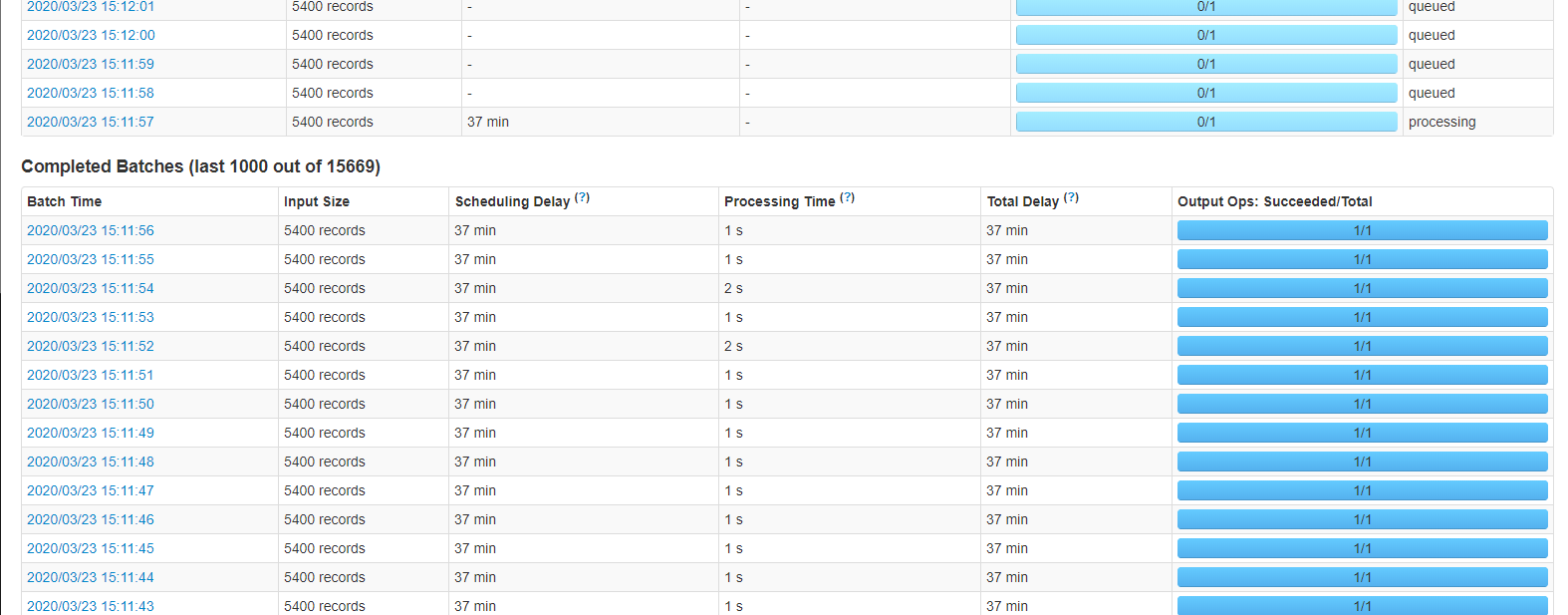
關于圖上的堆積問題,SchedulingDelay 越來越長是任務佇列出了什么問題么?
