前言
雙非渣碩,本以為簡歷都過不了...,還好位元組能給一次機會,前陣子位元組跳動的提前批開始了,看宣傳是說有海量HC,機會多多,本著漲漲面經的心理,然后就投遞了一下杭州那邊的Data部門,首先在這里還要非常感謝內推我的小哥哥,非常熱心的幫我跟蹤進度,因為中間還出了一些小插曲(我投錯部門了,,,),還是熱心的小哥哥幫我聯系HR,最后把我轉到想要投遞的部門了,我投的是java后端開發~面試專案大部分問題是圍繞我的開源專案 蘑菇博客 展開的,還有就是我之前準備面試的一些 筆記(大佬請輕噴..)

面試時間
HR面完后,等了一個禮拜多,以為涼涼了,沒想到收到驚喜,許愿成功~
- 第一天:第一面 + 第二面
- 等了兩天:第三面 + HR面
- 過了一周后:等來了意向書
第一面
第一面我覺得應該是基礎面,重點考察的是自己技術的廣度 和一些技術的掌握情況,一面小哥哥也沒有深究于某個特定的點,面試時間大約1個小時,
- 自我介紹
- 怎么打算投遞后臺崗位的,沒有考慮契合自己研究方向的作業
- 有了解過OAuth2.0么,說說你對OAuth2.0的理解
- 蘑菇博客開發程序中,有了解或學習其它的開源框架么
- 蘑菇博客文章發布的流程是怎么樣的,是多人博客系統么
- 對其它的一些博客框架有了解么,比如hexo
- hexo和蘑菇博客相比有什么區別呢?蘑菇博客多了哪些功能和優勢
- 看你蘑菇博客用到了RabbitMQ,那談談為什么引入RabbitMQ?
- RabbitMQ和其它訊息佇列,比如ActiveMQ,RocketMQ,Kafka有什么區別
- Redis在你博客專案中的使用,為什么引入Redis?
- Redis中存盤的是熱門文章,是通過什么來得到的?這樣做會有什么問題么?
- 有聽過長尾效應么?你通過推薦欄位設定的推薦等級,這樣會讓這些文章一直保持在較高的點擊量,而且熱度和點擊量也不會隨著時間而降低,有什么解決方案么?
- 我看到你有用到JustAuth這個登錄授權?說說它會存在賬號泄漏的問題么?
- 下面談談Redis,它會存在執行緒切換的問題么?
- 談談Redis單執行緒模型和IO多路復用
- Redis的大Key的問題,如果有個Value的大小是2M,會有什么問題么?最大支持的Value大小是多少?
- 談談Redis集群 Redis Cluster,以及主從復制原理?
- 說說Redis中的哨兵,即Redis Sentinel
- 下面來聊聊Linux,你知道Linux怎么查看當前的負載情況么?
- 你還知道其它的一些Linux命令么?
- cat、tail、vi、vim命令的區別,分別說一說?
- 如果Linux下需要打開或者查看大檔案,你會怎么做?
- 下面聊聊Http Code,你知道 3XX 狀態碼 對應的是什么?
- 再談談你知道的其它一些狀態碼,4XX 和 5XX?
- 下面我們來做個題目吧?語言任意,選擇喜歡的(ps:其實是leetCode原題,沒有做過類似的,想了幾分鐘沒有思路,哭,,,想問問思路,然后說換一題吧,那就,事后想想還挺簡單的,根據第一位排序一下就好了)
# 給定一個陣列,例如 [1,1,2,2,2,3,3,3,3]這樣的,里面的陣列不一定連續并且有序,假設我輸入 2,這個2表示出現次數最高的兩個
# 那么你需要給我回傳 2,3- 那就換個題目吧,看看下面這個題目,找陣列出現次數最多的TOP N,回頭聽室友說,好像又是leetcode原題,淚目,演算法能力太弱,沒怎么刷題,
# 給定一個陣列,例如 [1,1,2,2,2,3,3,3,3]這樣的,里面的陣列不一定連續并且有序,假設我輸入 2,這個2表示出現次數最高的兩個
# 那么你需要給我回傳 2,3然后我最開始的思路就是,通過hash存盤出現的次數,然后key就是陣列中出現的值,最后再對hash中的次數進行排序,最后得到top N,因為時間復雜度是O(N^2),問有沒有優化思路,能否優化到O(N),想了半天沒有想出來,沒有充分運用以及構建好的hash表
后面面試官給講了一下思路,從陣列長度向下遍歷進行查找
- 反問環節,問了問面試的表現,被告知演算法能力比較薄弱,以為就此涼涼,,,然后一面說這邊可以讓你進入下一環節,這邊大概需要等5到10分鐘左右
第二面
二面考察的是技術深度面試,面試時間大約50分鐘左右
- 自我介紹
- 博客已經開源了么,用的什么開源協議,博客的用戶多么?
- 看你博客中用到了Solr和ElasticSearch,談談它們的原理,以及倒排索引?
- 對于Solr或者ES里面用到的一些中文分詞器有了解過么?
- 談談那些技術堆疊,你比較熟悉的是那些,mysql 和redis?
