最近該期末了,期末作業有點頭蒙!對于一個上課不怎么聽講的人來說,稍稍有點難了。
首先我爬的資訊都差不多了,就是我想知道如何把英文名前后的/ /給刪掉,

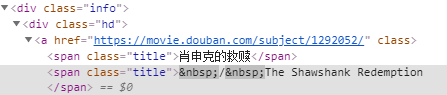

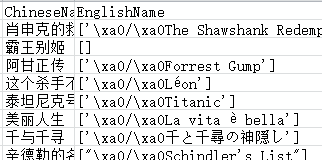
uj5u.com熱心網友回復:
雖然可能你的期末作業結束了...不過我來回復一下吧import requests
from bs4 import BeautifulSoup
def get_movies():
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
,'Host':'movie.douban.com'}
movie_list = []
for i in range(0,10):
url = 'https://movie.douban.com/top250?start=' + str( i * 25) + '&filter='
r = requests.get(url, headers=headers , timeout = 10)
print(str(i+1),'頁回應狀態碼',r.status_code)
soup = BeautifulSoup(r.text,'lxml')
div_list = soup.find_all('div',class_ = 'hd')
for each in div_list:
movie = each.a.contents[3].text.strip()
movie = movie[2:] #通過這個陳述句可以解決問題
movie_list.append(movie)
return movie_list
movies = get_movies()
print(movies)
uj5u.com熱心網友回復:
或者你可以嘗試下:EnglishName = li.xpath('.//a/span[@class='title']'[2]/text)[2:]
uj5u.com熱心網友回復:
哈哈哈,謝謝你啦~雖然真的已經結束了??
uj5u.com熱心網友回復:
好,有時間了我一定會試試!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14926.html
標籤:匯編語言
下一篇:腳本