QQ空間自動點贊
- 前景提要
- 目標確定
- 分析介紹
- 登陸獲取cookie
- 尋找XML
- 尋找可變引數
- 獲取第一個空間動態
- 尋找點贊所需的URL
- 尋找可變引數
- 功能提升到秒贊
- 全部代碼
- 最后還是希望你們能給我點一波小小的關注,
- 奉上自己誠摯的愛心💖
前景提要
因為我周圍的小伙伴們天天跟我說的最多的一句話就是:空間第一條點贊,
所以說我還不如直接做一個自動點贊的代碼呢,免得天天催我點贊,
目標確定
- QQ空間秒贊
分析介紹
登陸獲取cookie
首先既然是對 QQ空間的一系列操作,自然是先解決登陸方面,在這篇文章里面我就不過多介紹了,因為我上幾期之前對QQ空間已經做了一定的介紹了,直接放出鏈接就好,歡迎看博主以前的文章
def search_cookie():
qq_number = input('請輸入qq號:')
if not __import__('os').path.exists('cookie_dict.txt'):
get_cookie_json(qq_number)
with open('cookie_dict.txt', 'r') as f:
cookie=json.load(f)
return True
def get_cookie_json(qq_number):
password = __import__('getpass').getpass('請輸入密碼:')
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
login_url = 'https://i.qq.com/'
chrome_options =Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get(login_url)
driver.switch_to_frame('login_frame')
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="u"]').send_keys(qq_number)
driver.find_element_by_xpath('//*[@id="p"]').send_keys(password)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login_button"]').click()
time.sleep(1)
cookie_list = driver.get_cookies()
cookie_dict = {}
for cookie in cookie_list:
if 'name' in cookie and 'value' in cookie:
cookie_dict[cookie['name']] = cookie['value']
with open('cookie_dict.txt', 'w') as f:
json.dump(cookie_dict, f)
return True
def get_g_tk():
p_skey = self.cookie['p_skey']
h = 5381
for i in p_skey:
h += (h << 5) + ord(i)
g_tk = h & 2147483647
尋找XML
當我們拿到cookie資訊和g_tk這個引數之后,繼續去尋找空間好友動態的XML在何處,
首先點到XML位置一個個查找,發現有一個feeds3_html_more很像,點進去發現的確是我們要找的url鏈接,
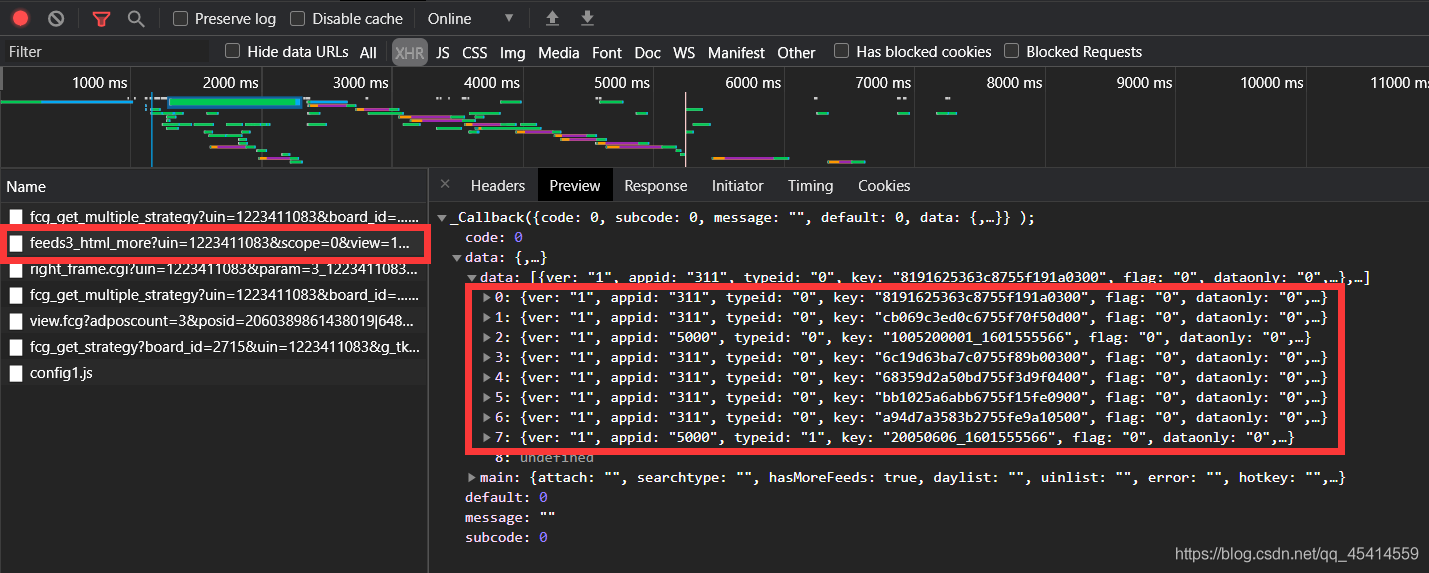
尋找可變引數
這個鏈接所需要的引數有很多,在這里列舉出來
- uin:
- scope:
- view:
- daylist:
- uinlist:
- gid:
- flag:
- filter:
- applist:
- refresh:
- aisortEndTime:
- aisortOffset:
- getAisort:
- aisortBeginTime:
- pagenum:
- externparam:
- firstGetGroup:
- icServerTime:
- mixnocache:
- scene:
- begintime:
- count:
- dayspac:
- sidomain:
- useutf8:
- outputhtmlfeed:
- rd:
- usertime:
- windowId:
- g_tk:
- qzonetoken:
- g_tk:
