
本系列出自《深入淺出SQL》,全文以問答形式展開,是我的個人學習筆記,
文章目錄
- 如果我只有一張白表,我為什么還要創建資料庫?
- 我發現CREATE DATABASE 命令的字母全是大寫,一定要這樣嗎?
- 給資料庫、表和列命名時有什么注意事項嗎?
- 為什么不能直接把BLOB當成所有文本值的型別?
- NULL是什么都沒有的意思嗎?
- 花絮
- 我試著從網路上復制并粘貼查詢,但在使用時卻一直出現錯誤資訊,我做錯什么了嗎?
- 所以我應該把查詢粘貼到Microsoft Word之類的軟體中嗎?
- 關于單引號的兩種轉義方法,哪一種比較好呢?
- 若是NOT 搭配 AND/OR,該如何處置?
- 花絮
- 為什么不能假設最后一條記錄就是最新的記錄?
- 資料會改變,所以知道如何改變資料才會如此重要,
- 查詢表時是否應該避免使用LIKE?LIKE有問題嗎?
- 為什簡短的查詢優于較長的查詢?
- 簡述創建表的思路
- 原子不是很小嗎?我是不是應該把資料分割成非常非常小的片段?
- 原子性對我有什么幫助?
- 主鍵規則說說看?
- 花絮
- 如果我想改變列的順序呢?像`ALTER TABLE MODIFY COLUMN proj_desc AFTER con_name;`這樣做可以嗎?
- 如果我已經創建了主鍵,然后又意外的想改用另一列呢?可以只移除主鍵的設定而不改變其中的資料嗎?
- AUTO_INCREMENT又該如何處理/
- 花絮
- ALTER使用示例
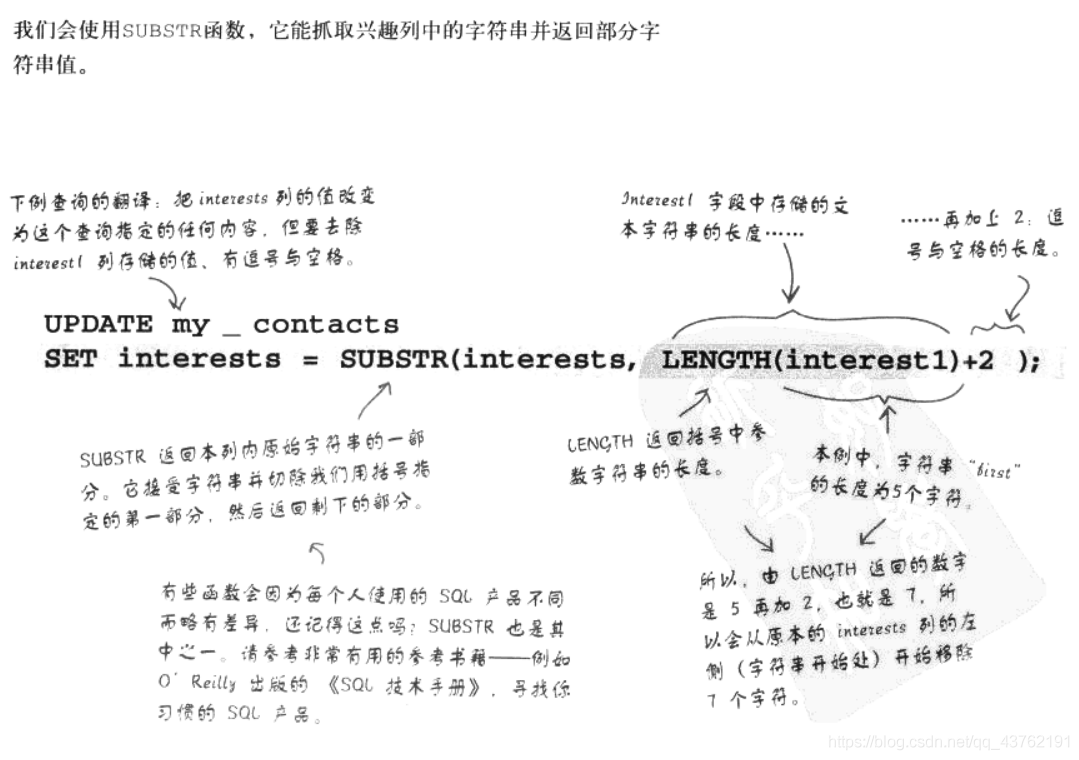
- 一些便利的字串函式
- 要用到ELSE嗎?
- 如果沒有ELSE而且列也不符合任何一個WHEN條件,會發生什么事?
- 如果我只想對部分列套用CASE運算式,應該怎么做呢?
- 講到MIN,如果查詢中的列有NULL,這會有上面影響嗎?
- 花絮
- CASE陳述句
- ORDER BY排序
- 1、升序排序:ASC | 降序排序:DESC
- 2、SQL排序規則
- 多列排序:
- GROUP BY 分組
- COUNT,計數
- DISTINCT,取獨
- LIMIT:限制查詢數量
- 如果外鍵是NULL,它右什么作用嗎?有辦法確定外鍵已經連接到父鍵了嗎?
- 不能單純的使用另一張表的鍵,稱之為外鍵,而不加上約束嗎?
- 加強連接?是什么意思?
- 所以上面說的那種,我就不能洗掉了是嗎?
- 遇到多對多關系的時候,一定要用中間件嗎?
- 花絮
- 資料庫決議圖
- 外鍵
- 外鍵約束
- 設計資料庫模式
- 資料模式:一對一
- 使用一對一的時機
- 資料模式:一對多
- 資料模式:多對多
- Junction table(連接表)
- 范式(NF)
- 第一范式(1NF)
- 組合鍵
- 第二范式(2NF)
- 函式依賴性
- 第三范式(3NF)
- 我為什么需要交叉聯接?
- 行內接和交叉聯接有什么區別嗎?
- 可以聯接多于兩張表嗎?
- ORDER BY 這些東西也能與聯接放到一起嗎?
- 外聯接呢?
- 花絮
- 字串切割函式
- 同時(幾乎同時)CREATE、SELECT、INSERT
- 關鍵字AS
- 表的別名,誰會需要?
- 聯接
- 交叉聯接(笛卡爾積)
- 行內接
- 自然聯接
- 子查詢決議
- 非關聯子查詢
- 關聯子查詢
- 內層查詢究竟可以回傳什么?外層查詢呢?
- 所以說,子查詢可以放在子查詢里嗎?
- 據說使用子查詢能解決的事情,用聯接也可以?是這樣嗎?
- 左外聯接
- 右外聯接
- 自聯接
- UNION
- UNION的使用限制
- 示例
- 聯接VS子查詢
- 有使用左外連接取代右外聯接的理由嗎?
