這里寫自定義目錄標題
- 前言
- 環境
- 開始前
- 第一步:爬取BUFF的[飾品名字]和[BUFF價格]
- 1.獲取cookie和header
- 2.訪問buff回傳html
- 3.re正則匹配得到[飾品名字]和[BUFF價格]
- 第二步:爬取steam的[steam價格]和[steam24小時售出數量]
- 1.訪問steam回傳html
- 2.re正則匹配得到[steam價格]和[steam24小時售出數量]
- 第三步:對獲得的資料進行處理
- 1.通過[飾品名字]獲得[steam24小時售出數量]
- 2.比較[steam24小時售出數量]判斷洗掉該組還是爬取[steam價格]
- 3.進行洗掉
- 4.保存
- 總結
前言
最近由于steam政策改變,steam禮品卡折上折難搞了,我一直買的那家tb店50$要270¥,在接近8折的條件下還需要提供賬號密碼代充,安全性有待考量,所以想著用py爬蟲爬buff資料和steam資料進行處理,最后得到買賣飾品的折值,以達到等同于禮品卡的效果,
在學習Charles-D的文章后發現他的目的是煉金,其中并不涉及steam的資訊爬取,而puppylpg的文章中對于steam資訊的處理是buff的近七天交易記錄,而折上折的要點在于銷量,所以我又找了一個steam的.jsonhttps://steamcommunity.com/market/priceoverview/?country=CN¤cy=23&appid=570&market_hash_name=Exalted%20Manifold%20Paradox來進行爬取,
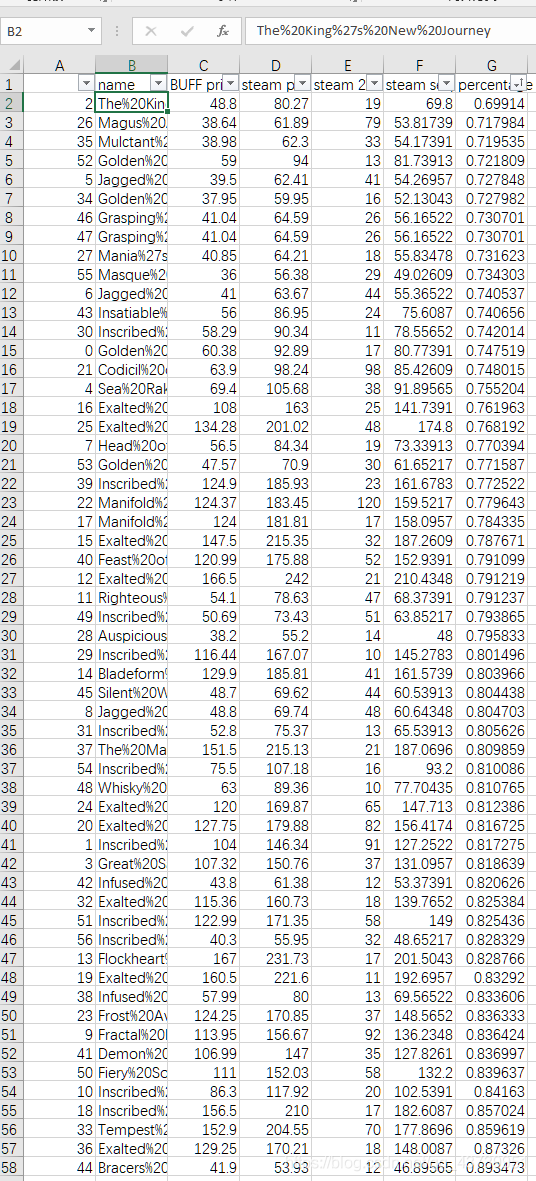
PS.本文例子為dota2,buff上的其余飾品同理
環境
import requests
import re
import pandas as pd
import time
根據我所用到的參考模塊,需要的庫為
requests庫,用于獲取buff及steam的html,安裝教程:
re庫,用于正則匹配獲取所需資料,為內置庫,
pandas庫,用于保存最終結果,安裝教程:
time庫,用于延時(防止被檢測請求過多,得到html為null)、記錄運行時間,為內置庫,
開始前
環境配置完畢后讓我們理一下邏輯,最終得到的結果應該包含[飾品名字]、[BUFF價格]、[steam價格]、[steam24小時售出數量]、[折率],
那么:
第一步——爬取BUFF的[飾品名字]和[BUFF價格],
第二步——爬取steam的[steam價格]和[steam24小時售出數量],
第三步——對獲得的資料進行處理,
第一步:爬取BUFF的[飾品名字]和[BUFF價格]
爬取BUFF資料遇到的第一個問題是登陸
可使用登錄后的cookie進行訪問,
詳細參考
1.獲取cookie和header
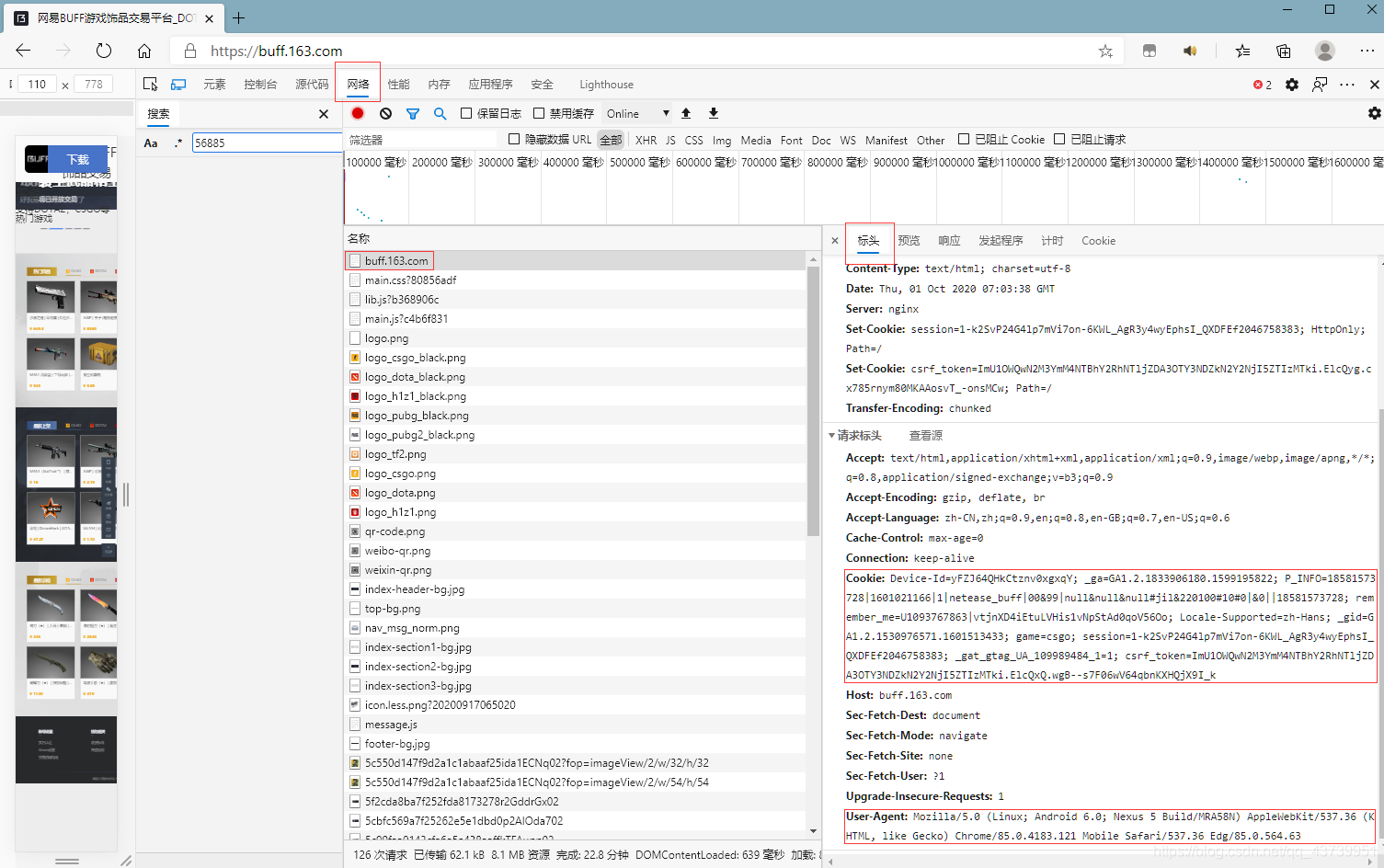
訪問https://buff.163.com/登陸BUFF后按F12打開開發者工具,選中網路+標頭,重繪頁面,找到Cookie和User-Agent
# 表頭
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Mobile Safari/537.36 Edg/85.0.564.63'