程式啟動時正常的,運行幾天就會開始堆積,偶爾會自己緩過來,若果直接重啟程式的話也會正常。
很多情況是因為某一個批次突然ProcessingTime特別長,接下來的批次SchedulingDelay 就開始延長,ProcessingTime又恢復正常,
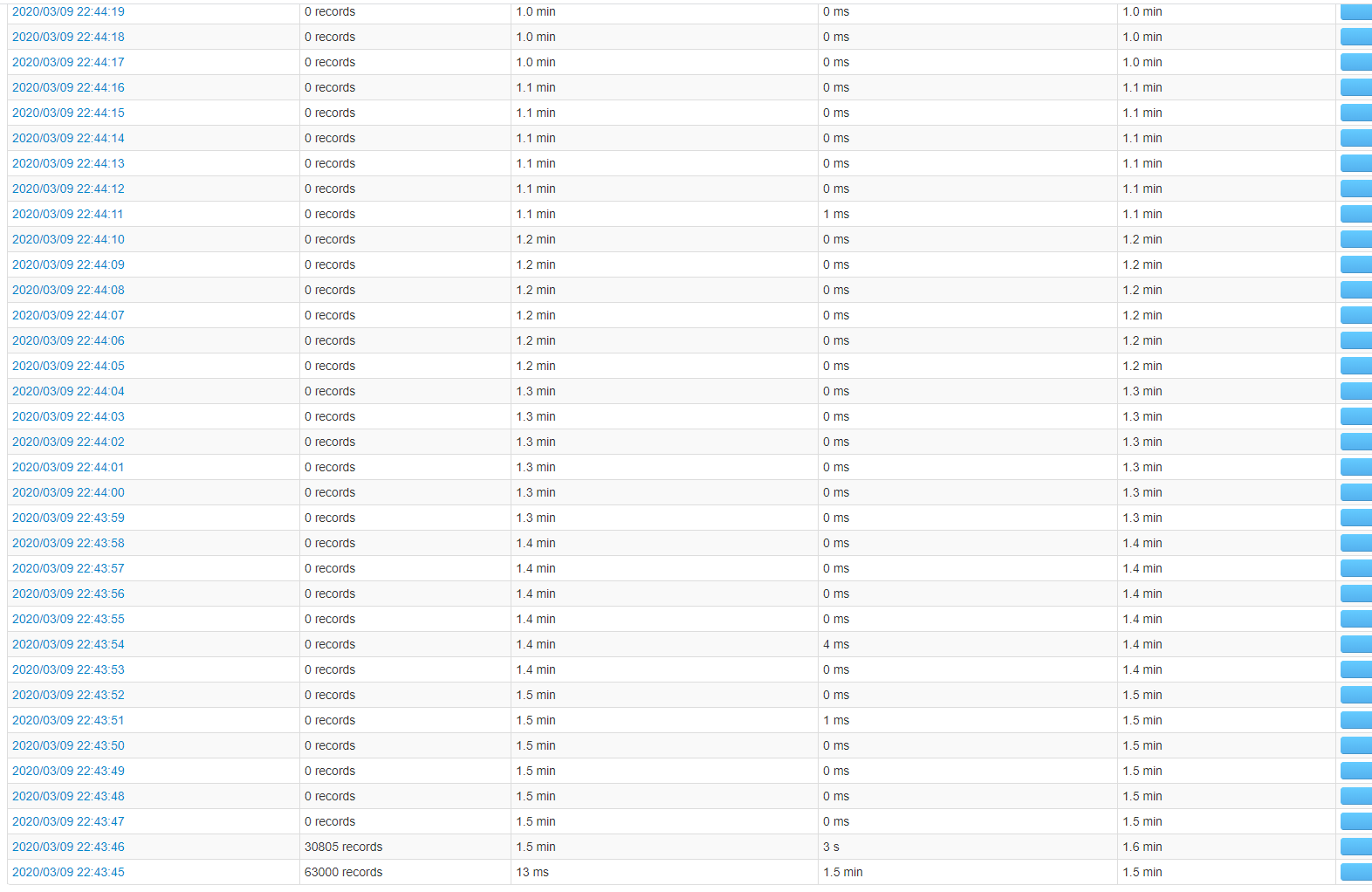
就出現圖上的情況,像第二張圖。
uj5u.com熱心網友回復:
并非是batchtime設定太短了,配置不變的情況下,在正常情況是能夠1秒2秒就處理完的,但還是會出現堆積情況uj5u.com熱心網友回復:
看最后一圖的最后幾行,明顯是出現資料洪峰導致資料傾斜了。而圖一顯示平均是5400events。考慮修改一下spark streaming配置,以進行削縫。關鍵配置是:
spark.streaming.receiver.maxRate=#每秒最多多少條events
具體見:
http://spark.apache.org/docs/latest/configuration.html#spark-streaming
根據實際情況調優。
uj5u.com熱心網友回復:
對于突然洪峰,然后后面很久都是每批0條,有可能是上游資料遲到了。跟上游訊息發布者溝通一下是什么情況?uj5u.com熱心網友回復:
謝謝關注啊,抱歉新手對問題考慮的不太全面,有一點忘了說了,這兩個圖其實不是同一個程式的,第二張沒資料是為了看0條資料時的情況。
關于這個問題確實是資料洪峰導致的,不過問題是第一批洪峰資料 處理了2min,導致后面批次SchedulingDelay調度時間延遲,但是處理時間卻是1s,這就看不明白了
uj5u.com熱心網友回復:
建議開啟FAIR調度,并設定每個job最大executor數,此數為(總executor數/n)。這樣job就可以并發。根據處理效率(處理時間小于視窗時間)調整n值。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14165.html
標籤:Spark