作者|PURVA HUILGOL
編譯|Flin
來源|analyticsvidhya
開始你的深度學習生涯?
對于新手來說,深度學習是一個復雜而令人生畏的領域,像隱藏層、卷積神經網路、反向傳播等概念在你試圖掌握深入學習的主題時不斷出現,
這并不容易——尤其是如果你走的是非結構化的學習道路,而且沒有首先了解基本的概念,你會像一個沒有地圖的游客一樣在外國城市里蹣跚而行!
有一個好訊息——你不需要高級學位或博士學位來學習和掌握深度學習,但是,在進入深度學習世界之前,你應該了解(并精通)某些關鍵概念,
在本文中,我將介紹五個這樣的基本概念,我還建議你通過以下資源來豐富你的深度學習經驗:
-
神經網路入門(免費課程)
- https://courses.analyticsvidhya.com/courses/Introduction-to-Neural-Networks
-
使用深度學習的計算機視覺
- https://courses.analyticsvidhya.com/courses/computer-vision-using-deep-learning-version2
-
2020年深度學習的綜合學習之路
- https://www.analyticsvidhya.com/blog/2020/01/comprehensive-learning-path-deep-learning-2020/
開始深度學習之旅的五個基本要素是:
-
準備系統
-
Python編程
-
線性代數與微積分
-
概率統計
-
關鍵的機器學習概念
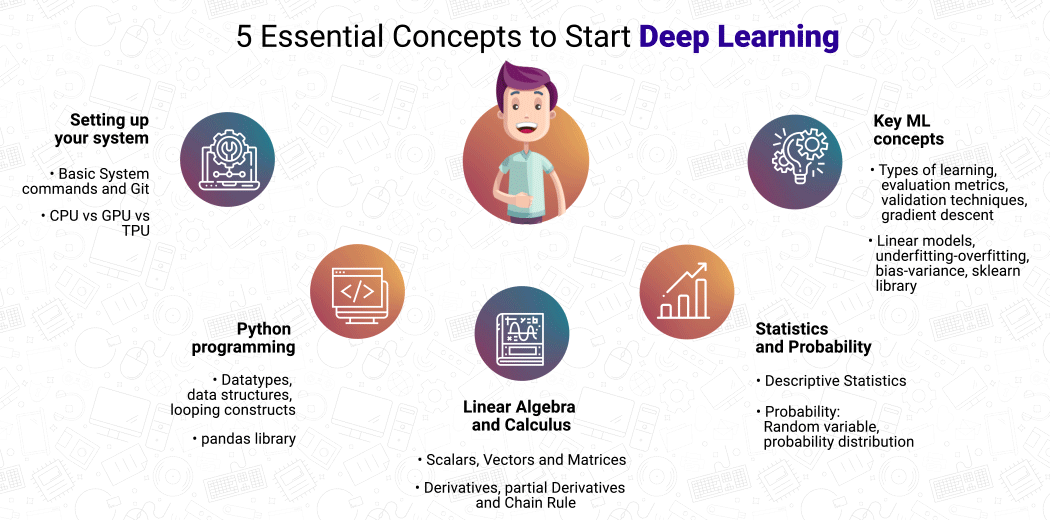
讓我們一一介紹,
1.準備系統
要學習新技能(例如烹飪),你首先需要擁有所有設備,你將需要工具,例如刀,炊具,當然還有燃氣灶!你還需要知道如何使用這些工具,

同樣,建立你的系統進行深度學習,了解所需工具以及如何使用它們也很重要,
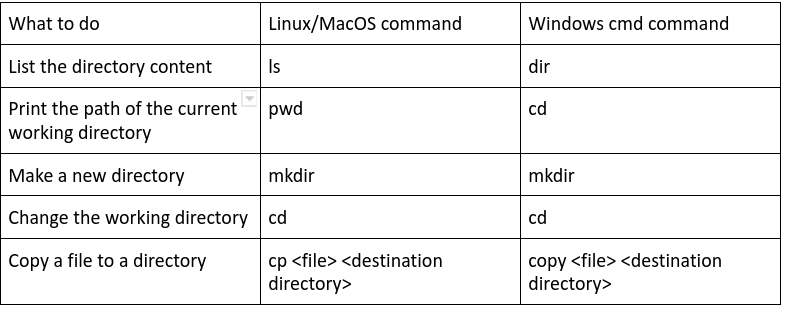
無論你使用的是Windows,Linux或Mac作業系統,都必須了解基本命令,這是一個方便的表格供你參考:
這是一個很棒的教程,可以讓你開始使用Git和基本的Git命令:https://www.vogella.com/tutorials/Git/article.html
深度學習熱潮不僅帶來了AI領域的突破性研究,而且打破了計算機硬體的新壁壘,
GPU(圖形處理單元):
對于大多數深度學習專案,你將需要GPU來處理影像和視頻資料,你也可以在沒有GPU的筆記本電腦/ PC上構建深度學習模型,但是這樣做將非常耗時,GPU必須提供的主要優勢是:
- 它允許并行處理
- 在CPU + GPU組合中,CPU將復雜的任務分配給GPU,并將其他任務分配給自身,從而節省了大量時間
這是一段精彩的視頻,解釋了GPU和CPU之間的區別:
- https://youtu.be/-P28LKWTzrI
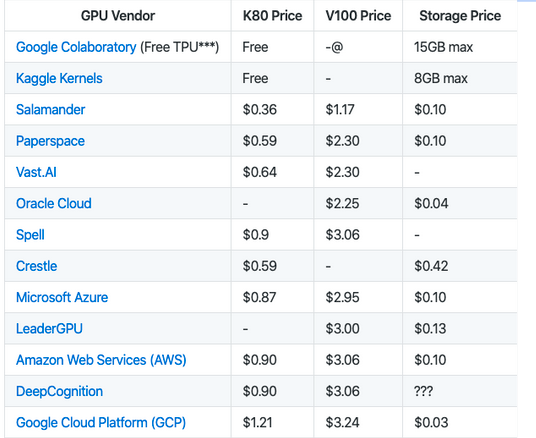
你無需購買GPU或在計算機上安裝GPU,有多種云計算資源可免費提供或以極低的成本提供GPU,此外,有一些預裝了一些練習資料集并預先加載了自己的教程的GPU,其中一些是Paperspace Gradient,Google Colab和Kaggle Kernels,
另一方面,也有成熟的服務器,它們需要一些安裝步驟和一些自定義功能,例如Amazon Web Services EC2,
下表說明了你擁有的選項:
深度學習還使得 Google 開發了自己型別的處理單元,專門用于構建神經網路和深度學習任務-TPU,
TPUs
TPU或張量處理單元本質上是與CPU一起使用的協處理器,TPU比GPU便宜,因此速度要快得多,因此可以輕松構建深度學習模型,
Google Colab還提供免費使用的TPU(不是完整的企業版,而是云版),這是Google自己的有關使用TPU并在其上建立模型的Colab教程: Colab notebooks | 云TPU,
- https://cloud.google.com/tpu/docs/colabs
總結一下,這是開始構建深度學習模型的基本最低硬體要求:

2. Python編程
繼續采用學習烹飪的類比,現在你掌握了操作刀子和煤氣灶的竅門,但是實際烹飪食物所需的技能和食譜呢?