- 檢查約束
- 視圖
- 創建視圖
- 查看視圖
- 視圖的實際行動
- 為什么視圖對資料庫有好處?
- 銷毀視圖
- 事務
- 可以查看以創建的視圖嗎?
- 如果我卸載了有視圖的表,會發生什么事?
如果我只有一張白表,我為什么還要創建資料庫?
A:SQL語言要求所有的表都放在資料庫中,這當然有它的理由,SQL能控制多位用戶同時訪問表的行為,能夠授予或撤銷對整個資料庫的訪問權,這有時比控制每張表的權限要簡單的多,
我發現CREATE DATABASE 命令的字母全是大寫,一定要這樣嗎?
A:有些系統確實要求某些關鍵字采用大寫形式,但SQL本身不區分大小寫,也就是說,命令不大小寫也可以,但命令大小寫是良好的SQL編程慣例,
大寫讓我們很容易分辨命令與資料庫名稱,
給資料庫、表和列命名時有什么注意事項嗎?
A:創建具有描述性的名稱通常有不錯的效果,有時候要多用幾個單詞來命名,所有名稱都不能包含空格,所以使用下劃線能夠讓你創建更具描述性的名稱,
命名時最好避免首字母大寫,因為SQL不區分大小寫,極可能會搞錯資料庫,
為什么不能直接把BLOB當成所有文本值的型別?
A:因為這樣很浪費空間,VARCHAR或CHAR只會占用特定空間,不會多于256個字符,但BLOB需要很大的存盤空間,
另外,有些重要的字串運算無法操作BLOB型別的資料,只能用于VARCHAR或CHAR,
NULL是什么都沒有的意思嗎?
A:當然不是!! 它從來就不等于0,而且它也不等于另一個NULL,事實上,兩個NULL根本不能放在一起比較,值可以是NULL,但是它不會等于NULL,因為NULL代表未定義的值!
花絮
- DEC(6,2):六位數,其中小數點后兩位數,
- DATATIME(時間和日期):10:30 a.m. 9/29/2020
- 如果想查看表的資料結構,可以使DESC陳述句
- DRAP TABLE 陳述句可以用于丟棄表,謹慎使用!
- 為表插入資料時,可以使用任何一種INSERT陳述句,
- NULL是未定義的值,它不等于0,也不是空值,值可以是NULL,但絕非等于NULL,
- 沒有在INSERT陳述句中被賦值的列默認為NULL,
- 可以把列修改為不使用NULL,這需要在創建表時使用關鍵字NOT NULL,
- 創建表時使用DEFAULT,可于日后輸入缺乏部分資料的記錄時自動的填入默認值,
我試著從網路上復制并粘貼查詢,但在使用時卻一直出現錯誤資訊,我做錯什么了嗎?
A:從web瀏覽器剪切過來的查詢有時包含了外觀像空格,但在SQL里有其他含義的隱形字符,你可以把查詢粘貼到文本編輯器中,如此一來,就可以仔細尋找并移除這些小麻煩,
所以我應該把查詢粘貼到Microsoft Word之類的軟體中嗎?
A:建議使用norepad(PC)或TextEdit(Mac)的純文本編輯模式,
關于單引號的兩種轉義方法,哪一種比較好呢?
A:其實沒有優劣之分,但是斜杠對我們肉眼有利,
若是NOT 搭配 AND/OR,該如何處置?
A:如果想在AND或OR子句中使用NOT,請直接將它放在關鍵字后面,如下:
SELECT * FROM asd WHERE NOT main = ‘aaa’ AND NOT mian = ‘bbb’;
花絮
- 在條件陳述句中,要查找空元素,應該使用
IS NULL - 模糊查詢(like)與它的通配符(%、_):匹配任意數量、單個數量
- 取定一個范圍的資料:BETWEEN…AND…
- 列舉選定:in :select XXX from XXX where XXX IN(XXX、XXX、XXX),select XXX from XXX where XXX NOT IN(XXX、XXX、XXX).
為什么不能假設最后一條記錄就是最新的記錄?
A:因為表中的記錄排序方式沒有一定的規則,而且我們很快又要調整查詢結果的記錄,所以實在無法保證表的最后一條記錄是最后插入的記錄,除非我們記住哪份資料先進來,
資料會改變,所以知道如何改變資料才會如此重要,
A:但表設計的越好,整體所需的更新操作就會越少,良好的表設計能讓我們從專心于表的內容中解放出來,
查詢表時是否應該避免使用LIKE?LIKE有問題嗎?
A:LIKE沒有問題,但可能很難運用到你的查詢中,而且你會冒著找出你不需要的一大堆資料的風險,如果你的列包含復雜資訊的話,LIKE搜索精確資料的能力還不夠,
為什簡短的查詢優于較長的查詢?
A:查詢越簡短越好,隨著資料的增長,還有對新表的添加,你的查詢就會變得越來越復雜,如果現在就練習設計最簡單的查詢,以后你會感謝現在的及早訓練,
簡述創建表的思路
A:1、挑出事物,挑出你希望表描述的某樣事物,
2、列一份關于那樣事物的資訊串列,這些資訊都是使用表時的必要資訊,
3、使用資訊串列,把關于那樣事物的綜合資訊拆分成小塊資訊,以便用于組織表,
原子不是很小嗎?我是不是應該把資料分割成非常非常小的片段?
A:不是哦,讓資料具有原子性,表示把資料分割成創建有效率的表所需的最小片段,
別把資料切割的超出必要,如果不需要增加額外的列,就別因為可以增加而增加,
原子性對我有什么幫助?
A:原子性有助于確保表內容的準確性,
原子性也可以使查詢更加有效率,因為查詢會因原子性而更容易設計,而且所需時間也更短,因此在面對大量資料時有加分效果,
主鍵規則說說看?
A:1、主鍵用于獨一無二地識別出每條記錄,
2、主鍵不可以為NULL,
3、插入新紀錄時必須指定主鍵值,
4、主鍵必須簡潔,
5、主鍵不可以被修改,
花絮
- 謹慎使用DELETE和UPDATE,使用SELECT確認自己加入了非常精確的WHERE陳述句,可以只選出你真正想要洗掉/修改的行,
- 使用UPDATE,你可以改變單一列或所有列的值,
- 在SET子句中加入更多的column = value組,其間以逗號分隔,
- UPDATE可用于更新單一的行或多行,一切交給WHERE子句決定,
- 自動遞增關鍵字:AUTO_INCREMENT
如果我想改變列的順序呢?像ALTER TABLE MODIFY COLUMN proj_desc AFTER con_name;這樣做可以嗎?
