一般來說,想給微信公眾號增加更多的功能,需要有一臺服務器,來進行公眾號后臺服務的搭建,那么在 Serverless 架構下,是否有更簡便的方法來實作這么一個公眾號后臺呢?我們試試?
初步搭建
Serverless 原生開發
首先我們當然要有一個微信公眾號!
接下來,我們要為我們的函式計算服務申請固定 IP:
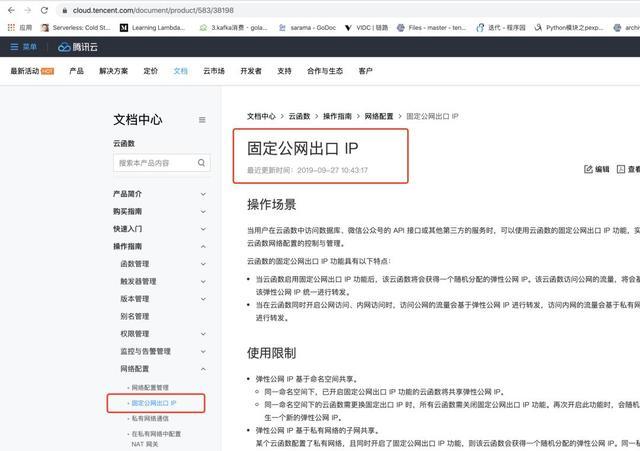

點擊白名單之后,我們可以填寫表單,完成固定公網出口 IP 的申請,
接下來進行代碼開發,
- 將函式系結到公眾號后臺,參考檔案:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Access_Overview.html
我們可以先在函式中按照檔案完成一個基本的鑒定功能:
def checkSignature(param):
'''
檔案地址:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Access_Overview.html
:param param:
:return:
'''
signature = param['signature']
timestamp = param['timestamp']
nonce = param["nonce"]
tmparr = [wxtoken, timestamp, nonce]
tmparr.sort()
tmpstr = ''.join(tmparr)
tmpstr = hashlib.sha1(tmpstr.encode("utf-8")).hexdigest()
return tmpstr == signature
再定義一個基本的回復方法:
def response(body, status=200):
return {
"isBase64Encoded": False,
"statusCode": status,
"headers": {"Content-Type": "text/html"},
"body": body
}
然后在函式入口處:
def main_handler(event, context):
if 'echostr' in event['queryString']: # 接入時的校驗
return response(event['queryString']['echostr'] if checkSignature(event['queryString']) else False)
配置我們 Yaml:
# serverless.yml
Weixin_GoServerless:
component: "@serverless/tencent-scf"
inputs:
name: Weixin_GoServerless
codeUri: ./Admin
handler: index.main_handler
runtime: Python3.6
region: ap-shanghai
description: 微信公眾號后臺服務器配置
memorySize: 128
timeout: 20
environment:
variables:
wxtoken: 自定義一個字串
appid: 暫時不寫
secret: 暫時不寫
events:
- apigw:
name: Weixin_GoServerless
parameters:
protocols:
- https
environment: release
endpoints:
- path: /
method: ANY
function:
isIntegratedResponse: TRUE
執行代碼,完成部署:

接下來在公眾號后臺,選擇基本配置:
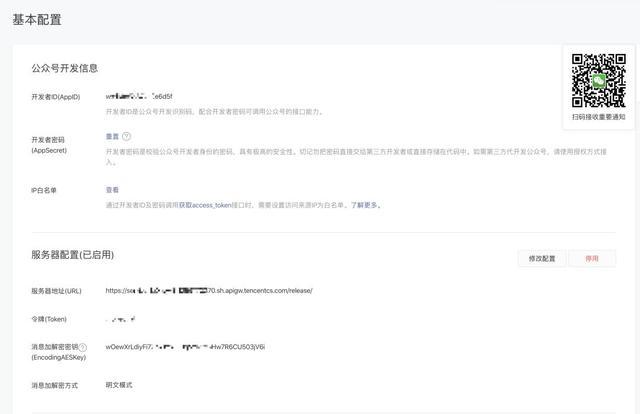
選擇修改配置:
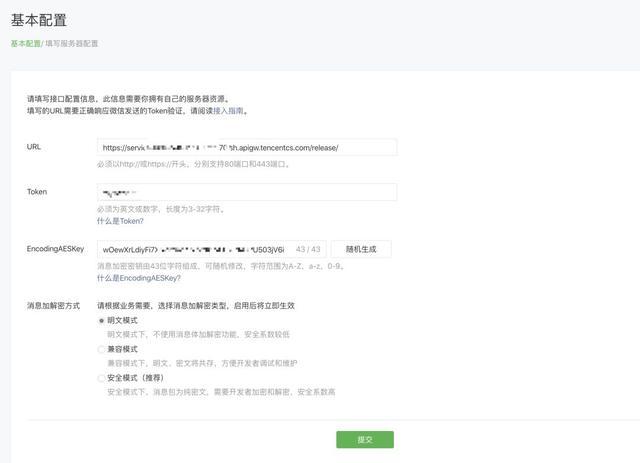
這里要注意:
-
URL,寫我們剛才部署完成回傳給我們的地址,并且在最后加一個 /
-
Token,寫我們 Yaml 中的 wxtoken,兩個地方要保持一樣的字串
-
EncodingAESKey,可以點擊隨機生成
-
訊息加密方法可以選擇明文
完成之后,我們可以點擊提交:

看到提交成功,就說明我們已經完成了第一步驟的系結,接下來,我們到函式的后臺:
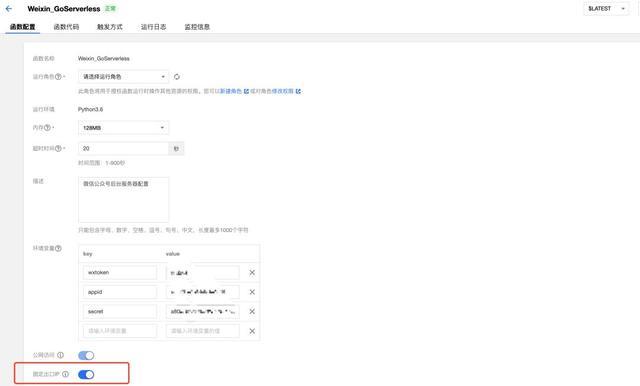
打開固定出口 IP,看到 IP 地址之后,復制 IP 地址:

點擊查看->修改,并將 IP 地址復制粘貼進來,保存,
同時我們查看開發者 ID 和密碼:
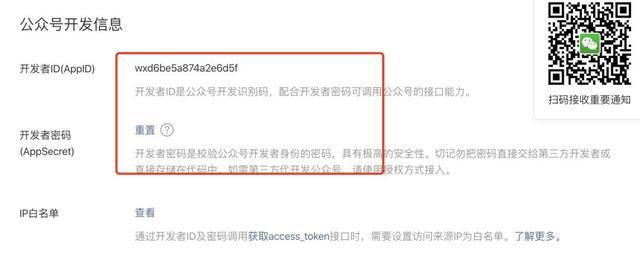
并將這兩個內容復制粘貼,放到我們環境變數中:

至此,我們完成了一個公眾號后臺服務的系結,
為了方便之后的操作,先獲取一下全域變數:
wxtoken = os.environ.get('wxtoken')
appid = os.environ.get('appid')
secret = os.environ.get('secret')
- 接下來對各個模塊進行編輯(本文只提供部分簡單基礎的模塊,更多功能實作可以參考微信公眾號檔案實作)
- 獲取 AccessToken 模塊:
def getAccessToken():
'''
檔案地址:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Get_access_token.html
正常回傳:{"access_token":"ACCESS_TOKEN","expires_in":7200}
例外回傳:{"errcode":40013,"errmsg":"invalid appid"}
:return:
'''
url = "https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=%s&secret=%s" % (appid, secret)
accessToken = json.loads(urllib.request.urlopen(url).read().decode("utf-8"))
print(accessToken)
return None if "errcode" in accessToken else accessToken["access_token"]
- 創建自定義選單模塊:
def setMenu(menu):
'''
檔案地址:https://developers.weixin.qq.com/doc/offiaccount/Custom_Menus/Creating_Custom-Defined_Menu.html
正確回傳:{"errcode":0,"errmsg":"ok"}
例外回傳:{"errcode":40018,"errmsg":"invalid button name size"}
:return:
'''
accessToken = getAccessToken()
if not accessToken:
return "Get Access Token Error"
url = "https://api.weixin.qq.com/cgi-bin/menu/create?access_token=%s" % accessToken
postData = https://www.cnblogs.com/serverlesscloud/p/urllib.parse.urlencode(menu).encode("utf-8")
