古詩詞是中國文化殿堂的瑰寶,記得曾經在韓國做 Exchange Student 的時候,看到他們學習我們的古詩詞,有中文的還有翻譯版的,自己發自內心的驕傲,甚至也會在某些時候背起一些耳熟能詳的詩詞,
本文將會通過深度學習為我們生成一些古詩詞,并將模型部署到 Serverless 架構上,實作基于 Serverless 的古詩詞生成 API,

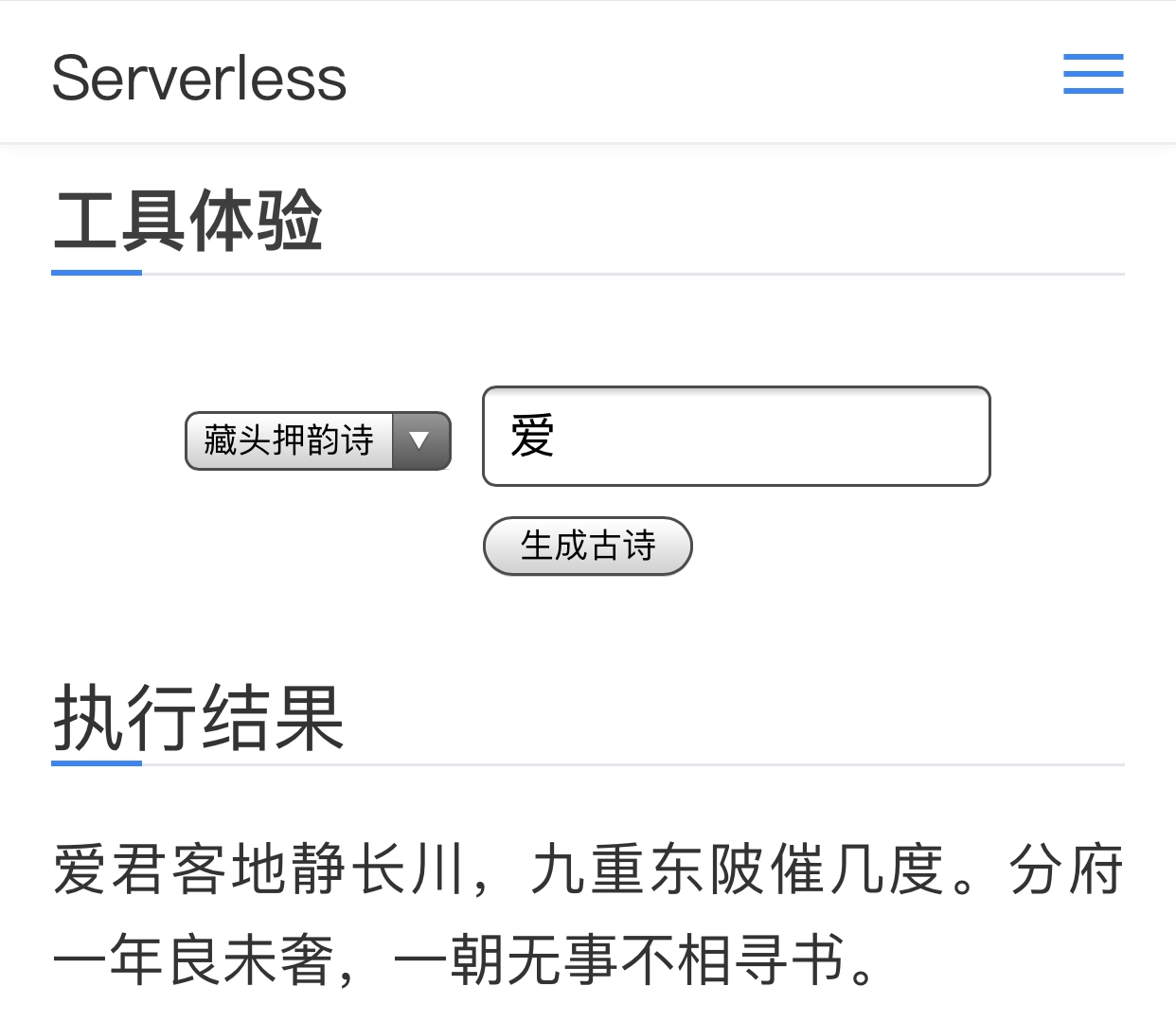
專案構建
古詩詞生成實際上是文本生成,或者說是生成式文本,關于基于深度學習的文本生成,最入門級的讀物包括 Andrej Karpathy 的博客,他使用例子生動講解了 Char-RNN (Character based Recurrent Neural Network) 如何用于從文本資料集里學習,然后自動生成像模像樣的文本,
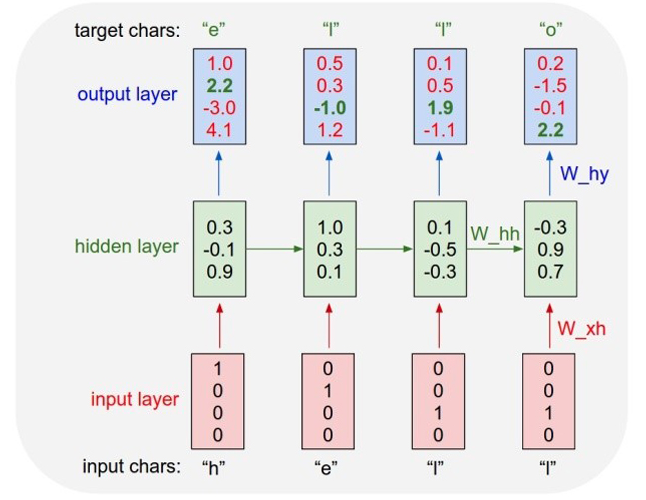
上圖直觀展示了 Char-RNN 的原理,以要讓模型學習寫出「hello」為例,Char-RNN 的輸入輸出層都是以字符為單位,輸入「h」,應該輸出「e」;輸入「e」,則應該輸出后續的「l」,
輸入層我們可以用只有一個元素為1的向量來編碼不同的字符,例如,「h」被編碼為「1000」、「e」被編碼為「0100」,而「l」被編碼為「0010」,使用 RNN 的學習目標是,可以讓生成的下一個字符盡量與訓練樣本里的目標輸出一致,在圖一的例子中,根據前兩個字符產生的狀態和第三個輸入「l」預測出的下一個字符的向量為 <0.1, 0.5, 1.9, -1.1>,最大的一維是第三維,對應的字符則為「0010」,正好是「l」,這就是一個正確的預測,但從第一個「h」得到的輸出向量是第四維最大,對應的并不是「e」,這樣就產生代價,
