前言:本篇爬蟲只做經驗交流,不可用于其他用途,如果轉載,請著名出處和鏈接即可
希望: 喜歡博主的小伙伴,希望點個關注哦~,更多爬蟲專案請收藏本欄目,不定期添加干貨
注意: 因為抖音那邊更新版本的速度還挺快,不能保證這個博文一直能用,但是爬蟲思想不會變,只要學會了思想,無論怎么變,相信你都能解決的
目錄
一、抖音視頻分析
二、分析復制的短鏈接
三、分析回傳的資料
四、下載原始碼
五、運行結果:
一、抖音視頻分析
①、打開抖音app,搜索想要爬取視頻的抖音音樂人
②、找到主頁右上角三個點
③、點擊其中的分享
④、選擇其中的復制鏈接
二、分析復制的短鏈接
①瀏覽器打開復制的鏈接
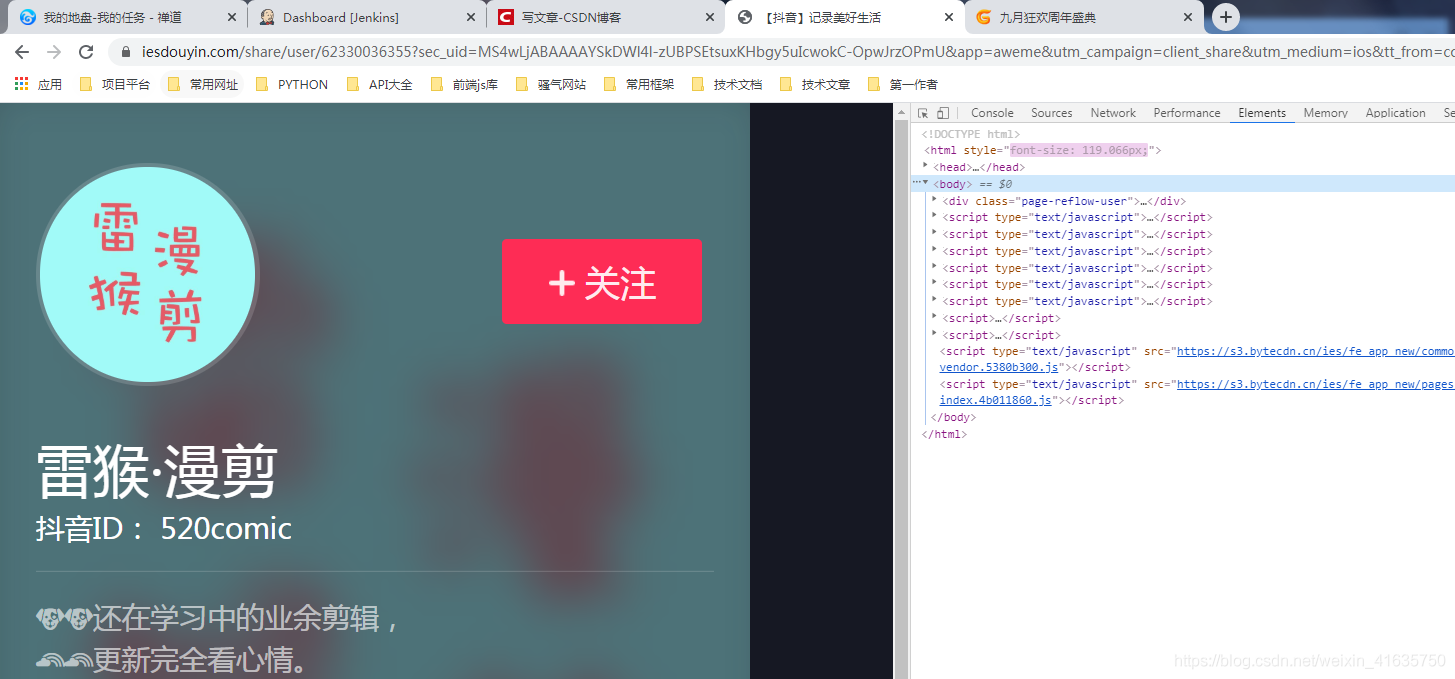
- 發現短連接被還原成了原始鏈接
- 暫時我們不知道需要下載視頻需要的是什么引數,后期通過分析知道只需要sec_uid這個引數即可
- pc端打開會出現樣式問題,我們選擇移動端打開,模擬手機環境
- 因此,爬蟲也需要模擬移動端環境進行請求