requestAttr = urllib.request.Request(url=url, data=https://www.cnblogs.com/serverlesscloud/p/postData)
responseAttr = urllib.request.urlopen(requestAttr)
responseData = json.loads(responseAttr.read())
return responseData['errmsg'] if "errcode" in responseData else "success"
- 常見訊息回復模塊:
def textXML(body, event):
'''
:param body: {"msg": "test"}
msg: 必填,回復的訊息內容(換行:在content中能夠換行,微信客戶端就支持換行顯示)
:param event:
:return:
'''
return """<xml><ToUserName><![CDATA[{toUser}]]></ToUserName>
<FromUserName><![CDATA[{fromUser}]]></FromUserName>
<CreateTime>{time}</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[{msg}]]></Content></xml>""".format(toUser=event["FromUserName"],
fromUser=event["ToUserName"],
time=int(time.time()),
msg=body["msg"])
def pictureXML(body, event):
'''
:param body: {"media_id": 123}
media_id: 必填,通過素材管理中的介面上傳多媒體檔案,得到的id,
:param event:
:return:
'''
return """<xml><ToUserName><![CDATA[{toUser}]]></ToUserName>
<FromUserName><![CDATA[{fromUser}]]]></FromUserName>
<CreateTime>{time}</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<Image>
<MediaId><![CDATA[{media_id}]]></MediaId>
</Image></xml>""".format(toUser=event["FromUserName"],
fromUser=event["ToUserName"],
time=int(time.time()),
media_id=body["media_id"])
def voiceXML(body, event):
'''
:param body: {"media_id": 123}
media_id: 必填,通過素材管理中的介面上傳多媒體檔案,得到的id
:param event:
:return:
'''
return """<xml><ToUserName><![CDATA[{toUser}]]></ToUserName>
<FromUserName><![CDATA[{fromUser}]]></FromUserName>
<CreateTime>{time}</CreateTime>
<MsgType><![CDATA[voice]]></MsgType>
<Voice>
<MediaId><![CDATA[{media_id}]]></MediaId>
</Voice></xml>""".format(toUser=event["FromUserName"],
fromUser=event["ToUserName"],
time=int(time.time()),
media_id=body["media_id"])
def videoXML(body, event):
'''
:param body: {"media_id": 123, "title": "test", "description": "test}
media_id: 必填,通過素材管理中的介面上傳多媒體檔案,得到的id
title::選填,視頻訊息的標題
description:選填,視頻訊息的描述
:param event:
:return:
'''
return """<xml><ToUserName><![CDATA[{toUser}]]></ToUserName>
<FromUserName><![CDATA[{fromUser}]]></FromUserName>
<CreateTime>{time}</CreateTime>
<MsgType><![CDATA[video]]></MsgType>
<Video>
<MediaId><![CDATA[{media_id}]]></MediaId>
<Title><![CDATA[{title}]]></Title>
<Description><![CDATA[{description}]]></Description>
</Video></xml>""".format(toUser=event["FromUserName"],
fromUser=event["ToUserName"],
time=int(time.time()),
media_id=body["media_id"],
title=body.get('title', ''),
description=body.get('description', ''))
def musicXML(body, event):
'''
:param body: {"media_id": 123, "title": "test", "description": "test}
media_id:必填,縮略圖的媒體id,通過素材管理中的介面上傳多媒體檔案,得到的id
title:選填,音樂標題
description:選填,音樂描述
url:選填,音樂鏈接
hq_url:選填,高質量音樂鏈接,WIFI環境優先使用該鏈接播放音樂
:param event:
:return:
'''
return """<xml><ToUserName><![CDATA[{toUser}]]></ToUserName>
<FromUserName><![CDATA[{fromUser}]]></FromUserName>
<CreateTime>{time}</CreateTime>
<MsgType><![CDATA[music]]></MsgType>
<Music>
<Title><![CDATA[{title}]]></Title>
<Description><![CDATA[{description}]]></Description>
<MusicUrl><![CDATA[{url}]]></MusicUrl>
<HQMusicUrl><![CDATA[{hq_url}]]></HQMusicUrl>
<ThumbMediaId><![CDATA[{media_id}]]></ThumbMediaId>
</Music></xml>""".format(toUser=event["FromUserName"],
fromUser=event["ToUserName"],
time=int(time.time()),
media_id=body["media_id"],
title=body.get('title', ''),
url=body.get('url', ''),
hq_url=body.get('hq_url', ''),
