目錄
- 面向資料編程是什么?
- 單指令流多資料流(SIMD)
- 什么是SIMD
- 為什么需要SIMD
- 支持SIMD技術的指令集
- 使用SIMD編程
- 使用匯編行內
- 使用指令集庫
- 使用ISPC語言
- 并行回圈
- 避免Gather行為
- CPU快取(CPU cache)
- 什么是CPU快取
- 為什么需要CPU快取
- CPU快取預先存的是什么
- CPU快取命中/未命中
- 提高CPU快取命中率
- 使用連續陣列存盤要批處理的物件
- 避免無效資料夾雜在連續記憶體區域
- 冷資料/熱資料分割
- 頻繁呼叫的函式盡可能不要做成虛函式
- 重新認識C++ STL容器
- 更多小細節(不常用)
- 總結
- 參考
隨著軟體需求的日益復雜發展,遠古時期面的向程序編程思想才漸漸萌生了面向物件編程思想,
當人們發現面向物件在應對高層軟體的種種好處時,越來越沉醉于面向物件,熱衷于研究如何更加優雅地抽象出物件,
然而現代開發中漸漸發現面向物件編程層層抽象造成臃腫,導致運行效率降低,而這是性能要求高的游戲編程領域不想看到的,
于是現代游戲編程中,面向資料編程的思想越來越被接受(例如Unity2018更新的ECS框架就是一種面向資料思想的框架),
面向資料編程是什么?
先來一個簡單的比較:
面向程序:建立解決問題所需的各個步驟(函式),
面向物件:建立解決問題所需的各個模型(類),
面向資料:考慮資料的存取及布局(資料),
值得一說的是,面向程序和面向物件都是解決問題的一種方法,而面向資料只是一種優化的設計思想,而非解決問題的方法,
那么所謂的考慮資料存盤/布局是什么意思呢?
這里引入2個有關CPU處理資料的概念:
-
單指令流多資料流(SIMD)
-
CPU快取(CPU Cache)
單指令流多資料流(SIMD)
什么是SIMD

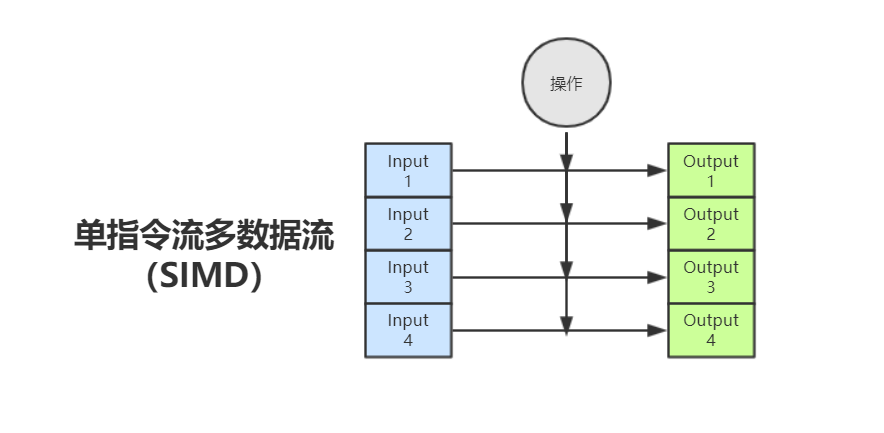
SIMD全稱Single Instruction Multiple Data,單指令流多資料流,是一種采用一個控制器來控制多個處理器,同時對若干個資料分別執行相同的操作從而實作空間上的并行性的技術,