②、使用移動端打開
③、瀏覽器抓包
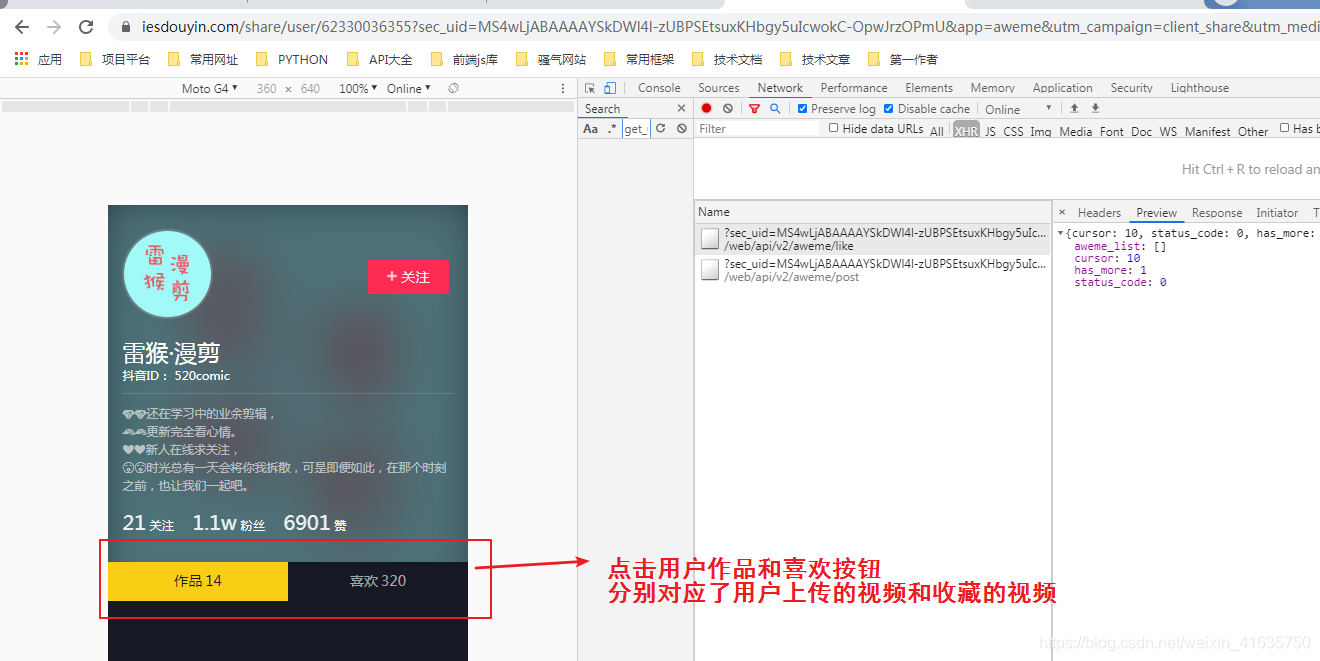
- 點擊作品和喜歡,可以抓包到請求的鏈接,這個我們稍后分析
- 因為現在抖音app有隱藏自己收藏的功能,所以如果用戶設定了隱藏,你將無法下載用戶收藏的視頻哦
④、分析請求鏈接
- 通過抓包我們知道
- 用戶上傳的資料鏈接為:https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAYSkDWl4l-zUBPSEtsuxKHbgy5uIcwokC-OpwJrzOPmU&count=21&max_cursor=0&aid=1128&_signature=Bth1lgAAWa-w6IbGQlE-1gbYdY&dytk=
- 用戶收藏的資料鏈接為:https://www.iesdouyin.com/web/api/v2/aweme/like/?sec_uid=MS4wLjABAAAAYSkDWl4l-zUBPSEtsuxKHbgy5uIcwokC-OpwJrzOPmU&count=21&max_cursor=0&aid=1128&_signature=Bth1lgAAWa-w6IbGQlE-1gbYdY&dytk=
- 請求結果如下,因抖音的檢測機制,你需要刷很多次才有資料,這個我們通過回圈判斷aweme_list中是否有資料即可
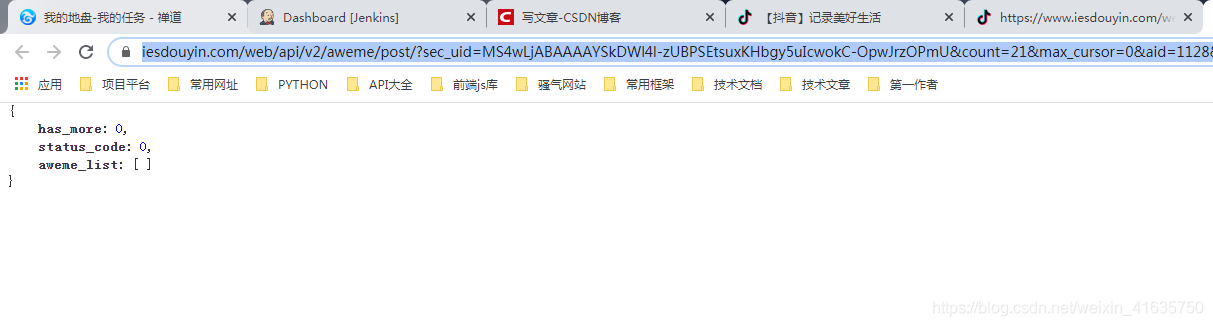
- 多次重繪后的結果如下
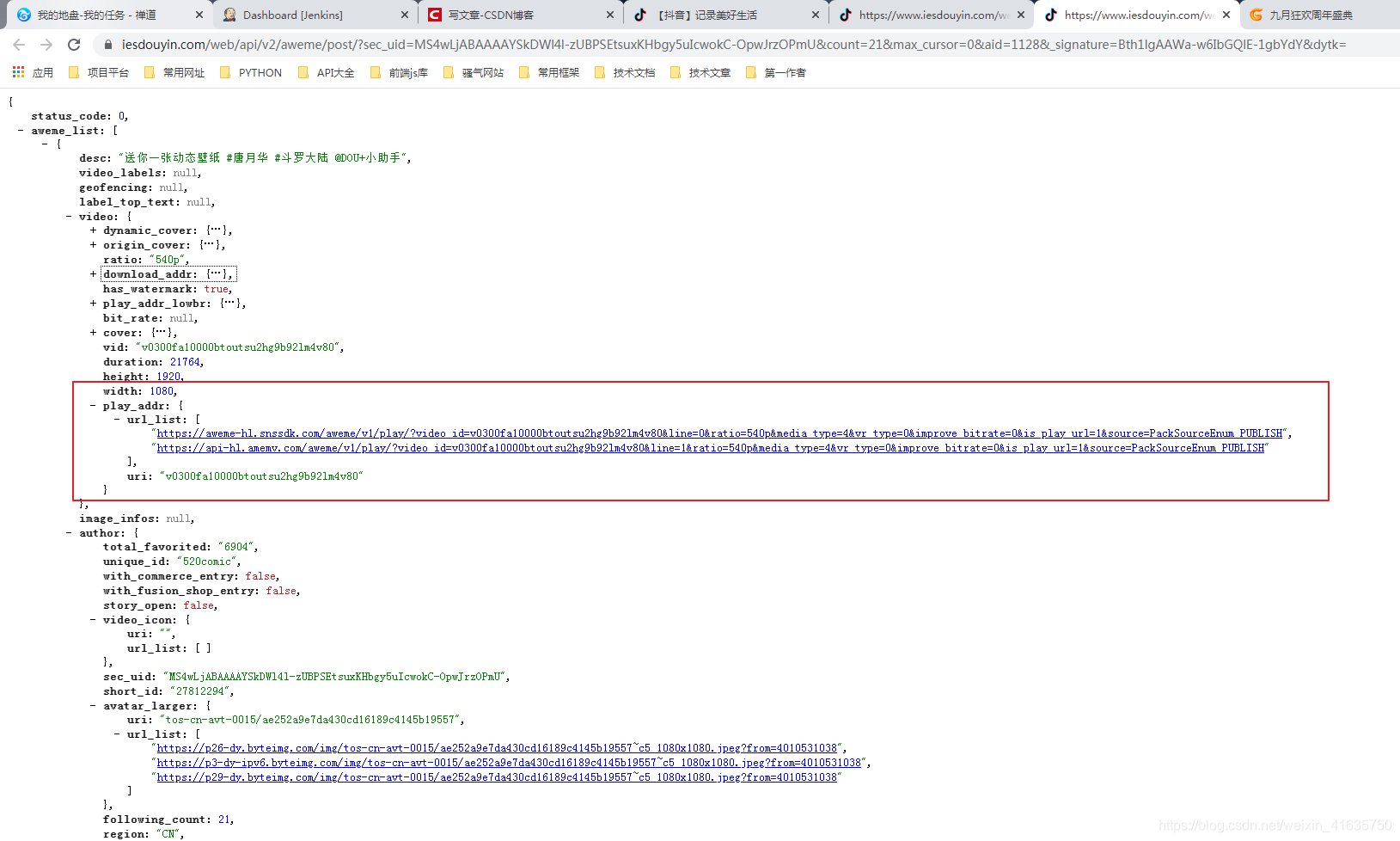
三、分析回傳的資料
①看整體資料,將陣列折疊先
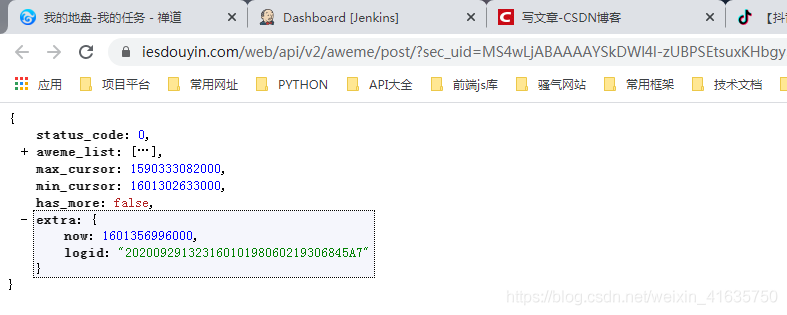
- status_code: 不用說,肯定是回傳狀態
- aweme_list: 存放視頻資訊的陣列,等會具體分析
- max_cursor/min_cursor: 這個盲猜都知道用來分頁的指標,如果是多頁,且請求的不是第一頁,需要傳其中的某個值,這個暫時不討論