description=body.get('description', ''))
def articlesXML(body, event):
'''
:param body: 一個list [{"title":"test", "description": "test", "picUrl": "test", "url": "test"}]
title:必填,圖文訊息標題
description:必填,圖文訊息描述
picUrl:必填,圖片鏈接,支持JPG、PNG格式,較好的效果為大圖360*200,小圖200*200
url:必填,點擊圖文訊息跳轉鏈接
:param event:
:return:
'''
if len(body["articles"]) > 8: # 最多只允許回傳8個
body["articles"] = body["articles"][0:8]
tempArticle = """<item>
<Title><![CDATA[{title}]]></Title>
<Description><![CDATA[{description}]]></Description>
<PicUrl><![CDATA[{picurl}]]></PicUrl>
<Url><![CDATA[{url}]]></Url>
</item>"""
return """<xml><ToUserName><![CDATA[{toUser}]]></ToUserName>
<FromUserName><![CDATA[{fromUser}]]></FromUserName>
<CreateTime>{time}</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>{count}</ArticleCount>
<Articles>
{articles}
</Articles></xml>""".format(toUser=event["FromUserName"],
fromUser=event["ToUserName"],
time=int(time.time()),
count=len(body["articles"]),
articles="".join([tempArticle.format(
title=eveArticle['title'],
description=eveArticle['description'],
picurl=eveArticle['picurl'],
url=eveArticle['url']
) for eveArticle in body["articles"]]))
-
對 main_handler 進行修改,使其:
-
識別系結功能
-
識別基本資訊
-
識別特殊額外請求(例如通過url觸發自定義選單的更新)
-
整體代碼:
def main_handler(event, context):
print('event: ', event)
if event["path"] == '/setMenu': # 設定選單介面
menu = {
"button": [
{
"type": "view",
"name": "精彩文章",
"url": "https://mp.weixin.qq.com/mp/homepage?__biz=Mzg2NzE4MDExNw==&hid=2&sn=168bd0620ee79cd35d0a80cddb9f2487"
},
{
"type": "view",
"name": "開源專案",
"url": "https://mp.weixin.qq.com/mp/homepage?__biz=Mzg2NzE4MDExNw==&hid=1&sn=69444401c5ed9746aeb1384fa6a9a201"
},
{
"type": "miniprogram",
"name": "在線編程",
"appid": "wx453cb539f9f963b2",
"pagepath": "/page/index"
}]
}
return response(setMenu(menu))
if 'echostr' in event['queryString']: # 接入時的校驗
return response(event['queryString']['echostr'] if checkSignature(event['queryString']) else False)
else: # 用戶訊息/事件
event = getEvent(event)
if event["MsgType"] == "text":
# 文本訊息
return response(body=textXML({"msg": "這是一個文本訊息"}, event))
elif event["MsgType"] == "image":
# 圖片訊息
return response(body=textXML({"msg": "這是一個圖片訊息"}, event))
elif event["MsgType"] == "voice":
# 語音訊息
pass
elif event["MsgType"] == "video":
# 視頻訊息
pass
elif event["MsgType"] == "shortvideo":
# 小視頻訊息
pass
elif event["MsgType"] == "location":
# 地理位置訊息
pass
elif event["MsgType"] == "link":
# 鏈接訊息
pass
elif event["MsgType"] == "event":
# 事件訊息
if event["Event"] == "subscribe":
# 訂閱事件
if event.get('EventKey', None):
# 用戶未關注時,進行關注后的事件推送(帶引數的二維碼)
pass
else:
# 普通關注
pass
elif event["Event"] == "unsubscribe":
# 取消訂閱事件
pass
elif event["Event"] == "SCAN":
# 用戶已關注時的事件推送(帶引數的二維碼)
pass
elif event["Event"] == "LOCATION":
# 上報地理位置事件
pass
elif event["Event"] == "CLICK":
# 點擊選單拉取訊息時的事件推送
pass
elif event["Event"] == "VIEW":
# 點擊選單跳轉鏈接時的事件推送
pass
在上述代碼中可以看到:
if event["MsgType"] == "text":
# 文本訊息
return response(body=textXML({"msg": "這是一個文本訊息"}, event))
elif event["MsgType"] == "image":
# 圖片訊息
return response(body=textXML({"msg": "這是一個圖片訊息"}, event))
這里就是說,當用戶發送了文本訊息時候,我們給用戶回復一個文本訊息:這是一個文本訊息,當用戶發送了一個圖片,我們給用戶回傳這是一個圖片訊息,用這兩個功能測驗我們這個后臺的連通性:
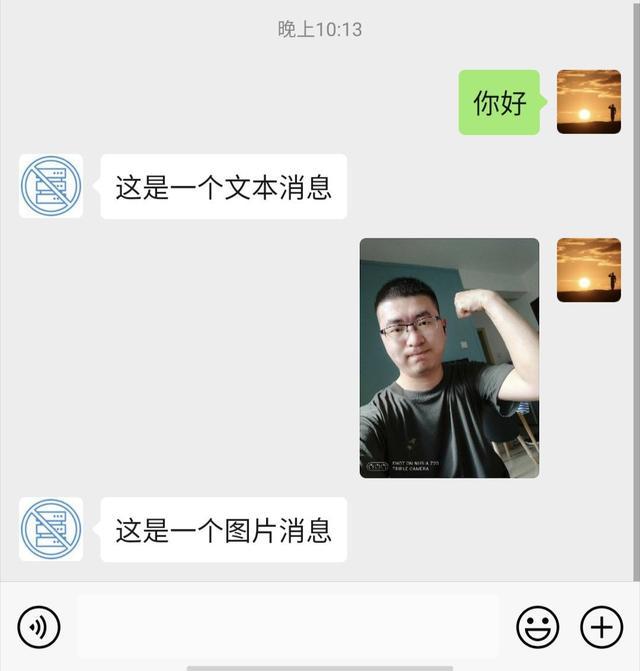
可以看到,系統已經可以正常回傳,
有人問了,這樣一個簡單的 Demo 有什么意義呢?可以告訴大家,我們可以很輕量地通過一個函式來實作微信公眾號的后端服務;這里都是基礎能力,我們可以在這個基礎能力之上,盡情添加創新力,例如:
-
用戶傳過來的是圖片訊息,我們可以通過一些識圖 API 告訴用戶這個圖片包括了什么?