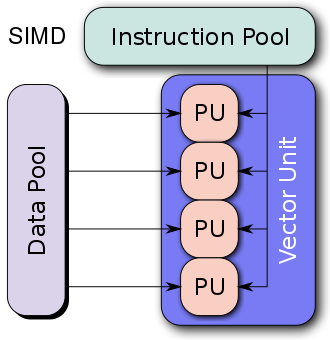
簡單來說,SIMD技術可以讓CPU在一個指令周期執行多個資料的操作(不過操作需要一樣),而不是一個指令周期執行一個資料的操作,
為什么需要SIMD
在上面的介紹里,我們可以直觀的知道最大的好處在于:可以允許CPU利用并行性快速處理多個資料,
但是局限性還是有的,SIMD技術一般對矢量算術型操作(例如矢量相加,矢量相乘)支持的很好,而不支持其他型別操作(例如分支判斷和跳轉),
所以SIMD技術常用于CPU資料計算密集型應用,例如:
- 人工智能
- 物理計算
- 粒子系統
- 光線追蹤
- 影像處理
支持SIMD技術的指令集
X86架構的CPU所支持SSE/SSE2/SSE3指令集就是典型的重點針對/支持SIMD功能的指令集,
目前的PC的CPU架構絕大多數都是Intel的X86架構,而ARM架構的CPU可以在很多消費性電子產品上看到,從可攜式裝置(PDA、移動電話、多媒體播放器、掌上型電子游戲,和計算機)到電腦外設(硬碟、桌上型路由器)甚至在導彈的彈載計算機等軍用設施中都有它的存在,
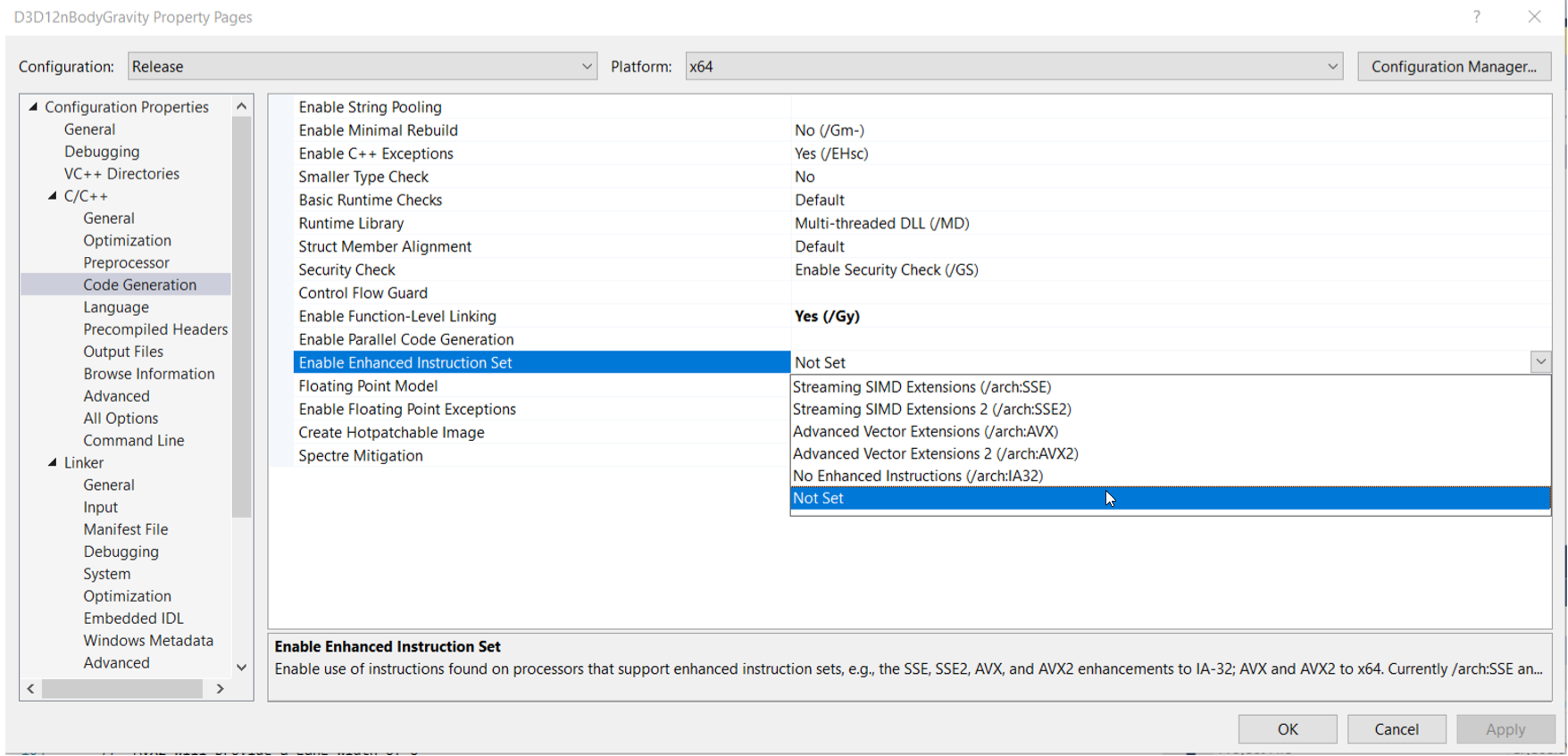
(vs2019里專案設定可以找到指令集設定選項)
我們可以在IDE/編譯器里設定好支持SIMD技術的指令集選項,
使用SIMD編程
使用匯編行內
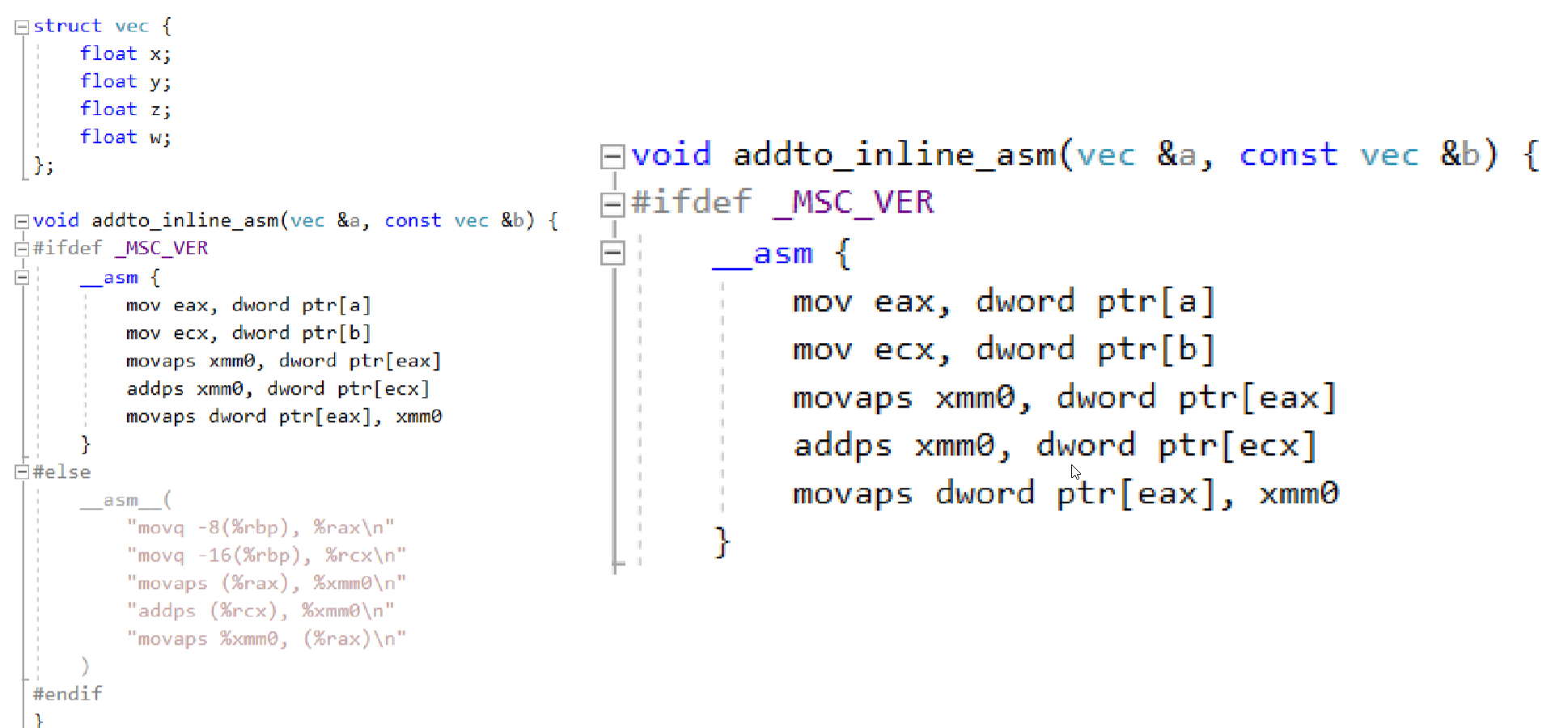
缺陷:
- 匯編代碼需根據不同平臺定制(無跨平臺特性)
- 匯編代碼復雜,開發效率低
使用指令集庫
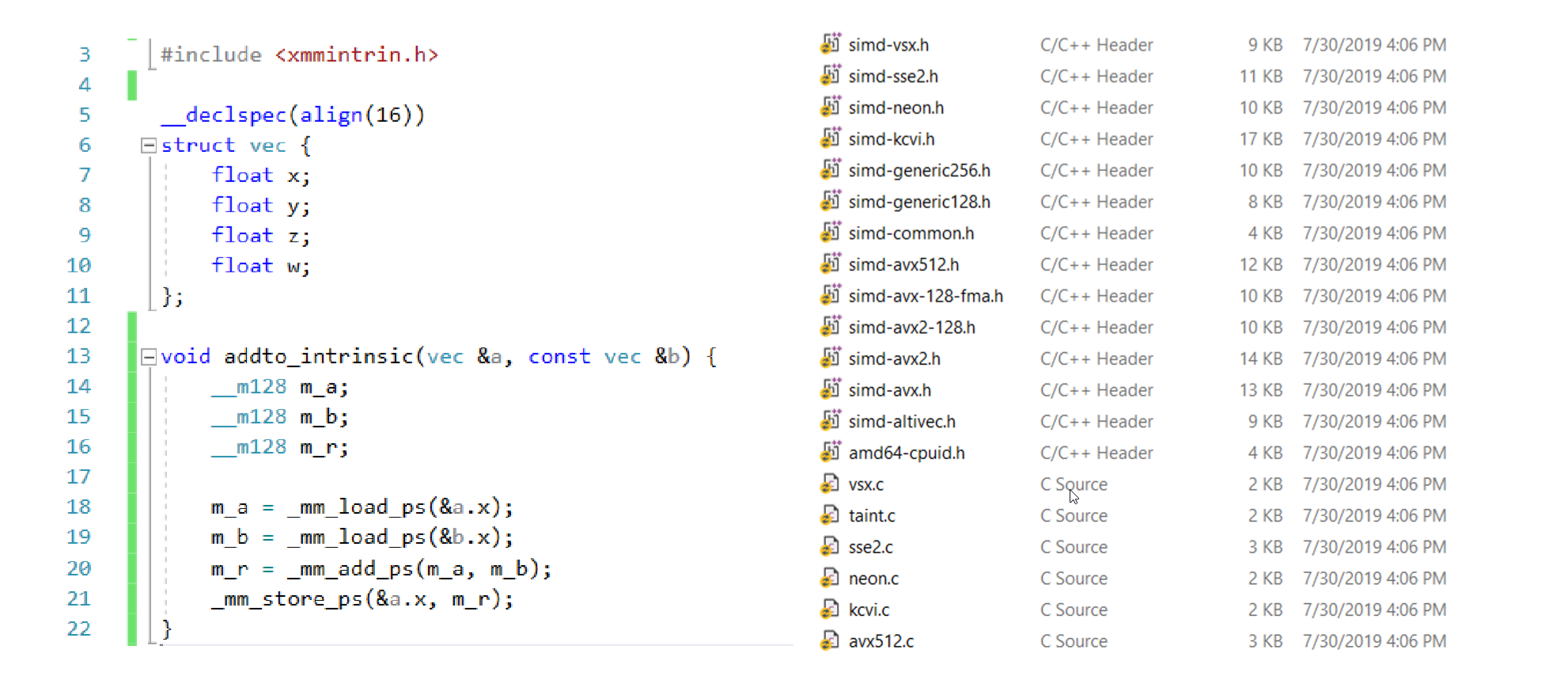
缺陷:
- 代碼需根據不同平臺指令集,包含不同指令集庫頭檔案(無跨平臺特性)
使用ISPC語言
ISPC是英特爾推出的面向CPU的著色器語言,它適用多種指令集的矢量指令(如SSE2、SSE4、AVX、AVX2等),
ISPC是基于C語言的,所以它大部分語法和C語言是一致的,可以減少學習成本,