這些引數中類似于可變引數的一共有五個,
- qzonetoken
- windowId
- rd
- usertime
- g_tk
- qzonetoken 引數在原始碼中是個可變的“定值”,因為每次重繪這個引數都會變,但是原始碼中卻給出了他的具體值,直接獲取即可,
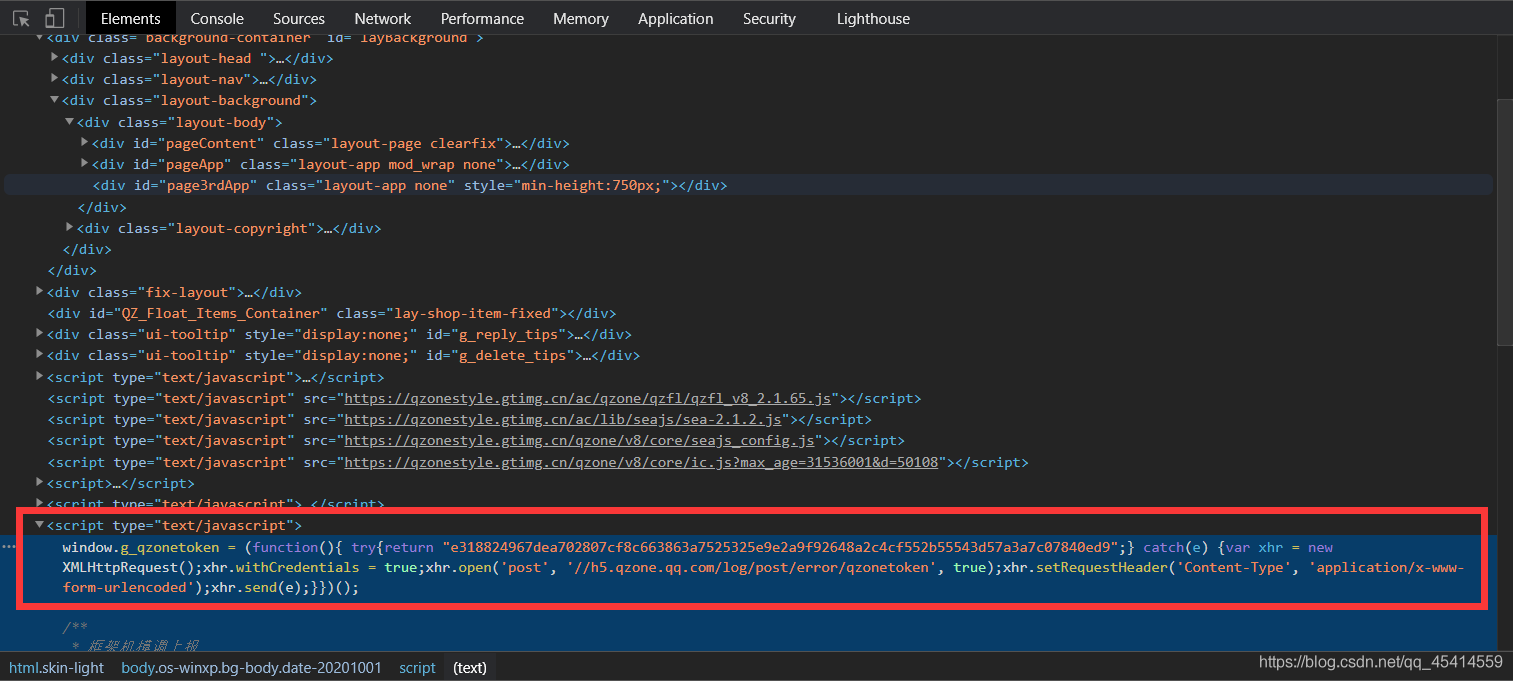
def get_space():
your_url = 'https://user.qzone.qq.com/' + str(qq_number)
html = requests.get(your_url,headers=headers,cookies=cookie)
if html.status_code == 200:
qzonetoken = re.findall('window.g_qzonetoken =(.*?);',html.text,re.S)[1].split('"')[1]
return True
- windowId 與 rd 雖說每次重繪結果都不同,但是經過博主多次實驗得出,這兩個引數對整體并沒有什么影響,可以直接抄下來,
'rd': '0.9311604844249088',
'windowId': '0.51158950324406',
- usertime 引數看似很眼熟,是個時間戳引數,因為位數不對,說明應該是被放大了一千倍,
'usertime': str(round(time.time() * 1000)),
- g_tk 引數上次教程已給出,在JavaScript中分析即可獲得,
def get_g_tk():
p_skey = self.cookie['p_skey']
h = 5381
for i in p_skey:
h += (h << 5) + ord(i)
g_tk = h & 2147483647
獲取第一個空間動態
我們拿到XML以及各個引數后,即可訪問該網頁獲取其回傳值了,
但是這個回傳與其他的有一些不同的是,它不僅僅是個json檔案,我們無法獲取后直接轉換成字典格式去給我們使用,這就很麻煩,
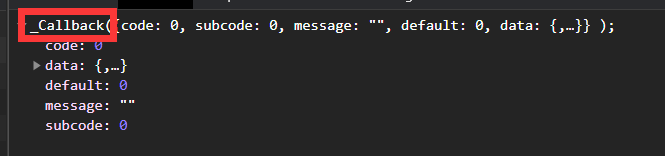
我們獲取字串后,首先先將前后不一致的都切片扔掉,之后經過一系列處理后發現,我們很難將這個看似像json格式的字串轉換成字典,
在這里我繼續介紹一個第三方庫demjson,
demjson 可以解決不正常的json格式資料
demjson的使用方法很簡單,
| encode | 將 Python 物件編碼成 JSON 字串 |
|---|---|
| decode | 將已編碼的 JSON 字串解碼為 Python 物件 |
# 例子
# -*- coding: utf-8 -*-
import demjson
js_json = "{x:1, y:2, z:3}"
py_json1 = "{'x':1, 'y':2, 'z':3}"
py_json2 = '{"x":1, "y":2, "z":3}'
data = demjson.decode(js_json)
print(data)
# {'y': 2, 'x': 1, 'z': 3}
data = demjson.decode(py_json1)
print(data)
# {'y': 2, 'x': 1, 'z': 3}
data = demjson.decode(py_json2)
print(data)
# {'y': 2, 'x': 1, 'z': 3}
我們使用demjson直接將該字串轉換為耳熟能詳的字典格式,提取其中的data的data,即為前八條動態的每個引數,但我們這里只要第一個說說的動態資訊,
text = html.text[10:-2].replace(" ", "").replace('\n','')
json_list = demjson.decode(text)['data']['data']
qq_spaces = json_list[0]
我們拿到其資訊后,先提取一些我們比較想知道的東西,比如名字、QQ號、發布時間、所獲贊數、說說內容、說說地址等等結果,
在 qq_spaces 引數中我們發現里面有一個很長也很特殊的一個結果是 html 結果,這個結果里面很長,簡單來看是個網頁常規代碼,應該是被JavaScript寫入到網頁中了,既然不是全部代碼,那么只能用正則提取一下里面的具體我們需要的東西了,
content = str(qq_spaces['html'])
try:zanshu = re.findall('<spanclass="f-like-cnt">(.*?)</span>人覺得很贊</div>',content,re.S)[0]
