercentage,
其中aof_current_size和aof_base_size可以在info Persistence統計資訊中查看,
AOF檔案重寫后為什么會變小?
(1)舊的AOF檔案含有無效的命令,如:del key1, hdel key2等,重寫只保留最終資料的寫入命令,
(2)多條命令可以合并,如lpush list a,lpush list b,lpush list c可以直接轉化為lpush list a b c,
AOF檔案資料恢復
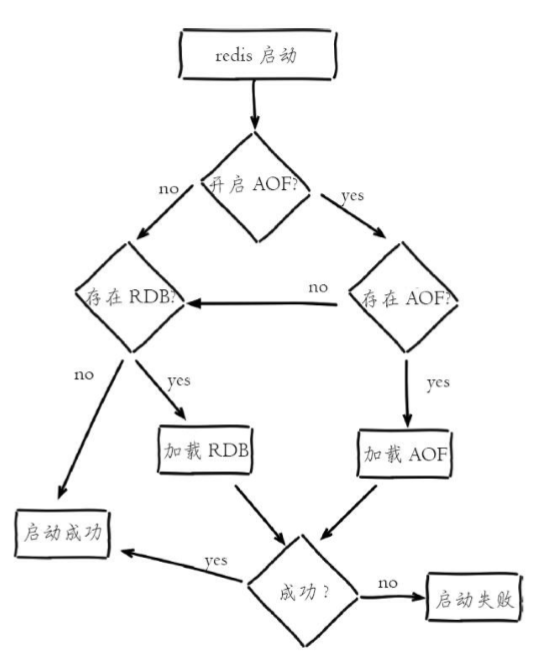
資料恢復流程說明:
(1)AOF持久化開啟且存在AOF檔案時,優先加載AOF檔案,
(2)AOF關倍訓者AOF檔案不存在時,加載RDB檔案,
(3)加載AOF/RDB檔案成功后,Redis啟動成功,
(4)AOF/RDB檔案存在錯誤時,Redis啟動失敗并列印錯誤資訊,
-- AOF持久化完 --
RDB和AOF的優缺點
RDB優點
-
RDB 是一個非常緊湊的檔案,它保存了某個時間點的資料集,非常適用于資料集的備份,比如你可以在每個小時報保存一下過去24小時內的資料,同時每天保存過去30天的資料,這樣即使出了問題你也可以根據需求恢復到不同版本的資料集,
-
RDB 是一個緊湊的單一檔案,很方便傳送到另一個遠端資料中心,非常適用于災難恢復,
-
RDB 在保存 RDB 檔案時父行程唯一需要做的就是 fork 出一個子行程,接下來的作業全部由子行程來做,父行程不需要再做其他 IO 操作,所以 RDB 持久化方式可以最大化 Redis 的性能,
-
與AOF相比,在恢復大的資料集的時候,RDB 方式會更快一些,
AOF優點
-
你可以使用不同的 fsync 策略:無 fsync、每秒 fsync 、每次寫的時候 fsync .使用默認的每秒 fsync 策略, Redis 的性能依然很好( fsync 是由后臺執行緒進行處理的,主執行緒會盡力處理客戶端請求),一旦出現故障,你最多丟失1秒的資料,
-
AOF檔案是一個只進行追加的日志檔案,所以不需要寫入seek,即使由于某些原因(磁盤空間已滿,寫的程序中宕機等等)未執行完整的寫入命令,你也也可使用redis-check-aof工具修復這些問題,
-
Redis 可以在 AOF 檔案體積變得過大時,自動地在后臺對 AOF 進行重寫: 重寫后的新 AOF 檔案包含了恢復當前資料集所需的最小命令集合, 整個重寫操作是絕對安全的,因為 Redis 在創建新 AOF 檔案的程序中,會繼續將命令追加到現有的 AOF 檔案里面,即使重寫程序中發生停機,現有的 AOF 檔案也不會丟失, 而一旦新 AOF 檔案創建完畢,Redis 就會從舊 AOF 檔案切換到新 AOF 檔案,并開始對新 AOF 檔案進行追加操作,
-
AOF 檔案有序地保存了對資料庫執行的所有寫入操作, 這些寫入操作以 Redis 協議的格式保存, 因此 AOF 檔案的內容非常容易被人讀懂, 對檔案進行分析(parse)也很輕松, 匯出(export) AOF 檔案也非常簡單: 舉個例子, 如果你不小心執行了 FLUSHALL 命令, 但只要 AOF 檔案未被重寫, 那么只要停止服務器, 移除 AOF 檔案末尾的 FLUSHALL 命令, 并重啟 Redis , 就可以將資料集恢復到 FLUSHALL 執行之前的狀態,
RDB缺點
-
Redis 要完整的保存整個資料集是一個比較繁重的作業,你通常會每隔5分鐘或者更久做一次完整的保存,萬一在 Redis 意外宕機,你可能會丟失幾分鐘的資料,
-
RDB 需要經常 fork 子行程來保存資料集到硬碟上,當資料集比較大的時候, fork 的程序是非常耗時的,可能會導致 Redis 在一些毫秒級內不能回應客戶端的請求,
AOF缺點
-
對于相同的資料集來說,AOF 檔案的體積通常要大于 RDB 檔案的體積,
-
資料恢復(load)時AOF比RDB慢,通常RDB 可以提供更有保證的最大延遲時間,
RDB和AOF簡單對比總結
RDB優點:
-
RDB 是緊湊的二進制檔案,比較適合備份,全量復制等場景
-
RDB 恢復資料遠快于 AOF
RDB缺點:
-
RDB 無法實作實時或者秒級持久化;
-
新老版本無法兼容 RDB 格式,
AOF優點:
-
可以更好地保護資料不丟失;
-
appen-only 模式寫入性能比較高;
-
適合做災難性的誤洗掉緊急恢復,
AOF缺點:
-
對于同一份檔案,AOF 檔案要比 RDB 快照大;
-
AOF 開啟后,會對寫的 QPS 有所影響,相對于 RDB 來說 寫 QPS 要下降;
-
資料庫恢復比較慢, 不合適做冷備,
6、講解一下Redis的執行緒模型?
redis 內部使用檔案事件處理器 file event handler,這個檔案事件處理器是單執行緒的,所以 redis 才叫做單執行緒的模型,它采用 IO 多路復用機制同時監聽多個 socket,根據 socket 上的事件來選擇對應的事件處理器進行處理,
如果面試官繼續追問為啥 redis 單執行緒模型也能效率這么高?