-
用戶傳過來的是文字訊息,我們可以先設定一些幫助資訊/檢索資訊進行對比,如果沒找到就給用戶開啟聊天功能(這里涉及到人工智能中的自然語言處理,例如文本相似度檢測)
-
如果用戶發送的是語音,我們還可以將其轉成文本,生成對話訊息,然后再轉換成語音回傳給用戶
-
如果用戶發送了地理位置資訊,我們可以回傳用戶所在經緯度的街景資訊,或者周邊生活服務資訊等
-
留給大家想象!
使用 Werobot 框架
上面的方法,是通過 Serverless 原生開發的方法進行對接,除此之外,我們還可以選擇一些已有的框架,例如werobot等,
WeRoBot 是一個微信公眾號開發框架,通過 Serverless Component 中的tencent-werobot組件快速部署該框架:
Weixin_Werobot:
component: "@serverless/tencent-werobot"
inputs:
functionName: Weixin_Werobot
code: ./test
werobotProjectName: app
werobotAttrName: robot
functionConf:
timeout: 10
memorySize: 256
environment:
variables:
wxtoken: 你的token
apigatewayConf:
protocols:
- http
environment: release
然后新建代碼:
import os
import werobot
robot = werobot.WeRoBot(token=os.environ.get('wxtoken'))
robot.config['SESSION_STORAGE'] = False
robot.config["APP_ID"] = os.environ.get('appid')
robot.config["APP_SECRET"] = os.environ.get('secret')
# @robot.handler 處理所有訊息
@robot.handler
def hello(message):
return 'Hello World!'
if __name__ == "__main__":
# 讓服務器監聽在 0.0.0.0:80
robot.config['HOST'] = '0.0.0.0'
robot.config['PORT'] = 80
robot.run()
并且在本地安裝 werobot 相關依賴,完成之后,執行部署:

將下面的這個地址復制到公眾號后臺,開啟呼叫即可,

參考 Git:https://github.com/serverless-tencent/tencent-werobot
這里需要注意的是,我們一定要關掉 Session 或者將 Session 改成云資料庫,不能使用本地檔案等,例如關閉 Session 配置:
robot.config['SESSION_STORAGE'] = False
文本相似度實作圖文檢索
有時候用戶不知道我們發了什么文章,也不清楚每個文章具體內容,他可能只需要簡單的關鍵詞,來看一下這個公眾號是否有他想要的東西,
例如他搜索:如何上傳檔案?或者搜索:如何開發Component?而圖文檢索功能就可以快速把最相關的歷史文章推送給用戶,這將會是很方便的一件事情,效果圖如下:
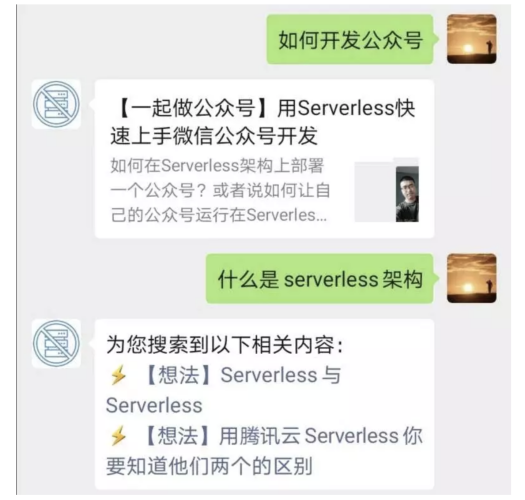
通過簡單的問題描述,找到目標結果,這就是我們做的文章搜索功能,當然,我們還可以把它拓展成「客服系統」,這是后話了,
回到正題,我們在之前的代碼基礎上,新增兩個函式:
- 函式 1:索引建立函式
主要功能:通過觸發該函式,可以將現有的公眾號資料進行整理,并且建立適當的索引檔案,存盤到 COS 中,
# -*- coding: utf8 -*-
import os
import re
import json
import random
from snownlp import SnowNLP
from qcloud_cos_v5 import CosConfig
from qcloud_cos_v5 import CosS3Client
bucket = os.environ.get('bucket')
secret_id = os.environ.get('secret_id')
secret_key = os.environ.get('secret_key')
region = os.environ.get('region')
client = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key))