這就是我們遇到深度學習所需的軟體的地方,Python是一種用于深入學習的跨行業編程語言,

然而,對于深度學習所需的計算和操作,我們不能只使用Python,其他功能由Python中的庫提供,一個庫可以有數百個稱為函式的小工具,我們可以用來編程,
雖然你不需要成為深入學習的編碼忍者,但你確實需要了解Python編程的基本知識
也就是說,與其掌握Python編程的浩瀚海洋,不如先學習一些專門用于機器學習和處理資料的特定庫
Anaconda是一個幫助你跟蹤Python版本和庫的框架,它是一個方便的多功能工具,非常流行,易于使用,并且有簡單的檔案,下面是如何安裝Anaconda ,
- https://www.analyticsvidhya.com/blog/2019/08/everything-know-about-setting-up-python-windows-linux-and-mac/
那么我所說的Python基礎是什么意思呢?讓我們更詳細地討論一下,
注意:你可以在我們的免費課程中開始學習Python
- https://courses.analyticsvidhya.com/courses/introduction-to-data-science
1. Python中的變數和資料型別
Python中的主要資料型別是:
- Int:整數
- Float:小數
- String:單個字符或字符序列
- Bool:保存2個布林值-True和False
2. Python中的運算子
Python中有5種主要的運算子型別:
- 算術運算子:+,-,*,/ 等
- 比較運算子:如<,>,<=,> =,==,!=
- 邏輯運算子:and, or, not
- 標識運算子:is, is not
- 成員資格運算子:in, not in
3. Python中的資料結構
Python提供了多種資料集,可用于不同目的,每個資料結構都有其獨特的屬性,我們可以利用它們存盤不同型別的資料和資料型別,這些屬性是:
-
有序的: 這意味著資料結構中元素的存盤順序是特定的,無論我們如何以及何時使用它,此順序都將保持不變(除非我們明確更改它)
-
不可變:這意味著無法更改資料結構,如果資料結構是可變的,則意味著可以更改它
在資料科學中,最常用的資料結構是:
- Lists:有序且可變
示例:我們有一個這樣的串列:
my_list = [1、3、7、9]
在使用到此串列的所有地方,此順序都將保持不變,另外,我們可以更改此串列,例如洗掉7,添加11等,
- Tuple:類似于串列(有序),但與串列不同,元組是不可變的
示例:元組可以宣告為:
my_tuple = ("apple", "banana", "cherry")
現在,此順序將保持不變,但是與串列不同,我們無法洗掉“cherry”或在元組中添加“orange”,
- Sets:無序且可變,盡管它們只能容納唯一的值
示例:集合使用如下花括號:
my_set = {'apple', 'banana', 'cherry'}
沒有為集合定義順序,
- Dictionaries:一組<鍵,值>對,字典是無序且可變的,這意味著它們基本上沒有順序,可以更改,但是可以通過索引或鍵進行訪問,字典只能具有唯一鍵,盡管鍵不一定必須具有唯一值,
示例:字典還使用鍵值格式的花括號:
my_dict = { "brand": "Ford", "model": "Mustang", "year": 1964}
在這里,“brand”,“model”和“year”是分別具有值“Ford”,“Mustang”和“ 1964”的鍵,每次列印字典時,鍵的順序可以不同,
4. Python中的控制流
控制流意味著控制代碼執行流,我們一行一行地執行代碼,一行執行的內容會影響我們撰寫下一行代碼的方式:
條件陳述句
通過我們之前看到的條件運算子設定條件,
- if-else:你今天想吃點什么?漢堡還是沙拉?如果你想要更健康的選擇,則可以選擇沙拉,或者,如果你只是想要一口快餐而又不關心卡路里,則可以選擇漢堡,這就是if-else條件陳述句的作用
示例:你需要檢查學生是通過還是不通過,如果他獲得的分數> = 40,則表示他已通過;否則,他的成績是不通過,
在這種情況下,我們的條件陳述句將是:
if marks >= 40:
print("Pass")
else:
print("Fail")
回圈
for回圈:用來遍歷序列,該序列可以表示字符序列(字串)或上面的任何資料結構,例如串列,集合,元組和字典
示例:我們有一個值從1到5的串列,我們需要將此串列中的每個值乘以3:
numbers_list = [1, 2, 3, 4, 5]
for each_number is numbers_list:
print(each_number * 3)
試試上面的代碼片段,你會發現Python多么簡單!
有趣的是:與其他編程語言不同,我們不需要在資料結構中存盤相同型別的變數,我們完全可以有一個像這樣的串列[John,153,78.5,“ A +”]甚至是一個像 [ [“A”,56],[“ B”,36.5] ] 這樣的串列,正是Python的多樣性和靈活性使它在資料科學家中如此受歡迎!
