作者|LAKSHAY ARORA
編譯|Flin
來源|analyticsvidhya
總覽
-
Web抓取是一種從網站提取資料的高效方法(取決于網站的規定)
-
了解如何使用流行的BeautifulSoup庫在Python中執行網頁抓取
-
我們將介紹可以抓取的不同型別的資料,例如文本和影像
介紹
我們擁有的資料太少,無法建立機器學習模型,我們需要更多資料!
如果這句話聽起來很熟悉,那么你并不孤單!希望獲得更多資料來訓練我們的機器學習模型是一個一直困擾人們的問題,我們無法在資料科學專案中獲得可以直接使用的Excel或.csv檔案,對嗎?
那么,如何應對資料匱乏的問題呢?
實作此目的最有效,最簡單的方法之一就是通過網頁抓取,我個人發現網路抓取是一種非常有用的技術,可以從多個網站收集資料,如今,某些網站還為你可能希望使用的許多不同型別的資料提供API,例如Tweets或LinkedIn帖子,

但是有時你可能需要從不提供特定API的網站收集資料,這就是web抓取能力派上用場的地方,作為資料科學家,你可以撰寫一個簡單的Python腳本并提取所需的資料,
因此,在本文中,我們將學習Web抓取的不同組件,然后直接研究Python,以了解如何使用流行且高效的BeautifulSoup庫執行Web抓取,
我們還為本文創建了一個免費課程:
- 使用Python進行Web爬網簡介,這種結構化的格式將幫助你更好地學習,
- https://courses.analyticsvidhya.com/courses/introduction-to-web-scraping
請注意,網頁抓取要遵守許多準則和規則,并非每個網站都允許用戶抓取內容,因此存在一定的法律限制,在嘗試執行此操作之前,請務必確保已閱讀網站的網站條款和條件,
目錄
-
3個流行的工具和庫,用于Python中的Web爬蟲
-
Web爬網的組件
- Crawl
- Parse and Transform
- Store
-
從網頁中爬取URL和電子郵件ID
-
爬取圖片
-
在頁面加載時抓取資料
3個流行的工具和庫,用于Python中的Web爬蟲
你將在Python中遇到多個用于Web抓取的庫和框架,以下是三種高效完成任務的熱門工具:
BeautifulSoup
-
BeautifulSoup是Python中一個了不起的決議庫,可用于從HTML和XML檔案進行Web抓取,
-