ISPC源代碼,經過編譯后輸出.obj檔案和.h檔案,這樣我們在撰寫C/C++程式時可以包含該頭檔案以使用ISPC代碼,
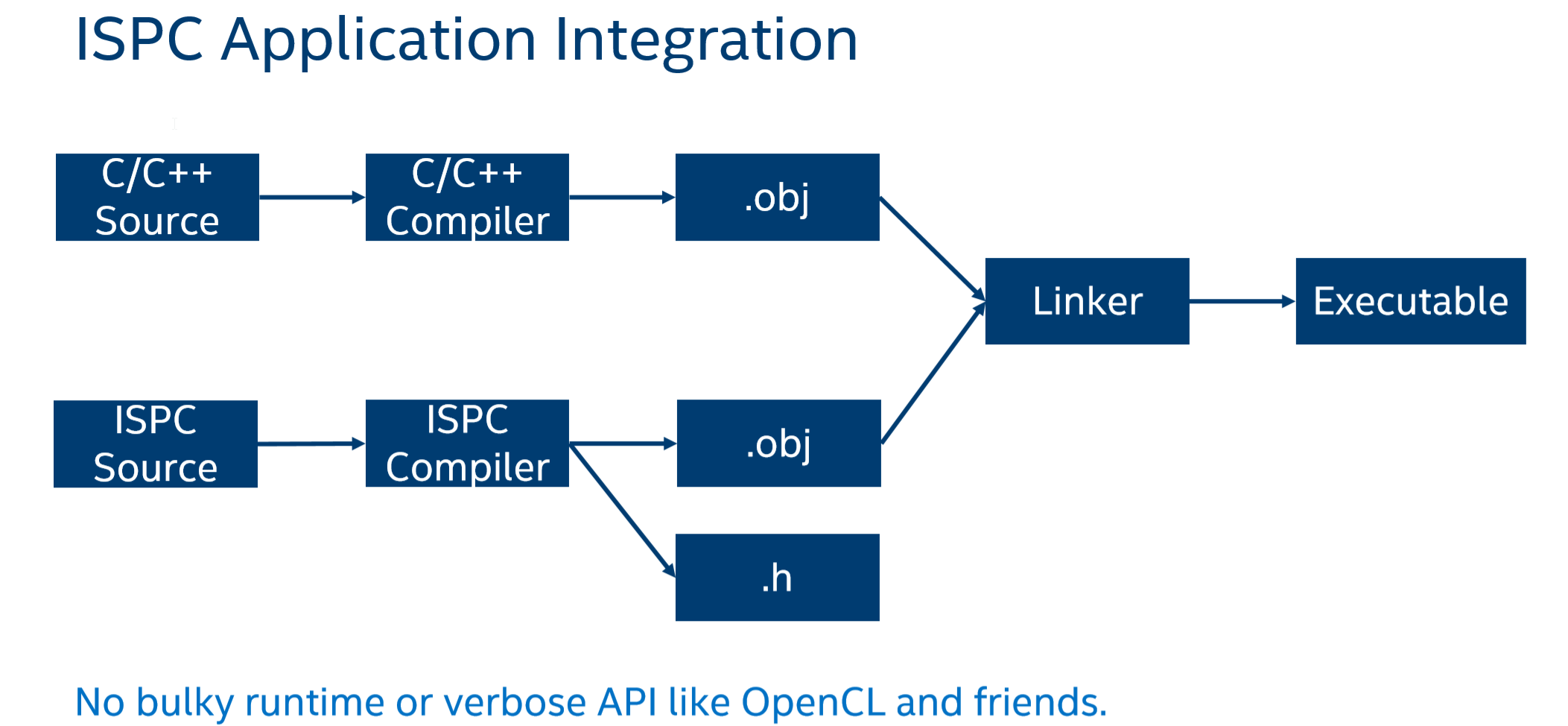
下面簡單提供個代碼示例比較:
// C/C++ Code
id rgb2grey(int N,
float R[],
float G[],
float B[],
float grey[]) {
for (int i = 0; i < N; i++) {
grey[i] = 0.3f * R[i] + 0.59f * G[i] + 0.11f * B[i];
}
}
// ISPC Code
export void rgb2grey(uniform int N,
uniform float R[],
uniform float G[],
uniform float B[],
uniform float grey[]) {
foreach(i = 0 ... N) {
grey[i] = 0.3f * R[i] + 0.59f * G[i] + 0.11f * B[i];
}
}
ISPC語言的語法非常易學,因為它的關鍵字真的很少:
- 類似于C/C++的關鍵字:if, else, switch, for, while, do…while, goto
- 當然也有為了支持并行回圈的關鍵字:foreach, foreach_active, foreach_tiled, foreach_unique
- 還有其它一些不常用關鍵字就不列舉了
更具體的ISPC語法就不多講解,可以自己自行去查看官方檔案(文章末尾參考部分會給出鏈接),
在線編譯器godbolt,可以用于測驗ISPC代碼及除錯匯編代碼:Compiler Explorer
并行回圈
// C/C++ Code
void func(int N,
float A[],
float B[],
float C[]) {
for (int i = 0; i < N; i++) {
C[i] = A[i] * B[i];
}
}