- has_more: 是否有多頁
- extra: 額外的資訊,當前請求的毫秒級時間戳,以及logid,這個不重要,抖音那邊用來日志記錄的
②、分析視頻資訊
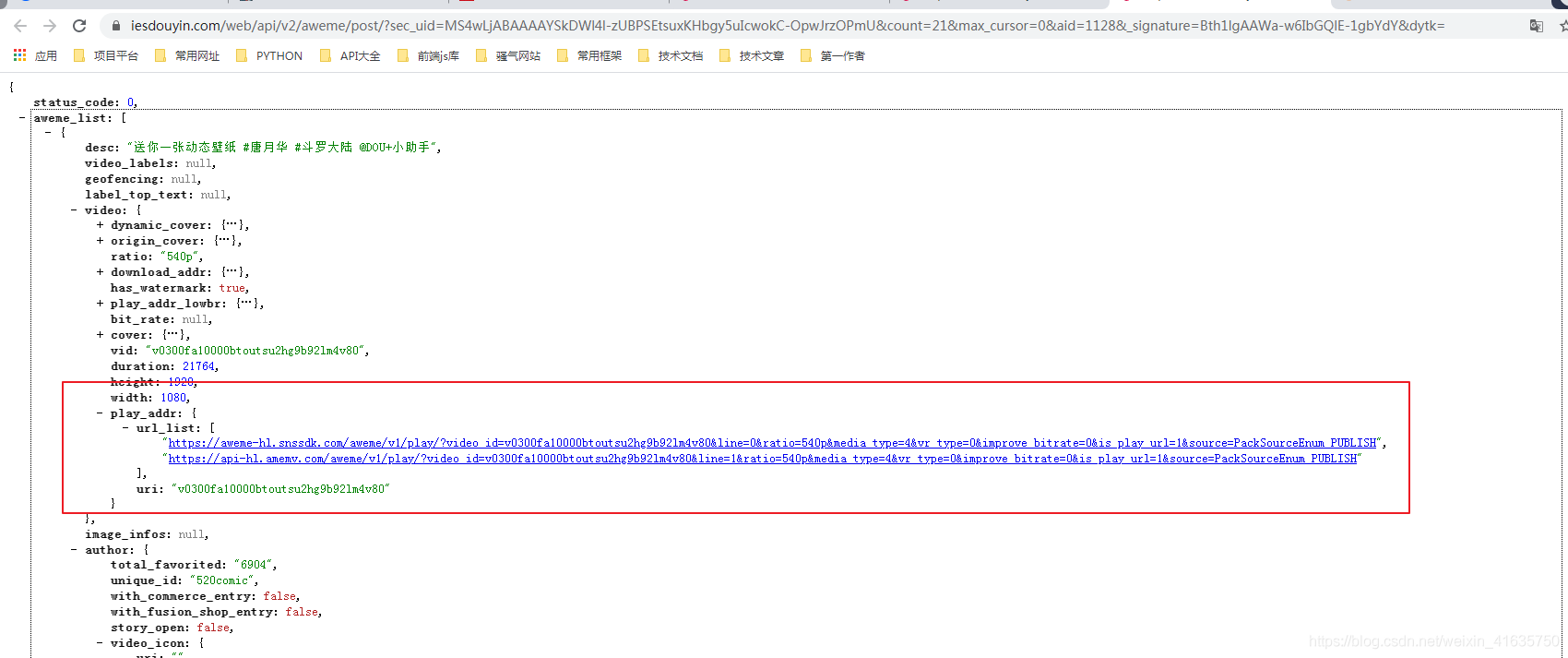
- 可以看出每個視頻有兩個鏈接,自己訪問一下就知道,一個鏈接是用戶上傳的原視頻,另一個是抖音那邊加了水印的視頻
- 其實到這里大家都知道無水印視頻如何下載了,不必贅述了
四、下載原始碼
- 其實通過分析,抖音下載只需要拿到sec_uid這個引數即可
- 瀏覽器打開分享的短連接,就能看到地址欄這個引數
#!/usr/bin/env python
# encoding: utf-8
'''
#-------------------------------------------------------------------
# CONFIDENTIAL --- CUSTOM STUDIOS
#-------------------------------------------------------------------
#
# @Project Name : 抖音下載小助手
#
# @File Name : main.py
#
# @Programmer : Felix
#
# @Start Date : 2020/7/30 14:42
#
# @Last Update : 2020/7/30 14:42
#
#-------------------------------------------------------------------
'''
import os, sys, requests
import json, re, time
from retrying import retry
from contextlib import closing
class DouYin:
'''
This is a main Class, the file contains all documents.
