寫在前面:
(閱讀本文前需要了解KMP演算法的基本思路,另外,本著大道至簡的思想,本文的所有例子都會做從頭到尾的講解)
在翻閱了大量網上現有的KMP演算法博客后,發現廣為流傳的竟然是一種不完整的KMP演算法,即通過next陣列來作為有限狀態自動機,以此實作非匹配時的回退,雖然這不失為一種好的方法,
但我想介紹一種更好和更完整的方法————擁有完整DFA的KMP演算法
先列出本文要介紹的方法與一般方法對比下的幾大優點:
- 在最壞情況下,對字串的操作次數僅為一般做法的三分之二,
- 在所有情況下,對字串的運算元都小于等于一般做法,
- 思路上相對于一般做法更加完整細致,學習了它一定能讓你對kmp有一個全新的認識,
(讀者可以在通讀全文之后回頭來看這幾句話到底對不對)
一、關于有限狀態自動機(什么是DFA)
kmp演算法模擬了有限狀態自動機的運行,一般演算法中的next陣列和本文中的dfa陣列都是作為有限狀態自動機的運行指導,
有限狀態自動機不同,程式運行起來自然會存在不同,
在本文介紹的KMP演算法中,我們使用二維陣列DFA來作為有限狀態自動機指導:
- 定義:DFA=new int[R][M],R為文本可能出現的字符種類(EXTENDED_ASCII的R為256位,一般情況下是夠用了),M為模式字串的長度,
- 空間:DFA占用空間上比next陣列大了R倍,但空間的犧牲必然要迎來性能上的提升!
- 儲存內容:和next陣列一樣的是,DFA也儲存了每個位置匹配失敗時模式串的重啟位置,但它更加詳細,DFA針對了匹配失敗時可能出現的不同字符對應了其特定的重啟位置,這樣的好處在后面的性能分析中會降到,
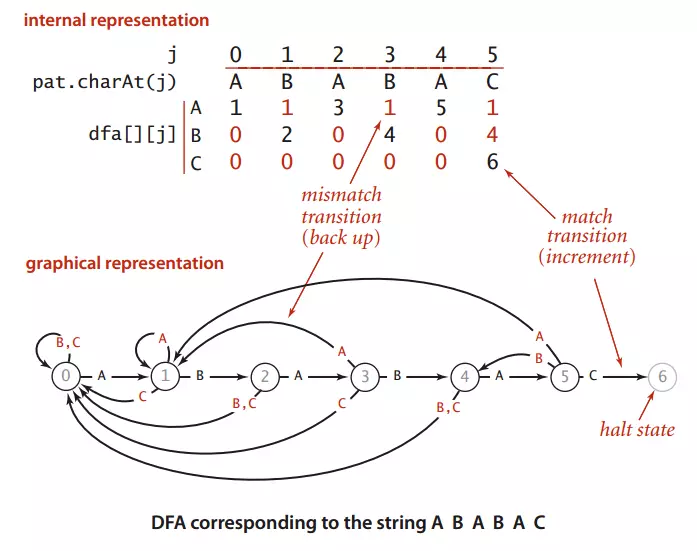
圖1 和模式字串ABABAC對應的確定有限狀態機自動機
圖一展示了模式字串pat:ABABAC對應的確定有限狀態機自動機
dfa[A][j]表示:模式串成功匹配到第j個位置時文本這時對應字符為'A'的情況下模式串下一個將要匹配的位置,