-
純記憶體操作
-
核心是基于非阻塞的 IO 多路復用機制
-
單執行緒反而避免了多執行緒的頻繁背景關系切換問題
7、快取雪崩、快取穿透、快取預熱、快取擊穿、快取降級的區別是什么?
在實際生產環境中有時會遇到快取穿透、快取擊穿、快取雪崩等例外場景,為了避免例外帶來巨大損失,我們需要了解每種例外發生的原因以及解決方案,幫助提升系統可靠性和高可用,
(1)快取穿透
什么是快取穿透?
快取穿透是指用戶請求的資料在快取中不存在即沒有命中,同時在資料庫中也不存在,導致用戶每次請求該資料都要去資料庫中查詢一遍,然后回傳空,
如果有惡意攻擊者不斷請求系統中不存在的資料,會導致短時間大量請求落在資料庫上,造成資料庫壓力過大,甚至擊垮資料庫系統,
快取穿透常用的解決方案
(1)布隆過濾器(推薦)
布隆過濾器(Bloom Filter,簡稱BF)由Burton Howard Bloom在1970年提出,是一種空間效率高的概率型資料結構,
布隆過濾器專門用來檢測集合中是否存在特定的元素,
如果在平時我們要判斷一個元素是否在一個集合中,通常會采用查找比較的方法,下面分析不同的資料結構查找效率:
-
采用線性表存盤,查找時間復雜度為O(N)
-
采用平衡二叉排序樹(AVL、紅黑樹)存盤,查找時間復雜度為O(logN)
-
采用哈希表存盤,考慮到哈希碰撞,整體時間復雜度也要O[log(n/m)]
當需要判斷一個元素是否存在于海量資料集合中,不僅查找時間慢,還會占用大量存盤空間,接下來看一下布隆過濾器如何解決這個問題,
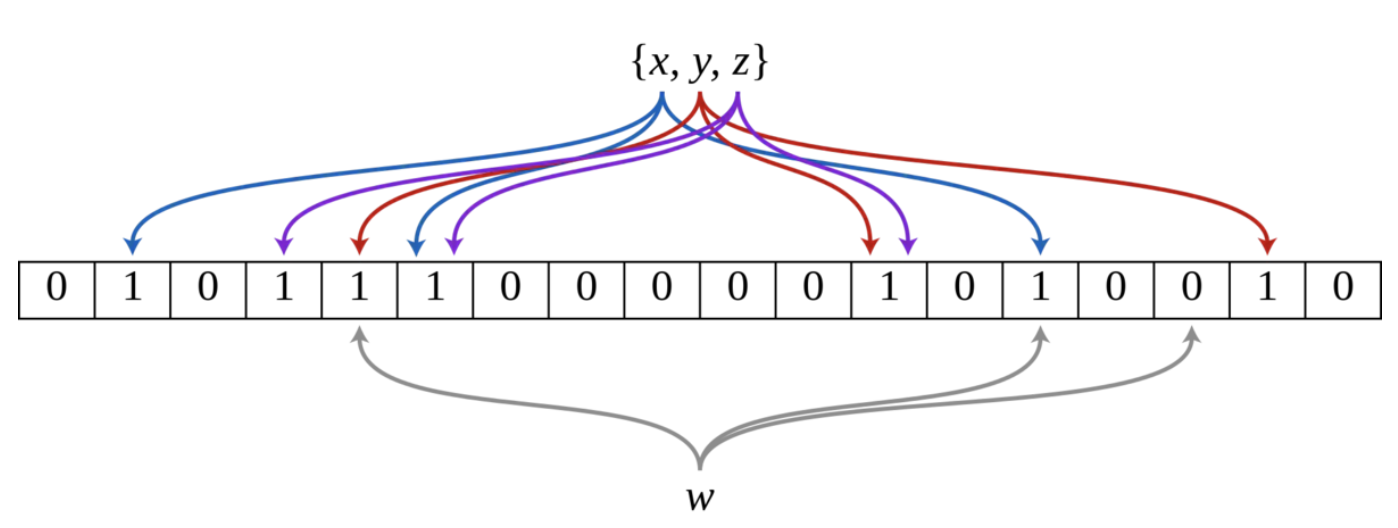
布隆過濾器設計思想
布隆過濾器由一個長度為m位元的位陣列(bit array)與k個哈希函式(hash function)組成的資料結構,位陣列初始化均為0,所有的哈希函式都可以分別把輸入資料盡量均勻地散列,
當要向布隆過濾器中插入一個元素時,該元素經過k個哈希函式計算產生k個哈希值,以哈希值作為位陣列中的下標,將所有k個對應的位元值由0置為1,
當要查詢一個元素時,同樣將其經過哈希函式計算產生哈希值,然后檢查對應的k個位元值:如果有任意一個位元為0,表明該元素一定不在集合中;如果所有位元均為1,表明該集合有可能性在集合中,為什么不是一定在集合中呢?因為不同的元素計算的哈希值有可能一樣,會出現哈希碰撞,導致一個不存在的元素有可能對應的位元位為1,這就是所謂“假陽性”(false positive),相對地,“假陰性”(false negative)在BF中是絕不會出現的,
總結一下:布隆過濾器認為不在的,一定不會在集合中;布隆過濾器認為在的,可能在也可能不在集合中,
舉個例子:下圖是一個布隆過濾器,共有18個位元位,3個哈希函式,集合中三個元素x,y,z通過三個哈希函式散列到不同的位元位,并將位元位置為1,當查詢元素w時,通過三個哈希函式計算,發現有一個位元位的值為0,可以肯定認為該元素不在集合中,
布隆過濾器優缺點
優點:
-
節省空間:不需要存盤資料本身,只需要存盤資料對應hash位元位
-
時間復雜度低:插入和查找的時間復雜度都為O(k),k為哈希函式的個數
缺點:
-
存在假陽性:布隆過濾器判斷存在,可能出現元素不在集合中;判斷準確率取決于哈希函式的個數
-
不能洗掉元素:如果一個元素被洗掉,但是卻不能從布隆過濾器中洗掉,這也是造成假陽性的原因了
布隆過濾器適用場景
-
爬蟲系統url去重
-
垃圾郵件過濾
-
黑名單
(2)回傳空物件
當快取未命中,查詢持久層也為空,可以將回傳的空物件寫到快取中,這樣下次請求該key時直接從快取中查詢回傳空物件,請求不會落到持久層資料庫,為了避免存盤過多空物件,通常會給空物件設定一個過期時間,
這種方法會存在兩個問題:
-
如果有大量的key穿透,快取空物件會占用寶貴的記憶體空間,
-
空物件的key設定了過期時間,在這段時間可能會存在快取和持久層資料不一致的場景,
(2)快取擊穿
什么是快取擊穿?
