面試官問:如何設計一個高并發系統?
說實話,如果面試官問你這個題目,那么你必須要使出全身吃奶勁了,為啥?因為你沒看到現在很多公司招聘的 JD 里都是說啥有高并發經驗者優先,
如果你確實有真才實學,在互聯網公司里干過高并發系統,那你確實拿 offer 基本如探囊取物,沒啥問題,面試官也絕對不會這樣來問你,否則他就是蠢,
假設你在某知名電商公司干過高并發系統,用戶上億,一天流量幾十億,高峰期并發量上萬,甚至是十萬,那么人家一定會仔細盤問你的系統架構,你們系統啥架構?怎么部署的?部署了多少臺機器?快取咋用的?MQ 咋用的?資料庫咋用的?就是深挖你到底是如何扛住高并發的,
因為真正干過高并發的人一定知道,脫離了業務的系統架構都是在紙上談兵,真正在復雜業務場景而且還高并發的時候,那系統架構一定不是那么簡單的,用個 redis,用 mq 就能搞定?當然不是,真實的系統架構搭配上業務之后,會比這種簡單的所謂“高并發架構”要復雜很多倍,
如果有面試官問你個問題說,如何設計一個高并發系統?那么不好意思,一定是因為你實際上沒干過高并發系統,面試官看你簡歷就沒啥出彩的,感覺就不咋地,所以就會問問你,如何設計一個高并發系統?其實說白了本質就是看看你有沒有自己研究過,有沒有一定的知識積累,
最好的當然是招聘個真正干過高并發的哥兒們咯,但是這種哥兒們人數稀缺,不好招,所以可能次一點的就是招一個自己研究過的哥兒們,總比招一個啥也不會的哥兒們好吧!
所以這個時候你必須得做一把個人秀了,秀出你所有關于高并發的知識!
阿里內部絕密《百億級并發系統設計》
真沒干過高并發系統?沒有高并發實戰經驗?沒關系,這次我冒著被開除的風險給大家分享一份阿里內部絕密資料《百億級并發系統設計》,擼完這份資料絕對能夠讓你在面試官面前挺起腰桿!
實戰教程共分為基礎篇+資料庫篇+快取篇+訊息佇列篇+分布式服務篇+維護篇+實戰篇,干貨滿滿
由于篇幅原因,文章只介紹大概內容,請轉發+關注,然后添加VX(tkzl6666)獲得這份阿里內部絕密資料《百億級并發系統架構》實戰教程完整版的免費領取方式,(承若百分之百免費喲)
一、基礎篇
01 | 高并發系統:它的通用設計方法是什么?
我們知道,高并發代表著大流量,高并發系統設計的魅力就在于我們能夠憑借自己的聰明才智設計巧妙的方案,從而抵抗巨大流量的沖擊,帶給用戶更好的使用體驗,這些方案好似能操縱流量,讓流量更加平穩得被系統中的服務和組件處理,

02 | 架構分層:我們為什么一定要這么做?
在 系統從 0 到 1 的階段,為了讓系統快速上線,我們通常是不考慮分層的,但是隨著業務越來越復雜,大量的代碼糾纏在一起,會出現邏輯不清晰、各模塊相互依賴、代碼擴展性差、改動一處 就牽一發而動全身等問題,這時,對系統進行分層就會被提上日程,那么我們要如何對架構進行分層?架構分層和高并發架構設計又有什么關系呢?本章將帶你尋找答案,

03 | 系統設計目標(一):如何提升系統性能?
04 | 系統設計目標(二):系統怎樣做到高可用?
05 | 系統設計目標(三):如何讓系統易于擴展?
提到互聯網系統設計,你可能聽到最多的詞兒就是“三高”,也就是“高并發”“高性能”“高可用”,它們是互聯網系統架構設計永恒的主題,在前兩章中,帶你了解了高并發系統設計的含義,意義以及分層設計原則,接下來,帶你整體了解一下高并發系統設計的目標

06 | 面試現場第一期:當問到組件實作原理時,面試官是在刁難你嗎?

