Time will tell.

這些年,自動駕駛的概念很火,
美國汽車工程師協會提出了六級(L0-L5)分層模型,用來衡量自動駕駛的能力和水平,許多人對這個分類模型耳熟能詳,
自動化測驗和自動化駕駛一樣,也是人類的夢想,如何衡量自動化測驗的水平呢?

有人就參考自動駕駛的分層方法,對自動化測驗也進行了類似的分級,
(參見《人工智能測驗的六個層次》、《測驗工程師不懂AI,還有未來嗎?》等文章)
仔細看完具體的分類內容后,我發現這些分級方法存在模仿過度的問題,
由于忽視了軟體測驗的本質,由于脫離了自動化測驗的實際,而劃分出在我看來有些錯亂的型別, 例如,將難度最高的測驗檢查點自動化劃分為L1層次,
給自動化測驗分等級,不能偏離測驗的基本原理,軟體測驗是構造測驗輸入,作用于被測軟體,然后觀察其實際輸出并與期望輸出進行比較的程序,
軟體測驗依賴于測驗輸入和期望輸出,其中測驗輸入與測驗資料、測驗步驟、測驗操作序列等概念等價,
在已知測驗輸入和期望輸出的情況下,自動化測驗成為一個編程問題,無數通用或專用編程語言,例如Python、Java、Robot Framework等,能夠幫助我們解決這個問題,
編程需要人工,編程之后,測驗就可以實作自動化執行,相比完全手動的L0,這個層次的自動化測驗是L1,這也是自動化測驗領域當今的主流水平,
在L1基礎上,要想更進一步,需要突破測驗輸入和期望輸出的自動生成,這是兩個問題,
1、自動生成測驗輸入
在進行軟體測驗時,測驗人員需要精心構造測驗資料和測驗步驟,以期實作更高的覆寫,發現更多的bug,
業界嘗試了許多方法,來自動生成測驗資料和步驟,例如隨機方法、Fuzzing方法、基于搜索的方法、基于模型的方法、基于機器學習的方法等,
這些方法或多或少存在以下問題:
(1) 生成的用例數量過多
(2) 生成的用例長度過長
(2) 產生的誤報率過高
(4) 測驗的覆寫率過低等,除了有成本低的優勢之外,它們與人工設計相比,質量還相差甚遠,
測驗輸入的生成處于研究階段,可落地成果還較少,倘若突破了測驗輸入的自動生成,那么我們可以達到L2級的自動化測驗,
2、期望輸出自動生成
寫過測驗用例的人都知道,用例的相當篇幅是關于檢查點的,為了一個個檢查點,我們需要對說明檔案摳字眼,需要與用戶、與產品經理、與開發人員反復核對,即使這樣,有時候用例失敗報bug,結果由于我們的檢查點不合理而被打回,
這些現象從側面反映了測驗結果判定的難度,結果判定難,關鍵在于軟體的期望輸出獲取難,這個難題又叫做oracle難題,這里oracle的意思是預言、神諭,可以說,做預言有多難,生成期望輸出就有多難,人工都難,自動化就更難了,
oracle自動化之難,難于上青天,
過去幾十年的研究表明,大家對測驗oracle自動化基本還沒多少辦法,倘若突破了oracle生成的自動化,那么我們就可以實作L3級別的自動化測驗,
只有用例生成、用例執行和結果判定都自動化了,軟體測驗才能夠實作端到端、一站式的自動化,這是自動化測驗的終極目標,是測驗之巔,是真正的“解放”,
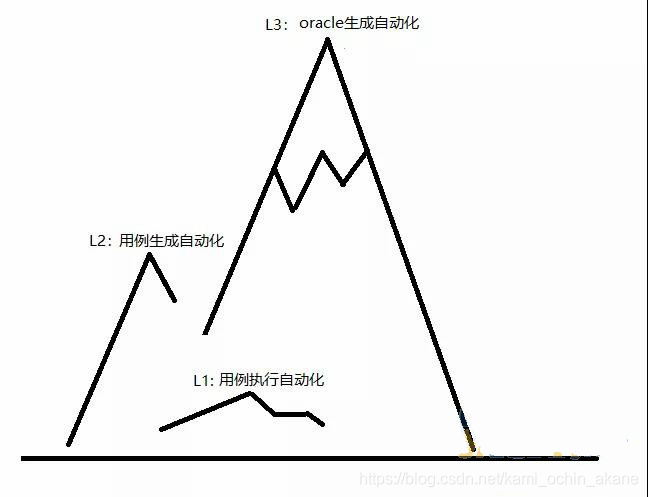
這張圖就是我認為的自動化測驗等級模型,這個模型很簡單,也比較符合實際,
說它符合實際,是因為自動化測驗的現狀就是:用例執行自動化80分,用例生成自動化20分,oracle自動化5分,
基于這個實際,任何的新技術、新工具,例如機器學習、人工智能,只有解決了測驗真正的瓶頸問題(用例生成和oracle生成),才能算明顯地推動了測驗的進步,

絮叨
對面試題、軟體、介面、自動化測驗、python感興趣的可以加入我們175317069一起學習喔,群內會有不定期測驗資料鏈接發放,
喜歡的話,歡迎【評論】、【點贊】、【關注】禮貌三連
Time will tell.(時間會證明一切)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/143243.html
標籤:其他
下一篇:如何最快速度上手介面測驗?