- 聊聊MySQL的底層索引結構,InnoDB里面的B+Tree?
- B Tree 和 B+ Tree的區別
- 聊聊MySQL索引的發展程序?是一來就是B+Tree的么?從 沒有索引、hash、二叉排序樹、AVL樹、B樹、B+樹 聊,
- 談談MySQL里面的事務,說說什么是事務?
- MySQL里面有那些事務級別,并且不同的事務級別會出現什么問題?
- 談談可重復讀和幻讀的區別?
- MySQL中如果使用like進行模糊匹配的時候,是否會使用索引?一定不會用么?(索引這塊了解的太少了,二面結束后,回去惡補了一下)
- 談談Redis吧,在你專案中的具體使用?
- 談談Redis如何實作分布式鎖?
- 蘑菇博客是否存在快取不一致的情況,你是如何解決的?
- 談談Redis中快取穿透的問題,以及解決的方法?
- 還有其它解決快取穿透的方法么?布隆過濾器有了解過么?
- Redis中大面積的快取失效,然后請求全部打到資料庫,有什么解決方法?
- 如果出現一些熱點資料,比如明星之間的新聞,造成大量的吃瓜用戶涌入后臺,但是服務器還沒有快取對應的資料,這樣可能造成資料庫宕機,如何避免這樣的情況?
- 聊聊 JVM的組成結構?
- 談談垃圾收集原理?以及垃圾收集演算法
- 復制演算法 和 標記整理演算法?
- 為什么不在新生代使用標記整理演算法?或者在老年代使用復制演算法?
- 有了解過Volatile么?談談你對Volatile的理解
- Volatile如何保證可見性的?以及如何實作可見性的機制,
- 如果大量的使用Volatile存在什么問題?
- 談談作業系統的執行緒,以及它的狀態
- 執行緒和行程的區別?
- 為什么要提出多執行緒應用,而不是多行程應用呢?
- Linux你平時都有用到什么命令呢?
- 如果我需要查看埠號或者行程號,你會使用什么命令?
- 談談你做的另外一個專案吧?稍微介紹一下
- 來吧,寫個題目試試
# 鏈表的兩兩翻轉 # 給定鏈表: 1->2->3->4->5->6->7 # 回傳結果: 2->1->4->3->6->5->7- 畢業時間是什么時候?現在面試的是實習崗位么?
- 反問環節:追問面試表現?告知 Redis這塊掌握的還可以,但是MySQL這塊顯得不足,問后續的安排,
第三面
應該是Leader面,面試時間大概50分鐘
- 自我介紹
- 好奇一下,用碼云的人應該不多吧,為什么沒有用Github?
- 你英文水平怎么樣?
- 聊聊開源專案吧?我看這專案已經有800多贊了,你在這開源專案主要做了什么作業?
- 我們找些點來聊聊吧?先從ES和Solr開始,你們這兩個都有在用么?
- SQL的方式實作搜索,你是怎么做的呢?
- 使用like匹配的時候,會不會查詢非常慢呢?
- ES和Solr的底層都用了lunce,談談你對lunce的理解?
- lunce里面也有用到分詞器,比如一些新的詞 “新冠肺炎” ,它能不能做到很好的劃分呢?
- 除了人為的維護詞庫,來解決最新詞語的分割,你還有知道其它什么更好的方法么?
- 你有了解過其它什么開源的分詞庫么?
- 談談字典樹?
- Solr 和 ES底層都用了Lunce,那他們兩者有什么區別呢?
- Solr所謂的集群環境 和 ES所謂的分布式環境,它們之間有什么區別呢?
- 上面你有提到微服務,你有了解過微服務是個什么樣的理念么?
- 你現在的微服務,也是打包成多個jar包,部署在一個服務器上,如果服務器出現問題了,也會造成服務不可用,有沒有好的解決方法呢?
- 聊聊服務的注冊與發現?
- 服務的注冊和發現,其實依賴于一個注冊中心的概念,會不會出現注冊中心掛掉,而導致整個服務不可用,有沒有什么好的解決方法呢?
- 有了解過Zookeeper整個的選舉程序么?
- 談談Zookeeper的分布式一致性協議?
- 聊聊索引,我給你寫個表,看看下面的查詢陳述句,走了那些索引?
create table 'tb' (
id int,
name varchar(64),
status int,
createtime timestamp,
PRIMARY KEY (`id`)
)
-- 創建了三個普通索引
create index index_name on table('name')
create index index_status on table('status')
create index index_createtime on table('createtime')
-- 給定SQL陳述句,判斷下面查詢會用到幾個索引
select * from tb where status = 1 and name = "zhangsan"- 上述SQL用到了幾個索引?分別是那幾個?
- 有了解過InnoDB底層的索引結構么?
- 通過兩個索引查詢出來的結果,會進行什么樣的操作?交集,并集?
- 如果你在MySQL中遇到一些慢查詢,有什么解決方法么?
- 談談explain?執行的explain后,出現的那些欄位,能夠幫助我們呢?
- 我看你的博客里面,關于Redis還有好幾篇文章,我們可以聊一聊你對Redis的理解?