創建表后你就無法真正的改變列的順序了,最多只能在指定位置添加新列,然后洗掉舊列,但是這樣會失去舊列中的所有資料,
如果我已經創建了主鍵,然后又意外的想改用另一列呢?可以只移除主鍵的設定而不改變其中的資料嗎?
A:可以,而且很簡單,
ALTER TABLE your_table DROP PRIMARY KEY,ADD PRIMARY KEY(XXX);
AUTO_INCREMENT又該如何處理/
A:你可以把它添加到沒有自動遞增功能的列中,如下所示:
ALTER TABLE your_table CHANGE yoour_id your_id INT(11) NOT NIULL AUTO_INCREMENT;
而且可以這樣就將它洗掉:ALTER TABLE your_table CHANGE your_id your_id INT(11) NOT NULL;
有一點要記住:每個表中只有一列可以加上AUTO_INCREMENT,該列必須為整形而且不能包含NULL,
花絮
ALTER使用示例
ALTER TABLE my_contacts
ADD COLUMN contact_id INT NOT NULL AUTO_INCREMENT FIRST,
ADD PRIMARY KEY(contact_id);
ALTER TABLE my_contacts
ADD COLUMN phone VARCHAR(10)
AFTER list_name;
CHANGE --可同時改變現有列的名稱和資料型別
MODIFY --修改現有列的資料型別或資料
ADD --在當前表中添加一列,可自選型別
DROP --從當前表中洗掉某列
ALTER TABLE project_list
CHANGE COLUMN number proj_id INT NOT NULL AUTO_INCREMENT,
ADD PRIMARY KEY(proj_id);
--將原名為“name”的列的名稱和型別修改
--如果把資料改成另一種型別,你可能會丟失資料
ALTER TABLE project_list
CHANGE COLUMN descriptionofproj proj_desc VARCHAR(10),
CHANGE COLUMN contractoronjob con_name VARCHAR(30),
ALTER TABLE project_list
MODIFY COLUMN proj_desc VARCHAR(120);
ALTER TABLE project_list
DROP COLUMN start_date;
一些便利的字串函式
SELECT RIGHT(lie,2) FROM my_contacts; --從lie列中讀取兩個字符
SELECT SUBSTRING_INDEX(lie,',',1) FROM my_contacts;
--截取部分字串,第三個引數就是尋找第一個逗號,用于截取第一個逗號之前的所有字符,
SELECT UPPER('usa'); --把整整組字串改大寫
SELECT LOWER('USA'); --改小寫
SELECT LTRIM(' dogfood '); --清除左側空格
SELECT RTRIM(' catfood ');
SELECT LENGTH('San Antonio,TX'); --回傳字串中的字符數量
要用到ELSE嗎?
A:看你咯,無所謂,
如果沒有ELSE而且列也不符合任何一個WHEN條件,會發生什么事?
在你想更新的列里面不會發生任何改變,
如果我只想對部分列套用CASE運算式,應該怎么做呢?
A:可以加上WHERE,可以在END后加上WHERE子句,這樣,CASE就只會套用在符合WHERE子句的列上,
CASE運算式可以搭配UPDATE以外的陳述句嗎?
A:why not?
講到MIN,如果查詢中的列有NULL,這會有上面影響嗎?
A:好問題,NULL其實不會有影響,因為NULL代表此處無值,而不是此值為0.
花絮
CASE陳述句
看圖:
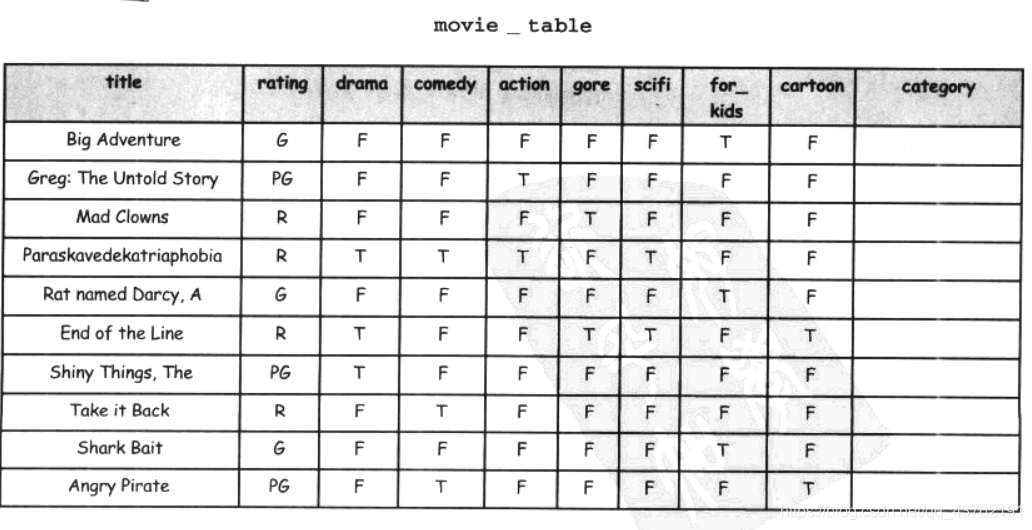
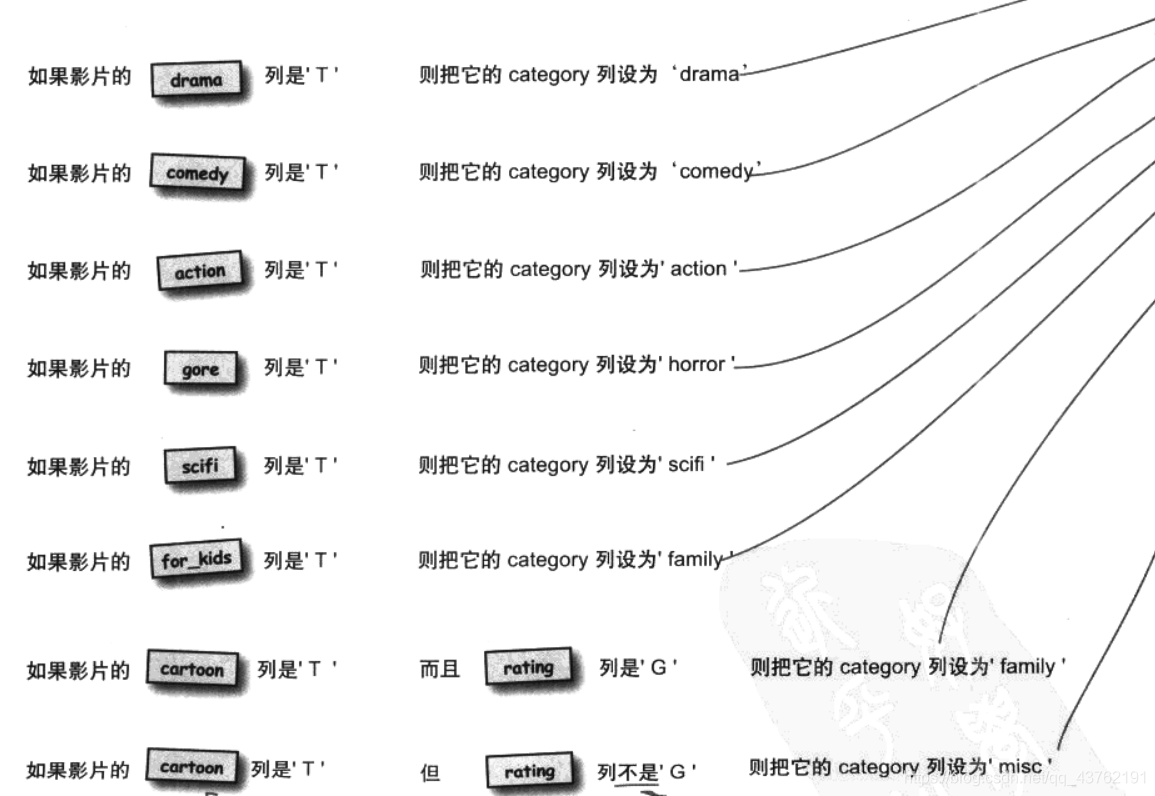
現在怎么辦?是像這樣嗎?