def main_handler(event, context):
response = client.get_object(
Bucket=bucket,
Key=event["key"],
)
response['Body'].get_stream_to_file('/tmp/output.txt')
with open('/tmp/output.txt') as f:
data = https://www.cnblogs.com/serverlesscloud/p/json.loads(f.read())
articlesIndex = []
articles = {}
tempContentList = ["_", " ",
]
for eveItem in data:
for i in range(0, len(eveItem['content']['news_item'])):
content = eveItem['content']['news_item'][i]['content']
content = re.sub(r'<code(.*?)</code>', '_', content)
content = re.sub(r'<.*?>', '', content)
for eve in tempContentList:
content = content.replace(eve, "")
desc = "%s,%s,%s" % (
eveItem['content']['news_item'][i]['title'],
eveItem['content']['news_item'][i]['digest'],
",".join(SnowNLP(content).summary(3))
)
tempKey = "".join(random.sample('zyxwvutsrqponmlkjihgfedcba', 5))
articlesIndex.append(
{
"media_id": tempKey,
"description": desc
}
)
articles[tempKey] = eveItem['content']['news_item'][i]
client.put_object(
Bucket=bucket,
Body=json.dumps(articlesIndex).encode("utf-8"),
Key=event['index_key'],
EnableMD5=False
)
client.put_object(
Bucket=bucket,
Body=json.dumps(articles).encode("utf-8"),
Key=event['key'],
EnableMD5=False
)
這一部分,可能定制化比較多一些,首先是 tempContentList 變數,這里可以寫上一些公眾號中可能出現但不重要的話,例如公眾號末尾的引導關注文案,這些文案一般不參與搜索,所以最好在建立索引的時候進行替換去除,然后我們還通過上述代碼去掉了 code 標簽里面的內容,因為代碼也會影響結果,同時我還去掉了 html 標簽,
原始的檔案大概是這樣的:
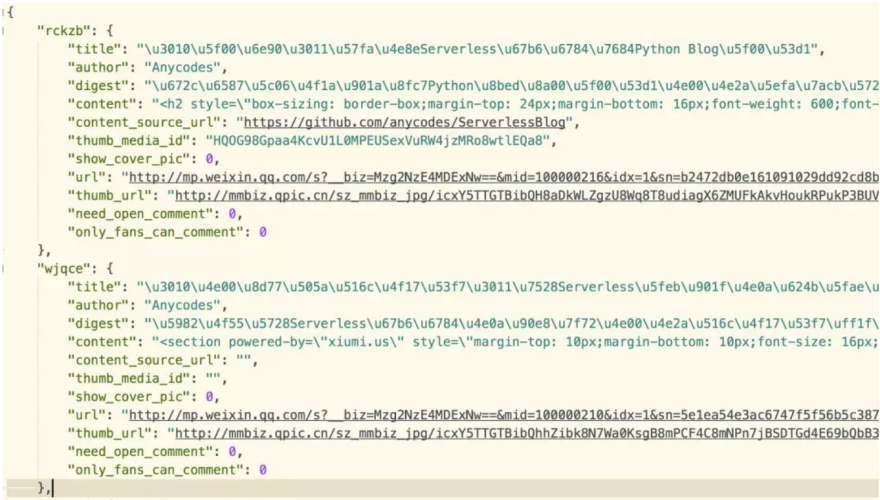
處理好的檔案(通過標題+描述+SnowNLP提取的摘要):

這些檔案將存盤到 COS 中,
這一部分的核心就是,正確讓我們提取出來的 description 盡可能準確地描述文章的內容,一般情況下,標題就是文章的核心,但是標題可能有一些資訊丟失,
例如文章「用騰訊云 Serverless 你要知道他們兩個的區別」,但實際上描述的是 Plugin 和 Component 的區別,雖然標題知道是兩個東西,但是卻缺少了核心的目標,所以再加上我們下面的描述:什么是 Serverless Framework Plugin?什么是Component?Plugin與Component 有什么區別?想要入門 Serverless CLI,這兩個產品必須分的清楚,本文將會分享這二者區別與對應的特點、功能,
當然,加上描述之后內容變得已經相當精確,但是正文中,可能有更加精準的描述或者額外的內容,所以采用的是標題+描述+摘要(textRank 提取出來的前三句,屬于提取式文本),
- 函式 2: 搜索函式
主要功能:當用戶向微信號發送了指定關鍵詞,通過該函式獲取的結果,
思考:函式 1 和函式 2,都可以集成在之前的函式中,為什么要把這兩個函式單獨拿出來做一個獨立的函式存在呢?將它們放在同一個函式中不好么?