One document contains paragraphs that have several sentences
It loads the original file and converts the original file to new content
Then the new content will be saved by this class
'''
def __init__(self):
'''
Initial the custom file by some url
'''
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
}
def hello(self):
'''
This is welcome speech
:return: self
'''
print("*" * 50)
print(' ' * 15 + '抖音下載小助手')
print(' ' * 5 + '作者: Felix Date: 2020-05-20 13:14')
print(' ' * 15 + '無水印 | 有水印')
print(' ' * 12 + '輸入用戶的sec_uid即可')
print(' ' * 2 + '用瀏覽器打開用戶分享鏈接,復制引數中sec_uid')
print("*" * 50)
return self
def get_video_urls(self, sec_uid, type_flag='p'):
'''
Get the video link of user
:param type_flag: the type of video
:return: nickname, video_list
'''
user_url_prefix = 'https://www.iesdouyin.com/web/api/v2/aweme/post' if type_flag == 'p' else 'https://www.iesdouyin.com/web/api/v2/aweme/like'
print('---決議視頻鏈接中...\r')
i = 0
result = []
while result == []:
i = i + 1
print('---正在第 {} 次嘗試...\r'.format(str(i)))
user_url = user_url_prefix + '/?sec_uid=%s&count=2000' % (sec_uid)
response = self.get_request(user_url)
html = json.loads(response.content.decode())
if html['aweme_list'] != []:
result = html['aweme_list']
nickname = None
video_list = []
for item in result:
if nickname is None:
nickname = item['author']['nickname'] if re.sub(r'[\/:*?"<>|]', '', item['author']['nickname']) else None
video_list.append({
'desc': re.sub(r'[\/:*?"<>|]', '', item['desc']) if item['desc'] else '無標題' + str(int(time.time())),
'url': item['video']['play_addr']['url_list'][0]
})
return nickname, video_list
def get_download_url(self, video_url, watermark_flag):
'''