except:return None
time_out = str(qq_spaces['feedstime'])
print("名字:"+str(qq_spaces['nickname']))
print("QQ號:"+str(qq_spaces['opuin']))
print("時間:"+time_out)
print('贊數:'+zanshu)
times = qq_spaces['abstime']
his_url = re.findall('data-curkey="(.*?)"',content,re.S)[0]
尋找點贊所需的URL
在QQ空間隨便找個好友點個贊吧,這樣我們才能接收到請求,
我們首先清空原來動態產生的抓包,直接點個贊發現關于dolike的url只有三個,第一個是個POST請求,應該是我們所需要的點贊網址,

尋找可變引數
我們獲取到URL后,找到里面所需要的引數,發現一共有十一個引數,在這里猜測應該不存在加密引數,
- qzreferrer引數為自己QQ空間的網址,表示從哪里來的鏈接地址,
- opuin引數為自己的QQ號,可以直接在代碼提取,
- unikey引數與curkey引數為被點贊方的鏈接,即說說鏈接,剛才已獲取,
- abstime引數為被點贊方說說的發布時間的時間戳,
- fid引數為被點贊方的鏈接后綴,
既然引數沒什么問題那就直接寫代碼吧,
def get_zan(times,his_url):
data = {'g_tk': g_tk,'qzonetoken': qzonetoken}
post_data = {
'qzreferrer': 'https://user.qzone.qq.com/'+str(qq_number),
'opuin': str(qq_number),
'unikey': str(his_url),
'curkey': str(his_url),
'from': '1',
'appid': '311',
'typeid': '0',
'abstime': str(times),
'fid': str(his_url).split('/')[-1],
'active': '0',
'fupdate': '1'
}
url = 'https://user.qzone.qq.com/proxy/domain/w.qzone.qq.com/cgi-bin/likes/internal_dolike_app?'
url = url + urllib.parse.urlencode(data)
html = requests.post(url,headers=headers,cookies=cookie,data=post_data)
if html.status_code == 200:print("點贊成功" if len(html.text) == 469 else "點贊失敗")
功能提升到秒贊
因為樹莓派并不是很不錯的問題,這個代碼做不到絕對的秒贊,
- 在本地建立一個檔案,負責寫入最后一條說說所產生的時間戳,
- 比對當前時間戳與空間第一條說說是否相同,若相同則無更新,
- 點贊后重寫檔案,以便下次使用代碼即可秒贊,
def run_tolike():
if os.path.exists('time_out.txt'):
with open('time_out.txt','r') as f:
time_out = f.read()
else:time_out = None
while True:
get_friends_list()
time.sleep(__import__('random').randint(0,5)) # 秒贊?
if not time_out or time_out != time_out:
time_out = time_out
get_zan(times,his_url)
return True
else:log('說說無更新,等待中...')
with open('time_out.txt','w') as f:
f.write(str(times))
全部代碼
import time,os,json
import re
import demjson
import urllib
import requests
from lxml import etree
def log(content):
this_time = time.strftime('%H:%M:%S',time.localtime(time.time()))
