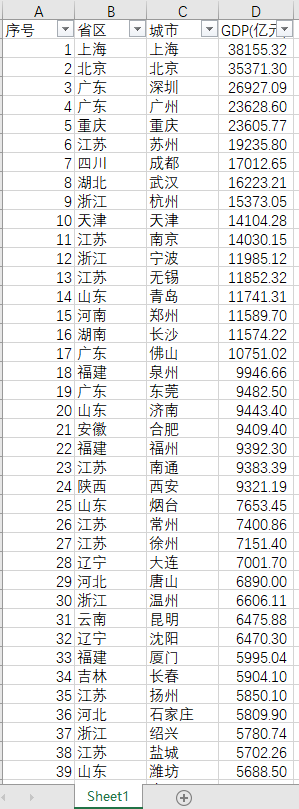
現有一組2019年全國GDP百強城市名單,包含序號,省區,城市,GDP(億元)四個欄位,需要找出每個省區中排名第三位的城市。
規則如下:如果是直轄市,且這個直轄市是GDP100強以內,則輸出該直轄市的記錄;如果不是直轄市,且在100強以內找不到第三名,輸出‘查無結果’;找得到第三名,則輸出第三名城市的記錄
我的代碼撰寫是這樣的:
GDP_Data_2019=pd.read_excel('D:\\python學習\\網易微專業資料分析課程\\python資料分析基礎\\2019年GDP排名100強城市.xlsx')
def top_3(x):
if x['省區'].isin(['上海','北京','天津','重慶']):
return x
elif len(x)<=2:
return '查無結果'
else:
return x.iloc[2,:]
result=GDP_Data_2019.groupby(['省區'])[['城市','GDP(億元)']].apply(top_3)
result
運行result=GDP_Data_2019.groupby(['省區'])[['城市','GDP(億元)']].apply(top_3)這一句的時候報錯KeyError:'省區'
隨后我進行了除錯發現,如果運行GDP_Data_2019.groupby(['省區'])不會報錯,運行result=GDP_Data_2019.groupby(['省區']).agg({'GDP(億元)':'mean'})依然不會報錯,說明代碼中的欄位和資料表是能夠匹配的,現在不知道原因出在哪里了,求大佬指導,感謝~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/149789.html
上一篇:R語言求解方程實根
下一篇:求如何將一行分成很多行