拿圖1來說,dfa[A][3]表示匹配到模式串ABABAC的第三位時(B),文本對應的是A,這時模式串將回到dfa[A][3]=1,也就是將模式串回到ABABAC的第一位(B),然后繼續下一位(也是就ABABAC中的第二位,這里是A)與文本的下一位繼續比較,
似乎蠻復雜的,但理解了它的構造方法之,你就可以靈活使用它,
1、dfa的構造方法:
我們需要借助j和X來構造dfa,j指向當前的匹配位置,X是匹配失敗時的重啟位置,一開始j和X都設為0,
對于每個j,我們要做的是:
- 將daf[][X]復制到daf[][j](對于匹配失敗的情況)
- 將daf[pat.charAt(j)][j]設為j+1(對于匹配成功的情況)
- 更新X
用代碼表示如下:
(推薦讀者先大概看看代碼,再結合下面給出的完整例子,然后做代碼運行除錯)
dfa[pat.charAt(0)][0]=1;
for(int X=0,j=1;j<M;j++){//計算dfa[][j]
for(int c=0;c<R;c++){//不匹配情況
dfa[c][j]=dfa[c][X];
}
dfa[pat.charAt(j)][j]=j+1;
X=dfa[pat.charAt(j)][X];
}
在上面代碼的基礎上來演示一個完整的構造程序:
① j和X都為0,dfa[pat.charAt(0)][0]=1
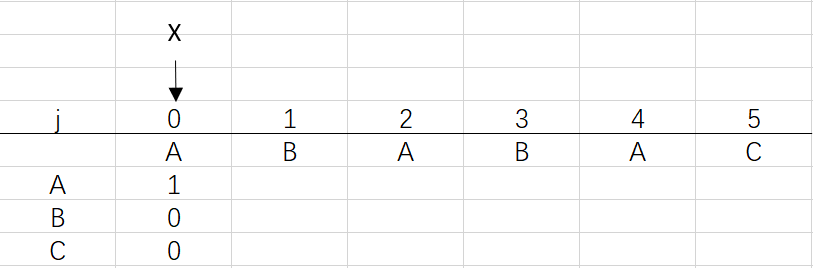
② 進入for回圈X=0,j=1:將X的列復制到j的列,再設dfa[pat.charAt(j)][j]=j+1,更新X
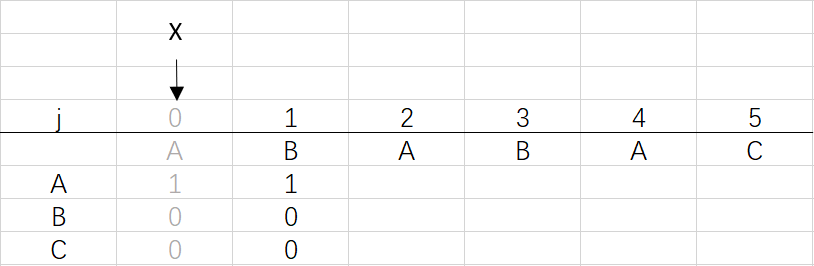
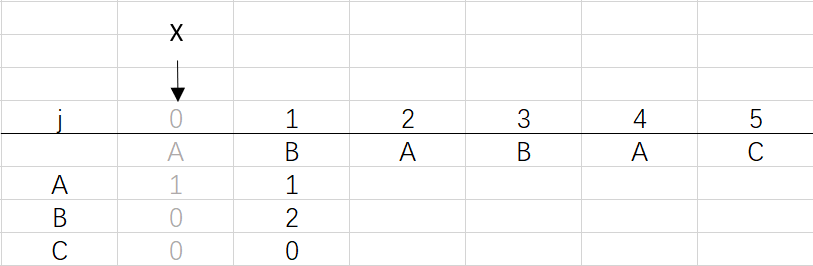
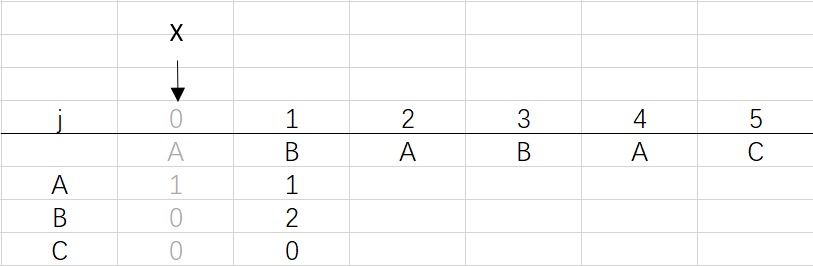
可以看到第三步更新X后X還是0,因為在第二步時X=dfa[pat.charAt(j)][X]=dfa[B][0]=0 (關于X變化的探討接下來就會提到)
③ 第二次回圈X=0,j=2:將X的列復制到j的列,再設dfa[pat.charAt(j)][j]=j+1,更新X