上面是一個正常的C/C++回圈代碼,這樣就是一般的分量操作,如下圖左側:
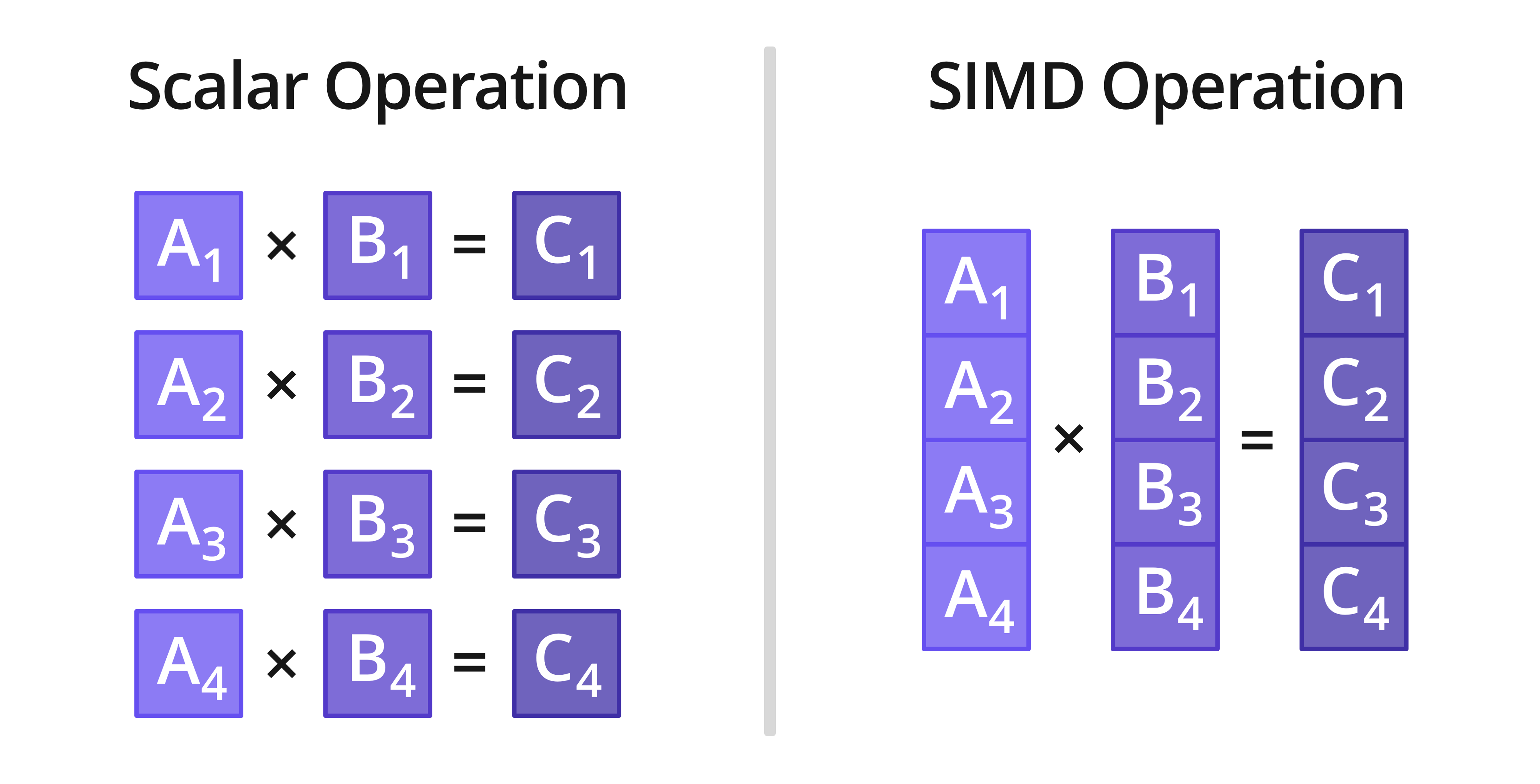
在ISPC語法里,只需簡單的寫上foreach(i = 0 ... N) ,IPSC編譯器編譯時會為其編譯成圖中右側的行為,即一次回圈并行處理M個元素,實際回圈N/M次,
// ISPC Code
export void rgb2grey(int N,
uniform float A[],
uniform float B[],
uniform float C[]) {
foreach(i = 0 ... N) {
C[i] = A[i] * B[i];
}
}
更方便的是,ISPC會自動處理并行回圈的邊界情況(例如每次并行處理4個元素時,N/4次回圈后余出1~3個元素),
避免Gather行為
這是一個正常的顏色結構,文中定義了若干個顏色物件,
struct Color{
float r,g,b;
};
Color colors[1024];
SIMD技術讀取變數一般都是連續若干個(在圖中為4個)變數一次性讀取,這種行為叫做矢量讀取,
而由于上文的顏色結構定義,其記憶體分布則如圖中的上部分,
要對4個紅色分量進行操作時,則需要進行多次讀取,這被稱為Gather行為,
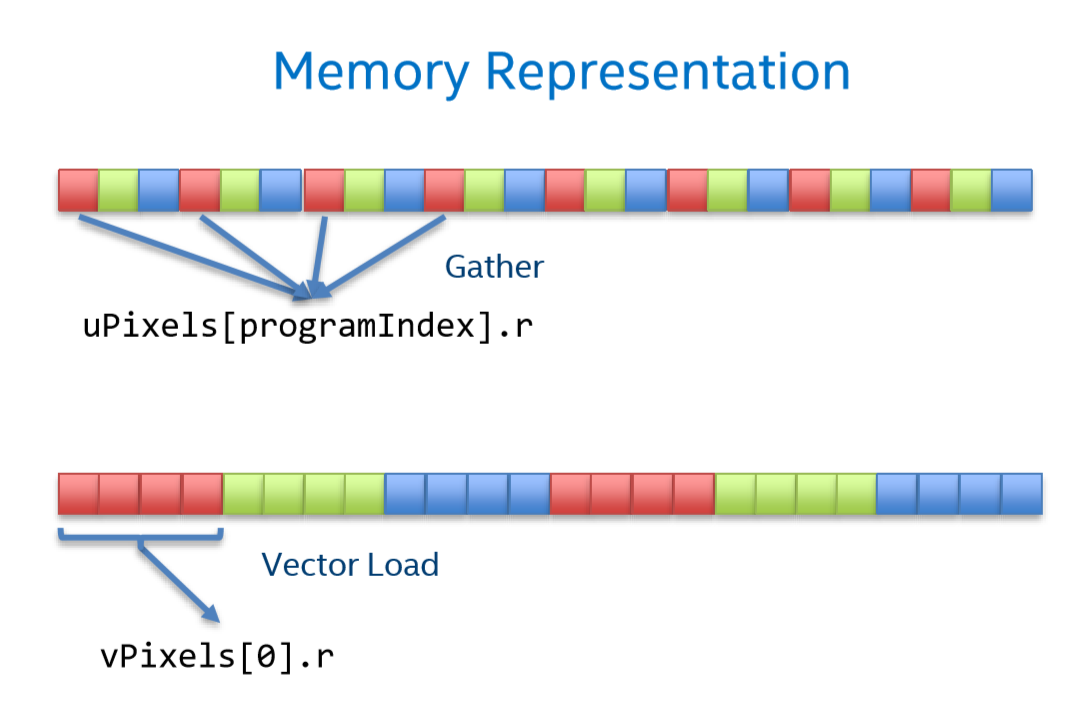
struct VaryingColor{
float r[vectorLen];
float g[vectorLen];
float b[vectorLen];
};
Color colors[1024/vectorLen];
倘若我們使用如下結構定義,則記憶體分布會如圖中下部分,這樣就能一次讀入4個紅色分量,高效地利用SIMD技術,這種結構被稱為SIMD友好型結構,
在ISPC語言里,使用varying型別可以方便的定義SIMD友好型結構,
CPU快取(CPU cache)
在組裝電腦購買CPU的時候,不知道大家是否留意過CPU的一個引數:N級快取(N一般有1/2/3)
什么是CPU快取