資料庫篇
07 | 池化技術:如何減少頻繁創建資料庫連接的性能損耗?
正式進入演進篇,會再從區域出發,帶你逐一了解完成這些目標會使用到的一些方法,這些方法會針對性地解決高并發系統設計中出現的問題,比如,在15 講中我會提及布隆過濾器,這個組件就是為了解決存在大量快取穿透的情況下,如何盡量提升快取命中率的問題

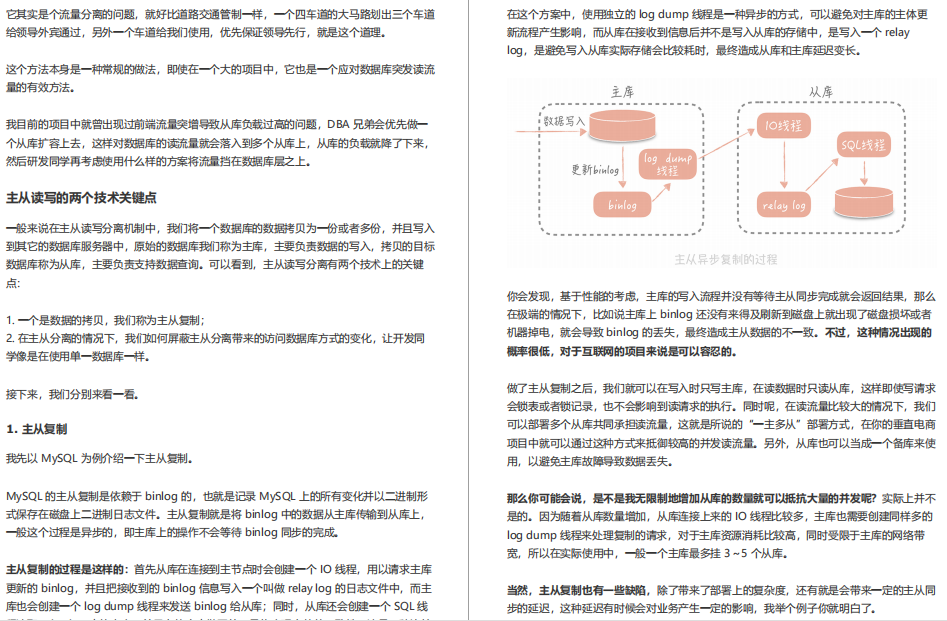
08 | 資料庫優化方案(一):查詢請求增加時,如何做主從分離?
09 | 資料庫優化方案(二):寫入資料量增加時,如何實作分庫分表?
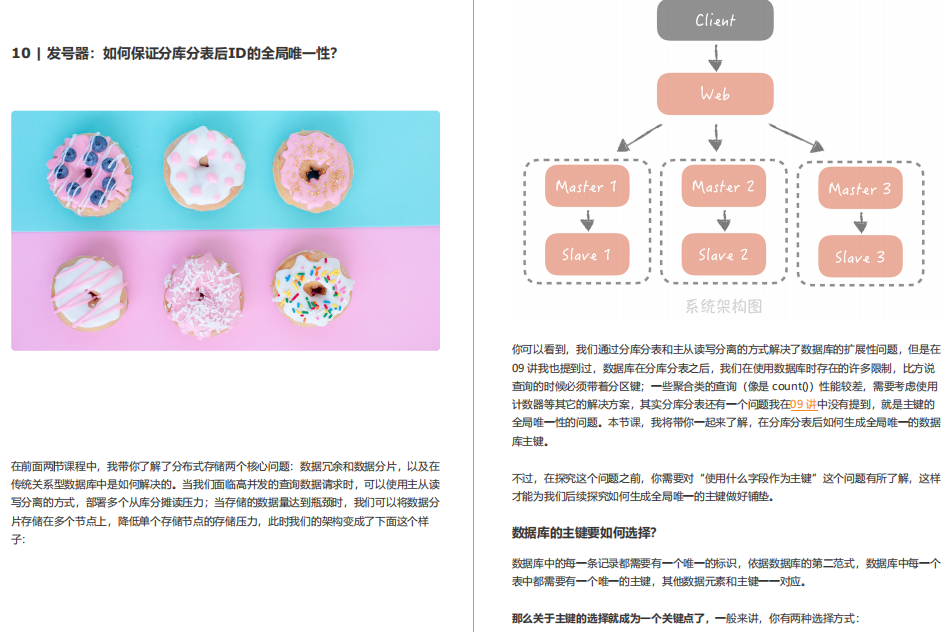
10 | 發號器:如何保證分庫分表后ID的全域唯一性?
11 | NoSQL:在高并發場景下,資料庫和NoSQL如何做到互補?
以你的垂直電商系統為例,帶你掌握如何用 NoSQL 資料庫和關系型資料庫互補,共同承擔高并發和大流量的沖擊,