Whether to download watermarked videos
:param video_url: the url of video
:param watermark_flag: the type of video
:return: the url of o
'''
if watermark_flag == True:
download_url = video_url.replace('api.amemv.com', 'aweme.snssdk.com')
else:
download_url = video_url.replace('aweme.snssdk.com', 'api.amemv.com')
return download_url
def video_downloader(self, video_url, video_name, watermark_flag=False):
'''
Download the video
:param video_url: the url of video
:param video_name: the name of video
:param watermark_flag: the flag of video
:return: None
'''
size = 0
video_url = self.get_download_url(video_url, watermark_flag=watermark_flag)
with closing(requests.get(video_url, headers=self.headers, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write('----[檔案大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))
with open(video_name + '.mp4', 'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write('----[下載進度]:%.2f%%' % float(size / content_size * 100) + '\r')
sys.stdout.flush()
@retry(stop_max_attempt_number=3)
def get_request(self, url, params=None):
'''
Send a get request
:param url: the url of request
:param params: the params of request
:return: the result of request
'''
if params is None:
params = {}
response = requests.get(url, params=params, headers=self.headers, timeout=10)
assert response.status_code == 200
return response
@retry(stop_max_attempt_number=3)
def post_request(self, url, data=None):
'''
Send a post request
:param url: the url of request
:param data: the params of request
:return: the result of request
'''
if data is None:
data = {}
response = requests.post(url, data=data, headers=self.headers, timeout=10)
assert response.status_code == 200