BeautifulSoup會自動檢測編碼并優雅地處理HTML檔案,即使帶有特殊字符也是如此,我們可以瀏覽已決議的檔案并找到所需的內容,這使得從網頁中提取資料變得快捷而輕松,在本文中,我們將詳細學習如何使用Beautiful Soup構建web Scraper
Scrapy
- Scrapy是用于大規模Web抓取的Python框架,它為你提供了從網站中高效提取資料,根據需要進行處理并以你喜歡的結構和格式存盤資料所需的所有工具,你可以在這里閱讀更多有關Scrapy的資訊,
- https://www.analyticsvidhya.com/blog/2017/07/web-scraping-in-python-using-scrapy
Selenium
- Selenium是另一個使瀏覽器自動化的流行工具,它主要用于行業中的測驗,但也非常方便進行網頁抓取,看看這篇很棒的文章,以了解更多有關使用Selenium進行Web抓取的作業方式的資訊,
- https://www.analyticsvidhya.com/blog/2019/05/scraping-classifying-youtube-video-data-python-selenium
Web爬網的組件
這是構成網頁抓取的三個主要組成部分的出色說明:

讓我們詳細了解這些組件,我們將通過goibibo網站抓取酒店的詳細資訊,例如酒店名稱和每間客房的價格,以實作此目的:
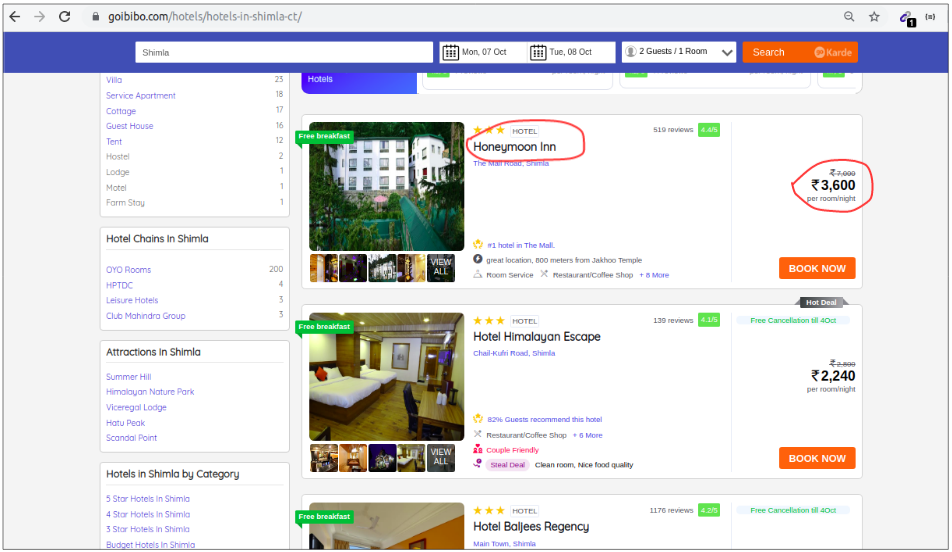
注意:請始終遵循目標網站的robots.txt檔案,該檔案也稱為漫游器排除協議,這可以告訴網路漫游器不要抓取哪些頁面,
- https://www.goibibo.com/robots.txt
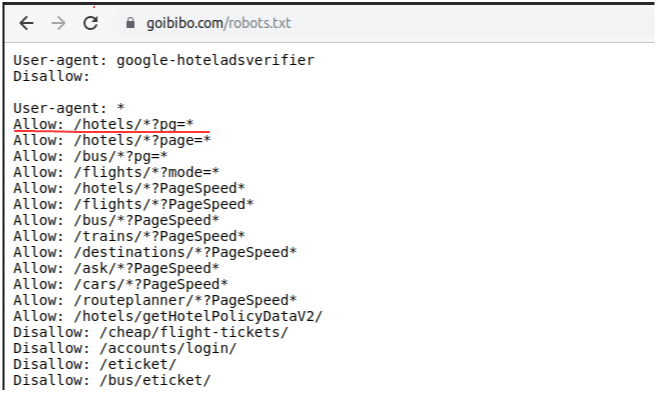
因此,我們被允許從目標URL中抓取資料,我們很高興去寫我們的網路機器人的腳本,讓我們開始!
第1步:Crawl(抓取)
Web抓取的第一步是導航到目標網站并下載網頁的源代碼,我們將使用請求庫來執行此操作,http.client和urlib2是另外兩個用于發出請求和下載源代碼的庫,
- http.client:https://docs.python.org/3/library/http.client.html#module-http.client
- urlib2:https://docs.python.org/2/library/urllib2.html