由于篇幅原因,文章只介紹大概內容,請轉發+關注,然后私信回復我關鍵字 “666” 獲得這份阿里內部絕密資料《百億級并發系統架構》實戰教程完整版的免費領取方式,(承諾百分之百免費喲)
快取篇
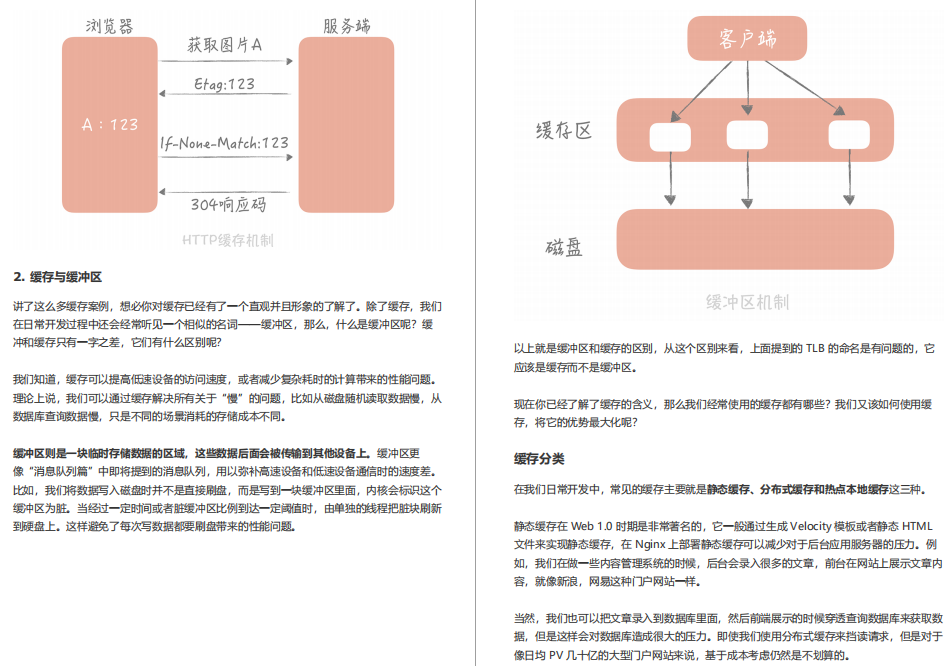
12 | 快取:資料庫成為瓶頸后,動態資料的查詢要如何加速?
本章是快取篇的總綱,將從快取定義、快取分類和快取優勢劣勢三個方面全方位帶你掌握快取的設計思想和理念,再用剩下的 4 章,帶你針對性地掌握使用快取的正確姿勢,以便讓你在實際作業中能夠更好地使用快取提升整體系統的性能,
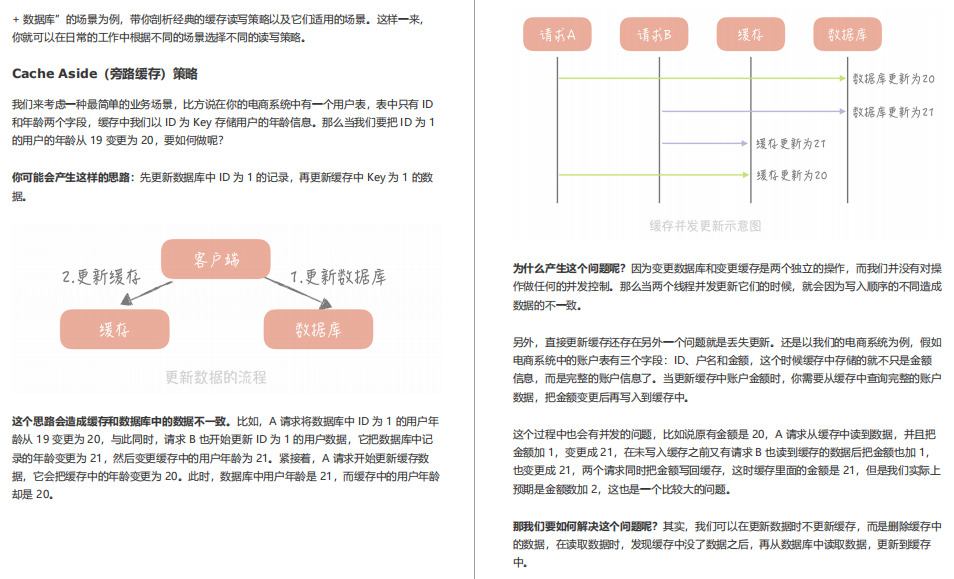
13 | 快取的使用姿勢(一):如何選擇快取的讀寫策略?
14 | 快取的使用姿勢(二):快取如何做到高可用?
15 | 快取的使用姿勢(三):快取穿透了怎么辦?
前面帶你了解了快取的定義、分類以及不足,你現在應該對快取有了初步的認知,從這章,我將帶你了解一下使用快取的正確姿勢,比如快取的讀寫策略是什么樣的,如何做到快取的高可用以及如何應對快取穿透,通過了解這些內容,你會對快取的使用有深刻的認識,這樣在實際作業中就可以在快取使用上游刃有余了,
16 | CDN:靜態資源如何加速?