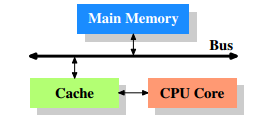
簡單地剖析結構,大概會是這個關系:
CPU暫存器 <————> CPU快取 <————> 記憶體
可以看到CPU快取是介于記憶體和CPU暫存器之間的一個存盤區域,
CPU快取地存盤空間比記憶體小,比暫存器大,
為什么需要CPU快取
CPU的運行頻率太快了,而CPU訪問記憶體的速度很慢,這樣在處理器時鐘周期內,CPU常常需要等待暫存器讀取記憶體,浪費時間,
而CPU訪問CPU快取則速度快很多,為了緩解CPU和記憶體之間速度的不匹配問題,CPU快取則預先存盤好潛在可能會訪問的記憶體資料,
CPU快取預先存的是什么
時間區域性:如果某個資料被訪問,那么在不久的將來它很可能再次被訪問,
空間區域性:如果某個資料被訪問,那么與它相鄰的資料很快也能被訪問,
CPU多級快取根據這兩個特點,一般存盤的是被訪問過的資料和被訪問資料的相鄰資料,
CPU快取命中/未命中
CPU把待處理的資料或已處理的資料存入快取指定的地址中,如果即將要處理的資料已經存在此地址了,就叫作CPU快取命中,這會比直接訪問記憶體要快的多,
如果CPU快取未命中,就轉到記憶體地址訪問,也就是直接訪問記憶體,
提高CPU快取命中率
要盡可能提高CPU快取命中率,關鍵就是要盡量讓使用的資料連續在一起,
由于面向資料編程技巧很多,本文篇幅有限,只介紹部分,
使用連續陣列存盤要批處理的物件
傳統的組件模式,往往讓游戲物件持有一個或多個組件的參考資料(指標資料),
(一個典型的游戲物件類,包含了2種組件的指標)
class GameObject {
//....GameObject的屬性
Component1* m_component1;
Component2* m_component2;
};
下面一幅圖顯示了這種傳統模式的結構: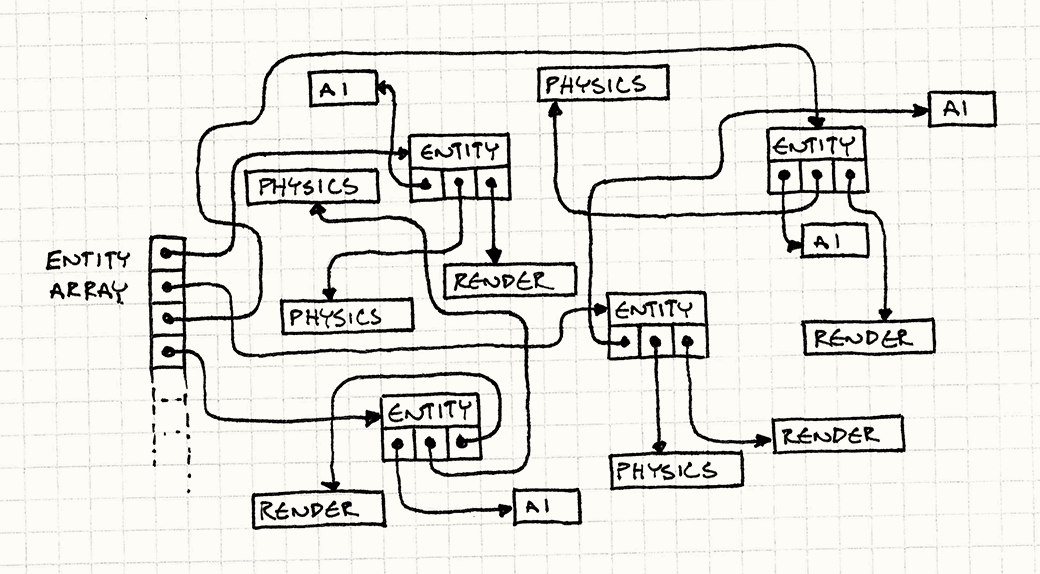
游戲物件/組件往往是批處理操作較多(每幀更新/渲染/或其他操作)的物件,
這個傳統結構相應的每幀更新代碼:
GameObject g[MAX_GAMEOBJECT_NUM];
