我是在學習《TensorFlow:實戰Google深度學習框架》中遇到這個問題。
方法一(簡稱占位符法):在第五章有一個用全連接神經網路訓練Mnist資料集的代碼,用到了學習率遞減,正則化以及取滑動平均值的優化方法,這里用mnist.train.next_batch獲取資料輸入占位符。
方法二(簡稱迭代器法):然后我將mnist的train資料和test轉成TFRecord檔案,再用迭代器進行獲取,再用和上面同樣的訓練模型。
結果相差非常大。如下圖:
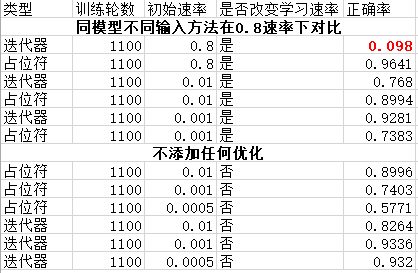
可以看出學習速率在0.8時,兩種方法有巨大的差異。用迭代器法直接就是失敗結果。我以為是我粗心敲錯了代碼,檢查后發現是學習速率太大了,調到0.01會得到較好的結果。但是同樣占位符法用相同的模型卻能達到96%的正確率。我非常困惑。我覺得可能是轉完資料改變了什么。我試過將所有的weight和bias調整seed=1,也不打亂迭代器法中挑選batch中的順序,還將mnist.train.next_batch(BATCH_SIZE,shuffle=False)中打亂順序調成False。而即使是這樣兩種方法出來的資料都是不同的(即取出順序不同)。這對我核對資料帶來很大的困擾。。。。求大神救救我!!!兩種方法為什么會出現這么大的區別。
方法一(占位符法)代碼如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#MNIST資料集相關常數
INPUT_NODE = 784
OUTPUT_NODE = 10
#配置神經網路的引數
LAYER1_NODE = 500 #隱藏層第一層神經元設為五百個
BATCH_SIZE = 100
LEANING_RATE_BASE = 0.8 #基礎學習率
LEARNING_RATE_DECAY = 0.99 #學習率的衰減率
REGULARIZATION_RATE = 0.001 #正則化速率
TRAINING_STEPS = 1100 #訓練輪數
#一個輔助函式,給定神經網路輸入的引數,計算向前傳播結果
def inference(input_tensor, weights1, biases1, weights2, biases2):
#這里用了relu激活函式
layer1 = tf.nn.relu(tf.matmul(input_tensor,weights1)+biases1)
#回傳輸出層這里沒用激活函式,因為后面會用softmax
return tf.matmul(layer1,weights2)+biases2
#模擬訓練程序
def train(mnist):
x=tf.placeholder(tf.float32,[None,INPUT_NODE],name='x-input')
y_=tf.placeholder(tf.float32,[None,OUTPUT_NODE],name='y-input')
#生成隱藏層引數
weight1 = tf.Variable(tf.truncated_normal([INPUT_NODE,LAYER1_NODE],stddev= 0.1,seed=1))
biases1 = tf.Variable(tf.constant(0.1,shape=[LAYER1_NODE]))
#生成輸出層引數
weight2 = tf.Variable(tf.truncated_normal([LAYER1_NODE,OUTPUT_NODE],stddev= 0.1,seed=1))
biases2 = tf.Variable(tf.constant(0.1,shape=[OUTPUT_NODE]))
#----------------計算向前傳播結果-----------
y = inference(x,weight1,biases1,weight2,biases2)
global_step = tf.Variable(0,trainable=False) #不需要訓練,其他的權重和偏向都需要
#-----------------用交叉熵和softmax配合計算損失函式。------
# 這里使用了tf.nn.sparse_softmax_cross_entropy_with_logits函式,
# 第一個引數為不包含softmax的向前傳播結果,第二個是訓練資料的正確答案
corss_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y , labels= tf.argmax(y_,1))
corss_entropy_mean = tf.reduce_mean(corss_entropy)#求均值
#------------------L2正則化的損失函式--------
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
regularization = regularizer(weight1)+regularizer(weight2)
#計算總損失函式
loss = corss_entropy_mean + regularization
#------------------設定學習速率----------------------------------
#這里的除法mnist.train.num_examples/BATCH_SIZE若等于x,則為x迭代才能過完整個訓練集,而這句話意思是進行x次(即整個訓練集結束)才更新一次速率
learning_rate = tf.train.exponential_decay(LEANING_RATE_BASE,global_step,mnist.train.num_examples/BATCH_SIZE,LEARNING_RATE_DECAY)
#-------------梯度下降反向傳播-------
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
#---------------檢驗準確率------------
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1)) #注意,這里用了average_y,上面用了的y。1表示按行輸出最大值得索引值,若是0,則表示按列。
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #tf.cast函式是用于型別轉換為float32
#------------初始化會話并開始訓練程序-----------
with tf.Session() as sess:
tf.global_variables_initializer().run()
#準備驗證資料
validate_feed = {x: mnist.validation.images,y_: mnist.validation.labels}
#準備測驗資料
test_feed = {x: mnist.test.images, y_: mnist.test.labels}
#迭代地訓練神經網路
for i in range (TRAINING_STEPS):
#每1000輪輸出一次在驗證資料集上的測驗結果
if i % 1000 == 0 :
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("After %d training step(s), validation accuracy using average model is %g,"
"test accuracy using average model is %g" % (i, validate_acc,test_acc))