快取擊穿,是指一個key非常熱點,在不停的扛著大并發,大并發集中對這一個點進行訪問,當這個key在失效的瞬間,持續的大并發就穿破快取,直接請求資料庫,就像在一個屏障上鑿開了一個洞,
快取擊穿危害
資料庫瞬時壓力驟增,造成大量請求阻塞,
如何解決?
方案一:使用互斥鎖(mutex key)
這種思路比較簡單,就是讓一個執行緒回寫快取,其他執行緒等待回寫快取執行緒執行完,重新讀快取即可,
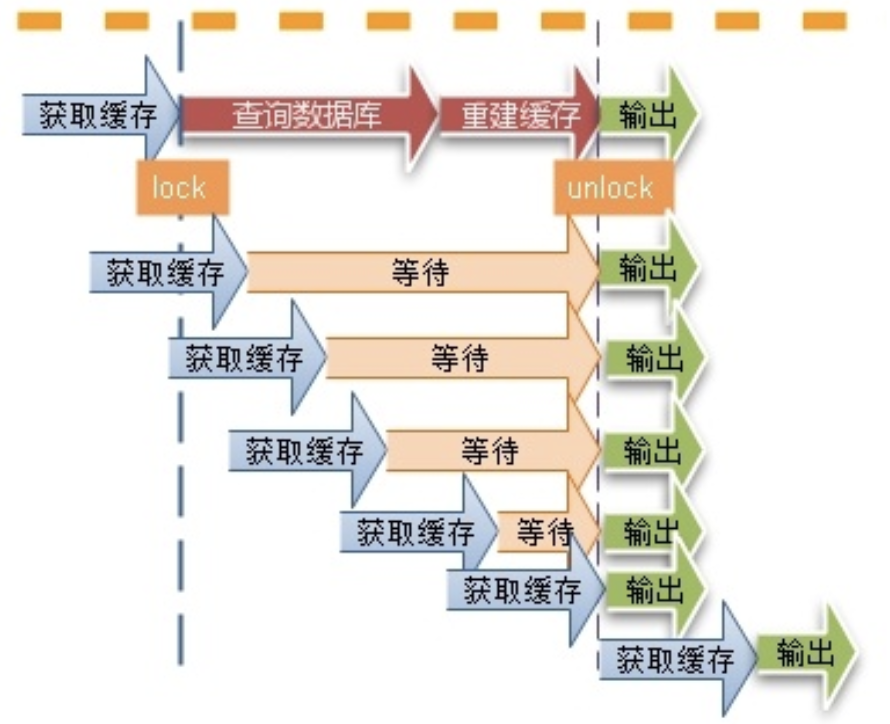
同一時間只有一個執行緒讀資料庫然后回寫快取,其他執行緒都處于阻塞狀態,如果是高并發場景,大量執行緒阻塞勢必會降低吞吐量,這種情況如何解決?大家可以在留言區討論,
如果是分布式應用就需要使用分布式鎖,
方案二:熱點資料永不過期
永不過期實際包含兩層意思:
-
物理不過期,針對熱點key不設定過期時間
-
邏輯過期,把過期時間存在key對應的value里,如果發現要過期了,通過一個后臺的異步執行緒進行快取的構建
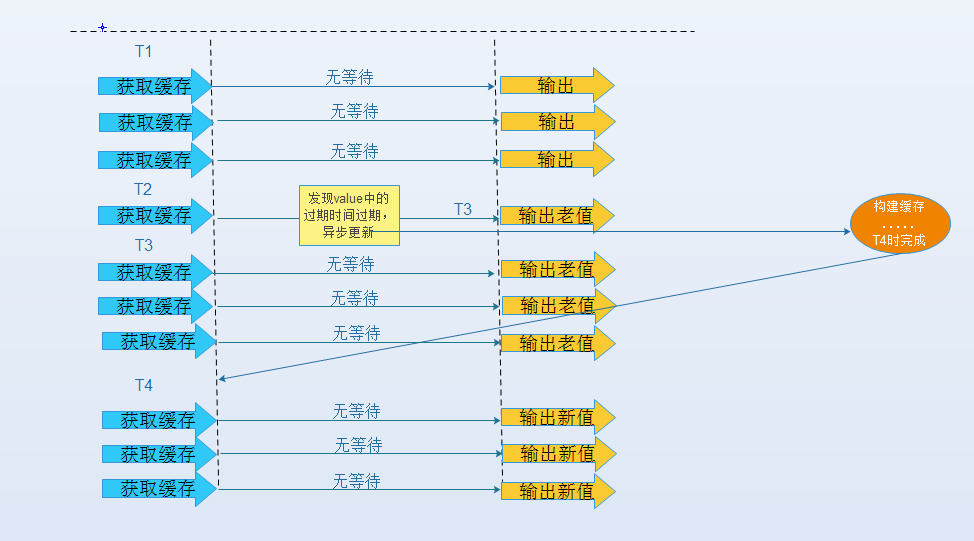
從實戰看這種方法對于性能非常友好,唯一不足的就是構建快取時候,其余執行緒(非構建快取的執行緒)可能訪問的是老資料,對于不追求嚴格強一致性的系統是可以接受的,
(3)快取雪崩
什么是快取雪崩?