- 為什么Redis能夠保持這么高的并發回應?
- 有了解過IO多路復用技術是個什么樣的原理
- 通過一個執行緒,同時連接多個執行緒不會存在多個執行緒切換么?(感覺進坑了,,)
- 當你通過jedis進行連接redis的時候,已經和一個行程連接了 ,redis還能夠和其它的行程進行通信么?
- Redis每秒能夠處理處理十萬請求,如果按照你上面說的,那說明它每次互動只在 1/十萬 秒內完成?
- 有了解過Redis的原始碼么?
- MySQL用了B+Tree,Redis中的SortSet內部用了跳躍表,他們之間有什么差別?為什么MySQL不用跳躍表,或者是Redis不用B+Tree呢?
- 感覺自己編碼功底怎么樣?那我們先聊聊作業系統的知識再給你一道題吧,在作業系統中,有高速快取,主存,虛擬記憶體,外存,有知道它們之間有什么樣的關系,以及它們的作用是啥?
- 對它們來說,肯定會存在一個問題,就是當我們的主存滿了,或者虛存滿了,那么需要存在一個換頁操作,你知道有那些換頁演算法么?
- 我們來聊聊LRU?叫你手寫一個LRU演算法談談你的思路?
- 用鏈表的方式實作,時間復雜度是O(N),有沒有什么方式能夠讓它是O(1)的時間復雜度呢?
- OK,思路還可以,那你手寫一個LRU演算法吧?(雙向鏈表 + Hash?)
- 反問環節:問了下組織架構,以及python和go在專案中的使用,然后問了下面試的表現,答:代碼寫的不算好吧,LRU寫成這樣我覺得是不太合適的,(心碎的聲音,感覺到涼涼的氣息...),結束后以為面試已經結束,后面在準備關頁面的時候,面試官說等一下,還有同學和我聊?
HR面
花10來分鐘做個簡單的溝通
- 自我介紹
- 考研的時候為什么選擇的是這個學校呢?
