著作權申明:本文為博主窗戶(Colin Cai)原創,歡迎轉帖,如要轉貼,必須注明原文網址 http://www.cnblogs.com/Colin-Cai/p/13499260.html 作者:窗戶 QQ/微信:6679072 E-mail:[email protected]
本系列文章是想思考思考遞回的編譯優化問題,目標在于希望如何從編譯、解釋層次將樹遞回進行優化,從而避免過低效率運行,本章來講講樹遞回的問題,
幾個遞回問題
先來看這樣一個知名數列Fibnacci數列,定義如下
$fib_{n} = \left\{\begin{matrix}
1, & n = 1,2\\
fib_{n-1}+fib_{n-2},& n>3
\end{matrix}\right.$
獲得數列第n項用程式寫如下,以下可以看成是偽碼,只是用Python寫出來,其實用什么語言寫出來對于本文章所述說內容來說沒太大關系:
def fib(n): if n < 3: return 1 return fib(n-1) + fib(n-2)
再來看另外一個問題,如下圖這樣的方格,從A走到B,每次往右走一步或每次往上走一步,問有多少走法,
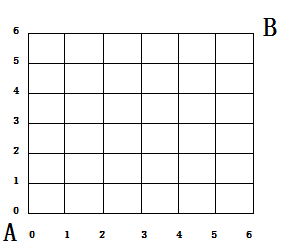
稍微加分析我們就可以知道,對于從(0,0)到坐標(x, y)的走法數量:
(1)如果在兩條坐標軸上,也就是x=0或者y=0,那么只有一種走法
(2)除此之外,任何一種走法走到(x,y)之前的上一步,則要么是走到了(x-1,y),要么是走到了(x,y-1),從而,這種情況下,走到(x,y)的走法數量應該是走到(x-1,y)的走法數量和走到(x,y-1)的走法數量之和,
用程式來表達,應該是
def ways(x, y): if x==0 or y==0: return 1 else: return ways(x-1, y) + ways(x, y-1)
再看一個問題,可以稱之為零錢問題,假如有1分、2分、5分、10分、20分、50分、100分、200分、500分、1000分這幾種面值各不相同的貨幣,組成1000分一共有多少種方法,
這個問題一眼看上去可能會覺得毫無頭緒,但依然存在樹遞回的方法,我們把原問題看成是changes(total, notes),total為希望組成的錢的數量,notes是各種貨幣面值組成的list,其遞回思路如下:
(1)如果total=0,則組成方法當然只有一種,
(2)如果total<0,則組成方法一種都沒有,
(3)如果total≥0且notes里面一種貨幣都沒有,則組成方法也是一種都沒有,
(4)其他情況下,從notes中拿出一種貨幣,那么所有的組成方法包含兩類,一類包含剛才這種貨幣,一類不包含剛才這種貨幣,兩類情況交集為空,
用程式來實作這個遞回如下:
def changes(total, notes): if total == 0: return 1 if total < 0: return 0 if len(notes) == 0: return 0 return changes(total-notes[0], notes) \ + changes(total, notes[1:])
原問題則可以靠changes(1000, [1,2,5,10,20,50,100,200,500,1000])這樣去求值了,其中第二個list的順序并不重要,
遞回的效率
實際上,上述的三個Python代碼執行以下三個函式呼叫
fib(100)
ways(100, 100)
changes(1000, [1,2,5,10,20,50,100,200,500,1000])
就可以看出問題,因為這三個函式呼叫似乎結束不了,最后一個可能需要修改一下堆疊大小,
一個純計算的函式的執行卡死,可能是執行運算量過大了,
我們這里只考慮一下fib函式,其他兩個類比,
實際上,我們單修改一下,添加一個計數cnt來記錄fib被呼叫的次數,用來估算時間復雜度,
cnt = 0 def fib(n): global cnt cnt += 1 if n < 3: return 1 return fib(n-1) + fib(n-2)
我們計算一下fib(10),得到55
列印cnt,得到109,
實際上,cnt顯然是以下這樣一個數列
$cnt_{n} = \left\{\begin{matrix}
1, & n = 1,2\\