快取雪崩是指快取中資料大批量到過期時間,而查詢資料量巨大,請求直接落到資料庫上,引起資料庫壓力過大甚至宕機,和快取擊穿不同的是,快取擊穿指并發查同一條資料,快取雪崩是不同資料都過期了,很多資料都查不到從而查資料庫,
快取雪崩解決方案
常用的解決方案有:
-
均勻過期
-
加互斥鎖
-
快取永不過期
-
雙層快取策略
(1)均勻過期
設定不同的過期時間,讓快取失效的時間點盡量均勻,通常可以為有效期增加隨機值或者統一規劃有效期,
(2)加互斥鎖
跟快取擊穿解決思路一致,同一時間只讓一個執行緒構建快取,其他執行緒阻塞排隊,
(3)快取永不過期
跟快取擊穿解決思路一致,快取在物理上永遠不過期,用一個異步的執行緒更新快取,
(4)雙層快取策略
使用主備兩層快取:
主快取:有效期按照經驗值設定,設定為主讀取的快取,主快取失效后從資料庫加載最新值,
備份快取:有效期長,獲取鎖失敗時讀取的快取,主快取更新時需要同步更新備份快取,
(4)快取預熱
什么是快取預熱?
快取預熱就是系統上線后,將相關的快取資料直接加載到快取系統,這樣就可以避免在用戶請求的時候,先查詢資料庫,然后再將資料回寫到快取,
如果不進行預熱, 那么 Redis 初始狀態資料為空,系統上線初期,對于高并發的流量,都會訪問到資料庫中, 對資料庫造成流量的壓力,
快取預熱的操作方法
-
資料量不大的時候,工程啟動的時候進行加載快取動作;
-
資料量大的時候,設定一個定時任務腳本,進行快取的重繪;
-
資料量太大的時候,優先保證熱點資料進行提前加載到快取,
(5)快取降級
快取降級是指快取失效或快取服務器掛掉的情況下,不去訪問資料庫,直接回傳默認資料或訪問服務的記憶體資料,
在專案實戰中通常會將部分熱點資料快取到服務的記憶體中,這樣一旦快取出現例外,可以直接使用服務的記憶體資料,從而避免資料庫遭受巨大壓力,
降級一般是有損的操作,所以盡量減少降級對于業務的影響程度,
8、Redis的記憶體淘汰機制
Redis記憶體淘汰策略是指當快取記憶體不足時,通過淘汰舊資料處理新加入資料選擇的策略,
如何配置最大記憶體?
(1)通過組態檔配置
修改redis.conf組態檔
maxmemory 1024mb //設定Redis最大占用記憶體大小為1024M
注意:maxmemory默認配置為0,在64位作業系統下redis最大記憶體為作業系統剩余記憶體,在32位作業系統下redis最大記憶體為3GB, (2)通過動態命令配置
Redis支持運行時通過命令動態修改記憶體大小:
127.0.0.1:6379> config set maxmemory 200mb //設定Redis最大占用記憶體大小為200M
127.0.0.1:6379> config get maxmemory //獲取設定的Redis能使用的最大記憶體大小
1) "maxmemory"
2) "209715200"
淘汰策略的分類
Redis最大占用記憶體用完之后,如果繼續添加資料,如何處理這種情況呢?實際上Redis官方已經定義了八種策略來處理這種情況:
noeviction
默認策略,對于寫請求直接回傳錯誤,不進行淘汰,
allkeys-lru
lru(less recently used), 最近最少使用,從所有的key中使用近似LRU演算法進行淘汰,
volatile-lru
lru(less recently used), 最近最少使用,從設定了過期時間的key中使用近似LRU演算法進行淘汰,
allkeys-random
從所有的key中隨機淘汰,
volatile-random
從設定了過期時間的key中隨機淘汰,
volatile-ttl
ttl(time to live),在設定了過期時間的key中根據key的過期時間進行淘汰,越早過期的越優先被淘汰,
allkeys-lfu
lfu(Least Frequently Used),最少使用頻率,從所有的key中使用近似LFU演算法進行淘汰,從Redis4.0開始支持,
volatile-lfu
lfu(Least Frequently Used),最少使用頻率,從設定了過期時間的key中使用近似LFU演算法進行淘汰,從Redis4.0開始支持,
注意:當使用volatile-lru、volatile-random、volatile-ttl這三種策略時,如果沒有設定過期的key可以被淘汰,則和noeviction一樣回傳錯誤,
LRU演算法
LRU(Least Recently Used),即最近最少使用,是一種快取置換演算法,在使用記憶體作為快取的時候,快取的大小一般是固定的,當快取被占滿,這個時候繼續往快取里面添加資料,就需要淘汰一部分老的資料,釋放記憶體空間用來存盤新的資料,這個時候就可以使用LRU演算法了,其核心思想是:如果一個資料在最近一段時間沒有被用到,那么將來被使用到的可能性也很小,所以就可以被淘汰掉,
LRU在Redis中的實作
Redis使用的是近似LRU演算法,它跟常規的LRU演算法還不太一樣,近似LRU演算法通過隨機采樣法淘汰資料,每次隨機出5個(默認)key,從里面淘汰掉最近最少使用的key,
可以通過maxmemory-samples引數修改采樣數量, 如:maxmemory-samples 10
maxmenory-samples配置的越大,淘汰的結果越接近于嚴格的LRU演算法,但因此耗費的CPU也很高,
Redis為了實作近似LRU演算法,給每個key增加了一個額外增加了一個24bit的欄位,用來存盤該key最后一次被訪問的時間,
Redis3.0對近似LRU的優化
Redis3.0對近似LRU演算法進行了一些優化,新演算法會維護一個候選池(大小為16),池中的資料根據訪問時間進行排序,第一次隨機選取的key都會放入池中,隨后每次隨機選取的key只有在訪問時間小于池中最小的時間才會放入池中,直到候選池被放滿,當放滿后,如果有新的key需要放入,則將池中最后訪問時間最大(最近被訪問)的移除,
當需要淘汰的時候,則直接從池中選取最近訪問時間最小(最久沒被訪問)的key淘汰掉就行,
LFU演算法
LFU(Least Frequently Used),是Redis4.0新加的一種淘汰策略,它的核心思想是根據key的最近被訪問的頻率進行淘汰,很少被訪問的優先被淘汰,被訪問的多的則被留下來,
LFU演算法能更好的表示一個key被訪問的熱度,假如你使用的是LRU演算法,一個key很久沒有被訪問到,只剛剛是偶爾被訪問了一次,那么它就被認為是熱點資料,不會被淘汰,而有些key將來是很有可能被訪問到的則被淘汰了,如果使用LFU演算法則不會出現這種情況,因為使用一次并不會使一個key成為熱點資料,
9、Redis有事務機制嗎?