- 回顧一下,上大學到現在這段時間內,讓自己最有挫敗感的事情是什么呢?
- 有哪些方面需要在改進的么?
- 對于以后參加的作業,你主要會看重哪些方面呢?
- 同學這塊,大家都有在投遞位元組這邊的崗位么?
- 反問環節:關于面試結果,告知,這邊只是做簡單的了解,面試結果大約會在一周左右出來,到時候會有郵件或者電話通知,關于面試的結果,需要綜合前面的幾個面試官進行綜合評測,才能決定是否錄取,
總結+面試前的準備(供大家參考學習)
給大家個建議,面試官如果愿意和你聊組里業務,一定要把味訓會好好聊,最好能提出讓面試官眼前一亮的問題,直指業務核心,代碼誰都會寫,基礎知識網上都能查到,但是對產品的理解和新的想法不是誰都有的
(1)第一步,面試前整理一個完整知識架構大綱
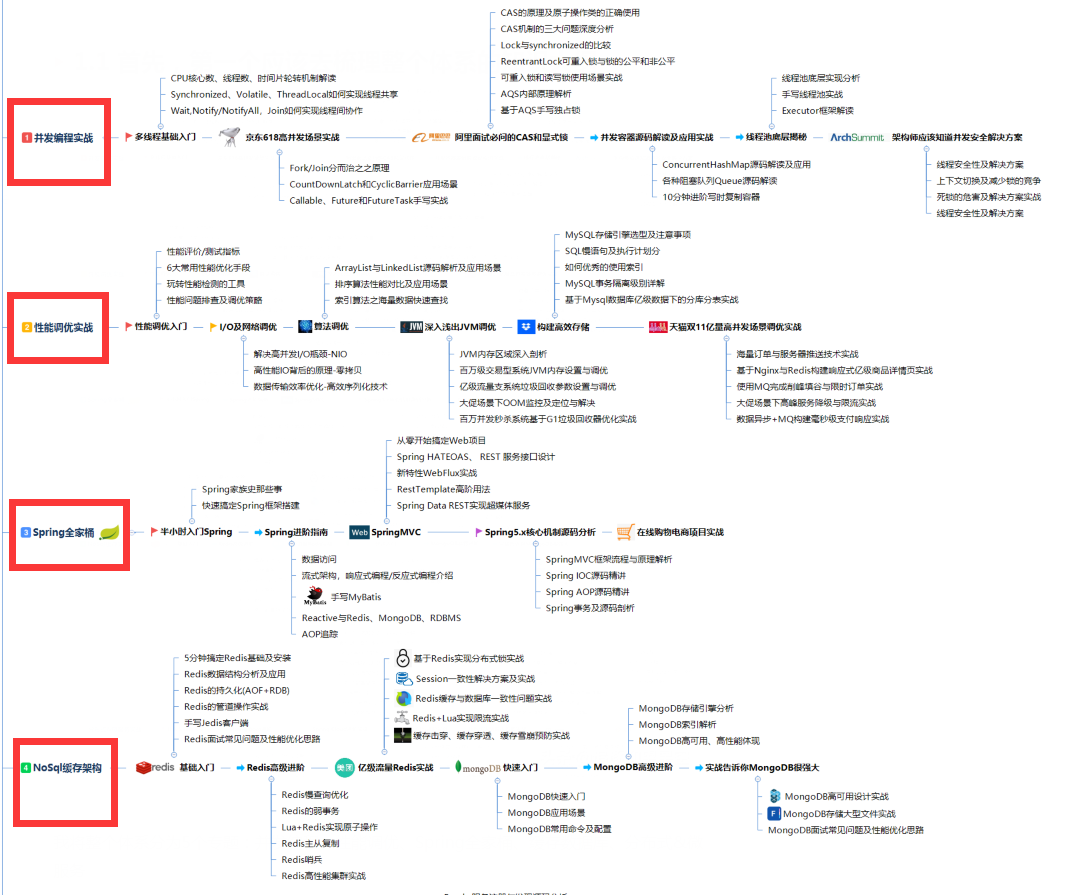