原因是 —— 主函式觸發次數相對來說是最多的,而且這個函式本身不需要太多的資源配置(64M 就夠了),而函式 1 和函式 2,可能需要消耗更多的資源,如果三個函式合并放在一起,可能函式的記憶體大小需要整體調大,滿足三個函式需求,這樣可能會消耗更多資源,
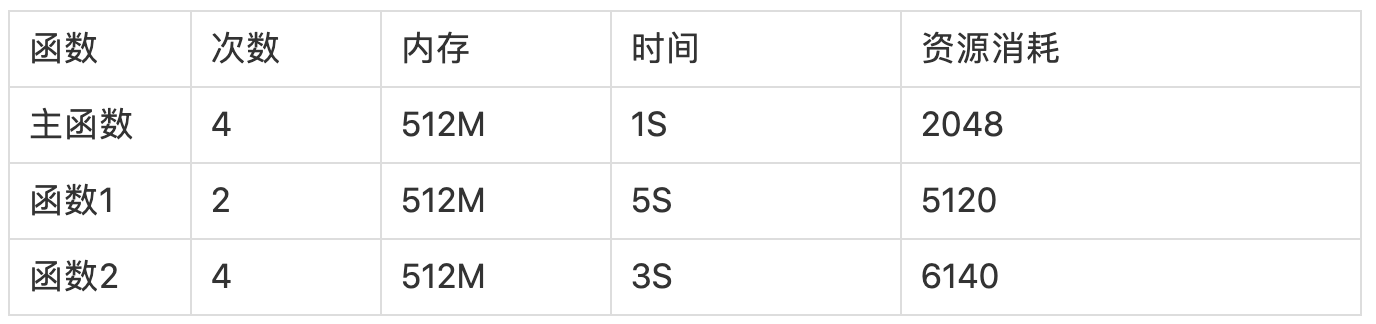
例如:主函式觸發了 10 次(64M,每次 1S),函式 1 觸發了 2 次(512 M,每次 5S),函式 2 觸發了 4 次(384M,每次 3S)
如果將三個函式放在一起,資源消耗是:
如果將其變成三個函式來執行,資源消耗是:
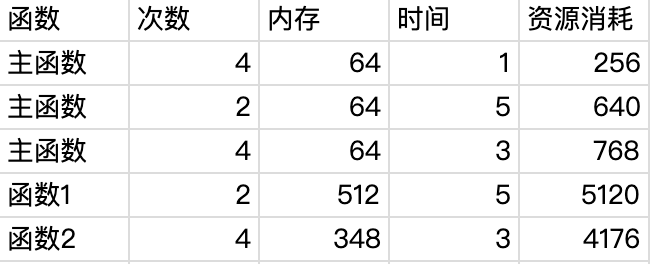
前者總計資源消耗 13308,后者 10432,呼叫次數越多,主函式的呼叫比例越大,所以節約的資源也就會越多,因此此處建議將資源消耗差距比較大的模塊,分成不同函式進行部署,
import os
import json
import jieba
from qcloud_cos_v5 import CosConfig
from qcloud_cos_v5 import CosS3Client
from collections import defaultdict
from gensim import corpora, models, similarities
bucket = os.environ.get('bucket')
secret_id = os.environ.get('secret_id')
secret_key = os.environ.get('secret_key')
region = os.environ.get('region')
client = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key))
def main_handler(event, context):
response = client.get_object(
Bucket=bucket,
Key=event["key"],
)
response['Body'].get_stream_to_file('/tmp/output.txt')
with open('/tmp/output.txt') as f:
data = json.loads(f.read())
articles = []
articlesDict = {}
for eve in data:
articles.append(eve['description'])
articlesDict[eve['description']] = eve['media_id']
sentence = event["sentence"]
documents = []
for eve_sentence in articles:
tempDatahttps://www.cnblogs.com/serverlesscloud/p/= " ".join(jieba.cut(eve_sentence))
documents.append(tempData)
texts = [[word for word in document.split()] for document in documents]
frequency = defaultdict(int)
for text in texts:
for word in text:
frequency[word] += 1
dictionary = corpora.Dictionary(texts)
new_xs = dictionary.doc2bow(jieba.cut(sentence))
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.TfidfModel(corpus)
featurenum = len(dictionary.token2id.keys())
sim = similarities.SparseMatrixSimilarity(
tfidf[corpus],
num_features=featurenum
)[tfidf[new_xs]]
answer_list = [(sim[i], articles[i]) for i in range(1, len(articles))]
answer_list.sort(key=lambda x: x[0], reverse=True)
result = []
print(answer_list)
for eve in answer_list:
if eve[0] > 0.10:
result.append(articlesDict[eve[1]])
if len(result) >= 8:
result = result[0:8]
return {"result": json.dumps(result)}
這一部分的代碼也是很簡單,主要是通過文本的相似度對每個文本進行評分,然后按照評分從高到低進行排序,給定一個閾值(此處設定的閾值為 0.1),輸出閾值之前的資料,
另外要注意,此處參考了兩個依賴是 jieba 和 gensim,這兩個依賴都可能涉及到二進制檔案,所以強烈推薦在 CentOS 系統下進行打包,
接下來就是主函式中的呼叫,為了實作上述功能,需要在主函式中新增方法:
- 獲取全部圖文訊息
def getTheTotalOfAllMaterials():
'''
檔案地址:https://developers.weixin.qq.com/doc/offiaccount/Asset_Management/Get_the_total_of_all_materials.html
:return:
'''
accessToken = getAccessToken()