#產生這一輪使用的一個batch的訓練資料,并運行訓練程序。
xs,ys = mnist.train.next_batch(BATCH_SIZE,shuffle=False)
# print((ys))
sess.run([train_step],feed_dict={x:xs,y_:ys})
#訓練結束后輸出在測驗資料上最終正確率
test_acc = sess.run(accuracy, feed_dict =test_feed)
print("基礎學習速率NO CHANGE:", LEANING_RATE_BASE)
print("不含滑動平均值")
print("After %d training step(s), test accuracy using average model is %g" % (TRAINING_STEPS, test_acc))
#---------------------主程式入口----------------------
def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data",one_hot=True)
train(mnist)
#提供一個主程式入口,tf.app.run會呼叫main函式
if __name__=='__main__':
tf.app.run()
方法二(迭代器法)代碼如下:
import tensorflow as tf
# 輸入資料使用本章第一節(1. TFRecord樣例程式.ipynb)生成的訓練和測驗資料。
train_files = tf.train.match_filenames_once("/path/to/MNIST_TF/output.tfrecords")
test_files = tf.train.match_filenames_once("/path/to/MNIST_TF/output_test.tfrecords")
#-------------------------------------------資料集-----------------------------------------------------------
# 決議一個TFRecord的方法。
def parser(record):
features = tf.parse_single_example(
record,
features={
'image_raw':tf.FixedLenFeature([],tf.string),
# 'pixels':tf.FixedLenFeature([],tf.int64),
'label':tf.FixedLenFeature([],tf.int64)
})
decoded_images = tf.decode_raw(features['image_raw'],tf.uint8)
retyped_images = tf.cast(decoded_images, tf.float32)
images = tf.reshape(retyped_images, [784])
labels = tf.cast(features['label'],tf.int32)
#pixels = tf.cast(features['pixels'],tf.int32)
return images, labels
batch_size = 100 # 定義組合資料batch的大小。
shuffle_buffer = 10000 # 定義隨機打亂資料時buffer的大小。
# 定義讀取訓練資料的資料集。
dataset = tf.data.TFRecordDataset(train_files)
dataset = dataset.map(parser)
# 對資料進行shuffle和batching操作。這里省略了對影像做隨機調整的預處理步驟。
dataset = dataset.shuffle(shuffle_buffer,seed=1).batch(batch_size)
# dataset = dataset.batch(batch_size) #不打亂
# 重復NUM_EPOCHS個epoch。間接定義了訓練次數
NUM_EPOCHS = 2
dataset = dataset.repeat(NUM_EPOCHS)
# 定義資料集迭代器。
iterator = dataset.make_initializable_iterator()
image_batch, label_batch = iterator.get_next()
#-------------------------------------------神經網路-----------------------------------------------------------
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
REGULARAZTION_RATE = 0.001 #正則化速率
LEANING_RATE_BASE = 0.001 #基礎學習率
LEARNING_RATE_DECAY = 0.99 #學習率的衰減率
# 定義神經網路的結構以及優化程序。這里與7.3.4小節相同。
def inference(input_tensor, weights1, biases1, weights2, biases2):
# 這里用了relu激活函式
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
# 回傳輸出層這里沒用激活函式,因為后面會用softmax
return tf.matmul(layer1, weights2) + biases2
# 生成隱藏層引數
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1,seed=1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成輸出層引數
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1,seed=1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
y = inference(image_batch, weights1, biases1, weights2, biases2)
global_step = tf.Variable(0, trainable=False) # 不需要在滑動平均的類里訓練,其他的權重和偏向都需要
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=label_batch)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 損失函式的計算
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
regularaztion = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularaztion
# ------------------設定學習速率----------------------------------
# 這里的除法mnist.train.num_examples/BATCH_SIZE若等于x,則為x迭代才能過完整個訓練集,而這句話意思是進行x次(即整個訓練集結束)才更新一次速率
learning_rate = tf.train.exponential_decay(LEANING_RATE_BASE, global_step, 55000 / batch_size,