訊息佇列篇
17 | 訊息佇列:秒殺時如何處理每秒上萬次的下單請求?
我們如何用訊息佇列解決秒殺場景下的問題呢?接下來,我們來結合具體的例子來看看訊息佇列在秒殺場景下起到的作用
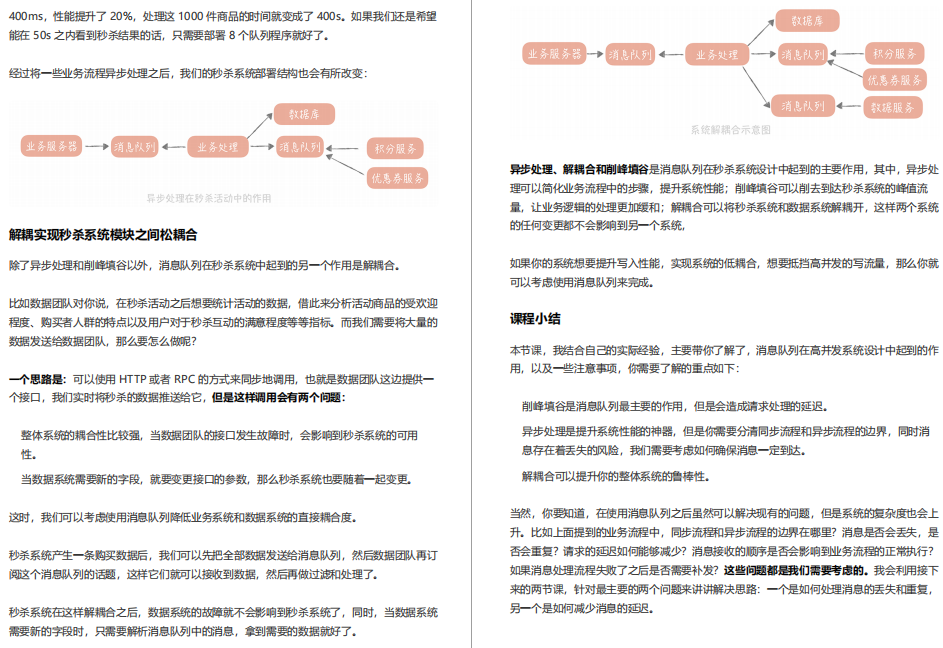
18 | 訊息投遞:如何保證訊息僅僅被消費一次?
我們如何保證,產生的訊息一定會被消費到,并且只被消費一次呢?這個問題雖然聽起來很淺顯,很好理解,但是實際上卻藏著很多玄機,本節我就帶你深入探討
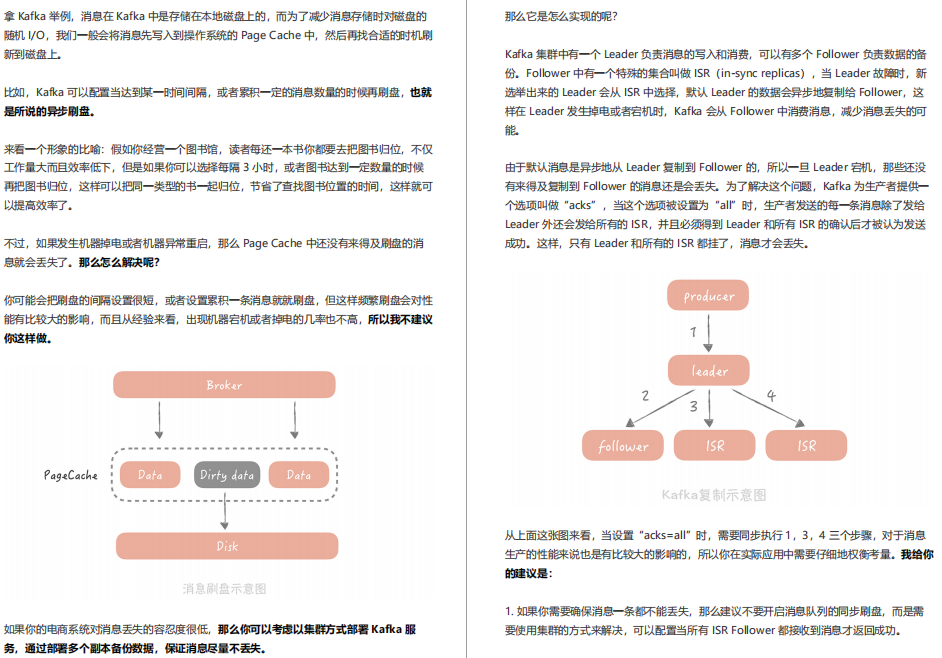