if not accessToken:
return "Get Access Token Error"
url = "https://api.weixin.qq.com/cgi-bin/material/get_materialcount?access_token=%s" % accessToken
responseAttr = urllib.request.urlopen(url=url)
return json.loads(responseAttr.read())
def getMaterialsList(listType, count):
'''
檔案地址:https://developers.weixin.qq.com/doc/offiaccount/Asset_Management/Get_materials_list.html
:return:
'''
accessToken = getAccessToken()
if not accessToken:
return "Get Access Token Error"
url = "https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=%s" % accessToken
materialsList = []
for i in range(1, int(count / 20) + 2):
requestAttr = urllib.request.Request(url=url, data=https://www.cnblogs.com/serverlesscloud/p/json.dumps({"type": listType,
"offset": 20 * (i - 1),
"count": 20
}).encode("utf-8"), headers={
"Content-Type": "application/json"
})
responseAttr = urllib.request.urlopen(requestAttr)
responseData = https://www.cnblogs.com/serverlesscloud/p/json.loads(responseAttr.read().decode("utf-8"))
materialsList = materialsList + responseData["item"]
return materialsList
可以通過以下代碼呼叫:
rticlesList = getMaterialsList("news", getTheTotalOfAllMaterials()['news_count'])
- 將圖文訊息存盤到 COS,并且通過函式的 Invoke 介面,實作函式間呼叫:
def saveNewsToCos():
global articlesList
articlesList = getMaterialsList("news", getTheTotalOfAllMaterials()['news_count'])
try:
cosClient.put_object(
Bucket=bucket,
Body=json.dumps(articlesList).encode("utf-8"),
Key=key,
EnableMD5=False
)
req = models.InvokeRequest()
params = '{"FunctionName":"Weixin_GoServerless_GetIndexFile", "ClientContext":"{\\"key\\": \\"%s\\", \\"index_key\\": \\"%s\\"}"}' % (
key, indexKey)
req.from_json_string(params)
resp = scfClient.Invoke(req)
resp.to_json_string()
response = cosClient.get_object(
Bucket=bucket,
Key=key,
)
response['Body'].get_stream_to_file('/tmp/content.json')
with open('/tmp/content.json') as f:
articlesList = json.loads(f.read())
return True
except Exception as e:
print(e)
return False
- 根據搜索反饋回來的 Key 實作文章內容的對應
def searchNews(sentence):
req = models.InvokeRequest()
params = '{"FunctionName":"Weixin_GoServerless_SearchNews", "ClientContext":"{\\"sentence\\": \\"%s\\", \\"key\\": \\"%s\\"}"}' % (
sentence, indexKey)
req.from_json_string(params)
resp = scfClient.Invoke(req)
print(json.loads(json.loads(resp.to_json_string())['Result']["RetMsg"]))
media_id = json.loads(json.loads(json.loads(resp.to_json_string())['Result']["RetMsg"])["result"])
return media_id if media_id else None
最后在 main_handler 中,增加使用邏輯:
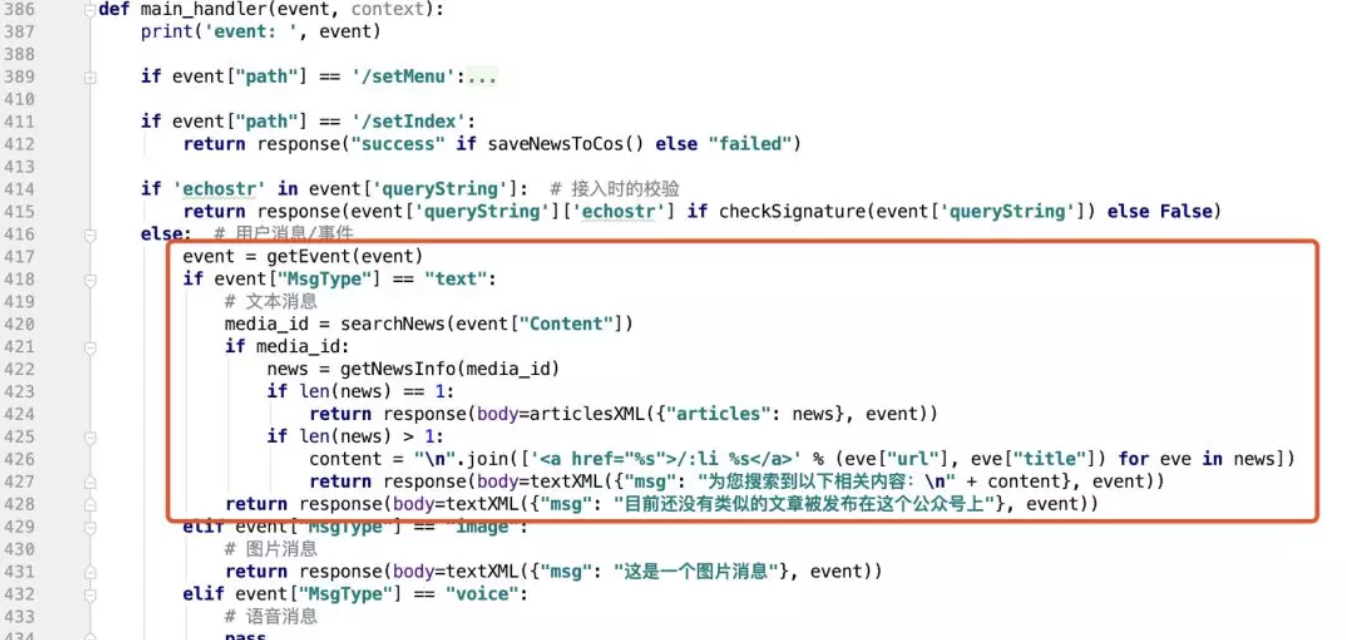