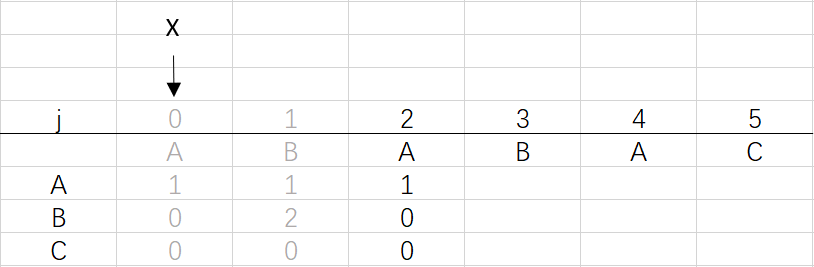
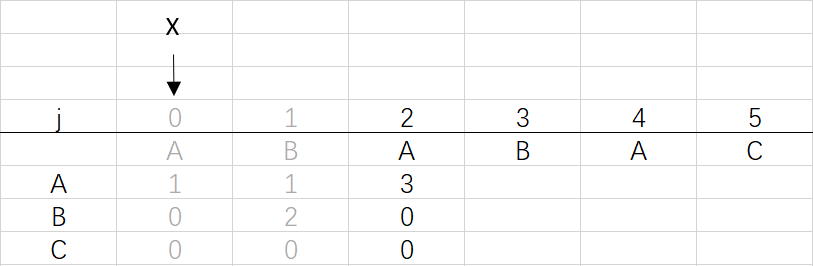
X=dfa[pat.charAt(j)][X]=dfa[A][0]=1
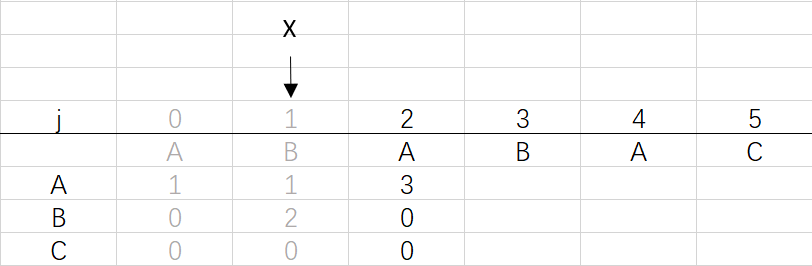
④ 第三次回圈X=1,j=3:將X的列復制到j的列,再設dfa[pat.charAt(j)][j]=j+1,更新X
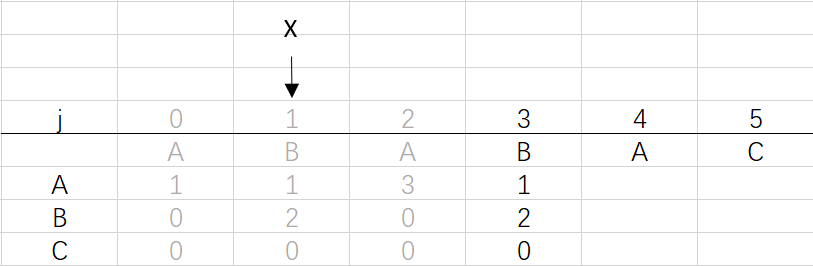
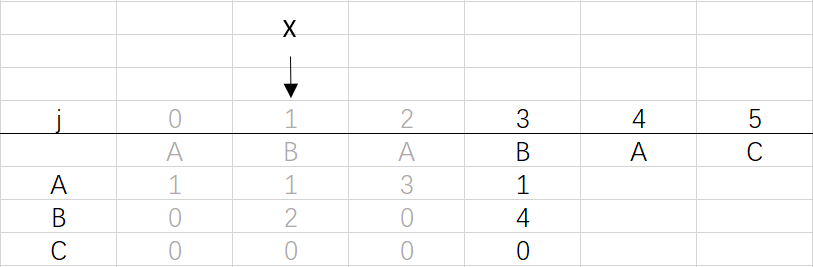
X=dfa[pat.charAt(j)][X]=dfa[B][1]=2
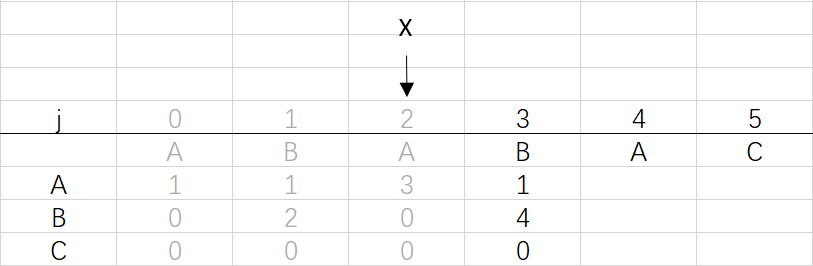
⑤ 第四次回圈X=2,j=4:將X的列復制到j的列,再設dfa[pat.charAt(j)][j]=j+1,更新X
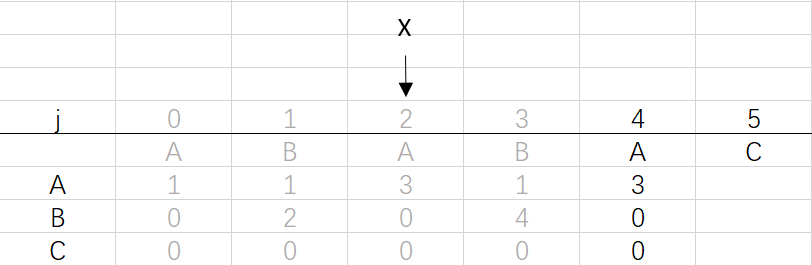
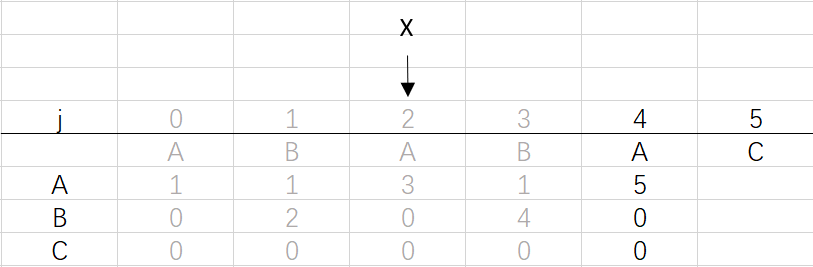
X=dfa[pat.charAt(j)][X]=dfa[A][2]=3
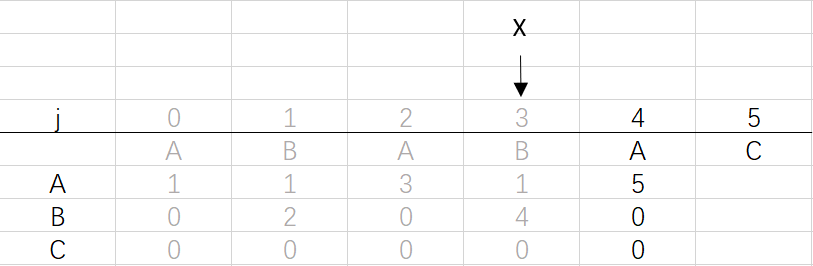
⑥ 第四次回圈X=3,j=5:將X的列復制到j的列,再設dfa[pat.charAt(j)][j]=j+1,已經結束到最后一位,不用更新X
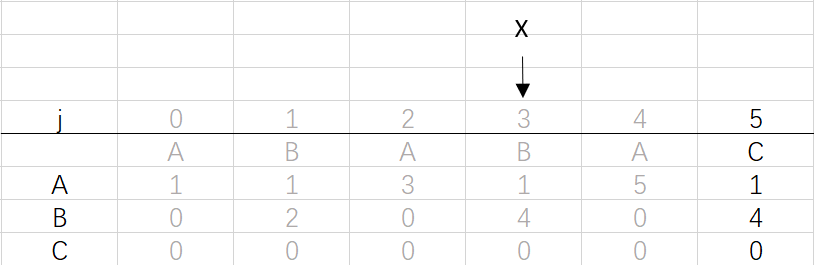
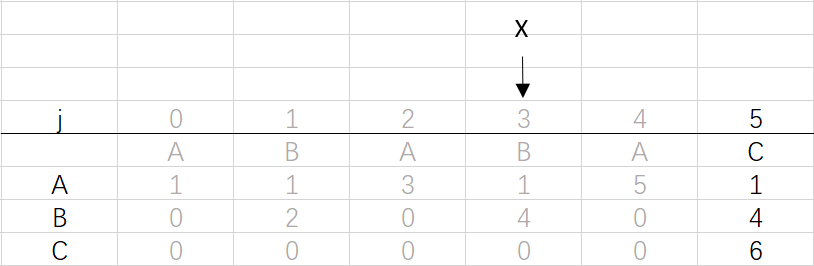
到這里就結束了模式字串ABABAC的dfa構造最終得到的結果:
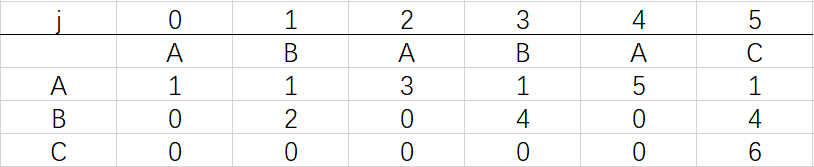
相信大家已經明白了dfa的構造思路
為鞏固練習,下面請讀者自己構造出模式字串ABRACAD的daf,然后和下圖對照一下是不是一樣