19 | 訊息佇列:如何降低訊息佇列系統中訊息的延遲?
學完前面兩節之后,相信你對在垂直電商專案中,如何使用訊息佇列應對秒殺時的峰值流量已經有所了解,當然了,你也應該知道要如何做,才能保證訊息不會丟失,盡量避免訊息重復帶來的影響,那么我你思考一下:除了這些內容,你在使用訊息佇列時還需要關注哪些點呢?
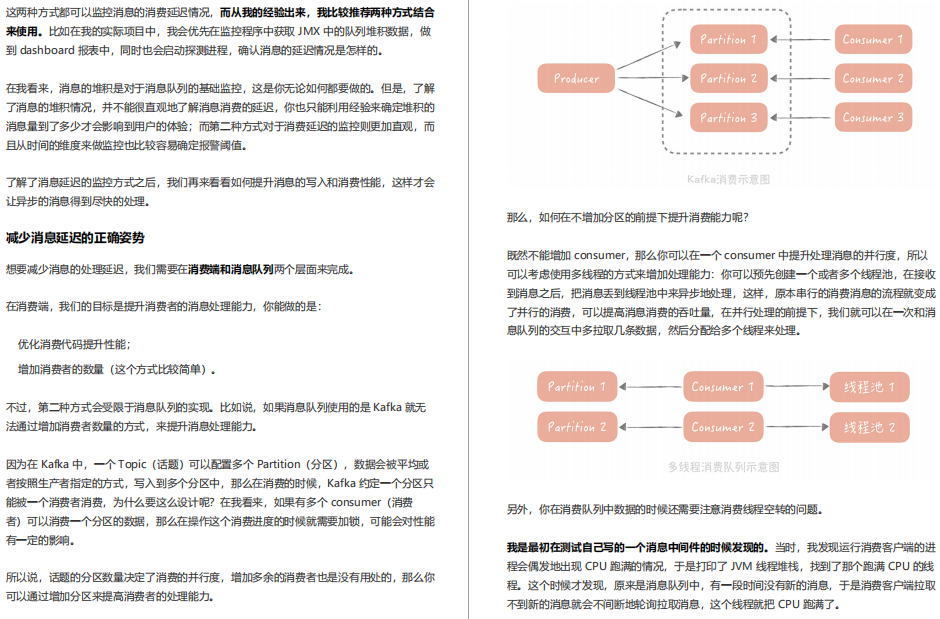
20 | 面試現場第二期:當問到專案經 歷時,面試官究竟想要了解什么?

