樹、森林與二叉樹的轉換
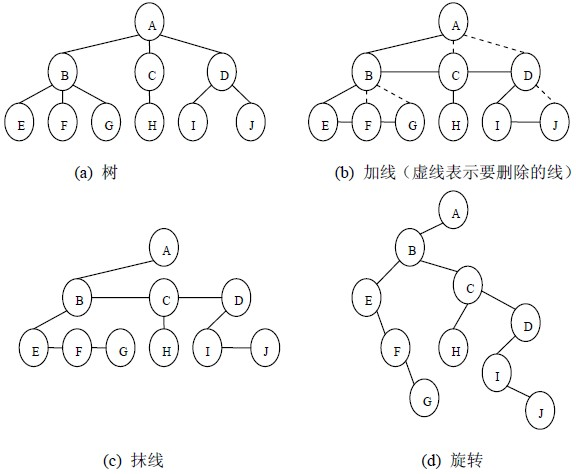
1、樹轉換為二叉樹
由于二叉樹是有序的,為了避免混淆,對于無序樹,我們約定樹中的每個結點的孩子結點按從左到右的順序進行編號,
將樹轉換成二叉樹的步驟是:
(1)加線,就是在所有兄弟結點之間加一條連線;
(2)抹線,就是對樹中的每個結點,只保留他與第一個孩子結點之間的連線,洗掉它與其它孩子結點之間的連線;
(3)旋轉,就是以樹的根結點為軸心,將整棵樹順時針旋轉一定角度,使之結構層次分明,
2、森林轉換為二叉樹
森林是由若干棵樹組成,可以將森林中的每棵樹的根結點看作是兄弟,由于每棵樹都可以轉換為二叉樹,所以森林也可以轉換為二叉樹,
將森林轉換為二叉樹的步驟是:
(1)先把每棵樹轉換為二叉樹;
(2)第一棵二叉樹不動,從第二棵二叉樹開始,依次把后一棵二叉樹的根結點作為前一棵二叉樹的根結點的右孩子結點,用線連接起來,當所有的二叉樹連接起來后得到的二叉樹就是由森林轉換得到的二叉樹,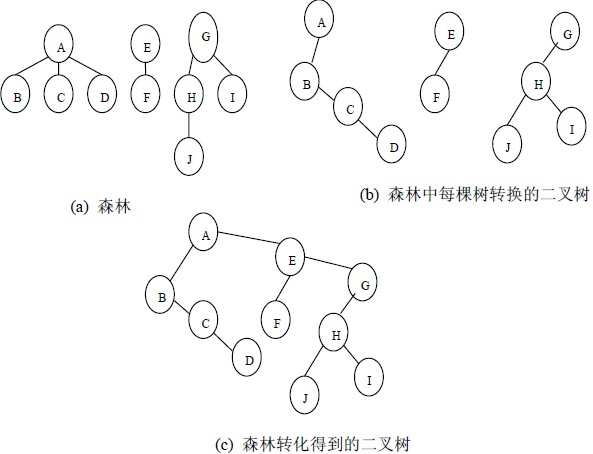
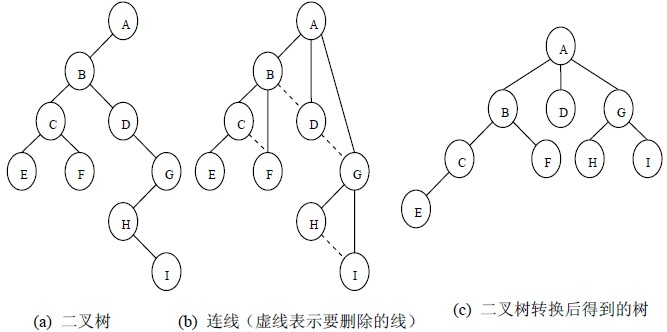
3、二叉樹轉換為樹
二叉樹轉換為樹是樹轉換為二叉樹的逆程序,其步驟是:
(1)若某結點的左孩子結點存在,將左孩子結點的右孩子結點、右孩子結點的右孩子結點……都作為該結點的孩子結點,將該結點與這些右孩子結點用線連接起來;
(2)洗掉原二叉樹中所有結點與其右孩子結點的連線;
(3)整理(1)和(2)兩步得到的樹,使之結構層次分明,
什么是哈夫曼樹?(最優二叉樹)
一. 目的:找出存放一串字符所需的最少的二進制編碼
二. 原理:首先統計出每種字符出現的頻率!(也可以是概率)//權值