:

這樣要執行n次啊,,,
那有沒有更好的辦法,其實在主語言中,這不過就是個分支陳述句的事情嘛,奈何SQL語言我不熟啊,,,
沒事,一直以來不懂,從今以后懂了:
UPDATE my_table
SET new_column =
CASE
WHEN column1 = somevalue1
THEN newvalue1
WHEN column2 = somevalue2
THEN newvalue2
ELSE newvalue3
END;

ORDER BY排序
1、升序排序:ASC | 降序排序:DESC
2、SQL排序規則

多列排序:
越靠前的列權重越高,擁有對后面列的一票否決權,
GROUP BY 分組
SELECT first_name,SUM(sales)
FROM cookie_sales
GROUP BY first_name
ORDER BY SUM(sales) DESC
;
SELECT first_name,AVG(sales)
FROM cookie_sales
GROUP BY first_name
ORDER BY AVG(sales) DESC
;
SELECT first_name,MAX(sales)
FROM cookie_sales
GROUP BY first_name
;
SELECT first_name,MIN(sales)
FROM cookie_sales
GROUP BY first_name
;
COUNT,計數
SELECT COUNT(sale_date)
FROM cookie_sales
;
DISTINCT,取獨
SELECT DISTINCT sale_date
FROM cookie_sales
ORDER BY sale_date
;
SELECT COUNT(DISTINCT sale_date)
FROM cookie_sales
;
LIMIT:限制查詢數量
SELECT first_name,SUN(sales)
FROM cookie_sales
GROUP BY first_name
ORDER BY SUN(sales) DESC
LIMIT 2 OFFSET 4 --跳過兩條,查詢兩條記錄
--也可以這樣寫:LIMIT 4,2
;
如果外鍵是NULL,它右什么作用嗎?有辦法確定外鍵已經連接到父鍵了嗎?
A:外鍵為NULL,表示在父表中沒有相符的主鍵,但我們可以確認外鍵包含有意義、已經存盤在父表中的值,請通過約束實作,
不能單純的使用另一張表的鍵,稱之為外鍵,而不加上約束嗎?
A:其實可以,但創建成外鍵約束后,就只能插入已經存在于父表中的值,有助于加強兩張表間的連接,
加強連接?是什么意思?
A:外鍵約束能確保參考完整性(換句話說,如果表中的某行有外鍵,約束能確保該行通過外鍵與另一張表中的某一行一一對應),如果我們試著洗掉主鍵表中的行或者是改變主鍵值,而這個主鍵是其他表的外鍵約束時,你就會收到錯誤警告,