你還可以利用以下涉及Python和Pandas基本知識的免費課程:
- Python for Data Science課程–免費課程
- https://courses.analyticsvidhya.com/courses/introduction-to-data-science
- Pandas用Python進行資料分析
- https://courses.analyticsvidhya.com/courses/pandas-for-data-analysis-in-python
5.Pandas Python
這是你啟動機器學習和深度學習時會遇到的庫之一,Pandas是一個非常受歡迎的庫,對于深度學習和機器學習都是必需的,
我們以多種格式存盤資料,例如CSV(逗號分隔值)檔案,Excel作業表等,為了處理這些檔案中的資料,Pandas提供了一種稱為Pandas資料框的資料結構(你可以考慮一下作為表格),
資料框和Pandas在資料框上提供的大量操作使其成為機器和深度學習的主力庫,
如果你還沒有Pandas的話,可以選擇免費的簡易課程:https://courses.analyticsvidhya.com/courses/pandas-for-data-analysis-in-python
現在,如果你閱讀了我們開始做的清單中的5件事,你可能會有一個問題:深度學習中的數學將如何處理?
好吧,讓我們找出答案!
3.深度學習的線性代數和微積分
有一個普遍的誤區,即深度學習需要高級的線性代數和微積分知識,好吧,讓我在這里消除這個誤區,
你只需要回憶起你的高中數學就可以開始深度學習之旅!
讓我們舉一個簡單的例子,我們有貓和狗的影像,我們希望機器告訴我們任何給定影像中存在哪種動物:
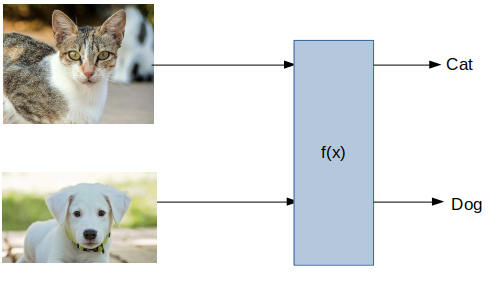
現在,我們可以在此處輕松識別貓和狗,但是機器將如何區分兩者?唯一的方法是以數字的形式將資料提供給模型,這就是我們需要線性代數的地方,我們基本上將貓和狗的影像轉換為數字,這些數字可以表示為向量或矩陣,
我們將介紹一些關鍵術語以及一些你可以從中學習的重要資源,
深度學習的線性代數
1. 標量和向量:雖然標量僅具有幅度,但向量同時具有方向和幅度,
- 點積:兩個向量的點積回傳一個標量值
- 叉積:兩個向量的叉積回傳另一個與這兩個向量正交(直角)的向量
示例:如果我們有2個向量 a = [1,-3,5] 和 b = [4,-2,-1],則:
a)點積:
a . b = (a1 * b1) + (a2 * b2) + (a3 * b3) = (1 * 4) + (-3 * -2) + (5 * 1) = 3
b)叉積:
a X b = [c1, c2, c3] = [13, 21, 10]
當
c1 =(a2 * b3)-(a3 * b2)
c2 =(a3 * b1)-(a1 * b3)
c3 =(a1 * b2)-(a2 * b1)
2.矩陣和矩陣運算:矩陣是行和列形式的數字陣列,例如,上面的貓的影像可以寫成像素矩陣:
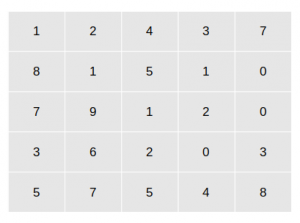
就像數字一樣,我們可以對兩個矩陣執行加法和減法的操作,但是,乘法和除法等運算與常規方式稍有不同:
-
標量乘法:當我們將單個標量值與矩陣相乘時,我們將標量與矩陣中的所有元素相乘
-
矩陣乘法:將2個矩陣相乘意味著計算行和列的點積,并創建一個尺寸與2個輸入矩陣不同的新矩陣
-
矩陣的轉置:我們交換矩陣中的行和列以獲取其轉置
-
逆矩陣:從概念上看,它與反數字相似,矩陣的逆與矩陣相乘即可??得到一個單位矩陣
你可以參考這本關于線性代數的Khan Academy優秀課程,以詳細了解上述概念,你還可以在此處檢查線性代數的10個強大應用程式,
- 課程:https://www.khanacademy.org/math/linear-algebra
- 線性代數的10個強大應用程式:https://www.analyticsvidhya.com/blog/2019/07/10-applications-linear-algebra-data-science
深度學習微積分
我們試圖預測的值,例如“ y”,就是影像是貓還是狗,該值可以表示為輸入變數/輸入向量的函式,我們的主要目的是使此預測值接近實際值,
現在,想象一下處理成千上萬的貓和狗的影像,這些看上去確實很可愛,但是你可以想象,處理這些影像和數字根本不容易!