我將架構體系分為五大模塊:并發編程、JVM性能調優、Spring開源框架原始碼解讀、快取資料庫、分布式架構,微服務架構
(2)第二步,通過大綱對面試中的高頻技術逐個攻克
1,并發編程(手寫筆記:并發編程+并發編程_原理+并發編程_應用+并發編程_模式)
- 并發編程共享模型篇
- 并發編程_模式篇
- 并發編程_應用篇
- 并發編程_原理篇
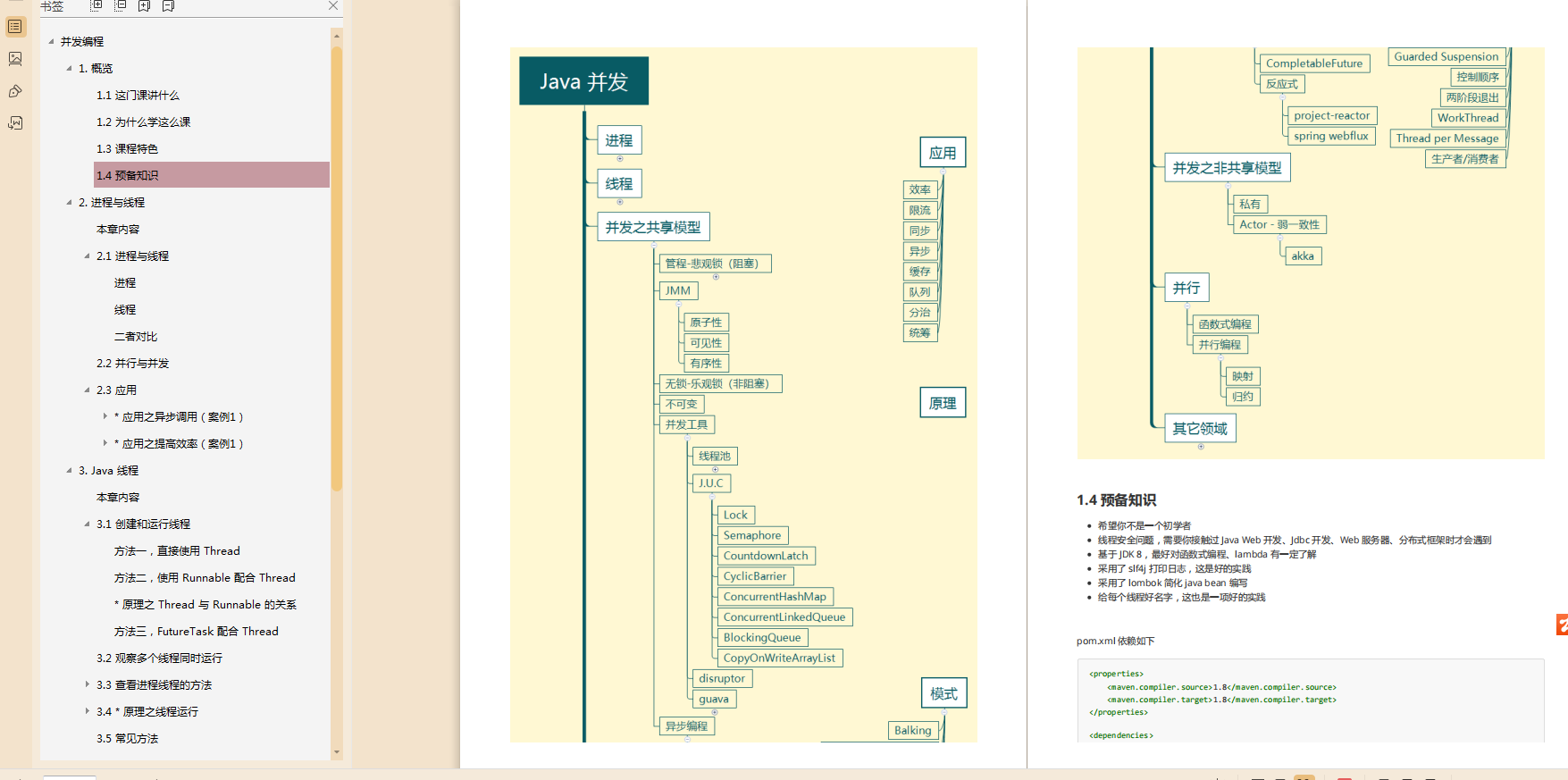
并發編程共享模型篇

并發編程_模式篇

并發編程_應用篇

并發編程_原理篇
2,性能調優(Java性能調優實戰:Java編程性能調優+JVM性能優化+Mysql調優筆記)
- JVM性能優化

JVM性能優化
- JVM性能監測及調優

JVM性能監測及調優
- Mysql調優筆記