print("["+str(this_time)+"]" + content)
class QQ_like:
def __init__(self,qq_number):
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
self.qq_number = qq_number
self.get_preparameter()
self.run_tolike()
def get_preparameter(self):
self.search_cookie()
self.get_g_tk()
self.get_space()
def run_tolike(self):
if os.path.exists('time_out.txt'):
with open('time_out.txt','r') as f:
self.time_out = f.read()
else:self.time_out = None
while True:
self.get_friends_list()
time.sleep(__import__('random').randint(0,5))
def search_cookie(self):
if not os.path.exists('cookie_dict.txt'):
self.get_cookie_json()
with open('cookie_dict.txt', 'r') as f:
self.cookie=json.load(f)
return True
def get_cookie_json(self):
password = __import__('getpass').getpass('請輸入密碼:')
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
login_url = 'https://i.qq.com/'
chrome_options =Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get(login_url)
driver.switch_to_frame('login_frame')
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="u"]').send_keys(self.qq_number)
driver.find_element_by_xpath('//*[@id="p"]').send_keys(password)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login_button"]').click()
time.sleep(1)
cookie_list = driver.get_cookies()
cookie_dict = {}
for cookie in cookie_list:
if 'name' in cookie and 'value' in cookie:
cookie_dict[cookie['name']] = cookie['value']
with open('cookie_dict.txt', 'w') as f:
json.dump(cookie_dict, f)
return True
def get_g_tk(self):
p_skey = self.cookie['p_skey']
h = 5381
for i in p_skey:
h += (h << 5) + ord(i)
self.g_tk = h & 2147483647
def get_space(self):
your_url = 'https://user.qzone.qq.com/' + str(self.qq_number)
html = requests.get(your_url,headers=self.headers,cookies=self.cookie)
if html.status_code == 200:
self.qzonetoken = re.findall('window.g_qzonetoken =(.*?);',html.text,re.S)[1].split('"')[1]
return True
def get_friends_list(self):
times = ""
url = "https://user.qzone.qq.com/proxy/domain/ic2.qzone.qq.com/cgi-bin/feeds/feeds3_html_more?"