有事務機制,Redis事務生命周期:
-
開啟事務:使用MULTI開啟一個事務
-
命令入佇列:每次操作的命令都會加入到一個佇列中,但命令此時不會真正被執行
-
提交事務:使用EXEC命令提交事務,開始順序執行佇列中的命令
10、Redis事務到底是不是原子性的?
先看關系型資料庫ACID 中關于原子性的定義:
**原子性:**一個事務(transaction)中的所有操作,要么全部完成,要么全部不完成,不會結束在中間某個環節,事務在執行程序中發生錯誤,會被恢復(Rollback)到事務開始前的狀態,就像這個事務從來沒有執行過一樣,
官方檔案對事務的定義:
-
事務是一個單獨的隔離操作:事務中的所有命令都會序列化、按順序地執行,事務在執行的程序中,不會被其他客戶端發送來的命令請求所打斷,
-
事務是一個原子操作:事務中的命令要么全部被執行,要么全部都不執行,EXEC 命令負責觸發并執行事務中的所有命令:如果客戶端在使用 MULTI 開啟了一個事務之后,卻因為斷線而沒有成功執行 EXEC ,那么事務中的所有命令都不會被執行,另一方面,如果客戶端成功在開啟事務之后執行 EXEC ,那么事務中的所有命令都會被執行,
官方認為Redis事務是一個原子操作,這是站在執行與否的角度考慮的,但是從ACID原子性定義來看,嚴格意義上講Redis事務是非原子型的,因為在命令順序執行程序中,一旦發生命令執行錯誤Redis是不會停止執行然后回滾資料,
11、Redis為什么不支持回滾(roll back)?
在事務運行期間雖然Redis命令可能會執行失敗,但是Redis依然會執行事務內剩余的命令而不會執行回滾操作,如果你熟悉mysql關系型資料庫事務,你會對此非常疑惑,Redis官方的理由如下:
只有當被呼叫的Redis命令有語法錯誤時,這條命令才會執行失敗(在將這個命令放入事務佇列期間,Redis能夠發現此類問題),或者對某個鍵執行不符合其資料型別的操作:實際上,這就意味著只有程式錯誤才會導致Redis命令執行失敗,這種錯誤很有可能在程式開發期間發現,一般很少在生產環境發現, 支持事務回滾能力會導致設計復雜,這與Redis的初衷相違背,Redis的設計目標是功能簡化及確保更快的運行速度,
對于官方的這種理由有一個普遍的反對觀點:程式有bug怎么辦?但其實回歸不能解決程式的bug,比如某位粗心的程式員計劃更新鍵A,實際上最后更新了鍵B,回滾機制是沒法解決這種人為錯誤的,正因為這種人為的錯誤不太可能進入生產系統,所以官方在設計Redis時選用更加簡單和快速的方法,沒有實作回滾的機制,
12、Redis事務相關的命令有哪幾個?
(1)WATCH
可以為Redis事務提供 check-and-set (CAS)行為,被WATCH的鍵會被監視,并會發覺這些鍵是否被改動過了, 如果有至少一個被監視的鍵在 EXEC 執行之前被修改了, 那么整個事務都會被取消, EXEC 回傳nil-reply來表示事務已經失敗,
(2)MULTI
用于開啟一個事務,它總是回傳OK,MULTI執行之后,客戶端可以繼續向服務器發送任意多條命令, 這些命令不會立即被執行,而是被放到一個佇列中,當 EXEC命令被呼叫時, 所有佇列中的命令才會被執行,
(3)UNWATCH
取消 WATCH 命令對所有 key 的監視,一般用于DISCARD和EXEC命令之前,如果在執行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被執行了的話,那么就不需要再執行 UNWATCH 了,因為 EXEC 命令會執行事務,因此 WATCH 命令的效果已經產生了;而 DISCARD 命令在取消事務的同時也會取消所有對 key 的監視,因此這兩個命令執行之后,就沒有必要執行 UNWATCH 了,
(4)DISCARD
當執行 DISCARD 命令時, 事務會被放棄, 事務佇列會被清空,并且客戶端會從事務狀態中退出,
(5)EXEC
負責觸發并執行事務中的所有命令:
如果客戶端成功開啟事務后執行EXEC,那么事務中的所有命令都會被執行,
如果客戶端在使用MULTI開啟了事務后,卻因為斷線而沒有成功執行EXEC,那么事務中的所有命令都不會被執行,需要特別注意的是:即使事務中有某條/某些命令執行失敗了,事務佇列中的其他命令仍然會繼續執行,Redis不會停止執行事務中的命令,而不會像我們通常使用的關系型資料庫一樣進行回滾,
13、什么是Redis主從復制?