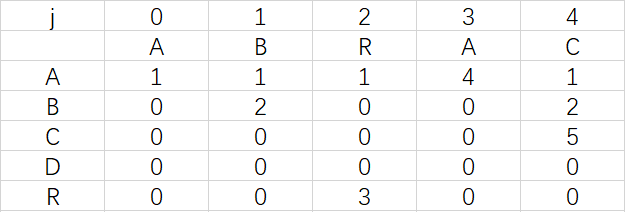
2、關于X的一些問答:
值得一提的是,X是構造dfa的關鍵,下面幾個問答有助于我們理解整個dfa構造,
為什么每次都能得出X的值?
答:因為X永遠小于j,X走的是j走的老路,
為什么要把X列復制到j列?
答:dfa里記錄了到每種狀態時可能的所有選擇,如果狀態A發生不匹配時可以回到狀態B繼續匹配,那我們就可以先把狀態B復制到狀態A,這樣在狀態A不匹配時就可以直接使用狀態B的方案,
X的位置何時會發生變化?
X的下一個位置與j當前指向的字符、j之前指向過的字符、X當前位置都有關,事實上不管j當前指向的字符在之前是否出現過,X都可能移動,
X的位置會怎么變化?
當每次j指向的字符與X指向的字符能夠連續對應上的時候,X就會每次向后移一位(字符與前綴對應時X往后移),
當j指向的字符在之前沒有出現過,X就會指向0,
3、實體對問題的證明:
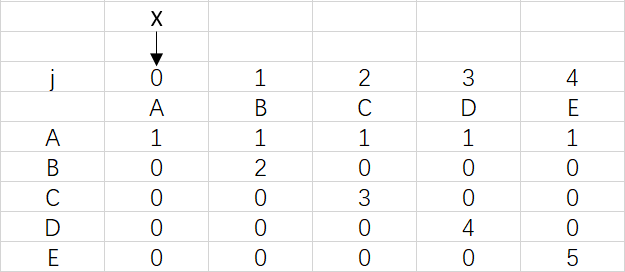
上圖是模式ABCDE的dfa陣列,可以觀察到ABCDE中是沒有出現重復字符的,所以到最后X依然指向0
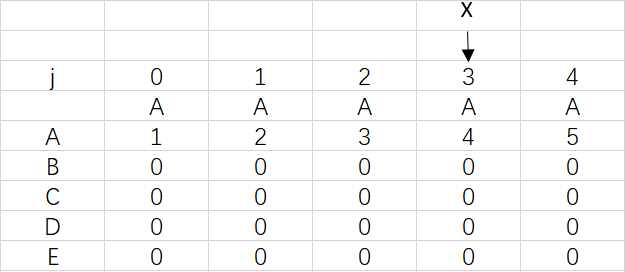
對應極端情況,前面的字符出現重復達到了四次,X也是要移動四次,但只停留在3是因為模式串已經匹配完成,不需要再移動X,
關于X的移動,是需要讀者自己在模擬dfa構造中細想的,想明白了就能全懂KMP,不明白就再看看上面的問題,嘗試自己作答就會有新的心得,
二、改變搜索方法
有了強大的有限狀態自動機,怎么用它呢?實際使用中是否比原來更強大呢?咱直接將兩者的代碼貼出來一頓對比,順便說明精妙之處,
大體的思路是一樣的,就是將txt字串從頭到尾回圈一遍,程序中不斷判斷模式串的位置
1、先來看看一般方法中的搜索方法代碼:
for(i=0;i<n;i++){ while (j>-1&&txt.charAt(i)!=pat.charAt(j)){ j=next[j]; } if(j==-1||txt.charAt(i)==pat.charAt(j)){ j++; } if(j==m){return i-j; } }