下載了網頁的源代碼后,我們需要過濾所需的內容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels/hotels-in-shimla-ct/"
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = https://www.cnblogs.com/panchuangai/p/BeautifulSoup(response.text,'html.parser')
print(data)
步驟2:Parse and Transform(決議和轉換)
Web抓取的下一步是將這些資料決議為HTML決議器,為此,我們將使用BeautifulSoup庫,現在,如果你已經注意到我們的目標網頁,則與大多數網頁一樣,特定酒店的詳細資訊也位于不同的卡片上,
因此,下一步將是從完整的源代碼中過濾卡片資料,接下來,我們將選擇該卡片,然后單擊“Inspect Element”選項以獲取該特定卡的源代碼,你將獲得如下內容:
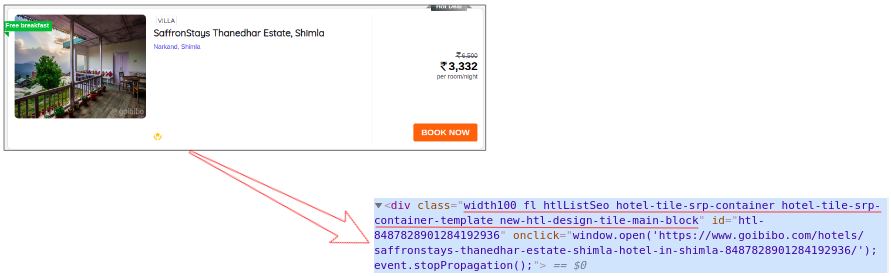
所有卡的類名都相同,我們可以通過傳遞標簽名稱和屬性(如
# find all the sections with specifiedd class name
cards_data = https://www.cnblogs.com/panchuangai/p/data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
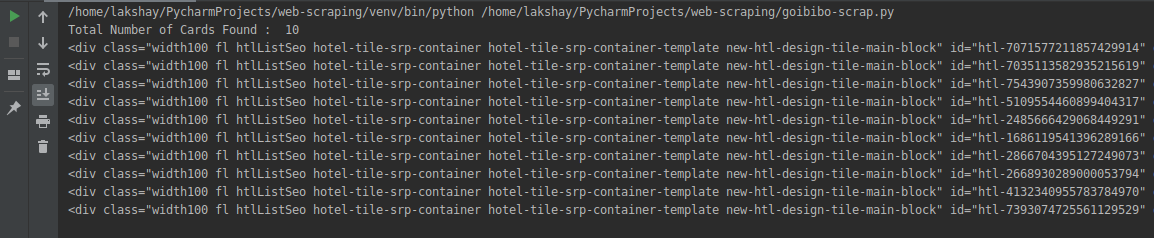
我們從網頁的完整源代碼中過濾出了卡資料,此處的每張卡都包含有關單獨酒店的資訊,僅選擇酒店名稱,執行“Inspect Element”步驟,并對房間價格執行相同操作:
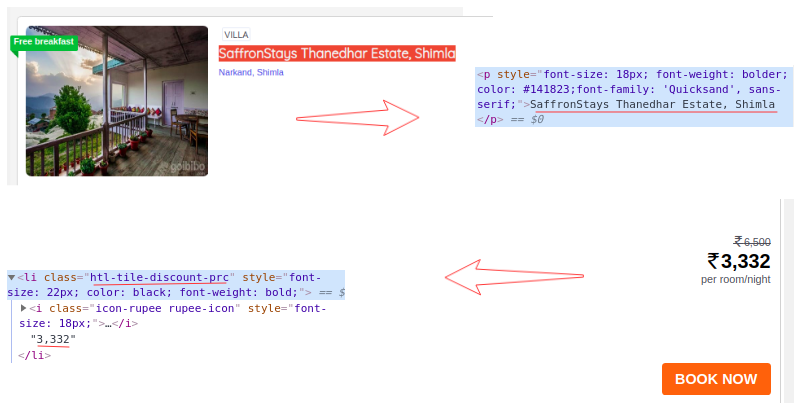
現在,對于每張卡,我們必須找到上面的酒店名稱,這些名稱只能從
標簽中提取,這是因為每張卡和房價只有一個 < p > 標簽和 < class > 標簽和類名:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
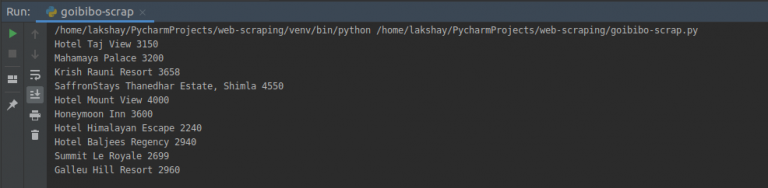
步驟3:Store(儲存資料)