3,Spring開源框架原始碼解讀
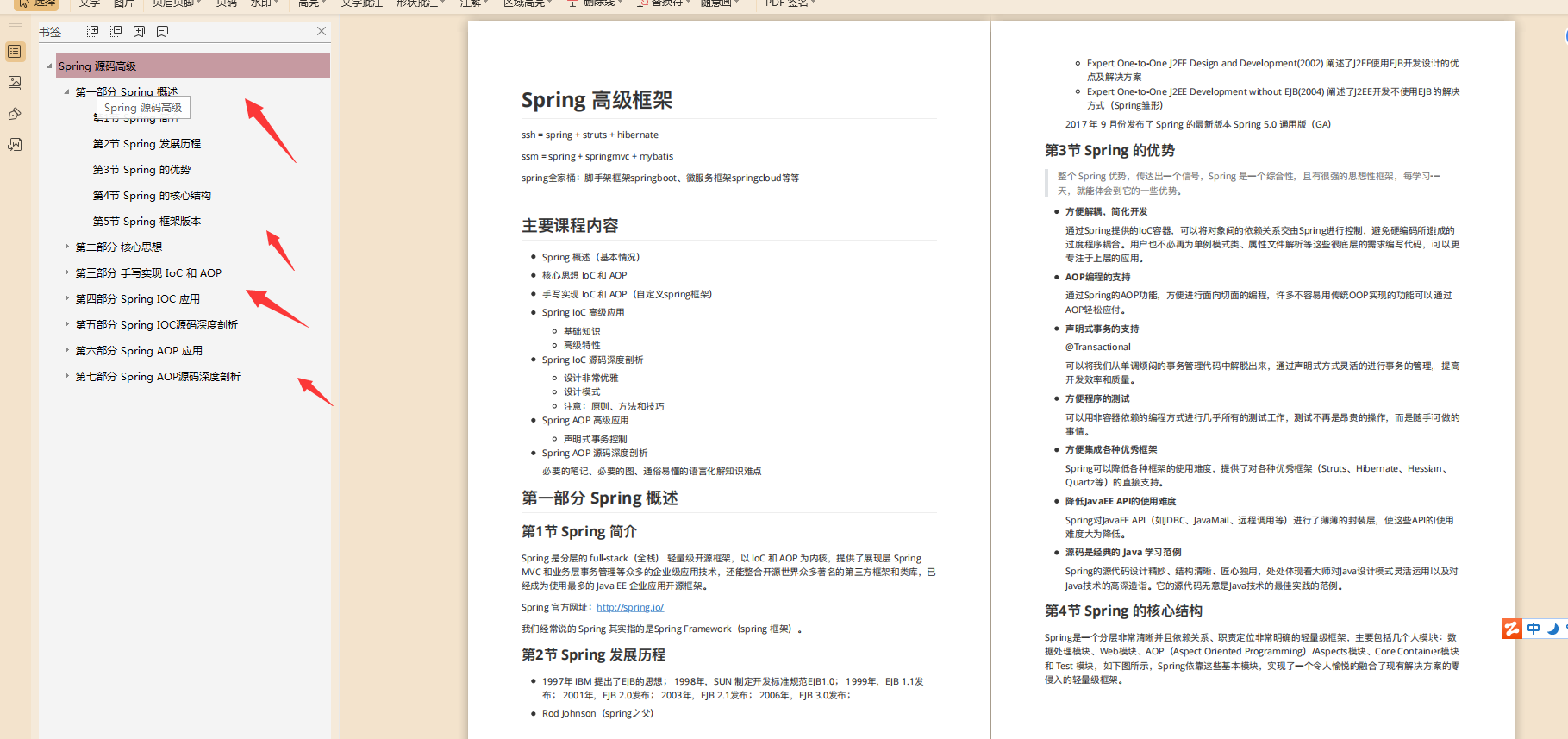
4,快取資料庫
- Redis核心筆記
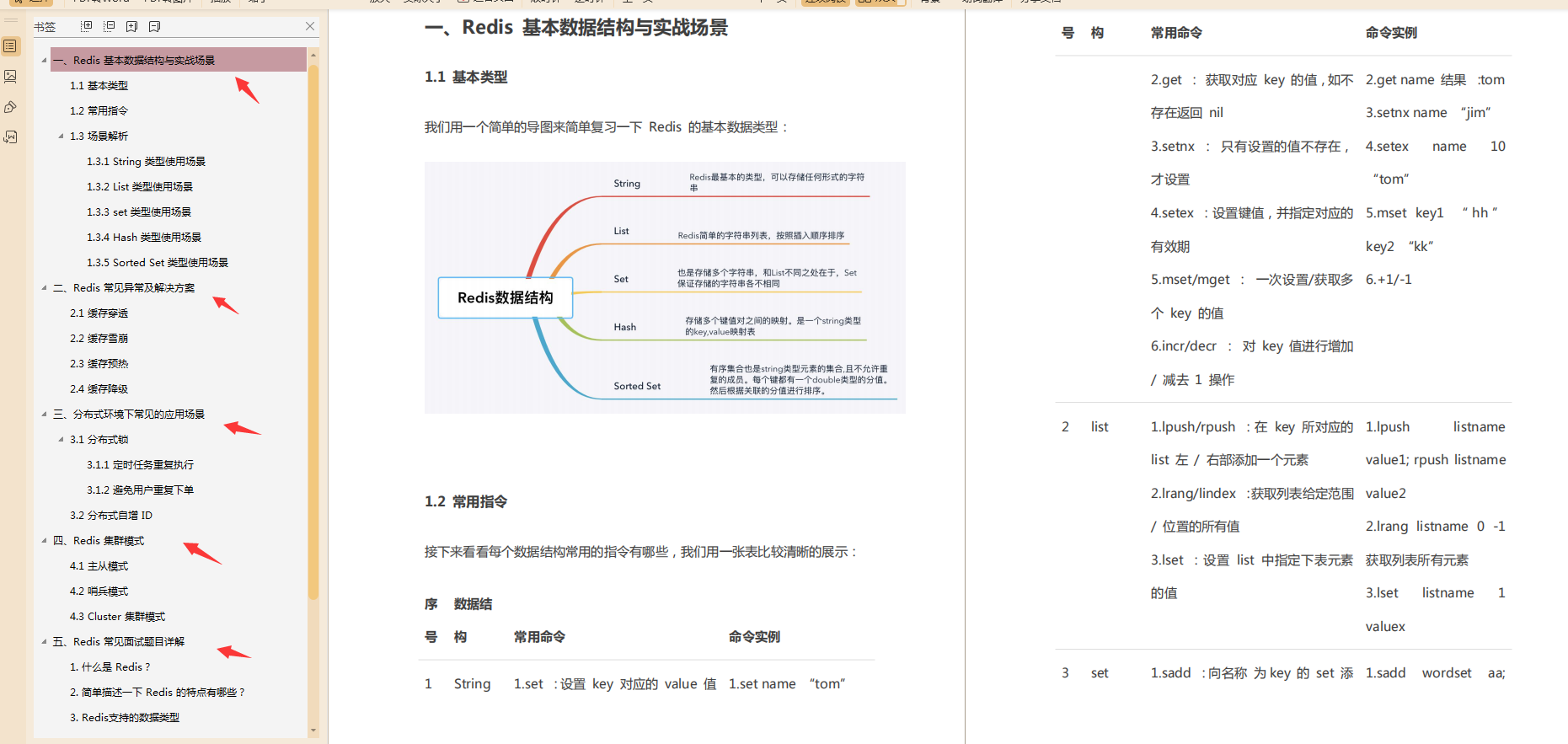
Redis核心筆記
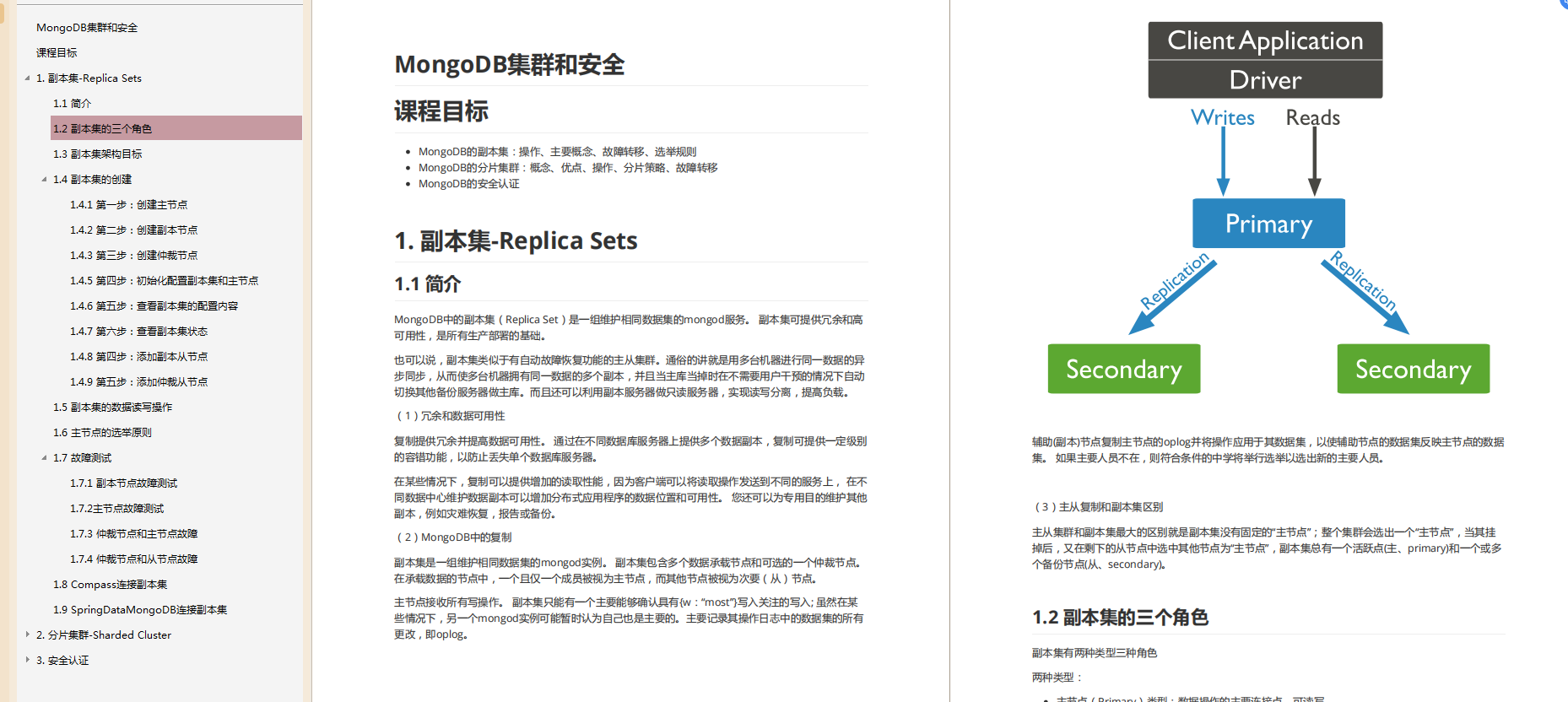
- MongDB基礎到進階

MongoDB快速上手
5,分布式架構
- Kafka原始碼決議與實戰

6,微服務架構
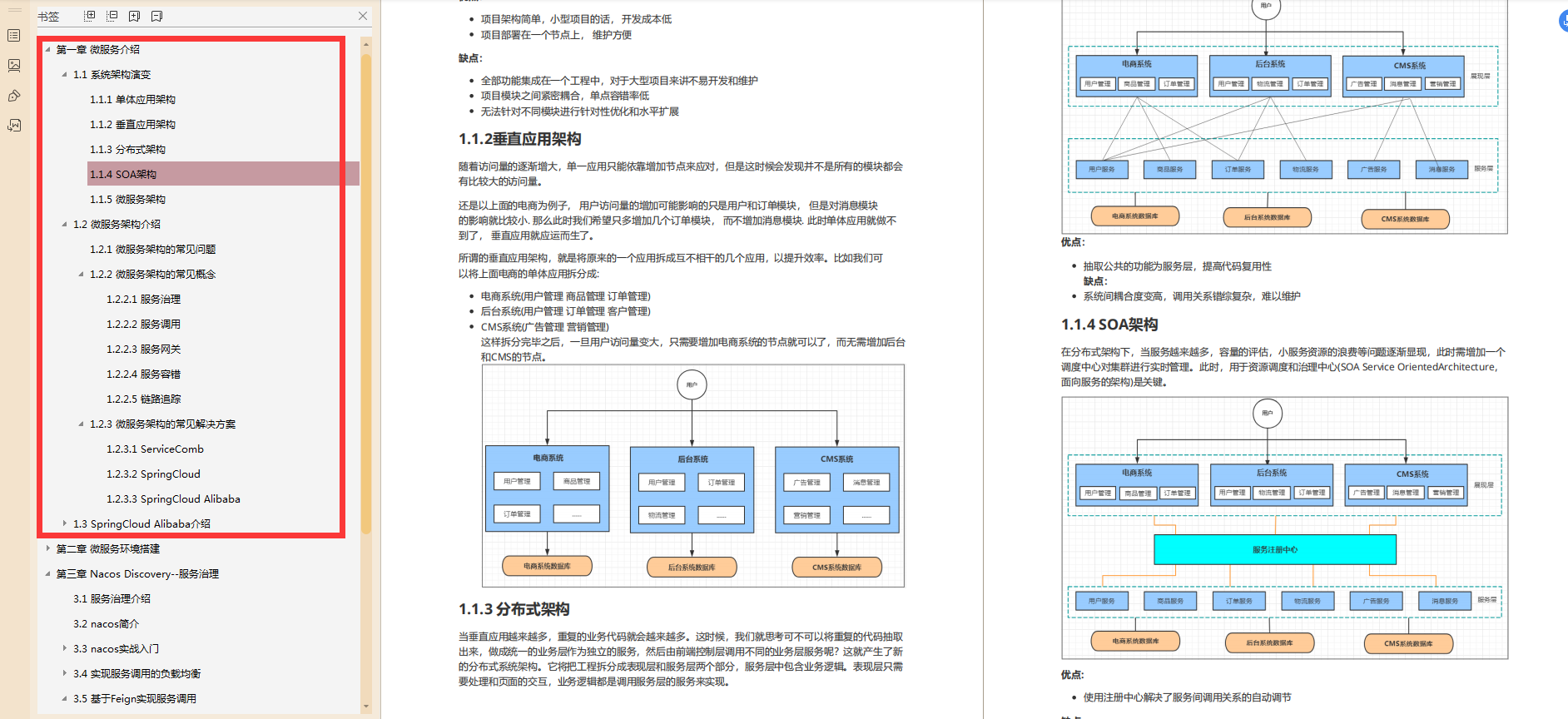
- Spring Cloud Alibaba技術堆疊全解
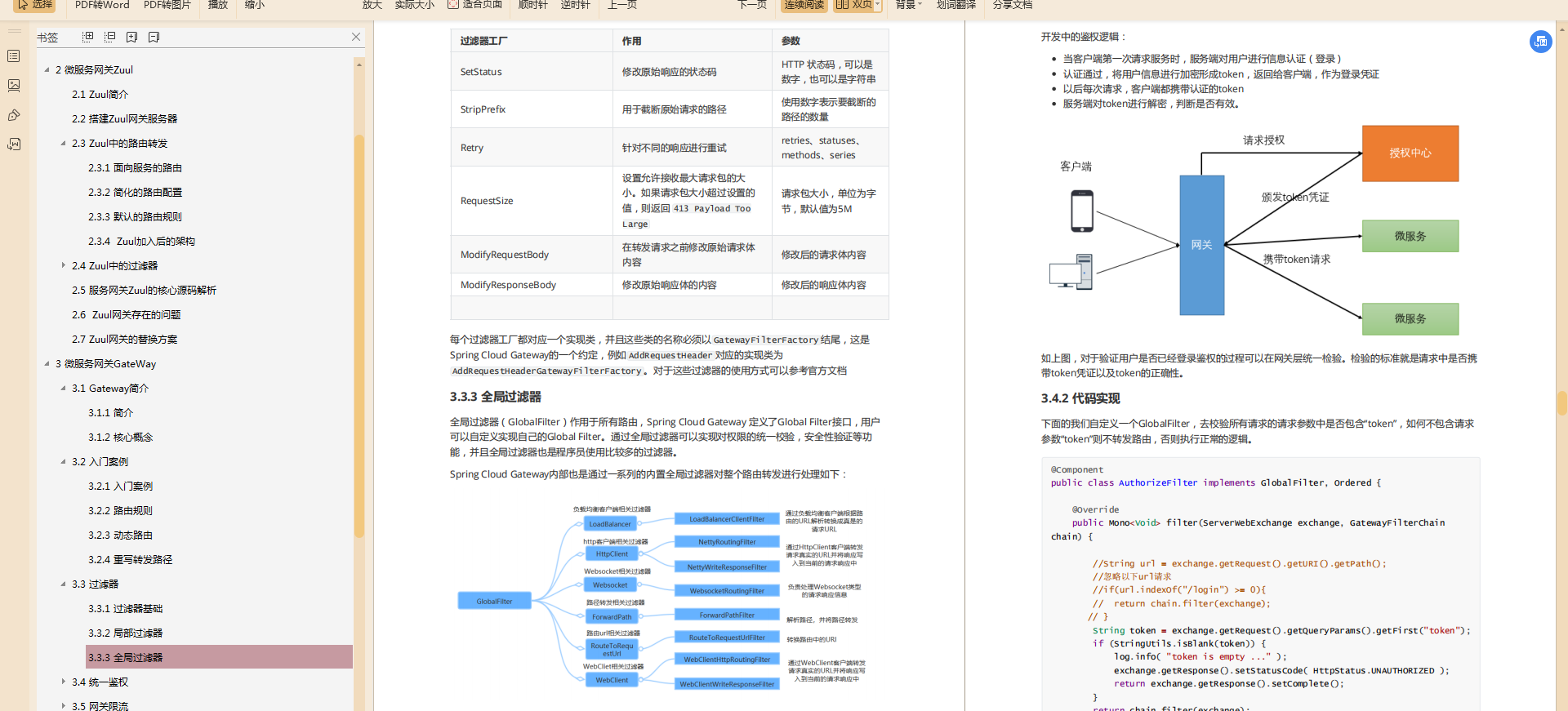
- Spring Cloud微服務筆記
- k8s+Jenkins筆記

(3)第三步,刷面試題,面試位元組跳動演算法是必問的
團滅 LeetCode的演算法刷題寶典
演算法刷題小冊

25大Java面試專題
位元組跳動總體來說,面試體驗還很不錯的,尤其是在手撕代碼題的時候,面試老哥會先叫你提供思路,如果你說的思路有問題的話,會幫你撥正,然后在進入coding階段,但是怎奈何平時沒怎么練習演算法,leetcode做的少,面試兩行淚,,這也算是提前批打響第一槍,期待后面精彩表現~
以上就是我在面試前整理搜集的面試資源和一個學習路線規劃,希望能對大家有所幫助,有需要的朋友點贊+關注,加助理VX:mxx2020666,即可免費獲取資料
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/141973.html
標籤:其他
下一篇:k8s單節點部署