一邊從頭到尾回圈,一邊判斷j是不是等于m,應該注意到的是,for回圈中還包含了一個while,用來做回退和繼續匹配的,
可以發現,這個程序中的操作次數必定是要大于i的(每次for回圈都可能要加入while)
2、下面是使用dfa后的搜索方法:
for(j=0,i=0;i<N&&j<M;i++){
j=dfa[txt.charAt(i)][j];
}
if(j==M){
System.out.println("匹配成功");
return i-M;
}else {
System.out.println("匹配失敗");
return N;
}
可以看到,在for回圈之后,直接進行匹配成功或失敗的判斷,整個程序的操作次數等于i,是小于一般方法的,
三、性能分析對比
①當字串不匹配時(這是兩種方法差異最大的地方):
使用DFA二維陣列作為有限狀態自動機,每次不匹配時都能到達精準位置(對每個不匹配的情況dfa都有記錄在案),
而使用next一維陣列時,在每次匹配失敗后到達的位置是不能確認的,它只是先到達可能的位置,
從可能的最長前綴位置,進行字符的匹配,如果不匹配再移到下一位可能的位置(下標在模式字串上往前移),
②當字串匹配時
在兩種方式中是一樣的,i和j都加一,然后進入下一個for回圈,
②最壞情況什么時候出現
對于一般方法:如果文本為AAAA,模式串為AAAB,這時匹配到最后一位時失敗,j會一步步往前走,這時在搜索方法中操作次數達到了2n,加上構造next陣列的n次操作,共3n次操作,
對于完整KMP演算法:上面的情況并不會使它達到3n,因為在j一步步往前走的時候i也會往后走,當i達到n時for回圈結束,這樣最多也就操作n次,加上dfa陣列的構造需要n次,共2n次操作,
結果:
可以看到,在通常情況下完整KMP演算法的操作次數要比一般演算法的操作次數少
即便是在最壞情況下完整KMP演算法的操作次數也為一般方法的三分之二,