cnt_{n-1}+cnt_{n-2}+1,& n>3
\end{matrix}\right.$
很容易用數學歸納法證明
$cnt_{n}=fib_{n}*2-1$
而fib是指數級的數列,所以這個樹遞回的計算fib(n)也是n的指數級的計算量,這個當然就可怕了,其他兩個也一樣是類似的計算量,從而短時間計算不出來是很正常的,
遞回為什么如此慢
為什么這些遞回會如此的慢呢?這是一個值得思考的問題,也是提升其效率的入手點,
我們還是從Fibnacci數列開始研究起,我們剛才知道了函式會被呼叫很多次,于是我們就想,每次呼叫函式的時候,引數都是什么,修改一下:
def fib(n): print('Call fib, arg:', n) if n < 3: return 1 return fib(n-1) + fib(n-2)
我們執行一下fib(6),得到下面的列印結果:
Call fib, arg: 6
Call fib, arg: 5
Call fib, arg: 4
Call fib, arg: 3
Call fib, arg: 2
Call fib, arg: 1
Call fib, arg: 2
Call fib, arg: 3
Call fib, arg: 2
Call fib, arg: 1
Call fib, arg: 4
Call fib, arg: 3
Call fib, arg: 2
Call fib, arg: 1
Call fib, arg: 2
我們觀察可以發現,一樣引數的fib呼叫總是頻繁發生,我們排除fib(1)、fib(2)這種可以直接得到結果的呼叫,fib(4)被呼叫了2次,fib(3)被呼叫了3次,然而,顯然這個函式不包含任何的副作用,也就是函式本身的運算不會影響任何全域變數,所使用的運算部件也不帶有任何的隨機成分等,那么也就是,這樣的函式是數學意義上的函式,所謂“純函式”,從而相同的引數會計算出相同的值,
比如fib(100),以下是計算中的遞回依賴
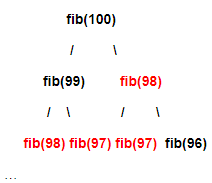
紅色的部分都是重復計算,大量的重復計算導致了計算效率過低,同樣的事情也發生在ways和changes兩個函式上,

如何避免重復
我們可以在黑板上依次根據規則一項項的寫出Fibnacci數列各項,
1 1 2 3 5 8 13 21 34 55 89 144 ...
可以預計,一個小時差不多可以寫出第100項,于是人比計算機快?
其實,還是在于人沒有重復計算,當然人在這里采用了一個更好的迭代演算法也是一個原因,
于是,我們可以想到,之前我們已經分析這些函式都是數學意義下的函式,如果建立一個cache,記錄下函式得到的值,每次計算函式,當可能出現遞回的時候,都先去查一下cache,如果cache中有,則取出回傳,如果沒有則遞回計算,
fib函式可以按照以上想法改寫為這樣,
cache = {} def fib(n): if n < 3: return 1 if n in cache: return cache[n] else: r = fib(n-1) + fib(n-2) cache[n] = r return r
以此演算法來運算fib(100)發現可以瞬間得到354224848179261915075
依然以之前的方法記錄一下函式呼叫次數,
cache = {} cnt = 0 def fib(n): global cnt cnt += 1 if n < 3: return 1 if n in cache: return cache[n] else: r = fib(n-1) + fib(n-2) cache[n] = r return r
發現計算fib(100)之后,cnt只記錄到197,顯然cache避免了大量重復計算,從而很快,
編譯器判斷一個函式是數學函式從而沒有副作用其實并不難,只需要滿足如下:
(1)函式和全域變數不產生直接互動
(2)函式如果有使用到其他函式,這些外部函式也是數學函式,
(3)函式如果用到操作,所使用的操作不產生副作用,
實際上,可以把操作也看成函式,從而只有上述1、2兩條,然后這個cache也是一個k/v系統,此種優化可以在編譯器中直接做到,
甚至還可以考慮引入多任務,不過這是個比較麻煩的問題,另外,這種優化并不一定總是可以帶來更高的效率,如果沒有上述的大量復重復計算,這樣的優化反而會加大資料復雜度開銷,也加長運算時間,