最后一步是將提取的資料存盤在CSV檔案中,在這里,對于每張卡,我們將提取酒店名稱和價格并將其存盤在Python字典中,然后,我們最終將其添加到串列中,
接下來,讓我們繼續將此串列轉換為Pandas資料框,因為它允許我們將資料框轉換為CSV或JSON檔案:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
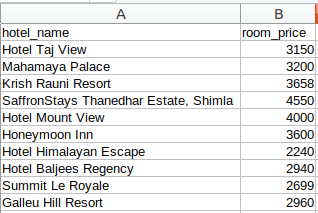
恭喜!我們已經成功創建了一個基本的網頁抓取工具,我希望你嘗試這些步驟,并嘗試獲取更多資料,例如酒店的等級和地址,現在,讓我們看看如何執行一些常見任務,例如在頁面加載時抓取URL,電子郵件ID,影像和抓取資料,
從網頁中抓取URL和電子郵件ID
我們嘗試使用網路抓取功能抓取的兩個最常見的功能是網站URL和電子郵件ID,我敢肯定你曾經參與過需要大量提取電子郵件ID的專案或挑戰,因此,讓我們看看如何在Python中抓取這些內容,
使用Web瀏覽器的控制臺
假設我們要跟蹤我們的Instagram關注者,并想知道取消關注我們帳戶的人的用戶名,首先,登錄到你的Instagram帳戶,然后單擊關注者以查看串列:
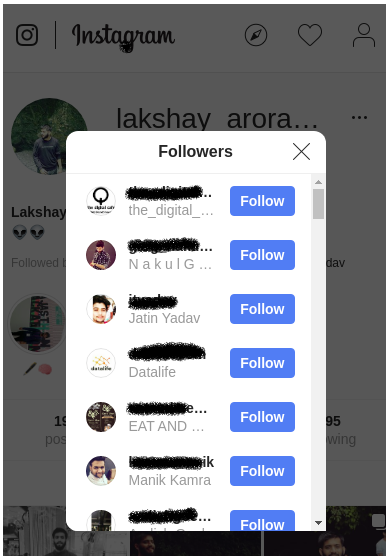
-
一直向下滾動,以便將所有用戶名都加載到瀏覽器記憶體中的后臺
-
右鍵單擊瀏覽器視窗,然后單擊“檢查元素”
-
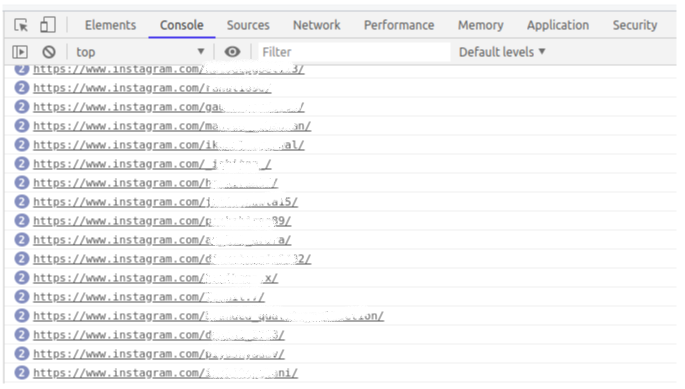
在控制臺視窗中,鍵入以下命令:
urls = $$(‘a’); for (url in urls) console.log ( urls[url].href);

僅需一行代碼,我們就可以找到該特定頁面上存在的所有URL:
-
接下來,將此串列保存在兩個不同的時間戳中,一個簡單的Python程式將使你知道兩者之間的區別,我們將能夠知道取消了我們的帳戶的用戶名!
-
我們可以使用多種方法來簡化此任務,主要思想是,只需一行代碼,我們就可以一次性獲得所有URL,
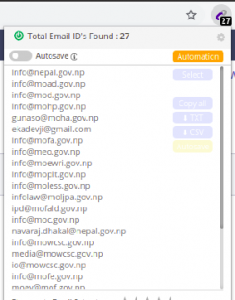
使用Chrome擴展程式電子郵件提取器
電子郵件提取器是一個Chrome插件,可捕獲我們當前正在瀏覽的頁面上顯示的電子郵件ID
它甚至允許我們下載CSV或文本檔案中的電子郵件ID串列:
BeautifulSoup和正則運算式
僅當我們只想從一頁抓取資料時,以上解決方案才有效,但是,如果我們希望對多個網頁執行相同的步驟怎么辦?