LEARNING_RATE_DECAY)
# 反向傳播+優化損失函式
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
# train_step = tf.train.GradientDescentOptimizer(LEANING_RATE_BASE).minimize(loss)
#-------------------------------------------測驗-----------------------------------------------------------
# 定義測驗用的Dataset。
test_dataset = tf.data.TFRecordDataset(test_files)
test_dataset = test_dataset.map(parser)
test_dataset = test_dataset.batch(batch_size)
# 定義測驗資料上的迭代器。
test_iterator = test_dataset.make_initializable_iterator()
test_image_batch, test_label_batch = test_iterator.get_next()
# 定義測驗資料上的預測結果。
test_logit = inference(test_image_batch, weights1, biases1, weights2, biases2)
predictions = tf.argmax(test_logit, axis=-1, output_type=tf.int32)
#-------------------------------------------sess-----------------------------------------------------------
# 宣告會話并運行神經網路的優化程序。
with tf.Session() as sess:
# 初始化變數。
sess.run((tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 初始化訓練資料的迭代器。
sess.run(iterator.initializer)
i=0
# 回圈進行訓練,直到資料集完成輸入、拋出OutOfRangeError錯誤。
while True:
try:
i+=1
print(i)
sess.run([train_step])
if i==1:
print(image_batch)
print(image_batch.eval())
except tf.errors.OutOfRangeError:
break
i=0
test_results = []
test_labels = []
# 初始化測驗資料的迭代器。
sess.run(test_iterator.initializer)
# 獲取預測結果。
while True:
try:
pred, label = sess.run([predictions, test_label_batch])
test_results.extend(pred)
test_labels.extend(label)
i+=1
print(i)
except tf.errors.OutOfRangeError:
break
# 計算準確率
correct = [float(y == y_) for (y, y_) in zip(test_results, test_labels)]
accuracy = sum(correct) / len(correct)
print("基礎學習速率 NO CHANGE:", LEANING_RATE_BASE)
print("不含滑動平均值")
print("Test accuracy is:", accuracy)
uj5u.com熱心網友回復:
這是將Mnist轉成TFrecord的代碼:import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 定義函式轉化變數型別。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=https://bbs.csdn.net/topics/[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=https://bbs.csdn.net/topics/[value]))
# 將資料轉化為tf.train.Example格式。
def _make_example(pixels, label, image):
image_raw = image.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'pixels': _int64_feature(pixels),
'label': _int64_feature(np.argmax(label)),
'image_raw': _bytes_feature(image_raw)
}))
return example
# 讀取mnist訓練資料。
mnist = input_data.read_data_sets("/path/to/MNIST_data",dtype=tf.uint8, one_hot=True)
images = mnist.train.images
labels = mnist.train.labels
pixels = images.shape[1]
num_examples = mnist.train.num_examples
# 輸出包含訓練資料的TFRecord檔案。
with tf.python_io.TFRecordWriter("/path/to/MNIST_TF/output.tfrecords") as writer:
for index in range(num_examples):
example = _make_example(pixels, labels[index], images[index])
writer.write(example.SerializeToString())
print("TFRecord訓練檔案已保存。")
# 讀取mnist測驗資料。
images_test = mnist.test.images
labels_test = mnist.test.labels
pixels_test = images_test.shape[1]
num_examples_test = mnist.test.num_examples
# 輸出包含測驗資料的TFRecord檔案。
with tf.python_io.TFRecordWriter("/path/to/MNIST_TF/output_test.tfrecords") as writer:
for index in range(num_examples_test):
example = _make_example(
pixels_test, labels_test[index], images_test[index])
writer.write(example.SerializeToString())
print("TFRecord測驗檔案已保存。")
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/150393.html