我這里用階乘舉個例:
def factorial(n): if n == 1: return 1 return n * factorial(n-1)
以上遞回并沒有重復計算,添加cache如下:
cache = {} def factorial(n): if n == 1: return 1 if n in cache: print('Cache Hit') return cache[n] r = n * factorial(n-1) cache[n] = r return r
因為沒有重復計算,所以上面的Cache Hit永遠不可能列印,
試圖追求更高的效率
前面提到可以在黑板上一項一項寫出Fibnacci數列,用到的方法是迭代,用Python使用遞回形式來描述迭代如下:
def fib(n): def fib_iter(n, m, first, second): if n == m: return second return fib_iter(n, m+1, second, second+first) if n < 3: return 1 return fib_iter(n, 2, 1, 1)
而用回圈來描述迭代如下:
def fib(n): if n < 3: return 1 first = 1 second = 1 for i in range(3, n+1): first, second = second, second+first return second
雖說對于Fibnacci數列求第n項有更好(時間復雜度更低)的演算法,但是如果編譯器可以自動產生以上演算法,已經是可以滿意了,
我們思考用遞回計算Fibnacci數列中的一項fib(n)
以下符號,->左邊代表目標,->右邊::左邊代表依賴值,::右邊代表函式,
fib(n)->fib(n-1) ,fib(n-2)::λx y·x+y
而所依賴的兩個值分別是如下依賴,
fib(n-1)->fib(n-2),fib(n-3)::λx y·x+y
fib(n-2)->fib(n-3),fib(n-4)::λx y·x+y
從而
fib(n-1),fib(n-2)->fib(n-3),fib(n-4)::λx y·x+y+x, λx y·x+y
于是我們反復來就可以有以下的依賴
fib(n)->fib(n-1) ,fib(n-2)::λx y·x+y
fib(n-1),fib(n-2)->fib(n-3),fib(n-4)::λx y·x+y+x, λx y·x+y
fib(n-3),fib(n-4)->fib(n-5),fib(n-6)::λx y·x+y+x, λx y·x+y
...
于是我們的依賴
fib(n)->fib(n-1),fib(n-2)->fib(n-3),fib(n-4)->fib(n-5,n-6)...
反過來
f(1),f(2)=>f(3),f(4)=>f(5),f(6)....f(n)
于是我們就有了一個O(1)空間的迭代,然而問題在于,我們怎么知道反過來可以從f(1),f(2)開始推呢?
而考慮第二個問題ways遞回,問題則變得麻煩了許多,
ways(a,b)->ways(a-1,b),ways(a,b-1)::λx y·x+y
而
ways(a-1,b)->ways(a-2,b),ways(a-1,b-1)::λx y·x+y
ways(a,b-1)->ways(a-1,b-1),ways(a,b-2)::λx y·x+y
從而
ways(a-1,b),ways(a,b-1)->ways(a-2,b),ways(a-1,b-1),ways(a,b-2)::λx y z·x+y,λx y z·y+z
....
于是我們通過觀察,可以反過來這樣去推:
f(1,1)=>f(2,1),f(1,2)=>f(3,1),f(2,2),f(3,3)=>....
其中省略所有的遞回邊界條件,比如
f(2,1) = f(1,1)+f(2,0) = f(1,1)+1
于是,這幾乎成了一個人腦才能理解的問題,很難有固定的演算法可以將樹遞回轉換為迭代,不過得到一種人腦似乎可以通過樹遞回尋找迭代的方法,也算不錯,
當然,編譯器大多數優化方法還是使用粒度更細的模板式尋找和替換,沒有通式的優化,可以采用模板式的匹配,替換,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/144286.html
標籤:其他