data = {
'uin': self.qq_number,
'scope': '0',
'view': '1',
'daylist': '',
'uinlist': '',
'gid': '',
'flag': '1',
'filter':'all',
'applist': 'all',
'refresh': '0',
'aisortEndTime': '0',
'aisortOffset': '0',
'getAisort': '0',
'aisortBeginTime': '0',
'pagenum': '1',
'externparam': 'undefined',
'firstGetGroup': '0',
'icServerTime': '0',
'mixnocache': '0',
'scene': '0',
'begintime': 'undefined',
'count': '10',
'dayspac': 'undefined',
'sidomain': 'qzonestyle.gtimg.cn',
'useutf8': '1',
'outputhtmlfeed': '1',
'rd': '0.9311604844249088',
'usertime': str(round(time.time() * 1000)),
'windowId': '0.51158950324406',
'g_tk': self.g_tk,
'qzonetoken': self.qzonetoken,
}
url = url + urllib.parse.urlencode(data) + '&g_tk=' + str(self.g_tk)
html = requests.get(url,headers=self.headers,cookies=self.cookie)
if html.status_code == 200:
text = html.text[10:-2].replace(" ", "").replace('\n','')
json_list = demjson.decode(text)['data']['data']
qq_spaces = json_list[0]
content = str(qq_spaces['html'])
try:zanshu = re.findall('<spanclass="f-like-cnt">(.*?)</span>人覺得很贊</div>',content,re.S)[0]
except:return None
time_out = str(qq_spaces['feedstime'])
log("名字:"+str(qq_spaces['nickname']))
log("QQ號:"+str(qq_spaces['opuin']))
log("時間:"+time_out)
log('贊數:'+zanshu)
times = qq_spaces['abstime']
his_url = re.findall('data-curkey="(.*?)"',content,re.S)[0]
if not self.time_out or self.time_out != time_out:
self.time_out = time_out
self.get_zan(times,his_url)
return True
else:log('說說無更新,等待中...')
else:log(html.status_code)
def get_zan(self,times,his_url):
data = {'g_tk': self.g_tk,'qzonetoken': self.qzonetoken}
post_data = {
'qzreferrer': 'https://user.qzone.qq.com/'+str(qq_number),
'opuin': str(qq_number),
'unikey': str(his_url),
'curkey': str(his_url),
'from': '1',
'appid': '311',
'typeid': '0',
'abstime': str(times),
'fid': str(his_url).split('/')[-1],
'active': '0',
'fupdate': '1'
}
url = 'https://user.qzone.qq.com/proxy/domain/w.qzone.qq.com/cgi-bin/likes/internal_dolike_app?'
url = url + urllib.parse.urlencode(data)
html = requests.post(url,headers=self.headers,cookies=self.cookie,data=post_data)
if html.status_code == 200:log("點贊成功" if len(html.text) == 469 else "點贊失敗")
with open('time_out.txt','w') as f:
f.write(str(times))
if __name__ == "__main__":
qq_number = input('請輸入qq號:')
QQ_like(qq_number)
最后還是希望你們能給我點一波小小的關注,
奉上自己誠摯的愛心💖
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/150963.html
標籤:其他