所以上面說的那種,我就不能洗掉了是嗎?
A:還是可以的,先移除外鍵行即可,
遇到多對多關系的時候,一定要用中間件嗎?
A:不然呢?
花絮
資料庫決議圖
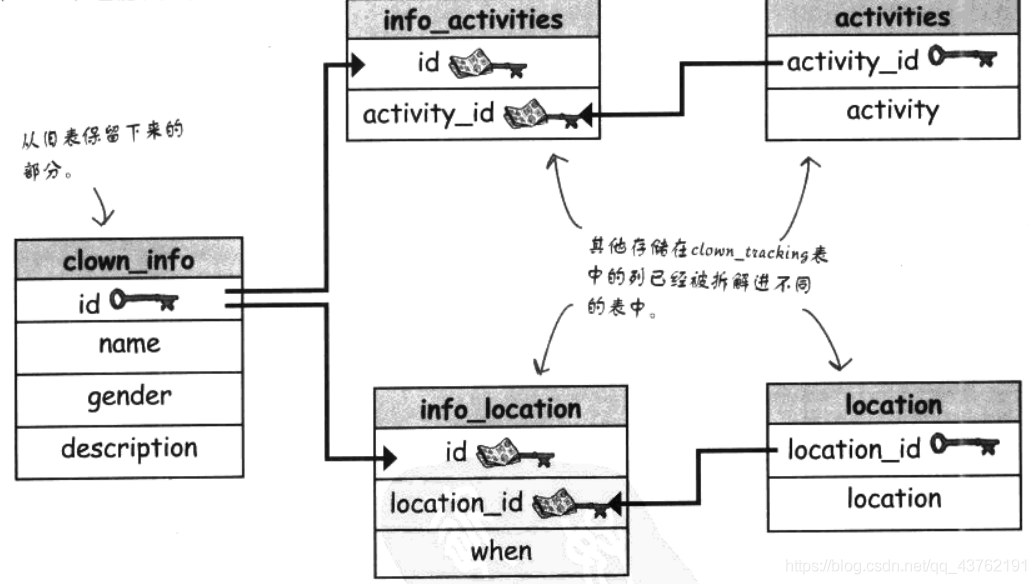
創建資料庫的視覺決議圖,在設計查詢時有助于理解資料相連的方式,但模式也能以文字形式表達,看個人,
外鍵
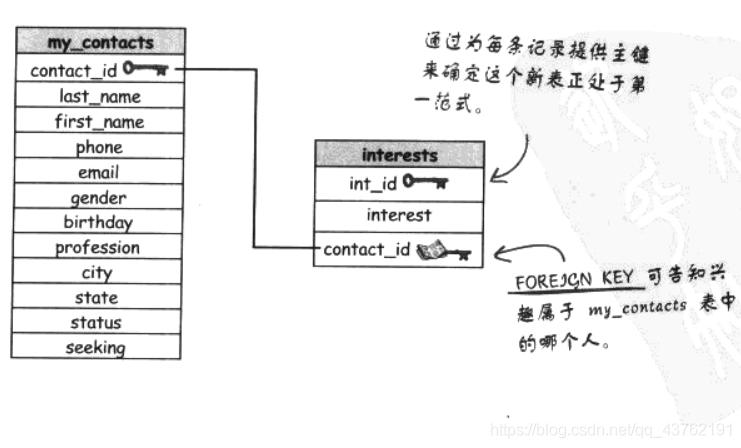

外鍵約束
創建一張表并加上可作為外鍵的列雖然很簡單,但除非你利用CREATE或ALTER陳述句來指定外鍵,否則都不算是真的外鍵,創建在結構內的外鍵被稱為約束,
插入外鍵列的值必須已經存在與父表的來源中,這是參考完整性,
創建外鍵作為表的約束提供了明確的優勢,如果違反了規則,約束會阻止我們破壞表,
外鍵不一定要是父表的主鍵,但是要具有唯一性,

設計資料庫模式
資料模式:一對一
在模式圖中,一對一關系的連接線是單純的實線,表示連接一件事物與另一件事物,
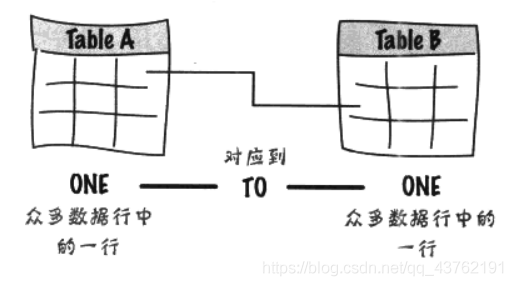
使用一對一的時機
事實上,很少,
- 抽出資料或許能讓你寫出更快速的查詢,
- 如果有列包含還不知道的值,可以單獨存盤這一列,以免主表中出現NULL,
- 我們可能希望某些資料不要太常被訪問,隔離這些資料,即可管制訪問次數,一員工表為例,他們的薪資資訊最好另存一張表,
- 如果有一大塊資料,例如BLOB型別,這段資料或許另存為另一張表會更好,
資料模式:一對多
A表的某一條記錄可以對應到B表的多條記錄,但B表中的一條記錄只能對應A表中的某一條記錄,
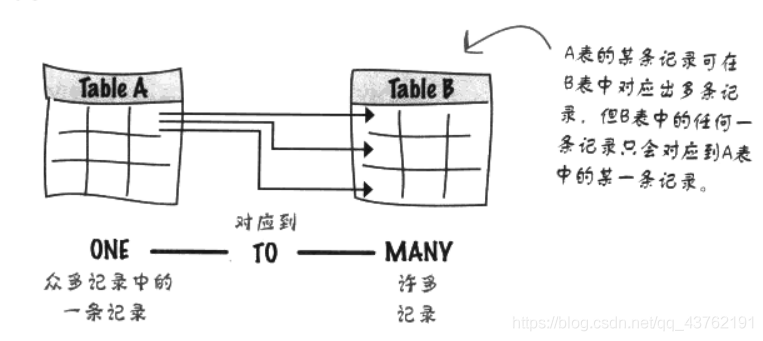
連接線應該帶有黑色箭頭來表示一對多的連接關系,
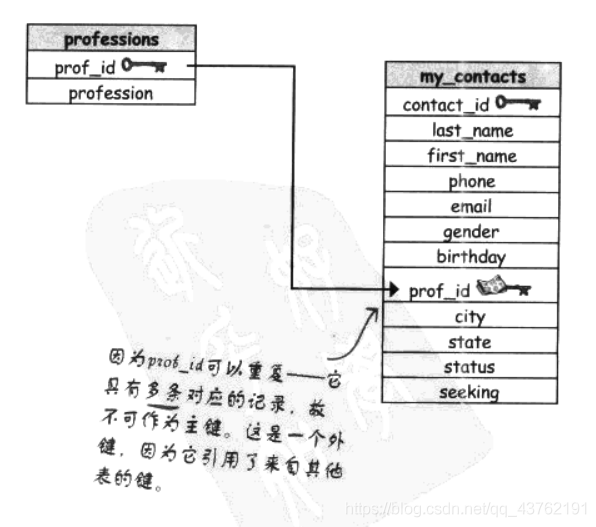
資料模式:多對多
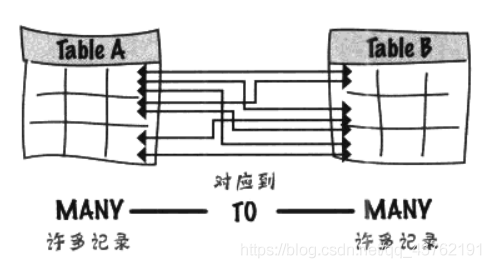
司空見慣了,中介者模式(調停者模式)該上場了,
Junction table(連接表)
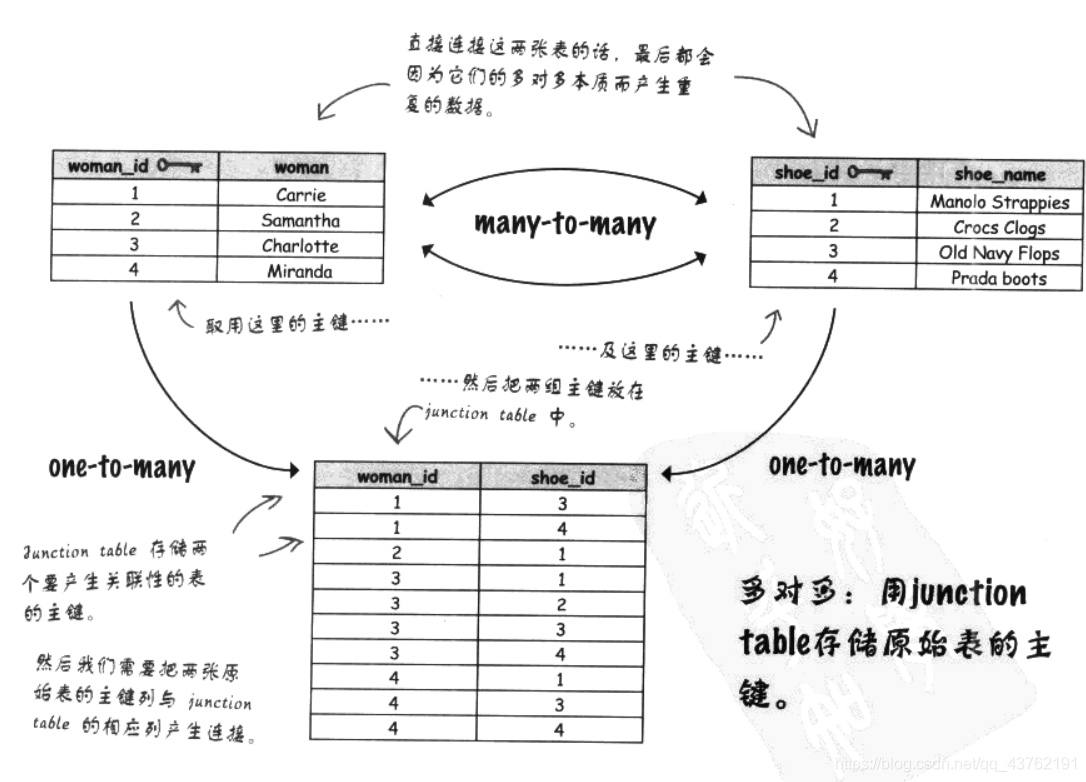
范式(NF)
第一范式(1NF)
- 資料列只包含具有院子性的值
- 沒有重復的資料組
組合鍵
組合鍵就是有多個資料列構成的主鍵,
第二范式(2NF)
- 符合1NF
- 沒有部分函式依賴性
函式依賴性
當某列的資料必須隨著另一列的資料改變而改變時,表示第一列函式依賴與第二列,
部分函式依賴:非主鍵的列依賴與組合鍵的某個部分(但不是完全依賴與組合主鍵),
傳遞函式依賴:如果改變任何非鍵列可能造成其他列的改變,即為傳遞依賴,
第三范式(3NF)
- 符合2NF
- 沒有傳遞函式依賴性
我為什么需要交叉聯接?