}
# BUFF cookie
cookie_str = r'Device-Id=yFZJ64QHkCtznv0xgxqY; _ga=GA1.2.1833906180.1599195822; P_INFO=18581573728|1601021166|1|netease_buff|00&99|null&null&null#jil&220100#10#0|&0||18581573728; remember_me=U1093767863|vtjnXD4iEtuLVHis1vNpStAd0qoV56Oo; Locale-Supported=zh-Hans; _gid=GA1.2.1530976571.1601513433; game=csgo; session=1-k2SvP24G4lp7mVi7on-6KWL_AgR3y4wyEphsI_QXDFEf2046758383; _gat_gtag_UA_109989484_1=1; csrf_token=ImU1OWQwN2M3YmM4NTBhY2RhNTljZDA3OTY3NDZkN2Y2NjI5ZTIzMTki.ElcQxQ.wgB--s7F06wV64qbnKXHQjX9I_k'
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
2.訪問buff回傳html
在BUFF中輸入篩選價格可以幫我們過濾一部分資料,我這里選的35~200,
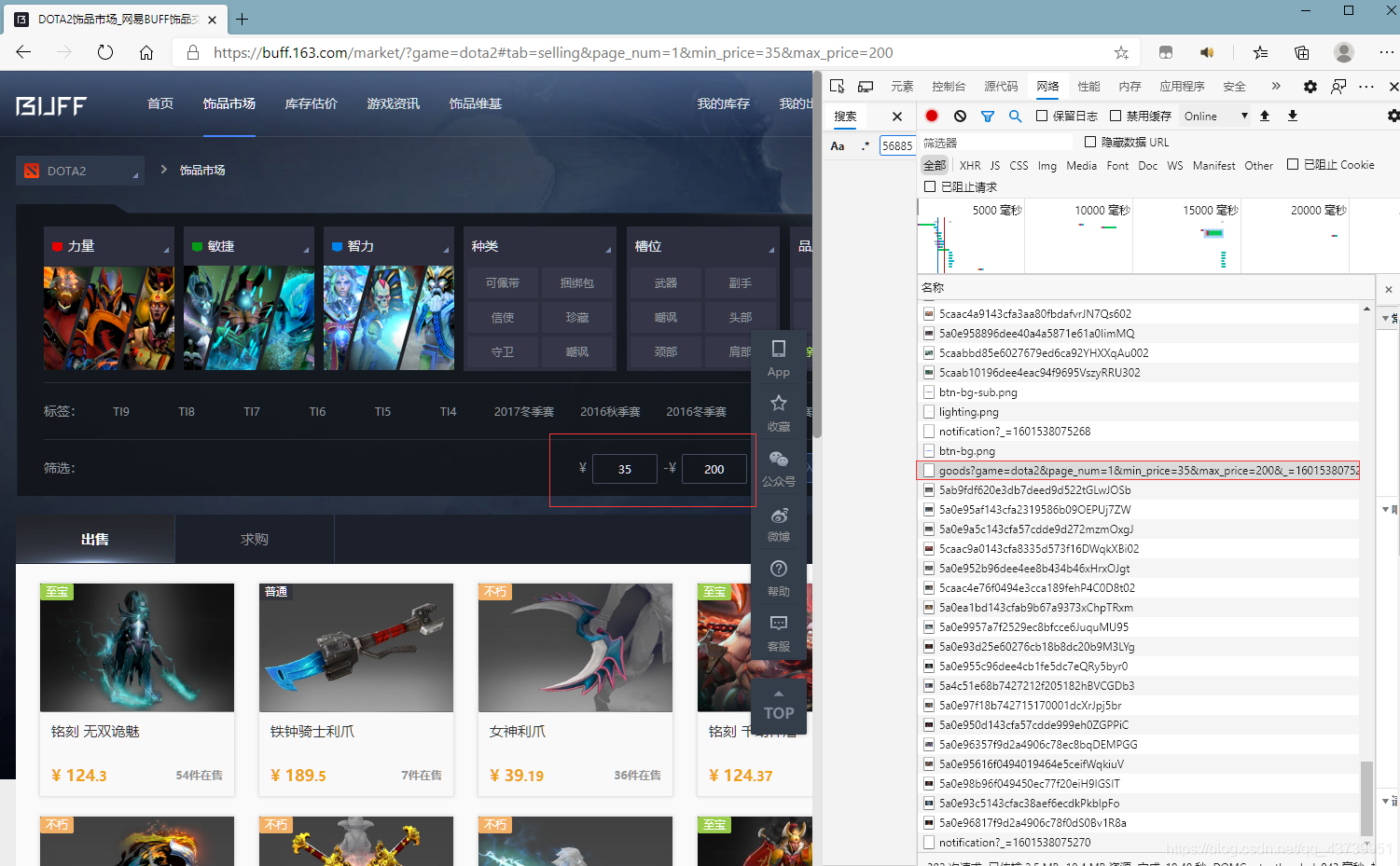
訪問https://buff.163.com/api/market/goods?game=dota2&page_num=1&min_price=35&max_price=200
"items": [
{
"appid": 570,
"bookmarked": false,
"buy_max_price": "131",
"buy_num": 45,
"can_search_by_tournament": false,
"description": null,
"game": "dota2",
"goods_info": {
"icon_url": "https://g.fp.ps.netease.com/market/file/5a0e956d6f049424e570876aRCofBmRW",
"info": {
"tags": {
"hero": {
"category": "hero",
"internal_name": "npc_dota_hero_phantom_assassin",
"localized_name": "\u5e7b\u5f71\u523a\u5ba2"
},
"rarity": {
"category": "rarity",
"internal_name": "arcana",
"localized_name": "\u81f3\u5b9d"
},
"slot": {
"category": "slot",
"internal_name": "weapon",
"localized_name": "\u6b66\u5668"
},
"type": {
"category": "type",
"internal_name": "wearable",