主從復制,是指將一臺Redis服務器的資料,復制到其他的Redis服務器,前者稱為主節點(master),后者稱為從節點(slave);資料的復制是單向的,只能由主節點到從節點,
主從復制的作用
-
資料冗余:主從復制實作了資料的熱備份,是持久化之外的一種資料冗余方式,
-
故障恢復:當主節點出現問題時,可以由從節點提供服務,實作快速的故障恢復;實際上是一種服務的冗余,
-
負載均衡:在主從復制的基礎上,配合讀寫分離,可以由主節點提供寫服務,由從節點提供讀服務,分擔服務器負載;尤其是在寫少讀多的場景下,通過多個從節點分擔讀負載,可以大大提高Redis服務器的并發量,
-
高可用基石:主從復制還是哨兵和集群能夠實施的基礎,因此說主從復制是Redis高可用的基礎,
主從復制實作原理
主從復制程序主要可以分為3個階段:連接建立階段、資料同步階段、命令傳播階段,
連接建立階段
該階段的主要作用是在主從節點之間建立連接,為資料同步做好準備,
步驟1:保存主節點資訊
slaveof命令是異步的,在從節點上執行slaveof命令,從節點立即向客戶端回傳ok,從節點服務器內部維護了兩個欄位,即masterhost和masterport欄位,用于存盤主節點的ip和port資訊,
步驟2:建立socket連接
從節點每秒1次呼叫復制定時函式replicationCron(),如果發現了有主節點可以連接,便會根據主節點的ip和port,創建socket連接,
從節點為該socket建立一個專門處理復制作業的檔案事件處理器,負責后續的復制作業,如接收RDB檔案、接收命令傳播等,
主節點接收到從節點的socket連接后(即accept之后),為該socket創建相應的客戶端狀態,并將從節點看做是連接到主節點的一個客戶端,后面的步驟會以從節點向主節點發送命令請求的形式來進行,
步驟3:發送ping命令
從節點成為主節點的客戶端之后,發送ping命令進行首次請求,目的是:檢查socket連接是否可用,以及主節點當前是否能夠處理請求,
從節點發送ping命令后,可能出現3種情況:
(1)回傳pong:說明socket連接正常,且主節點當前可以處理請求,復制程序繼續,
(2)超時:一定時間后從節點仍未收到主節點的回復,說明socket連接不可用,則從節點斷開socket連接,并重連,
(3)回傳pong以外的結果:如果主節點回傳其他結果,如正在處理超時運行的腳本,說明主節點當前無法處理命令,則從節點斷開socket連接,并重連,
步驟4:身份驗證
如果從節點中設定了masterauth選項,則從節點需要向主節點進行身份驗證;沒有設定該選項,則不需要驗證,從節點進行身份驗證是通過向主節點發送auth命令進行的,auth命令的引數即為組態檔中的masterauth的值,
如果主節點設定密碼的狀態,與從節點masterauth的狀態一致(一致是指都存在,且密碼相同,或者都不存在),則身份驗證通過,復制程序繼續;如果不一致,則從節點斷開socket連接,并重連,
步驟5:發送從節點埠資訊
身份驗證之后,從節點會向主節點發送其監聽的埠號(前述例子中為6380),主節點將該資訊保存到該從節點對應的客戶端的slave_listening_port欄位中;該埠資訊除了在主節點中執行info Replication時顯示以外,沒有其他作用,
資料同步階段
主從節點之間的連接建立以后,便可以開始進行資料同步,該階段可以理解為從節點資料的初始化,具體執行的方式是:從節點向主節點發送psync命令(Redis2.8以前是sync命令),開始同步,
資料同步階段是主從復制最核心的階段,根據主從節點當前狀態的不同,可以分為全量復制和部分復制,后面再講解這兩種復制方式以及psync命令的執行程序,這里不再詳述,
命令傳播階段
資料同步階段完成后,主從節點進入命令傳播階段;在這個階段主節點將自己執行的寫命令發送給從節點,從節點接收命令并執行,從而保證主從節點資料的一致性,
需要注意的是,命令傳播是異步的程序,即主節點發送寫命令后并不會等待從節點的回復;因此實際上主從節點之間很難保持實時的一致性,延遲在所難免,資料不一致的程度,與主從節點之間的網路狀況、主節點寫命令的執行頻率、以及主節點中的repl-disable-tcp-nodelay配置等有關,
14、Sentinel(哨兵模式)的原理你能講一下嗎?