由于篇幅原因,文章只介紹大概內容,請轉發+關注,然后添加VX(tkzl6666)獲得這份阿里內部絕密資料《百億級并發系統架構》實戰教程完整版的免費領取方式,(承若百分之百免費喲)
分布式服務篇
21 | 系統架構:每秒1萬次請求的系統要做服務化拆分嗎?

22 | 微服務架構:微服務化后,系統架構要如何改造?

23 | RPC框架:10萬QPS下如何實作毫秒級的服務呼叫?

24 | 注冊中心:分布式系統如何尋址?

25 | 分布式Trace:橫跨幾十個分布式組件的慢請求要如何排查?

26 | 負載均衡:怎樣提升系統的橫向擴展能力?

27 | API網關:系統的門面要如何做呢?
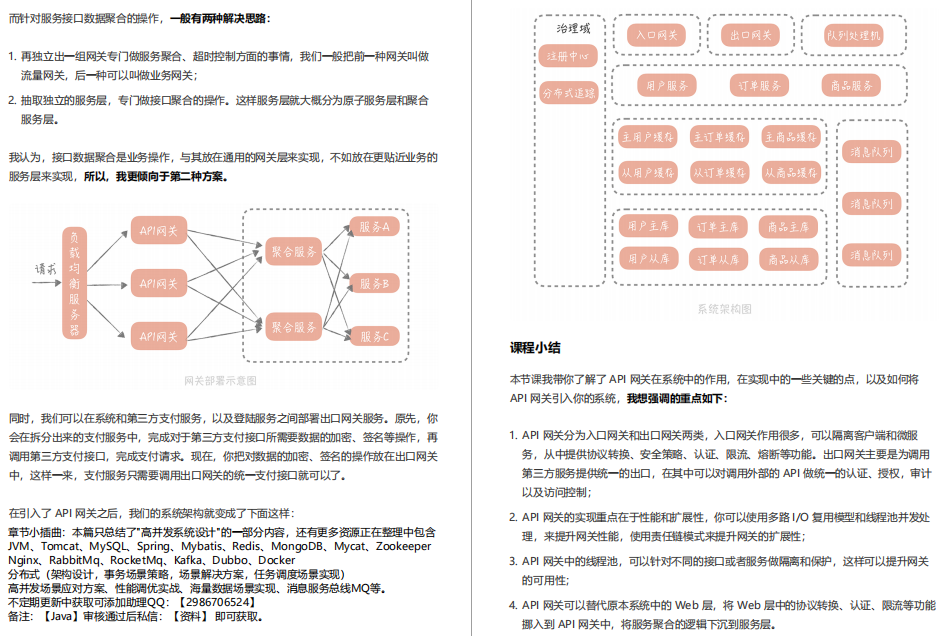
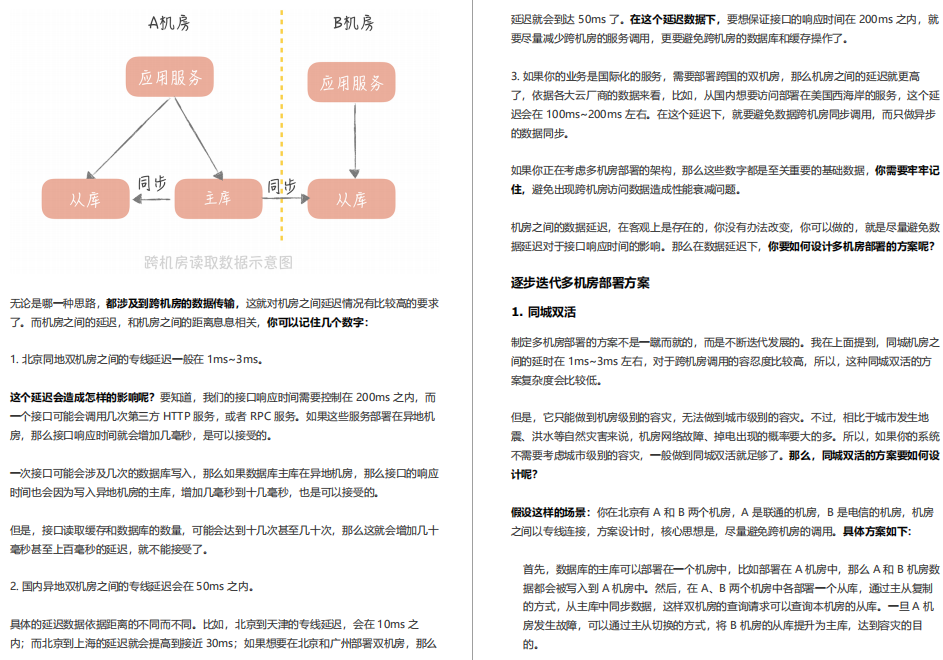
28 | 多機房部署:跨地域的分布式系統如何做?
29 | Service Mesh:如何屏蔽服務化系統的服務治理細節?

由于篇幅原因,文章只介紹大概內容,請轉發+關注,然后添加VX(tkzl6666) 獲得這份阿里內部絕密資料《百億級并發系統架構》實戰教程完整版的免費領取方式,(承諾百分之百免費喲)
維護篇
30 | 給系統加上眼睛:服務端監控要怎么做?

31 | 應用性能管理:用戶的使用體驗應該如何監控?