"localized_name": "\u53ef\u4f69\u5e26"
}
}
},
"item_id": 7247,
"original_icon_url": "https://g.fp.ps.netease.com/market/file/59926f895e60273b4cf3f424sv02msLE",
"steam_price": "29.48",
"steam_price_cny": "200.19"
},
"has_buff_price_history": true,
"id": 14575,
"market_hash_name": "Exalted Manifold Paradox",
"market_min_price": "0",
"name": "\u5c0a\u4eab \u65e0\u53cc\u8be1\u9b45",
"quick_price": "131.28",
"sell_min_price": "131.78",
"sell_num": 284,
"sell_reference_price": "131.78",
"steam_market_url": "https://steamcommunity.com/market/listings/570/Exalted%20Manifold%20Paradox",
"transacted_num": 0
},
訪問"steam_market_url":https://steamcommunity.com/market/listings/570/Exalted%20Manifold%20Paradox,正是頁面第一個飾品,
所以我們要訪問的url為https://buff.163.com/api/market/goods?game=dota2&page_num=+i+&min_price=35&max_price=200
for i in range(5):
# 標準url:https://buff.163.com/api/market/goods?game=dota2&page_num=1&min_price=35&max_price=200
buff_dota2_url = 'https://buff.163.com/api/market/goods?game=dota2&page_num=' + str(
i + 1) + '&min_price=35&max_price=200'
buff_dota2_text = requests.get(url=buff_dota2_url, headers=headers, cookies=cookies).text
print(buff_dota2_text)
3.re正則匹配得到[飾品名字]和[BUFF價格]
再利用re正則匹配找到我們需要[飾品名字]和[BUFF價格],
發現[飾品名字跟在"steam_market_url"后面,在https://buff.163.com/api/market/goods?game=dota2&page_num=1&min_price=35&max_price=200中查找"steam_market_url": "https://steamcommunity.com/market/listings/570/(.*)",發現僅有20個,意思就是每個item對應一個,那么這就是[飾品名字]的匹配規則,BUFF價格同理,