有許多網站可以通過收費為我們做到這一點,但這里有個好訊息——我們還可以使用Python撰寫自己的Web爬蟲!讓我們在下面的實時編碼視窗中查看操作方法,
- https://id.analyticsvidhya.com/auth/login/?next=https://www.analyticsvidhya.com/blog/2019/10/web-scraping-hands-on-introduction-python
在Python中爬取圖片
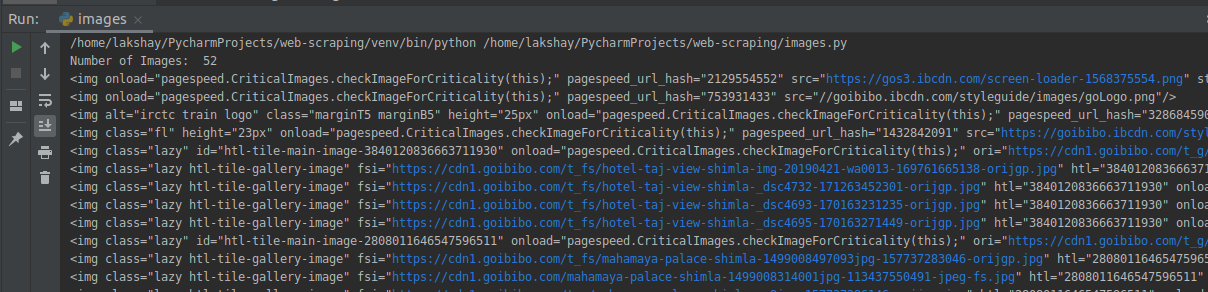
在本節中,我們將從同一個Goibibibo網頁抓取所有圖片,第一步是導航到目標網站并下載源代碼,接下來,我們將使用 < img > 標簽查找所有影像:
"""
Web Scraping - Scrap Images
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
# target URL
url = "https://www.goibibo.com/hotels/hotels-in-shimla-ct/"
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
response = requests.request("GET", url, headers=headers)
data = https://www.cnblogs.com/panchuangai/p/BeautifulSoup(response.text,'html.parser')
# find all with the image tag
images = data.find_all('img', src=https://www.cnblogs.com/panchuangai/p/True)
print('Number of Images: ', len(images))
for image in images:
print(image)
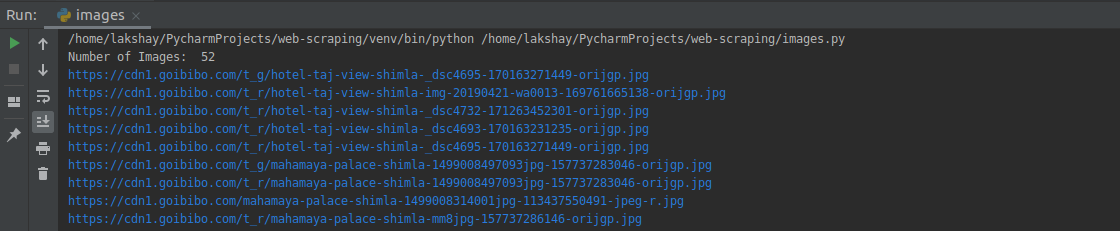
從所有影像標簽中,僅選擇src部分,另外,請注意,酒店圖片以jpg格式提供,因此,我們將僅選擇那些:
# select src tag
image_src = https://www.cnblogs.com/panchuangai/p/[x['src'] for x in images]
# select only jp format images
image_src = https://www.cnblogs.com/panchuangai/p/[x for x in image_src if x.endswith('.jpg')]
for image in image_src:
print(image)
現在我們有了影像URL的串列,我們要做的就是請求影像內容并將其寫入檔案中,確保打開檔案“ wb”(寫二進制檔案)形式
image_count = 1