return response
def run(self):
'''
Program entry
'''
sec_uid = input('請輸入用戶sec_uid:')
sec_uid = sec_uid if sec_uid else 'MS4wLjABAAAAle_oORaZCgYlB84cLTKSqRFvDgGmgrJsS6n3TfwxonM'
watermark_flag = input('是否下載帶水印的視頻 (0-否(默認), 1-是):')
watermark_flag = bool(int(watermark_flag)) if watermark_flag else 0
type_flag = input('p-上傳的(默認), l-收藏的:')
type_flag = type_flag if type_flag else 'p'
save_dir = input('保存路徑 (默認"./Download/"):')
save_dir = save_dir if save_dir else "./Download/"
nickname, video_list = self.get_video_urls(sec_uid, type_flag)
nickname_dir = os.path.join(save_dir, nickname)
if not os.path.exists(nickname_dir):
os.makedirs(nickname_dir)
if type_flag == 'f':
if 'favorite' not in os.listdir(nickname_dir):
os.mkdir(os.path.join(nickname_dir, 'favorite'))
print('---視頻下載中: 共有%d個作品...\r' % len(video_list))
for num in range(len(video_list)):
print('---正在決議第%d個視頻鏈接 [%s] 中,請稍后...\n' % (num + 1, video_list[num]['desc']))
video_path = os.path.join(nickname_dir, video_list[num]['desc']) if type_flag != 'f' else os.path.join(nickname_dir, 'favorite', video_list[num]['desc'])
if os.path.isfile(video_path):
print('---視頻已存在...\r')
else:
self.video_downloader(video_list[num]['url'], video_path, watermark_flag)
print('\n')
print('---下載完成...\r')
if __name__ == "__main__":
DouYin().hello().run()五、運行結果:
- 其中重試的次數,就是在連續請求那個資料連接,直達list中有資料
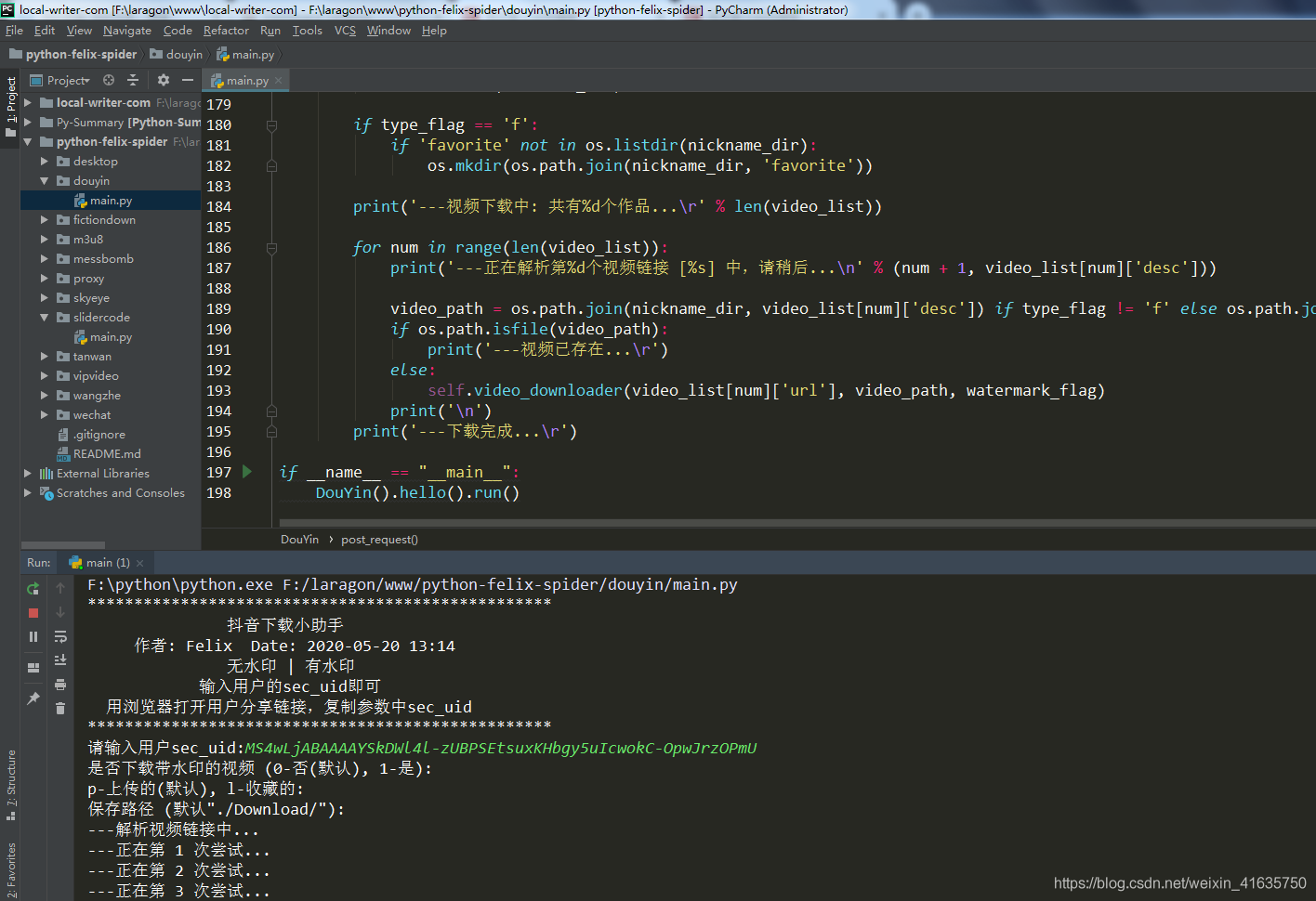
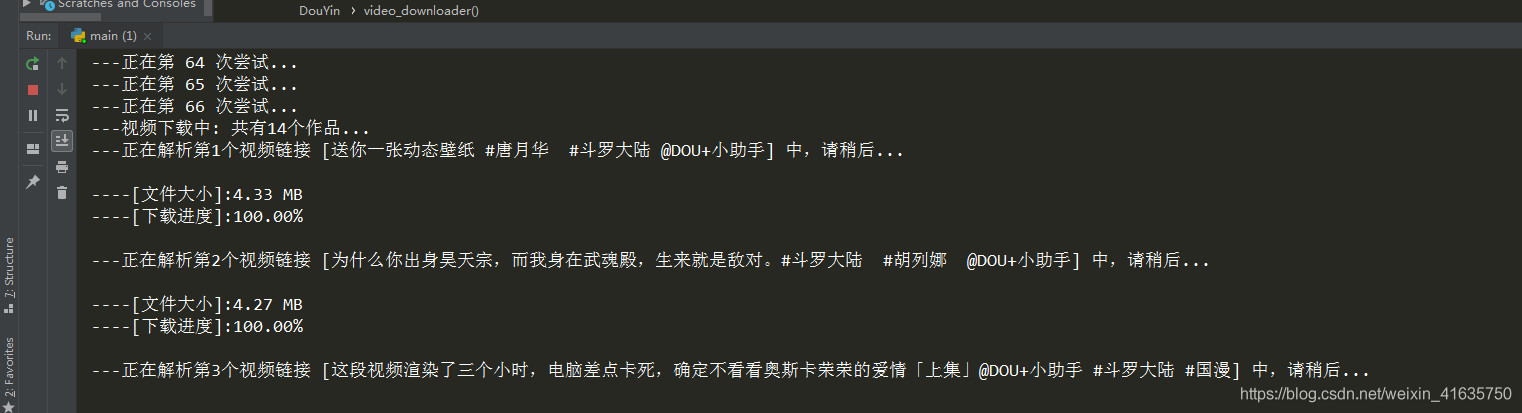
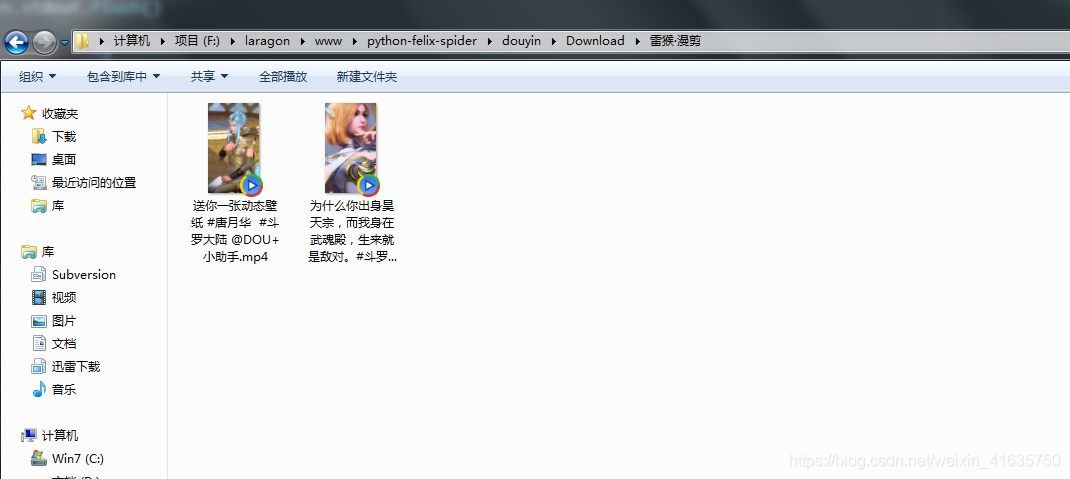
- 可以發現已經可以正常下載了
猜你喜歡:
「python爬蟲實戰」使用多行程教你下載M3U8加密或非加密視頻
「python爬蟲實戰」手把手教你從分析到實作,王者榮耀壁紙爬蟲
「python爬蟲實戰」超簡單爬取抖音無水印視頻,程式猿如果想火就是這么簡單
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/143551.html
標籤:AI