讓我們先舉一個例子,
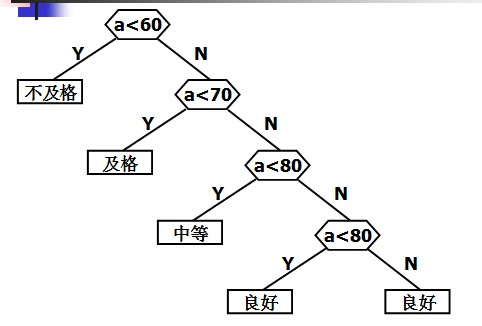
判定樹:
在很多問題的處理程序中,需要進行大量的條件判斷,這些判斷結構的設計直接影響著程式的執行效率,例如,編制一個程式,將百分制成績轉換成五個等級輸出,若考慮上述程式所耗費的時間,就會發現該程式的缺陷,在實際中,學生成績在五個等級上的分布是不均勻的,當學生百分制成績的錄入量很大時,上述判定程序需要反復呼叫,此時程式的執行效率將成為一個嚴重問題,
但在實際應用中,往往各個分數段的分布并不是均勻的,下面就是在一次考試中某門課程的各分數段的分布情況:

第一種構造方式:
第二種構造方式:

定義哈夫曼樹之前先說明幾個與哈夫曼樹有關的概念:
路徑: 樹中一個結點到另一個結點之間的分支構成這兩個結點之間的路徑,
路徑長度: 路徑上的分枝數目稱作路徑長度,
樹的路徑長度: 從樹根到每一個結點的路徑長度之和,
結點的帶權路徑長度:在一棵樹中,如果其結點上附帶有一個權值,通常把該結點的路徑長度與該結點上的權值之積 稱為該結點的帶權路徑長度(weighted path length)
什么是權值? ?( From 百度百科 )
計算機領域中(資料結構)
權值就是定義的路徑上面的值,可以這樣理解為節點間的距離,通常指字符對應的二進制編碼出現的概率,
至于霍夫曼樹中的權值可以理解為:權值大表明出現概率大!
一個結點的權值實際上就是這個結點子樹在整個樹中所占的比例.
abcd四個葉子結點的權值為7,5,2,4. 這個7,5,2,4是根據實際情況得到的,比如說從一段文本中統計出abcd四個字母出現的次數分別為7,5,2,4. 說a結點的權值為7,意思是說a結點在系統中占有7這個份量.實際上也可以化為百分比來表示,但反而麻煩,實際上是一樣的.