A:知道交叉聯接的存在,有助于我們找出修正聯接的正確方式,還有,交叉聯接有時可用于RDBMS軟體及其配置的運行速度,運行交叉聯接所需的時間可以輕易的檢測與比較出速度慢的查詢,
行內接和交叉聯接有什么區別嗎?
A:交叉聯接屬于行內接的一種,行內接就是通過查詢中的條件移除了某些結果的交叉聯接,
可以聯接多于兩張表嗎?
A:可以,后續章節再說,有點餓了,
ORDER BY 這些東西也能與聯接放到一起嗎?
A:是的,
外聯接呢?
A:莫急,
花絮
字串切割函式

同時(幾乎同時)CREATE、SELECT、INSERT
CREATE TABLE profession(
id INT(11) NOT NULL AUTP+INCREMENT PRIMARY KEY,
profession varchar(20)
);
INSERT INTO profession (profession)
SELECT profession FROM my_contacts
GROUP BY profession
ORDER BY profession;
CREATE TABLE profession AS
SELECT profession FROM my_contacts
GROUP BY profession
ORDER BY profession;
ALTER TABLE profession
ADD COLUMN id INT NOT NULL AUTO_INCREMENT FIRST,
ADD PRIMARY KEY(id);
CREATE TABLE profession(
id INT(11) NOT NULL AUTP+INCREMENT PRIMARY KEY,
profession varchar(20)
) AS
SELECT profession FROM my_contacts
GROUP BY profession
ORDER BY profession;
關鍵字AS
看上面陳述句,AS能把SELECT的查詢結果填入表中,
短短一個查詢陳述句,就出現了五次“profession”,這五次profession效果各有不同,我們容易弄暈,但是SQL能夠很輕易的分辨,
為了能讓我們容易分辨,SQL推出了假名功能,
創建別名真的很簡單,在查詢軟體中首次使用原始列名的地方后接一個AS并設定要采用的別名,告訴軟體現在開始要以另一個名稱參考my_contacs表的profession列,這樣可以讓查詢更容易被我們理解,


表的別名,誰會需要?
你會需要!
接下來要開始對表進行聯結了,嘿嘿,睜大眼睛吧,
創建表的別名的方式和創建列的別名的方式幾乎一樣,在查詢中首次出現表名的地方后接AS并設定別名,
當然,你甚至可以連AS也省了,
聯接
交叉聯接(笛卡爾積)
假設你有一個存盤男孩姓名的表以及一個記錄男孩們都有哪些玩具的表,現在我們要試著找出每個男孩擁有的玩具,
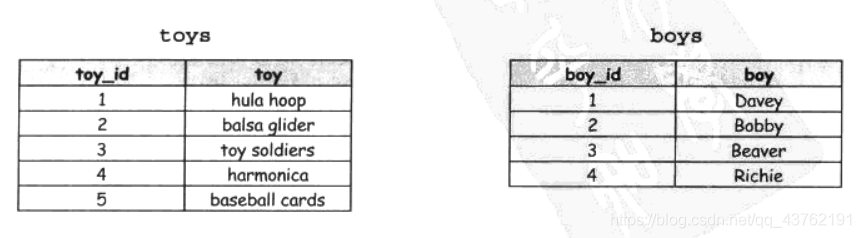
SELECT t.toy,b.boy
From toys t
CROSS JOIN
boys AS b
;
CROSS JOIN回傳兩張表的每一行相乘的結果,
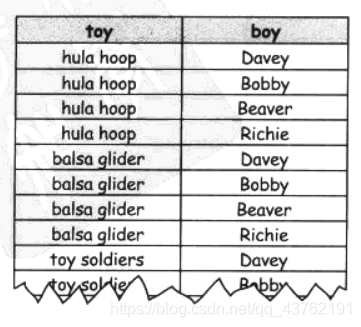
行內接
INNER JOIN利用條件判斷中的比較運算子結合兩張表的記錄,只有聯接記錄符合記錄條件時才會回傳列,
SELECT somecolumns
FROM table1
INNER JOIN
table2
ON somecondition; --條件式里課采用任何一個比較運算子,也可以改用WHERE
示例:
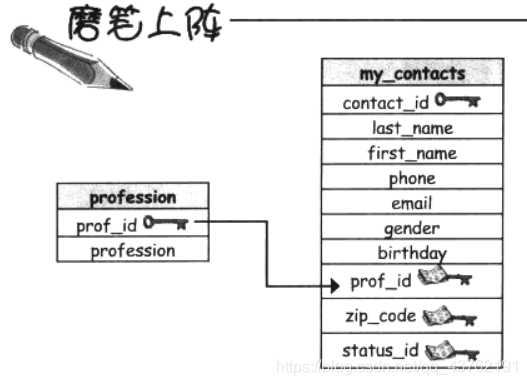
SELECT mc.last_name,mc.first_name,p.profession
FROM my_contacts AS mc
INNER JOIN
profession AS p
ON mc.prof_id = p.prof_id;

自然聯接
屬于行內接的一種,
自然聯接只有在聯接的列在兩張表中的名稱相同時才會用,
SELECT boys.boy,toys.toy
FROM boys
NATURAL JOIN
toys;
子查詢決議
在單一查詢不夠用的時候,請使用子查詢,
子查詢只不過是查詢里的查詢,
SELECT some_column,anther_column
FROM table
WHERE column = (SELECT column FROM table);
因為查詢里使用了 = 運算子,所以子查詢里只會回傳單一值,特定行和列的交叉點,這一個值將是WHERE子句中比對資料列的條件,
SELECT zip_code
FROM zip_code WHERE city =
(SELECT zip_code
From zip_code
WHERE city = 'Memphis' AND state ='TN'
)
;

非關聯子查詢
如果子查詢可以獨立運行且不會參考外層查詢的任何結果,即稱為外層查詢,
上面都是
有時候最好創建測驗資料庫來嘗試各種查詢方式,比較查詢運行時間,
聯接比子查詢更有效率,
關聯子查詢
關聯子查詢是內層查詢的決議需要依賴于外層查詢的結果,
關聯子查詢的常見用法是找出所有外層查詢結果里不存在于關聯表里的資料,
SELECT mc.first_name firstname,mc.last_name lastname,mc.email email
FROM my_contacts mc
WHERE NOT EXISTS(
SELECT * FROM job_cerrent jc
WHERE mc.contact_id = jc.contact_id
) ;
內層查詢究竟可以回傳什么?外層查詢呢?