關于re.findall的使用參考悲戀花丶無心之人,
for i in range(5):
# 標準url:https://buff.163.com/api/market/goods?game=dota2&page_num=1&min_price=35&max_price=200
buff_dota2_url = 'https://buff.163.com/api/market/goods?game=dota2&page_num=' + str(
i + 1) + '&min_price=35&max_price=200'
buff_dota2_text = requests.get(url=buff_dota2_url, headers=headers, cookies=cookies).text
# 飾品名
names_list_temp = re.findall(r'"steam_market_url": "https://steamcommunity.com/market/listings/570/(.*)",',
buff_dota2_text, re.M)
# BUFF售價
price_list_temp = re.findall(r'"sell_min_price": "(.*)",', buff_dota2_text, re.M)
第二步:爬取steam的[steam價格]和[steam24小時售出數量]
1.訪問steam回傳html
[steam24小時售出數量]我只在庫存中查看物品的時候看見過,所以進入庫存,按F12打開開發者工具,選中網路,重繪頁面后隨便點一個物品,
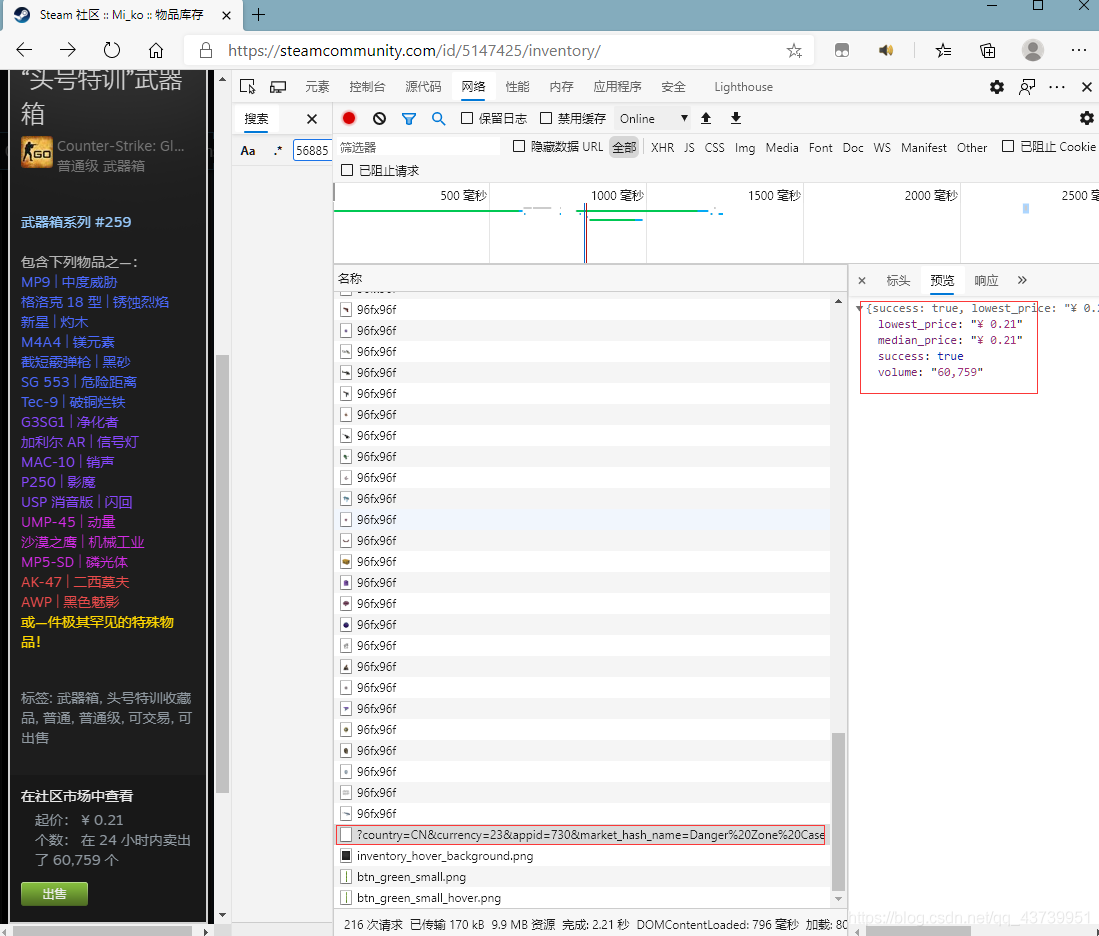
紅框的.json檔案內容正是我們要的內容,
訪問https://steamcommunity.com/market/priceoverview/?country=CN¤cy=23&appid=570&market_hash_name=Exalted%20Manifold%20Paradox
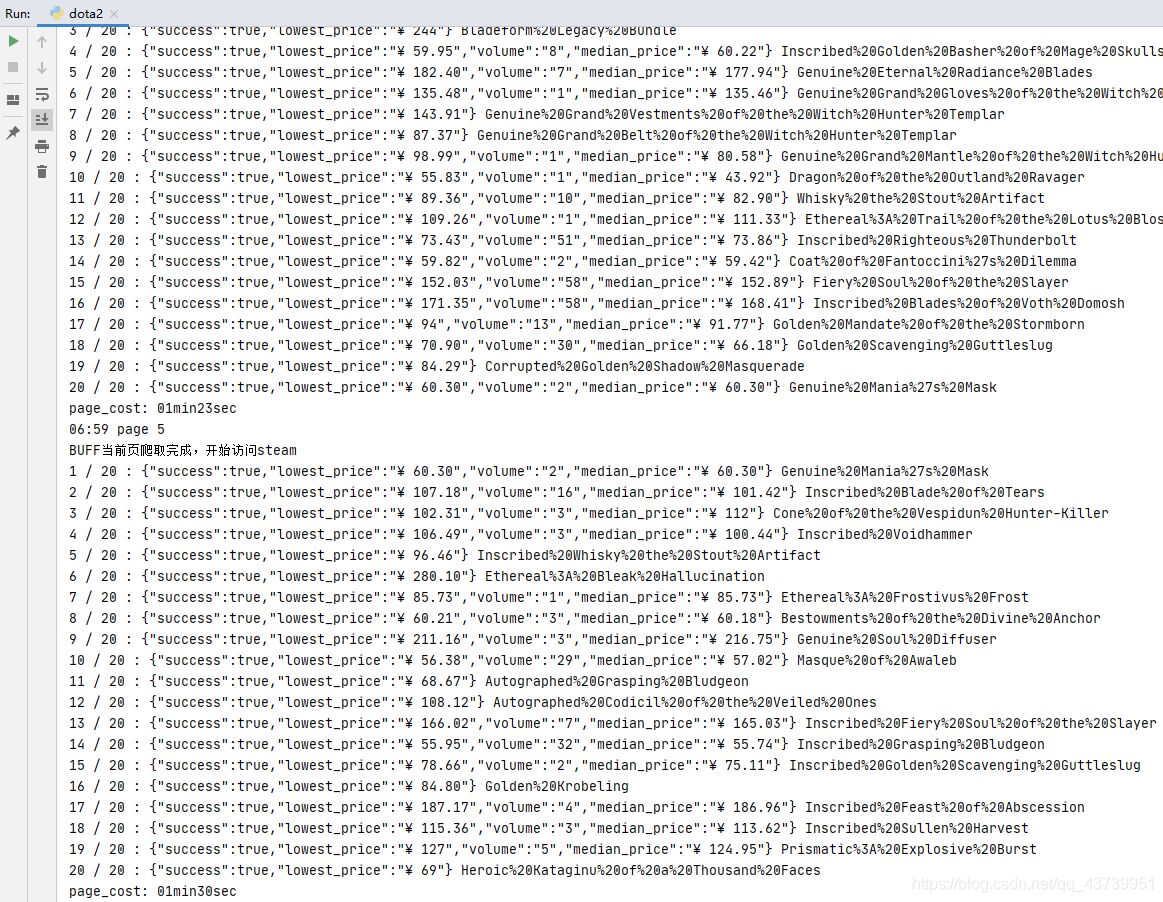
{"success":true,"lowest_price":"¥ 201.02","volume":"64","median_price":"¥ 167.51"}
steam_time = len(names_list_temp)
# 取steam價格和在售數量
for k in range(steam_time):
item = names_list_temp[k]
steam_item_text = requests.get(url=url + item, headers=headers).text
print(steam_item_text)
2.re正則匹配得到[steam價格]和[steam24小時售出數量]
這里注意,re.findall得到的是串列,需要選擇第一個才能進行比較與轉換,
steam_24h_qty = int(re.findall(r'"volume":"([0-9]*)",', steam_item_text, re.M)[0])