邏輯很簡答,就是根據用戶發的訊息,去查找對應的結果.拿到結果之后判斷結果個數,如果有 1 個相似內容,則回傳一個圖文,如果有多個則回傳帶有鏈接的文本,
另外一個邏輯是建立索引,直接是通過 API 網關觸發即可,當然,如果怕不安全或者有需要的話,可以增加權限堅定的引數:
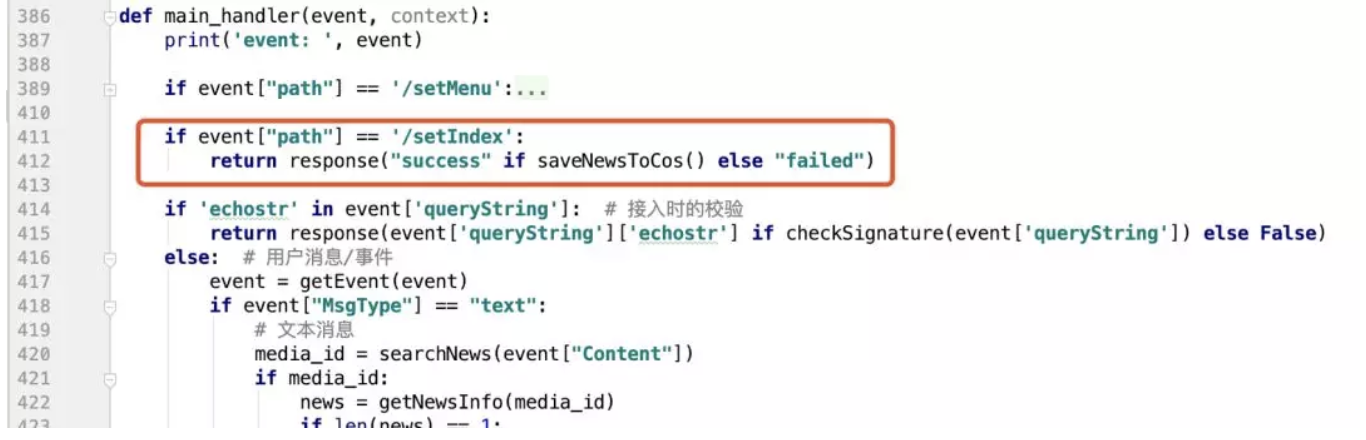
額外優化:
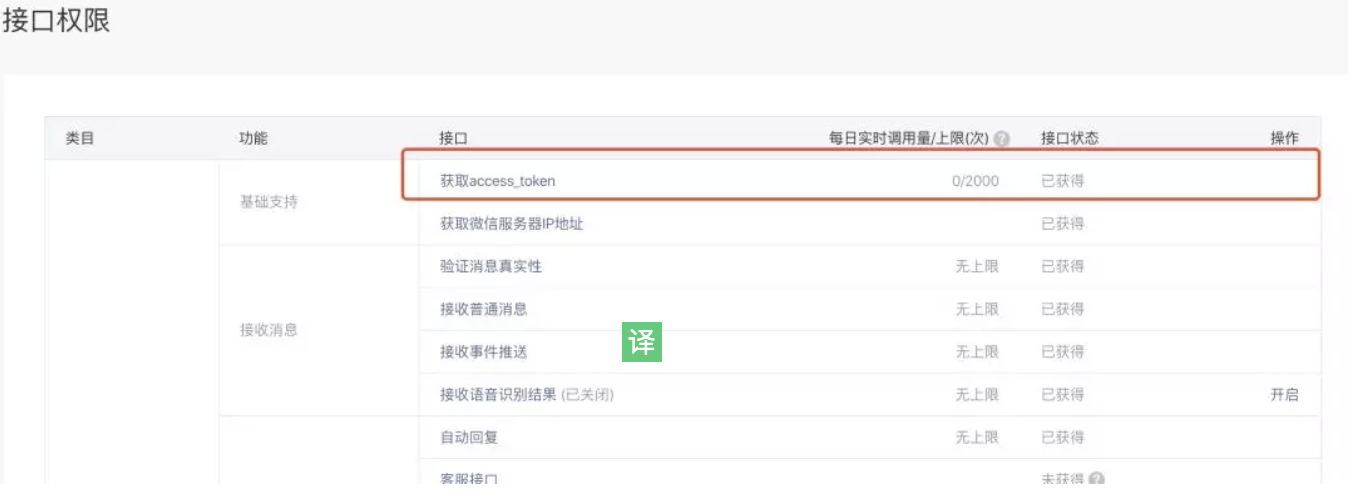
在介面串列中,我們可以看到獲取 accessToken 的介面實際上是有次數限制的,每次獲取有效期兩個小時,所以,我們就要在函式中,對這部分內容做持久化,為了這個小東西,弄一個 MySQL 并不劃算,所以決定用 COS:
def getAccessToken():
'''
檔案地址:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Get_access_token.html
正常回傳:{"access_token":"ACCESS_TOKEN","expires_in":7200}
例外回傳:{"errcode":40013,"errmsg":"invalid appid"}
:return:
'''
global accessToken
# 第一次判斷是判斷本地是否已經有了accessToken,考慮到容器復用情況
if accessToken:
if int(time.time()) - int(accessToken["time"]) <= 7000:
return accessToken["access_token"]
# 如果本地沒有accessToken,可以去cos獲取
try:
response = cosClient.get_object(
Bucket=bucket,
Key=accessTokenKey,
)
response['Body'].get_stream_to_file('/tmp/token.json')
with open('/tmp/token.json') as f:
accessToken = json.loads(f.read())
except:
pass
# 這一次是看cos中是否有,如果cos中有的話,再次進行判斷段
if accessToken:
if int(time.time()) - int(accessToken["time"]) <= 7000:
return accessToken["access_token"]
# 如果此時流程還沒停止,則說明accessToken還沒獲得到,就需要從介面獲得,并且同步給cos
url = "https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=%s&secret=%s" % (appid, secret)
accessTokenResult = json.loads(urllib.request.urlopen(url).read().decode("utf-8"))
accessToken = {"time": int(time.time()), "access_token": accessTokenResult["access_token"]}
print(accessToken)
response = cosClient.put_object(
Bucket=bucket,
Body=json.dumps(accessToken).encode("utf-8"),
Key=accessTokenKey,
EnableMD5=False
)
return None if "errcode" in accessToken else accessToken["access_token"]
當然這段代碼可以繼續優化,這里只是一個思路,
除了利用文本相似度進行圖文檢索,我們還可以利用云廠商提供的 AI 能力,為公眾號增加機器人功能,限于篇幅就先告一段落,感興趣的讀者可以自己探索一下,
總結
至此,我們完成了一個簡單的公眾號開發,通過 Serverless 的原生開發思路(也可以使用 Werobot 等公眾號開發框架),將公眾號后臺服務部署到 Serverless 架構上,再通過自然語言處理技術(特指文本相似度等)實作了一個圖文檢索功能,
Serverless 架構在開發微信公眾號這種事件驅動類的觸發式場景有著很大的優勢,本文也僅僅是一個小探索,更多的功能和應用,能力和價值,還是要看具體業務,希望讀者可以通過本文,對 Serverless 架構有更深入的了解,
Serverless Framework 30 天試用計劃
我們誠邀您來體驗最便捷的 Serverless 開發和部署方式,在試用期內,相關聯的產品及服務均提供免費資源和專業的技術支持,幫助您的業務快速、便捷地實作 Serverless!
詳情可查閱:Serverless Framework 試用計劃
One More Thing
3 秒你能做什么?喝一口水,看一封郵件,還是 —— 部署一個完整的 Serverless 應用?
復制鏈接至 PC 瀏覽器訪問:https://serverless.cloud.tencent.com/deploy/express
3 秒極速部署,立即體驗史上最快的 Serverless HTTP 實戰開發!
傳送門:
- GitHub: github.com/serverless
- 官網:serverless.com
歡迎訪問:Serverless 中文網,您可以在 最佳實踐 里體驗更多關于 Serverless 應用的開發!
推薦閱讀:《Serverless 架構:從原理、設計到專案實戰》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14657.html
標籤:其他