import json
import requests
from requests.exceptions import RequestException
import re
import time def get_one_page(url): try: headers = { 'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36' } response = requests.get('http://www.24timemap.com/', headers=headers) if response.status_code == 200: return response.text return None except RequestException: return None
def parse_one_page(html): pattern = re.compile('<div.*?>(.*?)</div>.*?(/d+).*?</div>') items = re.findall(pattern,html) for item in items: yield { 'location': item[0], 'time' : item[1] } print(item) write_to_file(item)
def write_to_file(content): with open('r1.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content,ensure_ascii=False)+'\n') time.sleep(1)
uj5u.com熱心網友回復:
pattern = re.compile('<div.*?>(.*?)</div>.*?(/d+).*?</div>')這個就是你要匹配的東西???
恕我直言,這東西任何div標簽有數字的都符合條件
你到要什么東西,能截圖看看嗎
uj5u.com熱心網友回復:
你好,我想獲取的這個網站是一個世界各地區時間的網站,我打算獲取地點還有時間,我以為也是我的正則運算式錯了然后我去了菜鳥工具的正則運算式工具那里檢驗我的正則運算式,是可以獲取我所需要的地點,還有時間。但是跑代碼的時候不可以正常運行,也沒有報錯。uj5u.com熱心網友回復:
你用正則決議這個('<div.*?>(.*?)</div>.*?(/d+).*?</div>'),用xpath決議不是更好,你能發下url嗎
uj5u.com熱心網友回復:
這是按我理解寫的代碼,有些第三方庫你可能沒有,需要你去下載import requests
from fake_useragent import UserAgent
from lxml import etree
if __name__ == '__main__':
url_ = 'http://www.24timemap.com/'
headers_ = {
'User-Agent': UserAgent().random
}
response_ = requests.get(url_, headers=headers_).text
html_response = etree.HTML(response_)
area_ = html_response.xpath('//div[@class="row1"]//li//a[@target="_blank"]/text()')
time_ = html_response.xpath('//div[@class="row1"]//li//i/text()')
area_time = {}
for i in range(len(area_)):
area_time[area_[i]] = time_[i]
print(area_time)
這是我運行結果
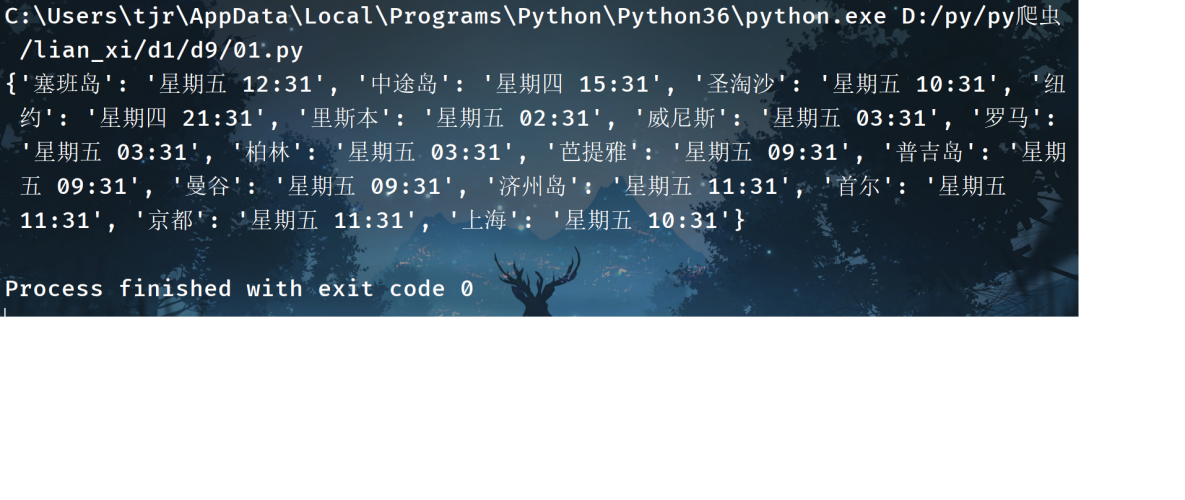
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14929.html
上一篇:求疲勞駕駛資料集