萌新正在學習用Python做爬蟲,但是遇到了個難題在網上也沒搜到解決方法,求大牛指點!
想在鏈家網爬取:租賃方式、房屋型別等資訊,但是鏈家把這個資訊放在了span和li標簽之間,導致它自己是沒有單獨的標簽的,我就不懂怎么提取了。
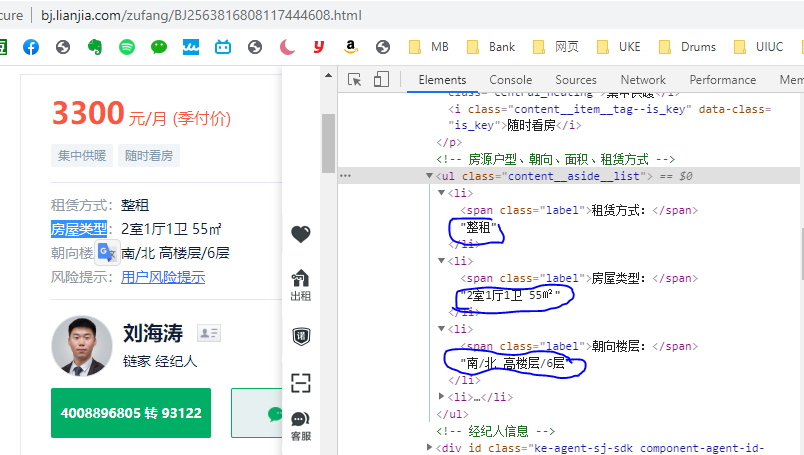
現在寫的代碼如下,求大牛教教我~感謝!就是想知道有沒有除了用切片以外的方式
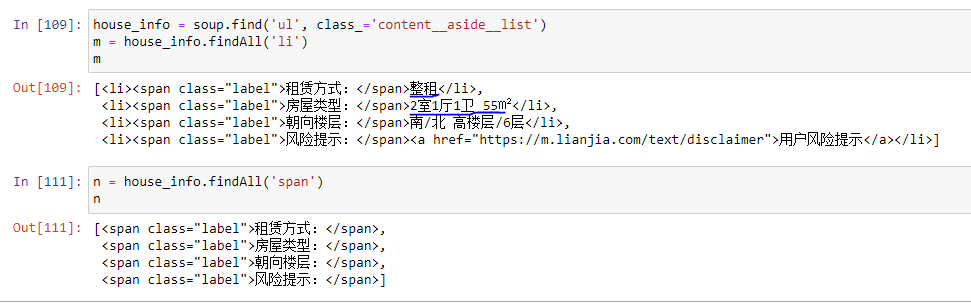
uj5u.com熱心網友回復:
from bs4 import BeautifulSoup
page_source = """
<li><span>房屋型別</span>2室1廳 xxxx</li>"""
soup = BeautifulSoup(page_source, 'html.parser')
item = soup.find_all('li')
print(item[0].contents[1])
uj5u.com熱心網友回復:
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
url = "https://m.lianjia.com/chuzu/bj/zufang/"
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Mobile Safari/537.36"
}
response = requests.get(url=url, headers=headers)
html = response.content.decode("utf8")
soup = BeautifulSoup(html, "html.parser")
for tag in soup.find_all('div', class_='content__item'):
style = str(tag.find_all('p', class_='content__item__content')).\
replace('[<p class="content__item__content">','').\
replace(" ","").replace("\n","").replace("</p>]","")
price = str(tag.find_all('p', class_='content__item__bottom'))[68:120].replace(" ","")
page = tag.find('img').get('alt')
print("{}----{}----{}/元每月".format(page,style,price))
uj5u.com熱心網友回復:
上面是代碼,下面是運行結果,希望能幫到你
uj5u.com熱心網友回復:
我是大致按照你給我說的方式嘗試了一下,思路是一樣的,沒想到成功了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14920.html
上一篇:鋸齒波的分解