price_steam_temp = re.findall(r'"lowest_price":"¥ ([0-9]*.[0-9]*)",', steam_item_text, re.M)[0]
第三步:對獲得的資料進行處理
首先理一下邏輯,已知引數[飾品名字]和[BUFF價格],可通過[飾品名字]獲得[steam價格]和[steam24小時售出數量],當[steam24小時售出數量]<一定值,這組資料就應該被刪去,[steam價格]也不需要爬取,也就是:
1.通過[飾品名字]獲得[steam24小時售出數量]
2.比較[steam24小時售出數量]判斷洗掉該組還是爬取[steam價格]
3.進行洗掉
4.保存
1.通過[飾品名字]獲得[steam24小時售出數量]
steam_time = len(names_list_temp)
# 取steam價格和在售數量
for k in range(steam_time):
item = names_list_temp[k]
steam_item_text = requests.get(url=url + item, headers=headers, cookies=steam_cookies).text
steam_24h_qty_temp = int(re.findall(r'"volume":"([0-9]*)",', steam_item_text, re.M)[0])
2.比較[steam24小時售出數量]判斷洗掉該組還是爬取[steam價格]
cleanlist = []
steam_time = len(names_list_temp)
# 取steam價格和在售數量
for k in range(steam_time):
item = names_list_temp[k]
steam_item_text = requests.get(url=url + item, headers=headers, cookies=steam_cookies).text
print(k + 1, "/", steam_time, ":", steam_item_text, item)
try:
steam_24h_qty_temp = int(re.findall(r'"volume":"([0-9]*)",', steam_item_text, re.M)[0])
except IndexError:
steam_24h_qty_temp = 0
if steam_24h_qty_temp < 10:
cleanlist.append(k)
else:
try:
price_steam_temp0 = re.findall(r'"lowest_price":"¥ ([0-9]*.[0-9]*)",', steam_item_text, re.M)[0]
price_steam_temp.append(price_steam_temp0)
sell_num_list_temp.append(steam_24h_qty_temp)
except IndexError:
cleanlist.append(k)
3.進行洗掉
for k in range(len(cleanlist) - 1, -1, -1):
names_list_temp.pop(cleanlist[k])