足以證明完整KMP的性能是更優的,
四、完整實作及測驗代碼(java)
1 public class KMP { 2 private String pat; 3 private int dfa[][]; 4 5 public KMP(String pat){//由模式字串構建dfa 6 this.pat=pat; 7 int M=pat.length(); 8 int R=256; 9 dfa=new int[R][M]; 10 dfa[pat.charAt(0)][0]=1; 11 for(int X=0,j=1;j<M;j++){//計算dfa[][j] 12 for(int c=0;c<R;c++){//不匹配情況 13 dfa[c][j]=dfa[c][X]; 14 } 15 dfa[pat.charAt(j)][j]=j+1; 16 X=dfa[pat.charAt(j)][X]; 17 } 18 } 19 20 public int search(String txt){ 21 int N= txt.length(); 22 int M=pat.length(); 23 int j,i; 24 for(j=0,i=0;i<N&&j<M;i++){ 25 j=dfa[txt.charAt(i)][j]; 26 } 27 if(j==M){ 28 System.out.println("匹配成功"); 29 return i-M; 30 }else { 31 System.out.println("匹配失敗"); 32 return N; 33 } 34 } 35 }
測驗例子:
1 @Test 2 public void KMPTest(){ 3 KMP kmp=new KMP("abc"); 4 System.out.println(kmp.search("abfeabcabc")); 5 }
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/137179.html
標籤:其他
上一篇:桶排序