由于深度學習本質上涉及大量資料和復雜的機器學習模型,因此兩者的使用通常會浪費時間和資源,這就是為什么重要的是要優化我們的深度學習模型,以使其能夠盡可能準確地進行預測而無需使用過多的資源和時間,
這就是深度學習中微積分的關鍵所在:優化,
在任何深度學習或機器學習模型中,我們都可以將輸出表示為輸入變數的數學函式,因此,我們需要查看輸出如何隨每個輸入變數的變化而變化,我們需要衍生工具來執行此操作,因為衍生工具表示變化率,
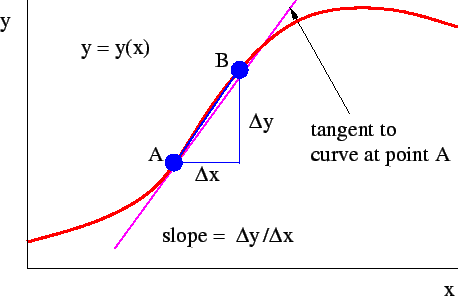
導數和偏導數:簡單來說,當我們改變輸入值時,導數測量輸出值的變化,用數學術語來說:
If y = f(x), then the derivative of y with respect to x, id given as
dy/dx = change in y / change in x
在幾何上,如果我們將f(x)表示為圖,則該點的導數也是該點在該圖上的切線的斜率,
這是一個可以幫助你理解它的圖:
我們上面看到的導數僅涉及一個變數x,但是,在深度學習中,最終輸出y可能取決于數百個變數,在這種情況下,我們需要針對每個輸入變數計算y的變化率,這是偏導數出現的地方,
偏導數:基本上,我們只考慮一個變數,而將所有其他變數保持不變,然后,我們使用剩余變數計算y的導數,這樣,我們就可以計算每個變數的導數,
鏈式規則:通常,根據輸入變數,y的函式可能要復雜得多,那么我們如何計算導數?鏈式規則可幫助我們計算以下內容:
If y = f(g(x)), where g(x) is a function of x, and f is a function of g(x), then
dy/dx = df/dx * dg/dx
讓我們考慮一個相對簡單的示例:
y = sin(x ^ 2)
因此,使用鏈式規則:
dy / dx = d(sin(x2))/ dx * d(x2)/ dx = cos(x2)* 2x
深度學習微積分的學習資源:
- 可汗學院微積分課程:微積分
- https://www.khanacademy.org/math/differential-calculus
- 3Blue1Brown上有關于數學和微積分的精彩視頻:
- https://www.youtube.com/channel/UCYO_jab_esuFRV4b17AJtAw
4.深度學習的概率統計
就像線性代數一樣,“統計和概率”是它自己的數學新世界,對于初學者來說,這可能是非常令人生畏的,甚至經驗豐富的資料科學家有時都覺得回憶先進的統計概念是很有挑戰性的,
但是,不可否認,統計學是機器學習和深度學習的骨干力量,概率和統計的概念(例如描述性統計和假設檢驗)在行業中至關重要,在該行業中,深度學習模型的可解釋性是重中之重,
讓我們從基本定義開始:
-
統計是對資料的研究
-
描述統計是對描述和表示資料的數學工具的研究
-
概率衡量事件發生的可能性
描述性統計
讓我舉一個簡單的例子,假設你在入學考試中獲得1000名學生的分數(滿分為100分),有人問你:學生在這次考試中的表現如何?你能向那個人介紹學生的分數嗎?將來,你可能會但首先會說平均分數為68,這是資料的平均值,
同樣,我們可以根據資料找出更簡單的陳述句:
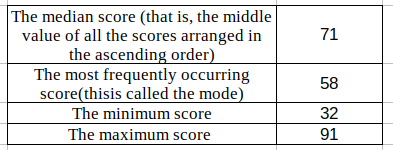
到此為止,只需說幾行,我們就可以說大多數學生的成績都不錯,但在測驗中得分不高的人并不多,這就是描述統計,我們僅使用5個值表示了1000名學生的資料,
描述性統計中還使用了其他關鍵術語,例如:
- 標準偏差
- 方差
- 正態分布
- 中心極限定理
可能性