Redis 的主從復制模式下,一旦主節點由于故障不能提供服務,需要手動將從節點晉升為主節點,同時還要通知客戶端更新主節點地址,這種故障處理方式從一定程度上是無法接受的,
Redis 2.8 以后提供了 Redis Sentinel 哨兵機制來解決這個問題,
Redis Sentinel 是 Redis 高可用的實作方案,Sentinel 是一個管理多個 Redis 實體的工具,它可以實作對 Redis 的監控、通知、自動故障轉移,
Redis Sentinel架構圖如下:
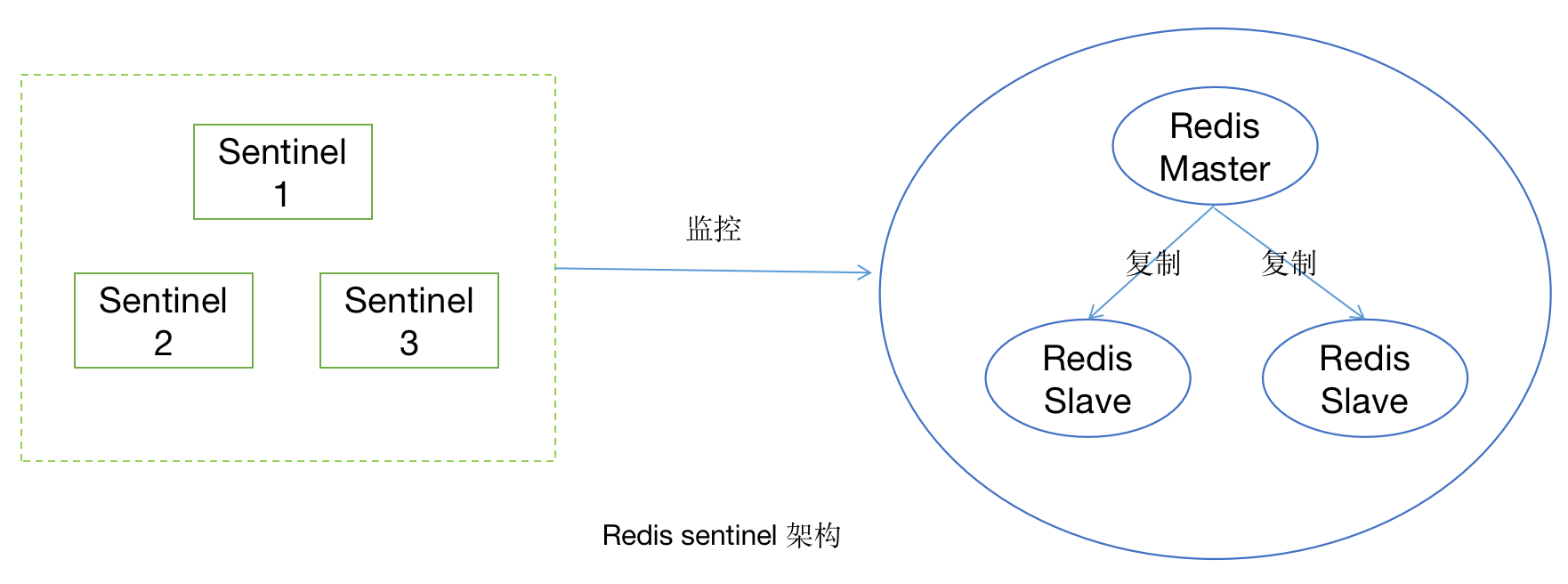
哨兵模式的原理
哨兵模式的主要作用在于它能夠自動完成故障發現和故障轉移,并通知客戶端,從而實作高可用,哨兵模式通常由一組 Sentinel 節點和一組(或多組)主從復制節點組成,
心跳機制
(1)Sentinel與Redis Node
Redis Sentinel 是一個特殊的 Redis 節點,在哨兵模式創建時,需要通過配置指定 Sentinel 與 Redis Master Node 之間的關系,然后 Sentinel 會從主節點上獲取所有從節點的資訊,之后 Sentinel 會定時向主節點和從節點發送 info 命令獲取其拓撲結構和狀態資訊,
(2)Sentinel與Sentinel
基于 Redis 的訂閱發布功能, 每個 Sentinel 節點會向主節點的 sentinel:hello 頻道上發送該 Sentinel 節點對于主節點的判斷以及當前 Sentinel 節點的資訊 ,同時每個 Sentinel 節點也會訂閱該頻道, 來獲取其他 Sentinel 節點的資訊以及它們對主節點的判斷,
通過以上兩步所有的 Sentinel 節點以及它們與所有的 Redis 節點之間都已經彼此感知到,之后每個 Sentinel 節點會向主節點、從節點、以及其余 Sentinel 節點定時發送 ping 命令作為心跳檢測, 來確認這些節點是否可達,
故障轉移
每個 Sentinel 都會定時進行心跳檢查,當發現主節點出現心跳檢測超時的情況時,此時認為該主節點已經不可用,這種判定稱為主觀下線,
之后該 Sentinel 節點會通過 sentinel ismaster-down-by-addr 命令向其他 Sentinel 節點詢問對主節點的判斷, 當 quorum(法定人數) 個 Sentinel 節點都認為該節點故障時,則執行客觀下線,即認為該節點已經不可用,這也同時解釋了為什么必須需要一組 Sentinel 節點,因為單個 Sentinel 節點很容易對故障狀態做出誤判,
這里 quorum 的值是我們在哨兵模式搭建時指定的,后文會有說明,通常為 Sentinel節點總數/2+1,即半數以上節點做出主觀下線判斷就可以執行客觀下線,
因為故障轉移的作業只需要一個 Sentinel 節點來完成,所以 Sentinel 節點之間會再做一次選舉作業, 基于 Raft 演算法選出一個 Sentinel 領導者來進行故障轉移的作業,
被選舉出的 Sentinel 領導者進行故障轉移的具體步驟如下:
(1)在從節點串列中選出一個節點作為新的主節點
-
過濾不健康或者不滿足要求的節點;
-
選擇 slave-priority(優先級)最高的從節點, 如果存在則回傳, 不存在則繼續;
-
選擇復制偏移量最大的從節點 , 如果存在則回傳, 不存在則繼續;
-
選擇 runid 最小的從節點,
(2)Sentinel 領導者節點會對選出來的從節點執行 slaveof no one 命令讓其成為主節點,
(3)Sentinel 領導者節點會向剩余的從節點發送命令,讓他們從新的主節點上復制資料,
(4)Sentinel 領導者會將原來的主節點更新為從節點, 并對其進行監控, 當其恢復后命令它去復制新的主節點,
15、Cluster(集群)的原理你能講一下嗎?