學習的程序就是不斷降低這個代價,學習到的模型,對任何輸入字符可以很好地不斷預測下一個字符,如此一來就能生成句子或段落,
本文專案構建參考了 Github 已有專案:https://github.com/norybaby/poet
通過 Clone 代碼,并且安裝相關依賴:
pip3 install tensorflow==1.14 word2vec numpy
通過訓練:
python3 train.py
可以看到訓練結果:
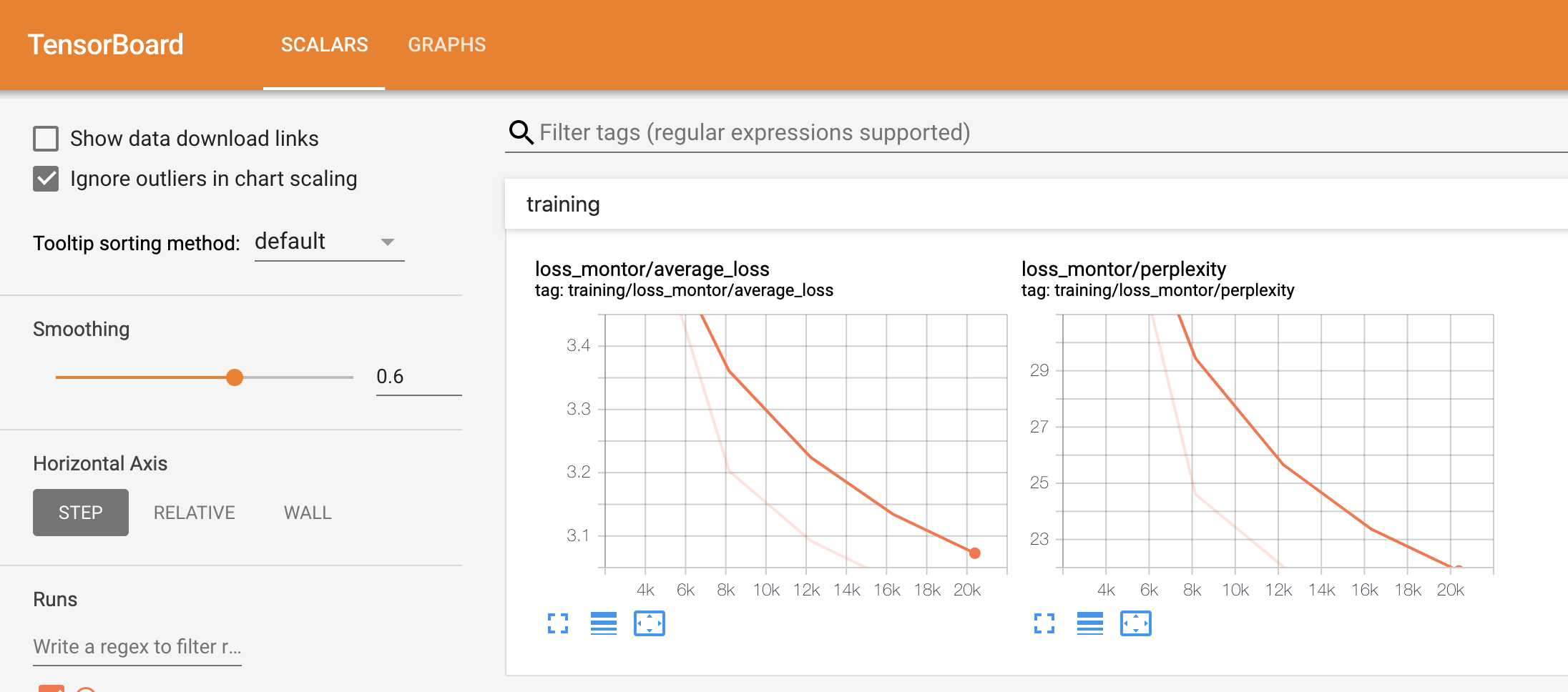
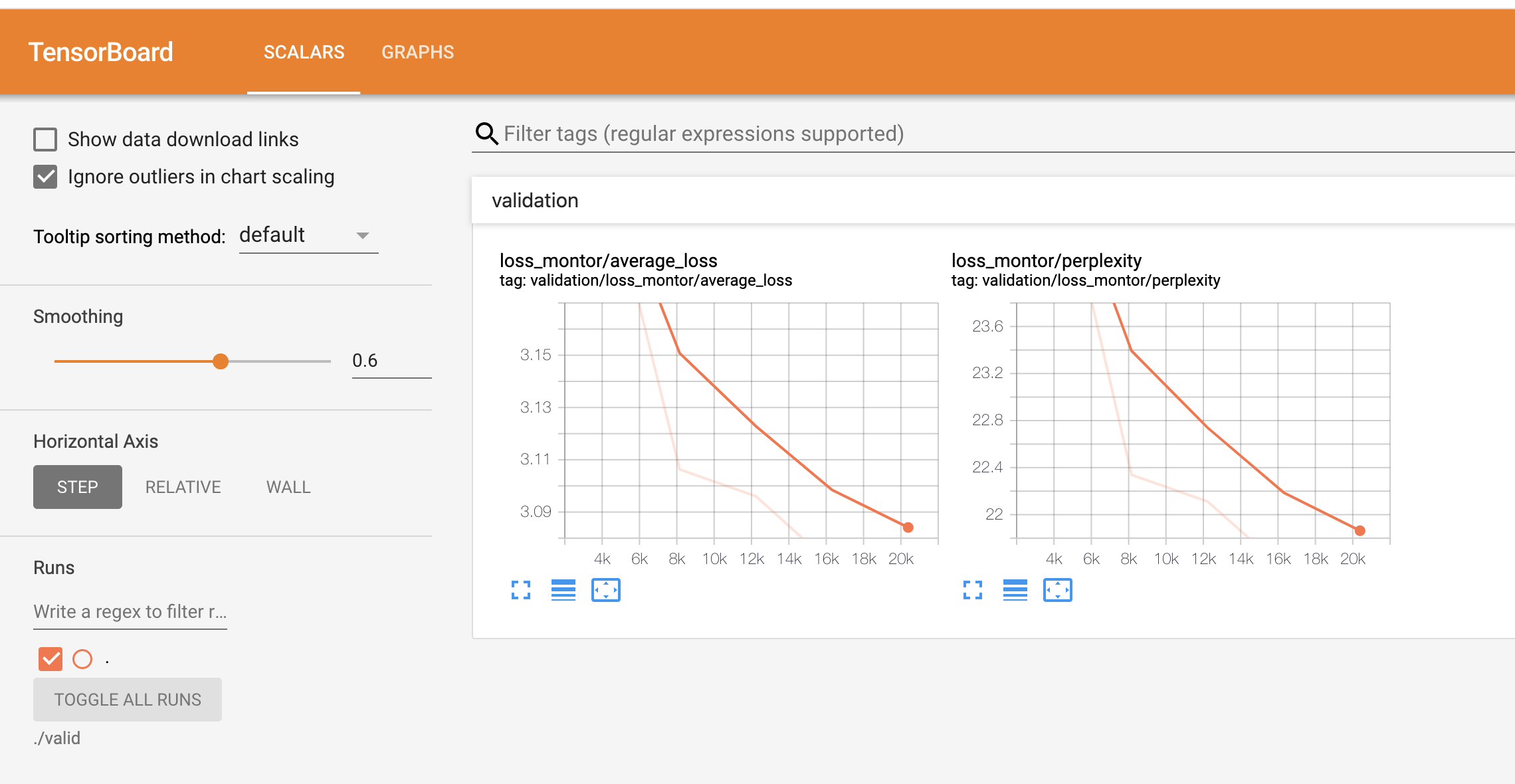
此時會生成多個模型在 output_poem 檔案夾下,我們只需要保留最好的即可,例如我的訓練之后生成的 json 檔案:
{
"best_model": "output_poem/best_model/model-20390",
"best_valid_ppl": 21.441762924194336,
"latest_model": "output_poem/save_model/model-20390",
"params": {
"batch_size": 16,
"cell_type": "lstm",
"dropout": 0.0,
"embedding_size": 128,
"hidden_size": 128,
"input_dropout": 0.0,
"learning_rate": 0.005,
"max_grad_norm": 5.0,
"num_layers": 2,