基于同一示例,假設你被問到一個問題:如果我從這1000名學生中隨機選擇一名學生,他/她通過考試的機會是多少?概率的概念將幫助你回答這個問題,如果你獲得0.6的概率,則表明他/她通過的概率為60%(假設通過標準為40分),
可以使用假設檢驗和推論統計來回答關于同一資料的其他問題(如下所示):
- 入學考試能被認為是難的嗎?
- 學生的高分是努力學習的結果還是因為考試中的問題很容易?
你可以從以下資源中了解有關統計和概率的所有資訊:
-
資料科學導論(統計與概率論)
- https://courses.analyticsvidhya.com/courses/introduction-to-data-science-2
-
綜合實用推理統計指南
- https://www.analyticsvidhya.com/blog/2017/01/comprehensive-practical-guide-inferential-statistics-data-science/
-
資料科學概率基礎
- https://www.analyticsvidhya.com/blog/2017/02/basic-probability-data-science-with-examples/
-
你的統計假設假設測驗指南
- https://www.analyticsvidhya.com/blog/2015/09/hypothesis-testing-explained/
5.深度學習的關鍵機器學習概念
這是個好訊息——你無需了解當今存在的機器學習演算法的全部范圍,并不是說它們無關緊要,而是僅從開始深度學習的角度來看,你不需要了解很多,
但是,有一些概念對于建立你的基礎并熟悉自己至關重要,讓我們回顧一下這些概念,
有監督和無監督演算法
-
監督學習:在這些演算法中,我們知道目標變數(我們要預測的),我們知道輸入變數(有助于目標變數的獨立特征),然后,我們生成一個方程,給出輸入變數和目標變數之間的關系,并將其應用于我們擁有的資料,示例: kNN, SVM,線性回歸等,
-
無監督學習:在無監督學習中,我們不知道目標變數,它主要用于將資料聚類為組,并且在聚類資料后我們可以識別出組,無監督學習的示例包括 k均值聚類,先驗演算法等,
評估指標
建立預測模型并不是深度學習所需的唯一步驟,你需要檢查模型的質量,并不斷對其進行改進,直到我們達到最佳模型為止,
那么,我們如何判斷深度學習模型的性能呢?我們使用一些評估指標,根據任務,我們對回歸和分類有不同的評估指標,
-
分類的評估指標:
-
混淆矩陣
-
準確性
-
精確度和召回率
-
F1分數
-
AUC-ROC
-
日志損失
-
-
回歸評估指標:
-
RMSE
-
RMSLE
-
R2和調整后的R2
-
評估指標在深度學習中至關重要,無論是在研究領域還是在行業中,你的深度學習模式都將根據評估指標的價值來判斷,
-
每個人都應該知道的11種重要的機器學習模型評估指標
- https://www.analyticsvidhya.com/blog/2019/08/11-important-model-evaluation-error-metrics
-
免費課程——機器學習模型的評估指標
- https://courses.analyticsvidhya.com/courses/evaluation-metrics-for-machine-learning-models
驗證技術
深度學習模型會根據提供給它的資料進行自我訓練,但是,如上所述,我們需要改進此模型,并且需要檢查其性能,僅當我們提供全新的資料(盡管已清理)時,才能觀察到模型的真正威力,
但是,我們如何改進該模型?每當我們想更改一個引數時,我們是否就給它新的資料?你可以想象這樣一項任務將是多么耗時又昂貴的事情!