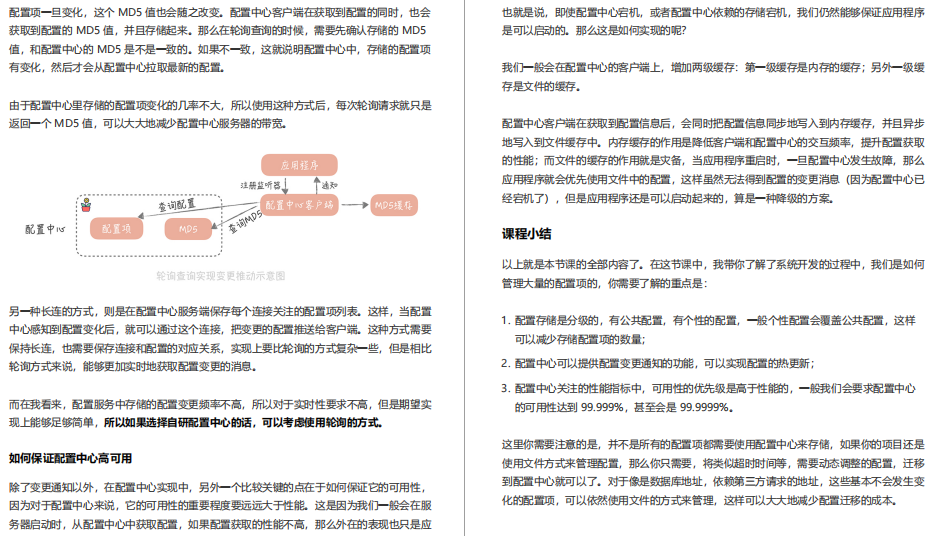
32 | 壓力測驗:怎樣設計全鏈路壓力測驗平臺?
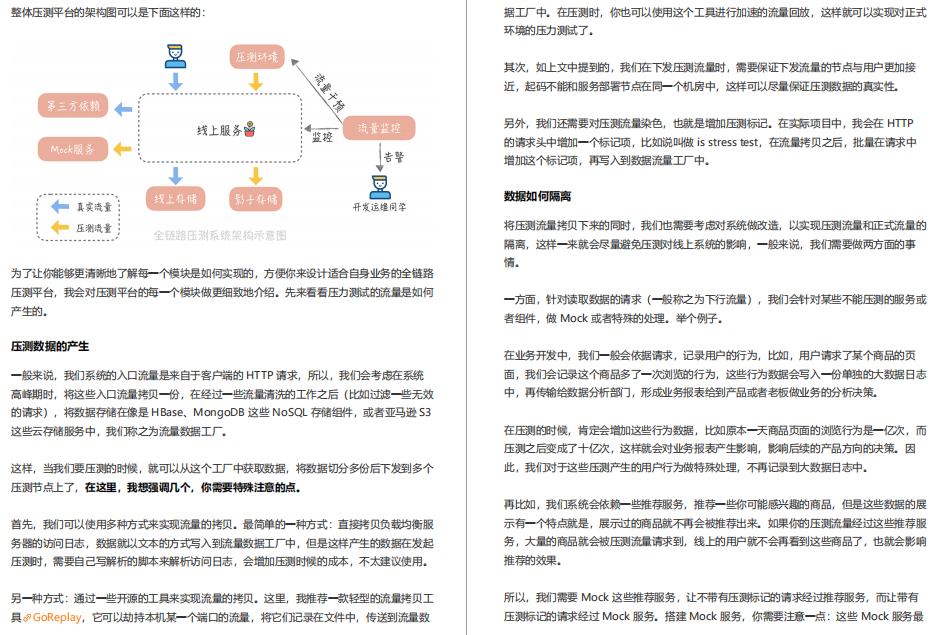
33 | 配置管理:成千上萬的配置項要如何管理?
34 | 降級熔斷:如何屏蔽非核心系統故障的影響?

35 | 流量控制:高并發系統中我們如何操縱流量?

36 | 面試現場第三期:你要如何準備一場技術面試呢?
實戰篇
37 | 計數系統設計(一):面對海量資料的計數器要如何做?

38 | 計數系統設計(二):50萬QPS下如何設計未讀數系統?

39 | 資訊流設計(一):通用資訊流系統的推模式要如何做?

40 | 資訊流設計(二):通用資訊流系統的拉模式要如何做?

由于篇幅原因,文章只介紹大概內容,請轉發+關注,然后添加VX(tkzl6666) 獲得這份阿里內部絕密資料《百億級并發系統架構》實戰教程完整版的免費領取方式,(承諾百分之百免費喲)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/135248.html
標籤:其他