"num_unrollings": 64
},
"test_ppl": 25.83984375
}
此時,我只需要保存 output_poem/best_model/model-20390 模型即可,
部署上線
在專案目錄下,安裝必要依賴:
pip3 install word2vec numpy -t ./
由于 Tensorflow 等是騰訊云云函式內置的package,所以這里無需安裝,另外 numpy 這個 package 需要在 CentOS+Python3.6 環境下打包,也可以通過之前制作的小工具打包:https://www.serverlesschina.com/35.html
完成之后,撰寫函式入口檔案:
import uuid, json
from write_poem import WritePoem, start_model
writer = start_model()
def return_msg(error, msg):
return_data = https://www.cnblogs.com/serverlesscloud/p/{"uuid": str(uuid.uuid1()),
"error": error,
"message": msg
}
print(return_data)
return return_data
def main_handler(event, context):
# 型別
# 1: 自由
# 2: 押韻
# 3: 藏頭押韻
# 4: 藏字押韻
style = json.loads(event["body"])["style"]
content = json.loads(event["body"]).get("content", None)
if style in '34' and not content:
return return_msg(True, "請輸入content引數")
if style == '1':
return return_msg(False, writer.free_verse())
elif style == '2':
return return_msg(False, writer.rhyme_verse())
elif style == '3':
return return_msg(False, writer.cangtou(content))
elif style == '4':
return return_msg(False, writer.hide_words(content))
else:
return return_msg(True, "請輸入正確的style引數")
同時需要準備好 Yaml 檔案:
getUserIp:
component: "@serverless/tencent-scf"
inputs:
name: autoPoem
codeUri: ./
exclude:
- .gitignore
- .git/**
- .serverless
- .env
handler: index.main_handler
runtime: Python3.6
region: ap-beijing
description: 自動古詩詞撰寫
namespace: serverless_tools
memorySize: 512
timeout: 10
events:
- apigw:
name: serverless
parameters:
serviceId: service-8d3fi753
protocols:
- http
- https
environment: release
endpoints:
- path: /auto/poem
description: 自動古詩詞撰寫
method: POST
enableCORS: true
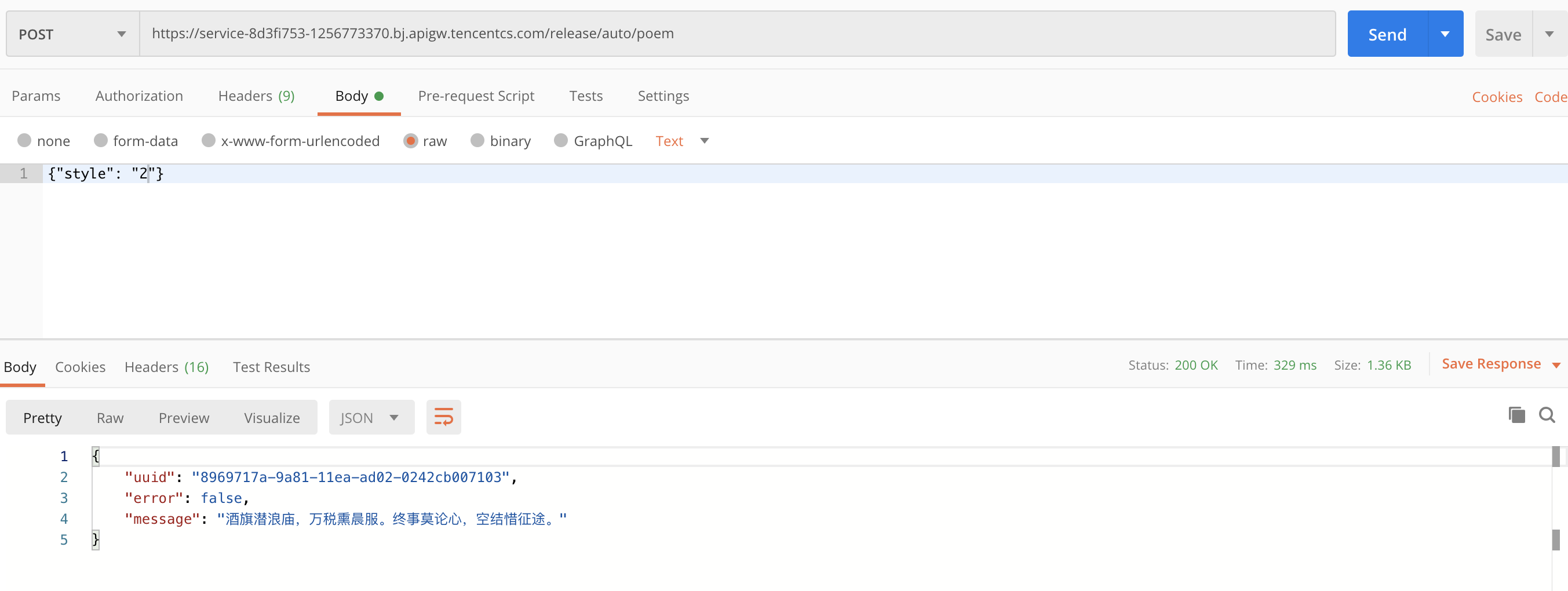
此時,我們就可以通過 Serverless Framework CLI 部署專案,部署完成之后,我們可以通過 PostMan 測驗我們的介面:
總結
本文通過已有的深度學習專案,在本地進行訓練,保存模型,然后將專案部署在騰訊云云函式上,通過與 API 網關的聯動,實作了一個基于深度學習的古詩詞撰寫的 API,
One More Thing
3 秒你能做什么?喝一口水,看一封郵件,還是 —— 部署一個完整的 Serverless 應用?
復制鏈接至 PC 瀏覽器訪問:https://serverless.cloud.tencent.com/deploy/express
3 秒極速部署,立即體驗史上最快的 Serverless HTTP 實戰開發!
傳送門:
- GitHub: github.com/serverless
- 官網:serverless.com
歡迎訪問:Serverless 中文網,您可以在 最佳實踐 里體驗更多關于 Serverless 應用的開發!
推薦閱讀:《Serverless 架構:從原理、設計到專案實戰》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14651.html
標籤:其他