引入Cluster模式的原因:
不管是主從模式還是哨兵模式都只能由一個master在寫資料,在海量資料高并發場景,一個節點寫資料容易出現瓶頸,引入Cluster模式可以實作多個節點同時寫資料,
Redis-Cluster采用無中心結構,每個節點都保存資料,節點之間互相連接從而知道整個集群狀態,
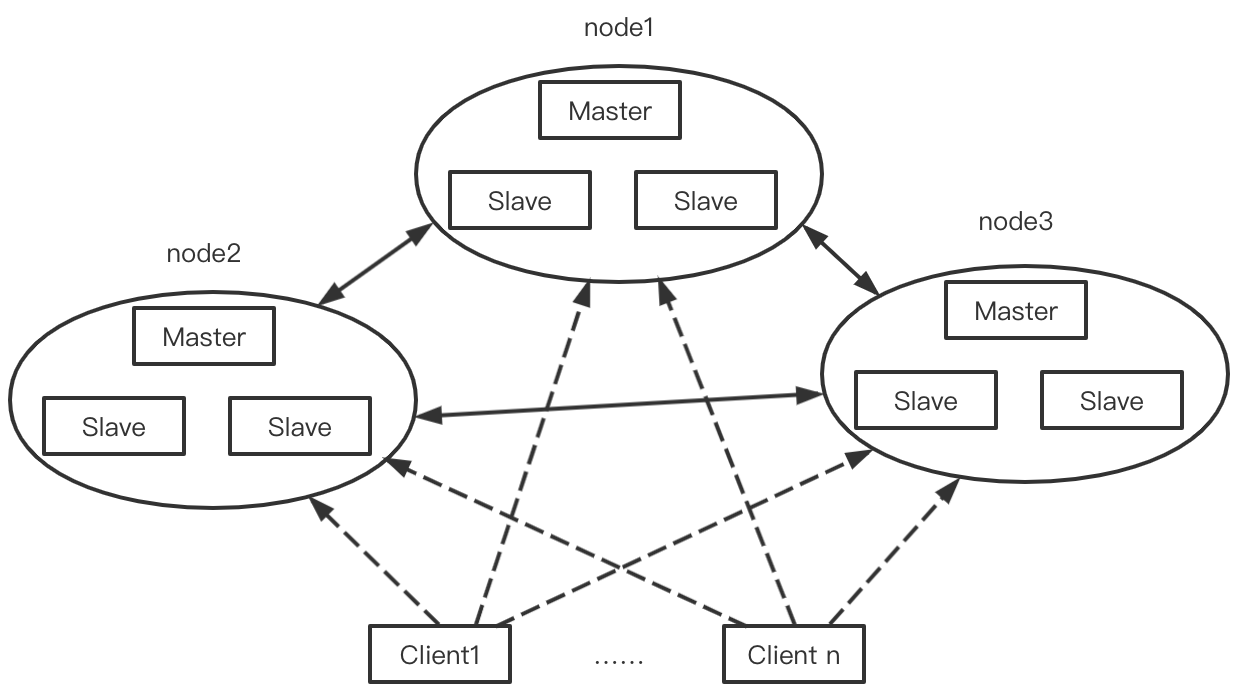
如圖所示Cluster模式其實就是多個主從復制的結構組合起來的,每一個主從復制結構可以看成一個節點,那么上面的Cluster集群中就有三個節點,
16、Memcache與Redis的區別都有哪些?
存盤方式
Memecache把資料全部存在記憶體之中,斷電后會掛掉,資料不能超過記憶體大小,
Redis有部份存在硬碟上,這樣能保證資料的持久性,
資料支持型別
Memcache對資料型別支持相對簡單,
Redis有豐富的資料型別,
使用底層模型不同
它們之間底層實作方式 以及與客戶端之間通信的應用協議不一樣,
Redis直接自己構建了VM 機制 ,因為一般的系統呼叫系統函式的話,會浪費一定的時間去移動和請求,
17、假如Redis里面有1億個key,其中有10w個key是以某個固定的已知的前綴開頭的,如果將它們全部找出來?
使用keys指令可以掃出指定模式的key串列:keys pre*,這個時候面試官會追問該命令對線上業務有什么影響,直接看下一個問題,
18、如果這個redis正在給線上的業務提供服務,那使用keys指令會有什么問題?
redis 的單執行緒的,keys 指令會導致線 程阻塞一段時間,線上服務會停頓,直到指令執行完畢,服務才能恢復,這個時 候可以使用 scan 指令,scan 指令可以無阻塞的提取出指定模式的 key 串列,但是會有一定的重復概率,在客戶端做一次去重就可以了,但是整體所花費的時間 會比直接用 keys 指令長,
19、如果有大量的key需要設定同一時間過期,一般需要注意什么?
如果大量的key過期時間設定的過于集中,到過期的那個時間點,Redis可能會出現短暫的卡頓現象(因為redis是單執行緒的),嚴重的話可能會導致服務器雪崩,所以我們一般在過期時間上加一個隨機值,讓過期時間盡量分散,
20、Redis常用的客戶端有哪些?
Jedis:是老牌的Redis的Java實作客戶端,提供了比較全面的Redis命令的支持,
Redisson:實作了分布式和可擴展的Java資料結構,
Lettuce:高級Redis客戶端,用于執行緒安全同步,異步和回應使用,支持集群,Sentinel,管道和編碼器,
優點:
Jedis:比較全面的提供了Redis的操作特性,
Redisson:促使使用者對Redis的關注分離,提供很多分布式相關操作服務,例如,分布式鎖,分布式集合,可通過Redis支持延遲佇列,
Lettuce:基于Netty框架的事件驅動的通信層,其方法呼叫是異步的,Lettuce的API是執行緒安全的,所以可以操 作單個Lettuce連接來完成各種操作,
-- END --
最后啰嗦兩句:
最近很多小伙伴詢問雷架有沒有學習資料,那雷架作為準架構師必然有啊,微信搜索"愛笑的架構師"關注公眾號,關注公眾號后回復數字666即可免費獲取,?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/135239.html
標籤:其他