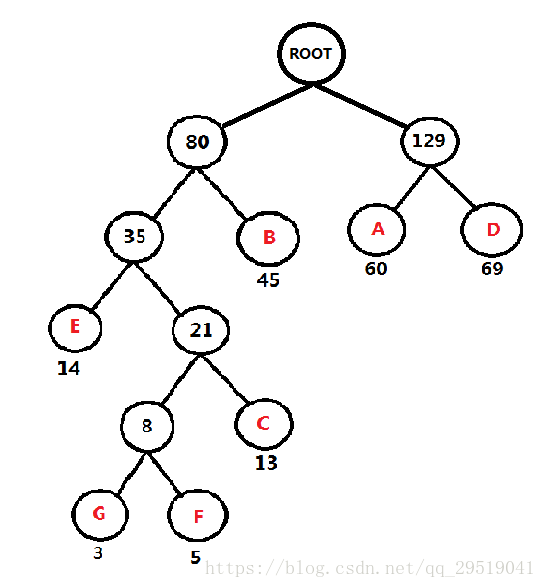
例如:頻率表 A:60, B: 45, C: 13 D: 69 E: 14 F: 5 G: 3
第一步:找出字符中最小的兩個,小的在左邊,大的在右邊,組成二叉樹,
在頻率表中洗掉此次找到的兩個數,并加入此次最小兩個數的頻率和
F和G最小,因此如圖,從字串頻率計數中洗掉F與G,并回傳F與G的和 8給頻率表
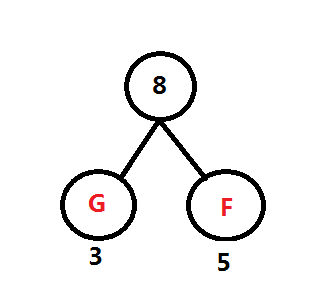
重復第一步:
頻率表 A:60, B:45, C:13 D:69 E:14 FG:8
最小的是 FG:8 與 C:13,因此如圖,并回傳FG 與 C的和:21給頻率表,
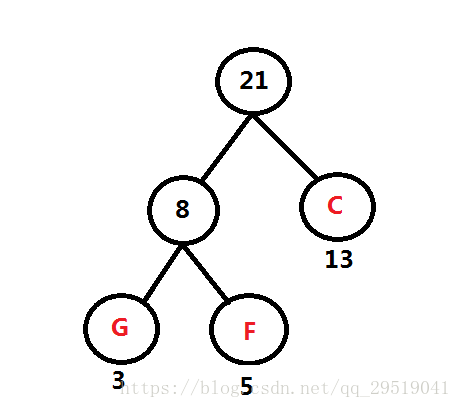
重復第一步:
頻率表 A:60 B: 45 D: 69 E: 14 FGC: 21
如圖
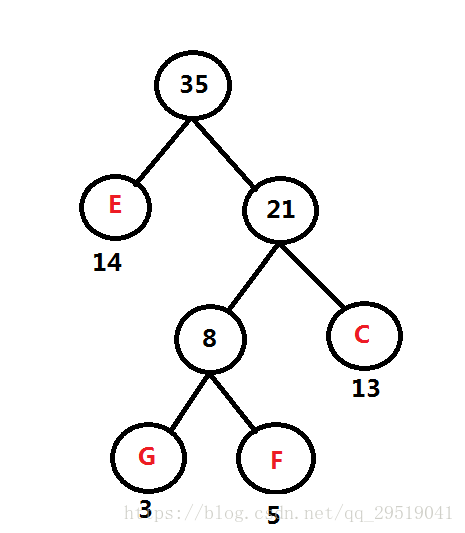
重復第一步
頻率表 A:60 B: 45 D: 69 FGCE: 35
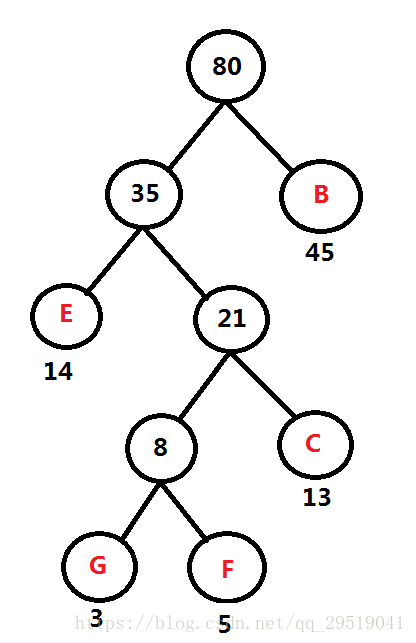
重復第一步
頻率表 A:60 D: 69 FGCEB: 80
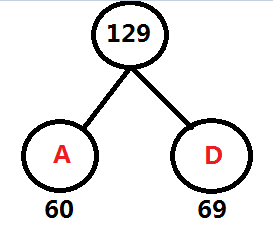
重復第一步
頻率表 AD:129 FGCEB: 80
添加 0 和 1,規則左0 右1
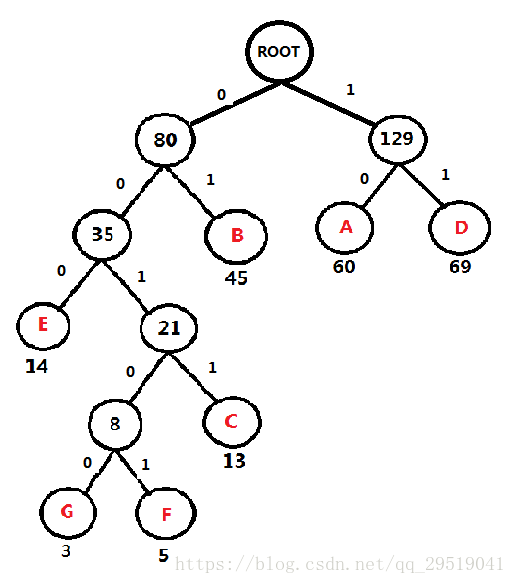
頻率表 A:60, B:45, C:13 D:69 E:14 F:5 G:3
每個字符的二進制編碼為(從根節點 數到對應的葉子節點,路徑上的值拼接起來就是葉子節點字母的應該的編碼)
A:10
B:01
C:0011
D:11
E:000
F:00101
G:00100
那么當我想傳送 ABC時,編碼為 10 01 0011
補充一下白話版:
大家觀察 出現得越多的字母,他的編碼越短 ,出現頻率越少的字母,他的編碼越長,
在資訊傳輸程序中,如果這個字母越多,那么我們希望他越瘦小(編碼短)這樣占用的編碼越少,其實編碼長的字母也是讓頻率比它多的字母把編碼短的位子都占用后,他才去占用當前最短的編碼,至此讓總的編碼長度最短,
且要保證長編碼的不與短編碼的字母沖突:
比如 不能出現 讀碼 讀到 01 還有長編碼的 字母為011,如果短編碼為一個長編碼的左起子串,這就是沖突,意思就是說讀到當前位置已經能確定是什么字母時不能因為再讀取一位或幾位讓這個編碼能表示另外的字母,
但哈夫曼樹(最優二叉樹)在構造的時候就避免了這個問題,為什么能避免呢,因為哈夫曼樹的它的字母都在葉子節點上,因此不會出現一個字母的編碼為另一個字母編碼左起子串的情況,
----原文補充----
我再補充一下:
為什么要保證長編碼不與短編碼沖突?
沖突情況:如果我們已經確定D,E,F,G 用 01 ,010 ,10,001的2進制編碼來傳輸了,那么想傳送FED時,我需要傳送1001001,接收方可以把它決議為FDG,當然也能決議為FED,他兩編碼一樣的,這就是編碼沖突,顯然這是不行的,就像我說壓脈帶,你如果是日本人會理解為 (你懂得),這就是發出同一種語,得出不同的意的情況,所以不能讓一個字母的二進制代表數,為另一個字母的二進制代表數的子串,但為什么實際要求只是左起子串呢而不是絕對意義上的子串呢,因為計算機從數字串的左邊開始讀,如果從右邊讀,那么可以是右起(無奈),你又可以問了為什么是左起或右起不直接規定不能是子串呢,比如說原文中B就是C,F,G的子串,那這不就不符合規則了么,這里是為了哈夫曼的根本目的,優化編碼位占用問題,如果完全不能有任何子串那么編碼將會非常龐大,但這里計算機是一位一位的·讀取編碼的,只需要保證計算機在讀取中不會誤判就行,并且編碼占用最少,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/138124.html
標籤:其他