A:大多數情況下,內層查詢只能回傳單一值,也就是一列里的一行,而后,外層查詢才能利用這個值與列中其他值進行比較,
一般而言,子查詢必須回傳一個值,使用IN是例外情況,
所以說,子查詢可以放在子查詢里嗎?
A:of couse.
據說使用子查詢能解決的事情,用聯接也可以?是這樣嗎?
A:不然呢?
左外聯接
LEFT OUTER JOIN 會匹配左表中的每一行及右表中符合條件的行,
當左表與右表具有一對多關系時,左外聯接特別有用,
理解外聯接的最大秘密在于知道表在左邊還是右邊,在LEFT OUTER JOIN中,出現在FROM后,聯接前的表稱為左表,而出現在聯接后的表稱為右表,
SELECT g.girl,t.toy
FROM girls g --g是左表
LEFT OUTER JOIN toys t --t是右表
ON g.toy_id = t.toy_id;
內外聯接有什么差別?外聯接一定會提供資料行,無論該行能否在另一個表中找出相匹配的行,
左外聯接的結果為NULL表示右表沒有找到與左表相符的記錄,
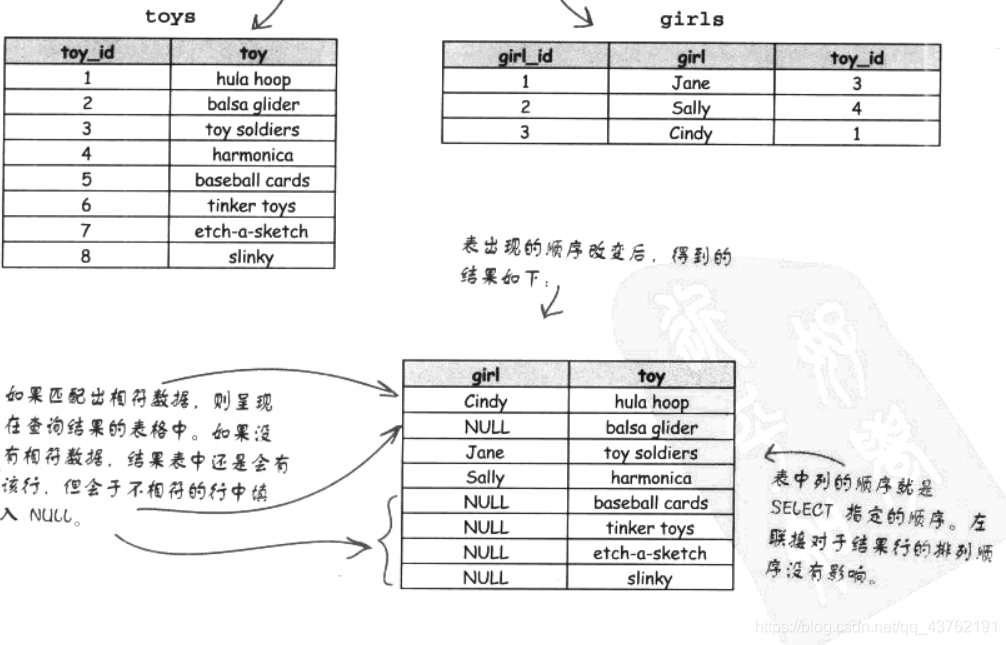
具體流程概覽(圖有點小瑕疵):
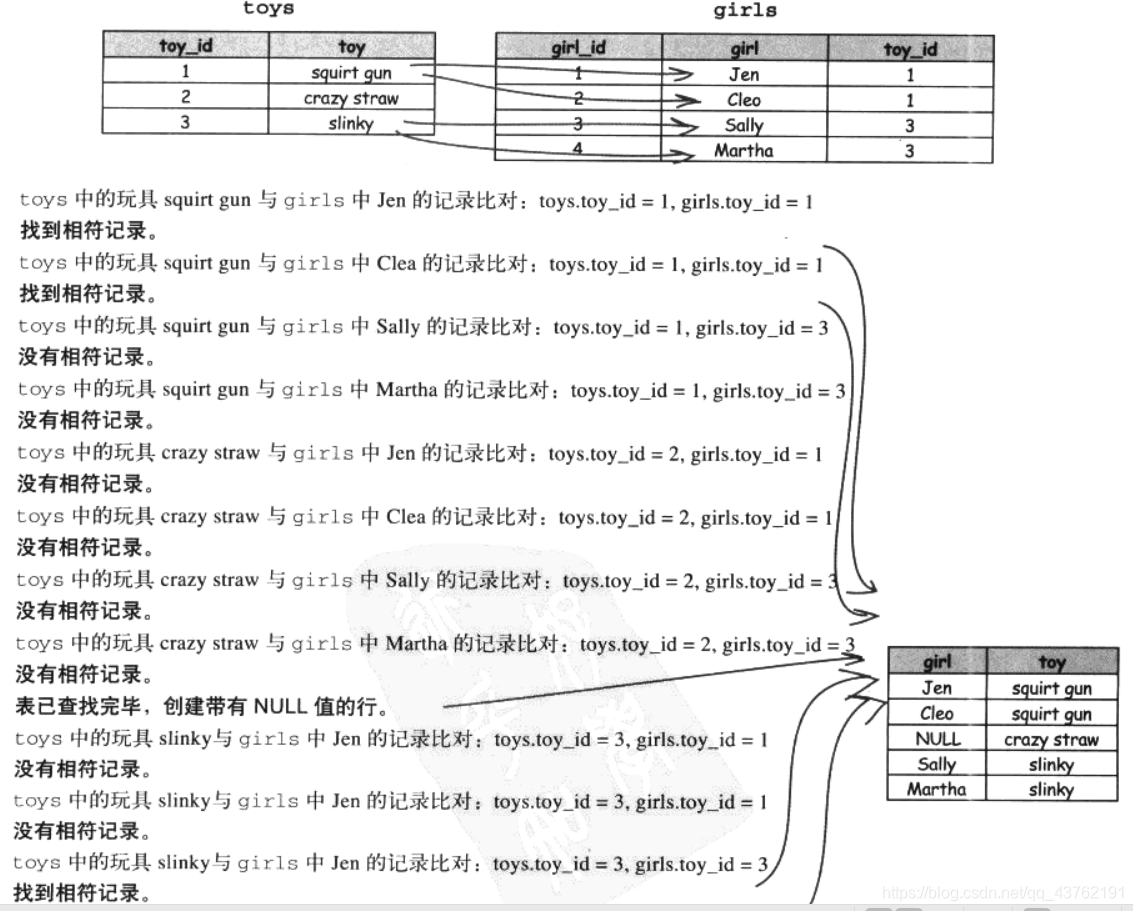
右外聯接
有外聯接與左外聯接一樣,除了它是用右表與左表比對,
自聯接
同一個表可以同時作為外聯接的左右表,雖然聽起來很奇怪,不過卻很好用,
來一題看看;
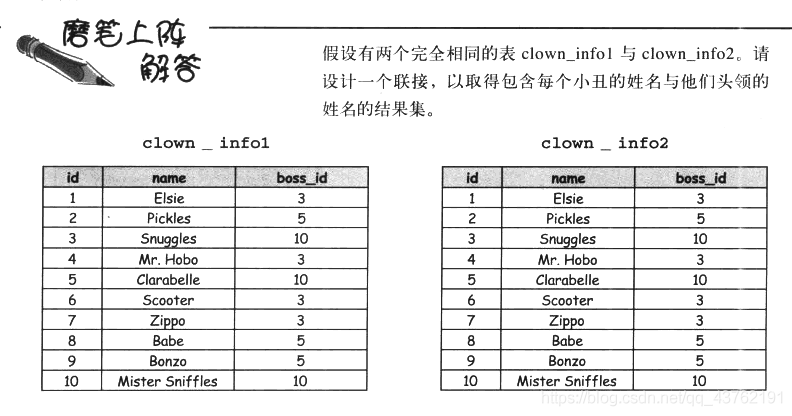
SELECT c1.name,c2.name AS boss
FROM clown_info1 c1
INNER JOIN clown_info2 c2
ON c1.bossid = c2.id
;
自聯接能夠把一張表當成兩張完全相同的表來進行查詢,
UNION
還有一種取得多張表的查詢結果的方式:UNION聯合,
UNION根據我們在SELECT中指定的列,把兩張表或更多張表的查詢結果合并至一個表中,
SELECT title FROM job_current
UNION
SELECT title FROM job_desired
UNION
SELECT title FROM job_listings;
UNION的使用限制

示例
SELECT title FROM job_current
UNION
SELECT title FROM job_desired
UNION
SELECT title FROM job_listings
ORDER BY title;
結果集:

SELECT title FROM job_current
UNION ALL
SELECT title FROM job_desired
UNION ALL
SELECT title FROM job_listings
ORDER BY title;
結果集:
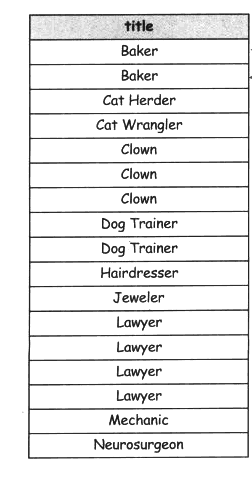
聯合規則說:選取的列必須可以互相轉換,