for image in image_src:
with open('image_'+str(image_count)+'.jpg', 'wb') as f:
res = requests.get(image)
f.write(res.content)
image_count = image_count+1

你還可以按頁碼更新初始頁面URL,并反復請求它們以收集大量資料,
在頁面加載時抓取資料
讓我們看一下Steam社區Grant Theft Auto V Reviews的網頁,你會注意到網頁的完整內容不會一口氣加載,
- https://steamcommunity.com/app/271590/reviews/?browsefilter=toprated&snr=1_5_100010_
我們需要向下滾動以在網頁上加載更多內容,這是網站后端開發人員使用的一種稱為“延遲加載”的優化技術,
但是對我們來說,問題是,當我們嘗試從該頁面抓取資料時,我們只會得到該頁面的有限內容:
一些網站還創建了“加載更多”按鈕,而不是無休止的滾動想法,僅當你單擊該按鈕時,它將加載更多內容,內容有限的問題仍然存在,因此,讓我們看看如何抓取這些網頁,
導航到目標URL并打開“檢查元素網路”視窗,接下來,點擊重新加載按鈕,它將為你記錄網路,如影像加載,API請求,POST請求等的順序,
清除當前記錄并向下滾動,你會注意到,向下滾動時,該網頁正在發送更多資料的請求:
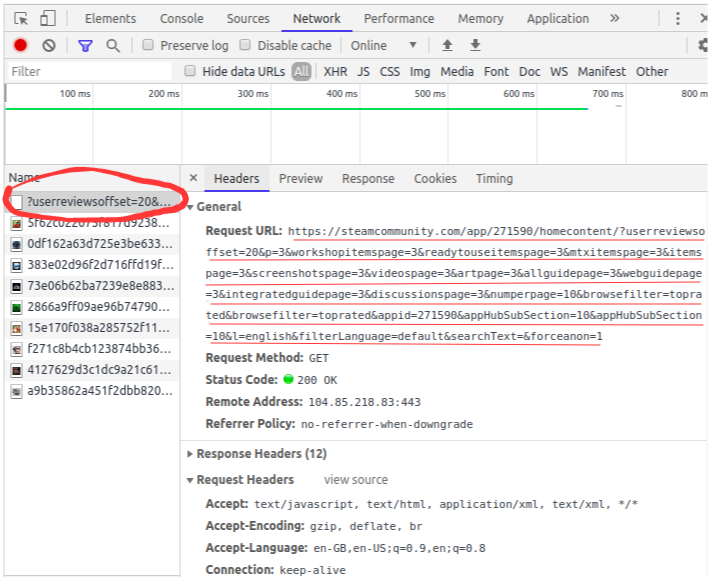
進一步滾動,你將看到網站發出請求的方式,查看以下URL——僅某些引數值正在更改,你可以通過簡單的Python代碼輕松生成這些URL:

你需要按照相同的步驟來抓取和存盤資料,方法是將請求一頁一頁地發送到每個頁面,
尾注
這是使用功能強大的BeautifulSoup庫對Python中的網路抓取進行的簡單且對初學者友好的介紹,老實說,當我正在尋找一個新專案或需要一個現有專案的資訊時,我發現網路抓取非常有用,
注意:如果你想以更結構化的形式學習本教程,我們有一個免費課程,我們將教授網路抓取BeatifulSoup,你可以在此處查看—— 使用Python進行Web爬網簡介,
- https://courses.analyticsvidhya.com/courses/introduction-to-web-scraping
如前所述,還有其他一些庫可用于執行Web抓取,我很想聽聽你更喜歡的庫的想法(即使你使用R語言!),以及你對該主題的經驗,在下面的評論部分中告訴我,我們將與你聯系!
原文鏈接:https://www.analyticsvidhya.com/blog/2019/10/web-scraping-hands-on-introduction-python/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/143258.html
標籤:其他
上一篇:手賤洗掉usb驅動,該如何恢復