這就是為什么我們使用驗證,我們將整個資料分為三個部分:訓練,驗證和測驗,這是一個簡單的句子,可以幫助你記住:
我們在訓練集上訓練模型,在驗證集上對其進行改進,最后在迄今為止看不見的測驗集上進行預測,
交叉驗證的一些常見策略是:k倍交叉驗證和留一法交叉驗證(LOOCV),
這是一篇全面的文章,內容涉及驗證技術以及如何在Python中實施驗證技術:使用交叉驗證提高模型性能(在Python / R中)
- https://www.analyticsvidhya.com/blog/2018/05/improve-model-performance-cross-validation-in-python-r
梯度下降
讓我們回到前面看到的演算以及對優化的需求,我們怎么知道我們已經達到了最好的模型?我們可以在方程式中進行一些細微的更改,每次更改時,我們都會檢查是否接近實際值,
這是朝著可能的方向邁出一小步的行為,也是梯度下降背后的基本直覺,梯度下降是你在深度學習中會遇到并經常重溫的最重要概念之一,
Python中的梯度下降的解釋和實作:機器學習中的梯度下降演算法(以及變體)簡介,
線性模型
你能想到的最簡單的方程式是什么?讓我列出一些:
- Y = x + 1
- 4x + 3y -2z = 56
- Y = x /(1-x)
你是否注意到這三個功能共有的一件事?是的,它們都是線性函式,如果我們可以使用這些函式預測y的值怎么辦?
然后這些被稱為線性模型,如果你知道線性模型在業界有多流行,你會感到驚訝的,它們不是太復雜,是可解釋的,而且通過正確的梯度下降,我們也可以得到高的評估指標!不僅如此,線性模型構成了深入學習的基礎,例如,你知道你可以用一個簡單的神經網路建立一個邏輯回歸模型嗎?
這里有一個詳細的指南,不僅涵蓋線性和邏輯回歸,還包括其他線性模型:資料科學中的7種回歸型別和技術,
- https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression
過擬合與過擬合
你經常會遇到這樣的情況:你的深度學習模型在訓練集上表現很好,但在驗證集上卻給你很差的準確度,這是因為模型正在從訓練集中學習每一個模式,因此,它無法在驗證集中檢測這些模式,這被稱為過度擬合資料,它使模型過于復雜,
另一方面,如果你的深度學習模型在訓練集和驗證集上都表現不佳,那么它很可能不適合,當我們的資料實際上是非線性的(復雜的)時,可以把它看作是對我們的資料應用一個線性方程(一個過于簡單的模型):
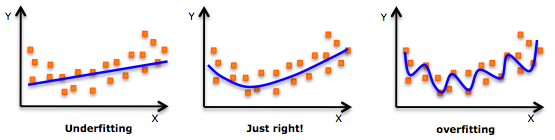
一個過擬合和欠擬合的簡單類比是一個學生在數學課上的例子:
-
過擬合與該學生死記硬背地學習了課堂上討論的所有問題,但在考試期間無法回答與同一概念有關的不同問題有關
-
欠擬合是那些在課堂上或考試中表現不佳的學生,我們的目標讀者是那些不需要知道課堂上討論的所有問題但在考試中表現出色的模型/學生,以表明他/她知道概念
看看這個關于過擬合和欠擬合的直觀解釋,以及它們之間的比較:機器學習中的過擬合與欠擬合,
- https://www.analyticsvidhya.com/blog/2020/02/underfitting-overfitting-best-fitting-machine-learning
偏差方差
用最簡單的術語來說,偏差是實際值和預測值之間的差,方差是通過更改訓練資料時輸出的變化來衡量的,
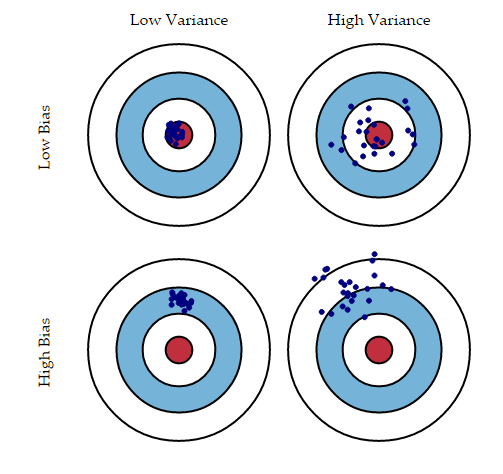
讓我們快速總結一下上圖可以解釋的內容:
-
左上:非常精確的模型,因此我們的模型的誤差會很低,這意味著偏差和偏差都較小,所有資料點都適合靶心
-
右上:預測的資料點以靶心為中心(低方差),但彼此之間也相距甚遠(高偏差)
-