for(int i = 0; i < GameObjectsNum; ++i) {
g[i].update();
if(g[i].componet1 != nullptr)g[i].componet1->update();
if(g[i].componet2 != nullptr)g[i].componet2->update();
}
而根據圖中可以看到,這種指來指去的結構對CPU快取極其不友好:為了訪問組件總是跳轉到不相鄰的記憶體,
倘若游戲物件和組件的更新順序不影響游戲邏輯,則一個可行的辦法是將他們都以連續陣列形式存在,
注意是物件陣列,而不是指標陣列,如果是指標陣列的話,這對CPU快取命中沒有意義(因為要通過指標跳轉到不相鄰的記憶體),
GameObject g[MAX_GAMEOBJECT_NUM];
Component1 a[MAX_COMPONENT_NUM];
Component2 b[MAX_COMPONENT_NUM];
//連續陣列存盤能讓下面的批處理中CPU快取命中率較高
for (int i = 0; i < GameObjectsNum; ++i) {
g[i].update();
}
for (int i = 0; i < Componet1Num; ++i) {
a[i].update();
}
for (int i = 0; i < Componet2Num; ++i) {
b[i].update();
}
避免無效資料夾雜在連續記憶體區域
這是一個簡單的粒子系統:
const int MAX_PARTICLE_NUM = 3000;
//粒子類
class Particle {
private:
bool active;
Vec3 position;
Vec3 velocity;
//....其它粒子所需方法
};
Particle particles[MAX_PARTICLE_NUM];
int particleNum;
它使用了典型的lazy策略,當要洗掉一個粒子時,只需改變active標記,無需移動記憶體,
然后利用標記判斷,每幀更新的時候可以略過洗掉掉的粒子,
