爬取完一個頁面想要做翻頁的操作,但是運行的時候報錯。
代碼如下:
class demo(scrapy.Spider):
name = "demo_spider"
allowed_domain=["books.toscrape.com"]
start_urls = ["http://books.toscrape.com/"]
count = 1
def parse(self, response):
books = response.xpath("//*[@id='default']/div/div/div/div/section/div[2]/ol/li")
for book in books:
title = book.xpath(".//*[@class='product_pod']/div/a/img/@alt")[0].extract()
p_url = book.xpath(".//*[@class='product_pod']/div/a/img/@src")[0].extract()
urllib.request.urlretrieve(url="http://books.toscrape.com/" + p_url,
filename=r"C:\Users\13959\Desktop\tmp\{}.jpg".format(str(self.count)),
reporthook=function)
self.count = self.count + 1
item = DemospiderItem(title=title, p_url=p_url)
yield item
next_page = self.start_urls[0] + Selector(response).re('<a href="https://bbs.csdn.net/topics/(/S*)">next</a>')[0]
#next_page="http://books.toscrape.com/catalogue/page-2.html"
print((next_page+"\n")*10)
if next_page:
yield scrapy.Request(next_page,callback=self.parse)
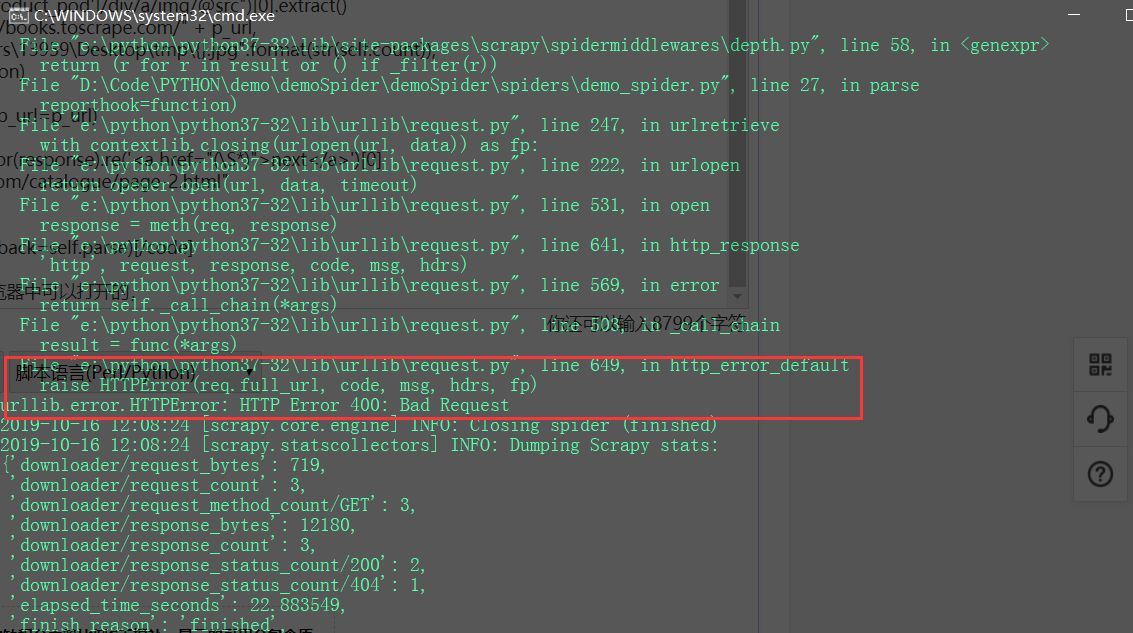
最后一行報錯,這里的next_page的鏈接在瀏覽器中可以打開的。
錯誤資訊如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/150371.html
下一篇:Pycharm中的jupyter顯示“{ "cells": [ { "cell_type": "code",”,怎么辦