左下:預測值聚集在一起(低方差),但與靶心相去甚遠(高偏差)
-
右下:預測資料點既不靠近靶心(高偏差)也不彼此靠近(高方差)
高偏差和高方差都會導致誤差增加,通常,高偏差表示擬合不足,而高方差表示擬合過度,既要實作低偏差又要實作低方差是非常困難的——一個通常是以另一個為代價的,
在模型復雜度方面,我們可以使用下圖來確定模型的最佳復雜度:

sklearn
就像Pandas庫一樣,還有另一個庫構成了機器學習的基礎,sklearn庫是機器學習中最受歡迎的庫,它包含大量的機器學習演算法,你可以將它們以函式的形式應用于資料,
此外,sklearn甚至還具有用于所有評估指標,交叉驗證以及縮放/標準化資料的功能,
這是一個實際的sklearn示例:
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error
regr = LinearRegression()
#train your data - remember how we train the model on our train set?
regr.fit(X_train, y_train)
#predict on our validation set to improve it
y_pred = regr.predict(X_Valid)
#evaluation metrics: MSE
print('Mean Squared Error:', mean_squared_error(y_test, y_pred))
...#further improvement of our model
我們可以用少于10行的代碼構建一個簡單的線性回歸模型!
這里有一些很好的資源,可以進一步了解sklearn:
-
scikit-learn(sklearn)機器學習入門
- https://courses.analyticsvidhya.com/courses/get-started-with-scikit-learn-sklearn
-
你需要了解的關于kitkit-learn最新更新的所有資訊
- https://www.analyticsvidhya.com/blog/2020/02/everything-you-should-know-scikit-learn
尾注
在本文中,我們介紹了在構建第一個深度學習模型之前需要了解的5個基本事項,在這里,你將遇到流行的深度學習框架,如PyTorch和TensorFlow,它們是用Python構建的,由于你很好的掌握了Python,現在可以很容易地理解如何使用它們,
下面是幾篇關于這些框架的好文章:
-
深度學習指南:介紹如何在Python中使用TensorFlow實作神經網路
- https://www.analyticsvidhya.com/blog/2016/10/an-introduction-to-implementing-neural-networks-using-tensorflow/
-
Pythorch的一個初學者友好的指南及其如何從頭開始作業
- https://www.analyticsvidhya.com/blog/2019/09/introduction-to-pytorch-from-scratch/
一旦你在這五大支柱上建立了自己的基礎,你就可以探索更高級的概念,如超引數調整、反向傳播等,這些都是我積累了深入學習知識的概念,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/03/deep-learning-5-things-to-know/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/143256.html
標籤:其他
下一篇:手賤洗掉usb驅動,該如何恢復