當需要創建新粒子時,只需要找到第一個被洗掉掉的粒子,更改其屬性即可,
for (int i = 0; i < particleNum; ++i) {
if (particles[i].isActive()) {
particles[i].update();
}
}
表面上看這很科學,實際上這樣做CPU快取命中率不高:每次批處理CPU快取都加載過很多不會用到的粒子資料(標記被洗掉的粒子),
一個可行的方法是:當要洗掉粒子時,將佇列尾的粒子記憶體復制到該粒子的位置,并記錄減少后的粒子數量,
移動記憶體(復制記憶體)操作是程式員最不想看到的,但是實際執行批處理帶來的速度提升相比洗掉的開銷多的非常多,除非你移動的記憶體物件大小實在大到令人發指
particles[i] = particles[particleNum];
particleNum--;
這樣我們就可以保證在這個粒子批量更新操作中,CPU快取總是能以高命中率擊中,
for (int i = 0; i < particleNum; ++i) {
particles[i].update();
}
冷資料/熱資料分割
有人可能認為這樣能最大程度利用CPU快取:把一個物件所有要用的資料(包括組件資料)都塞進一個類里,而沒有任何用指標或參考的形式間接存盤資料,
實際上這個想法是錯誤的,我們不能忽視一個問題:CPU快取的存盤空間是有限的
于是我們希望CPU快取存盤的是經常使用的資料,而不是那些少用的資料,這就引入了冷資料/熱資料分割的概念了,
熱資料:經常要操作使用的資料,我們一般可以直接作為可直接訪問的成員變數,
冷資料:比較少用的資料,我們一般以參考/指標來間接訪問(即存盤的是指標或者參考),
一個栗子:對于人類來說,生命值位置速度都是經常需要操作的變數,是熱資料,
而掉落物物件只有人類死亡的時候才需要用到,所以是冷資料;
class Human {
private:
float health;
float power;
Vec3 position;
Vec3 velocity;
LootDrop* drop;
//....