price_list_temp.pop(cleanlist[k])
4.保存
for k in range(len(names_list_temp)):
soldprice_temp0 = float(price_steam_temp[k]) / 1.15
percentage_temp0 = float(price_list_temp[k]) / soldprice_temp0
soldprice_temp.append(soldprice_temp0)
percentage_temp.append(percentage_temp0)
# 飾品名
name_list.extend(names_list_temp)
# BUFF價格
price_list.extend(price_list_temp)
# steam價格
price_steam_list.extend(price_steam_temp)
# steam 24小時銷售數量
sell_num_list.extend(sell_num_list_temp)
# 按steam市場最低價售出稅后價格
soldprice.extend(soldprice_temp)
# 折值
percentage.extend(percentage_temp)
# 匯合資訊寫成表格并保存
csv_name = ["name", "BUFF price", "steam price", "steam 24hour sold qty", "steam sellprice", "percentage"]
csv_data = zip(name_list, price_list, price_steam_list, sell_num_list, soldprice, percentage)
items_information = pd.DataFrame(columns=csv_name, data=csv_data)
items_information.to_csv("items_information.csv")
總結
對于steam的訪問需要梯子,不要忘記time.sleep(),如果訪問steam .json回傳為null,可以換個節點,
我自己使用時time.sleep(3),結果爬了幾頁BUFF后steam .json回傳null,一直沒變回來,估計是被ban了,后面time.sleep(5)運行沒問題,
附完整代碼
import requests
import re
import pandas as pd
import time
def main():
time_start = time.time()
# steam appid=750 為 DOTA2
url = r'https://steamcommunity.com/market/priceoverview/?country=CN¤cy=23&appid=570&market_hash_name='
# 表頭
headers = {
'User-Agent': ''
}
# BUFF cookie
cookie_str = r''
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
# 初始化
name_list = []
price_list = []