聯接VS子查詢


有使用左外連接取代右外聯接的理由嗎?
A:一般來說,固定使用一種聯接的習慣會讓事情更簡單,這樣不容易搞混,
檢查約束
CREATE TABLE piggy_bank(
id INT NOT NULL PRIMARY KEY,
coin CHAR(1) CHECK (coin IN ('P','N','D','Q'))
);
CHECK(檢查)用于限定允許插入某個列的值,它與WHERE子句都使用相同的條件運算式,
如果插入的值無法通過CHECk條件,則出現錯誤資訊,
ALTER TABLE my_contacts
ADD CONSTRAINT CHECk gender IN ('M','F');
視圖
創建視圖
CREATE VIEW web_designers AS
SELECT mc.first_name,mc.last_name.mc.phone,mc.email
FROM my_contacts mc
NATURAL JOIN job_desired jd
WHERE jd.title = 'Web Designer';
查看視圖
就像普通表那樣,
SELECT * FROM web_designers;
視圖的實際行動
SELECT* FROM(
SELECT mc.first_name,mc.last_name,mc.phone,mc.email
FROM my_contacts mc
NATURAL JOIN job_desired jd
WHERE jd.title = 'Web Designer' AS web_designers;
)
最后為什么要用個AS呢?因為當SELECT陳述句的結果是一個虛表時,若沒有別名,SQL就無法取得其中的表,
為什么視圖對資料庫有好處?
- 如果創建了視圖,就不需要重復創建復雜的聯接與子查詢,視圖隱藏了子查詢的復雜性,當SQL其他編程語言結合后,把視圖加入程式代碼會比加入冗長、復雜、充滿聯接的查詢更簡單,
- 為資料庫創建屬兔,可用于改變底層表結構時以視圖模仿資料庫的原始結構,因而無需修改使用舊結構的應用程式,
- 創建視圖可以隱藏讀者無需看到的訊息,
- 可以對視圖進行增刪改、約束等操作,這些操作會被寫入原表,不過這需要包括NOT NULL的值,所以少這么干,
銷毀視圖
DROP VIEW pb_dimes;
事務
事務是一群可以完成一組作業的SQL陳述句,
START TRANSACTION; --持續追蹤后續所有SQL陳述句
COMMIT; --提交所有程式代碼造成的改變
ROLLBACK; --回滾,回到事務開始前
可以查看以創建的視圖嗎?
A:SHOW TABLES;
如果我卸載了有視圖的表,會發生什么事?
A:看情況,有的RDBMS允許使用視圖,但不回傳資料,一般而言,最好先去除視圖,然后再卸載它所依據的表,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/142080.html
標籤:其他
上一篇:QWebKit 網址鏈接打不開