};
class LootDrop{
Item[2] itemsToDrop;
float chance;
//....
};
頻繁呼叫的函式盡可能不要做成虛函式
C++的虛函式機制,簡單來說是兩次地址跳轉的函式呼叫,這對CPU快取十分不友好,往往命中失敗,
實際上虛函式可以優雅解決很多面向物件的問題,然而在游戲程式如果有很多虛函式都要頻繁呼叫(例如每幀呼叫),很容易引發性能問題,
解決方法是,把這些頻繁呼叫的虛函式盡可能去除virtual特性(即做成普通成員函式),并避免呼叫基類物件的成員函式,代價是這樣一改得改很多與之牽連代碼,
所以最好一開始設計程式時,需要先想好哪些最好不要寫成virtual函式,
這實際上就是在優雅與性能之間尋求一個平衡,
重新認識C++ STL容器
STL容器,特別是set,map,有著很多O(logN)的操作速度,但并不意味著是最佳選擇,因為這種復雜度表示往往隱藏了常數很大的事實,
例如說,集合的主流實作是基于紅黑樹,基于節點存盤的,而每次插入/洗掉節點都意味著呼叫一次系統分配記憶體/釋放記憶體函式,這相比vector等矢量容器所有操作僅一次系統分配記憶體(理想情況來說),實際上就慢了不少,
此外,矢量容器對CPU快取更加友好,遍歷該種容器容易命中快取,而節點式容器則相對容易命中失敗,
綜合上述,如果要選擇一個最適合的容器,那么不要過度信賴時間復雜度,除非你十分徹底的了解STL容器,或對各容器進行多次效率測驗,
更多小細節(不常用)
面向資料編程還有更多小細節,但是這些都不常用,就只作為一種思考面向資料編程的另類角度,
對二維陣列int a[100][100]的遍歷:
for(int x=0;x<100;++x)
for(int y=0;y<100;++y)
a[x][y]; //do something
for(int y=0;y<100;++y)
for(int x=0;x<100;++x)
a[x][y]; //do something
內回圈應該是對x遞增還是對y遞增比較快?答案是:對y遞增比較快,
因為對 y 的遞增,結果是一個int大小的跳轉,也就是說容易訪問到相鄰的記憶體,即容易擊中CPU快取,
而對 x 的遞增,結果是100個int大小的跳轉,不容易擊中CPU,
而內回圈如果是y的話,那么就能內外回圈總共遞增100*100次y,
但內回圈如果是x的話,那么就內外回圈總共只能遞增100次y,相比上者,CPU擊中比較少,
總結
對面向物件和面向資料的看法:
先說結論:應該兼有,
因為游戲程式是一個既需要高性能又復雜的工程,
使用面向物件的游戲程式新手,常常就有一個問題:過度設計/過度抽象,什么都想用設計模式封裝一下抽象一下,
這就很容易導致一些過度設計/過度抽象導致游戲性能太差,
博主現在的專案風格都比較偏向面向資料思想,盡量減少虛函式的使用,多利用資料組合成物件,而不是重寫各種基類虛函式,
對于一些資料結構的考量,也盡量偏多使用連續存盤的結構(例如陣列),
如何兼有兩種思想,這種玄學的問題可能得靠自己去感悟,多嘗試和測驗性能差別,
參考
《Game Engine Architecture》 2014-1 作者: Jason Gregory
使用英特爾? ISPC 簡化SIMD開發 | 英特爾? 軟體
WebAssembly and SIMD - Wasmer - Medium
游戲設計模式——面向資料編程(舊) - KillerAery - 博客園
游戲設計模式系列-其他文章:
https://www.cnblogs.com/KillerAery/category/1307176.html
本文使用markdown”重置“以前寫的面向資料編程文章,順便添加和修改了一些內容,吐槽一下,博客園的博文發出去指定tinymce后就不能再修改成md型別了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14623.html
標籤:其他