price_steam_list = []
sell_num_list = []
soldprice = []
percentage = []
for i in range(5):
time_page_start = time.time()
dec = time_page_start - time_start
minute = int(dec / 60)
second = dec % 60
print("%02d:%02d page" % (minute, second), i)
# 標準url:https://buff.163.com/api/market/goods?game=dota2&page_num=1&min_price=35&max_price=200
buff_dota2_url = 'https://buff.163.com/api/market/goods?game=dota2&page_num=' + str(
i + 1) + '&min_price=35&max_price=200'
buff_dota2_text = requests.get(url=buff_dota2_url, headers=headers, cookies=cookies).text
# 飾品名
names_list_temp = re.findall(r'"steam_market_url": "https://steamcommunity.com/market/listings/570/(.*)",',
buff_dota2_text, re.M)
# BUFF售價
price_list_temp = re.findall(r'"sell_min_price": "(.*)",', buff_dota2_text, re.M)
cleanlist = []
price_steam_temp = []
soldprice_temp = []
percentage_temp = []
sell_num_list_temp = []
print("BUFF當前頁爬取完成,開始訪問steam")
steam_time = len(names_list_temp)
# 取steam價格和在售數量
for k in range(steam_time):
item = names_list_temp[k]
steam_item_text = requests.get(url=url + item, headers=headers, cookies=steam_cookies).text
print(k + 1, "/", steam_time, ":", steam_item_text, item)
time.sleep(5)
try:
steam_24h_qty_temp = int(re.findall(r'"volume":"([0-9]*)",', steam_item_text, re.M)[0])
except IndexError:
steam_24h_qty_temp = 0
if steam_24h_qty_temp < 10:
cleanlist.append(k)
else:
try:
price_steam_temp0 = re.findall(r'"lowest_price":"¥ ([0-9]*.[0-9]*)",', steam_item_text, re.M)[0]
price_steam_temp.append(price_steam_temp0)
sell_num_list_temp.append(steam_24h_qty_temp)
except IndexError:
cleanlist.append(k)
for k in range(len(cleanlist) - 1, -1, -1):
names_list_temp.pop(cleanlist[k])
price_list_temp.pop(cleanlist[k])
for k in range(len(names_list_temp)):
soldprice_temp0 = float(price_steam_temp[k]) / 1.15
percentage_temp0 = float(price_list_temp[k]) / soldprice_temp0
soldprice_temp.append(soldprice_temp0)
percentage_temp.append(percentage_temp0)
# 飾品名
name_list.extend(names_list_temp)
# BUFF價格
price_list.extend(price_list_temp)
# steam價格
price_steam_list.extend(price_steam_temp)
# steam 24小時銷售數量
sell_num_list.extend(sell_num_list_temp)
# 按steam市場最低價售出稅后價格
soldprice.extend(soldprice_temp)
# 折值
percentage.extend(percentage_temp)
time_page_end = time.time()
dec = time_page_end - time_page_start
minute = int(dec / 60)
second = dec % 60
print("page_cost: %02dmin%02dsec" % (minute, second))
# 匯合資訊寫成表格并保存
csv_name = ["name", "BUFF price", "steam price", "steam 24hour sold qty", "steam sellprice", "percentage"]
csv_data = zip(name_list, price_list, price_steam_list, sell_num_list, soldprice, percentage)
items_information = pd.DataFrame(columns=csv_name, data=csv_data)
items_information.to_csv("items_information.csv")
if __name__ == "__main__":`在這里插入代碼片`
# 當程式被呼叫執行時,呼叫函式
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/150951.html
標籤:其他