理解可變自動編碼器背后的原理
? 生成模型是機器學習中一個有趣的領域,在這個領域中,網路學習資料分布,然后生成新的內容,而不是對資料進行分類,生成建模最常用的兩種方法是生成對抗網路(GAN)和可變自編碼器(VAE),在這篇文章中,我將嘗試解釋可變自動編碼器(VAE)背后的原理,以及它是如何生成上述面的資料的,
自編碼器(AE)
? 我們將首先討論自動編碼器,Auto Encoder是一種自監督的神經網路,它學習如何將輸入編碼為更低的維數,然后再次解碼和重構資料以盡可能有效地接近輸入,
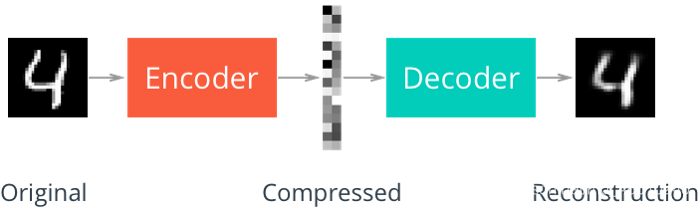
? Autoencoder由3個部分組成:
- 編碼器,將輸入資料編碼為較低維表示的層,
- 壓縮層,包含編碼/壓縮表示的最低維數的層,也被稱為瓶頸,
- 譯碼器,學會解碼或重新構造編碼表示到資料的層接近輸入資料,
? 為了學習最好的編碼和解碼,自編碼器的目標是使重構誤差最小化,重構誤差基本上是重構資料和輸入資料之間的差值,
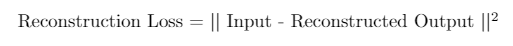
? 注意,我們使用L2(平方)重建損失而不是L1,如果你想知道選擇L2而不是L1背后的原理,
什么是自動編碼器?
? 您可能認為自動編碼器將用于壓縮影像,但令人驚訝的是,它在壓縮領域不是很流行,因為壓縮演算法的性能仍然更好,相反,這些是一些通用應用的自動編碼器功能:
- 去噪:為了使自動編碼器學會去噪影像,我們使用一個損壞或有噪聲的影像作為輸入,然后修改重建損失,使重建輸出與原始干凈的影像之間的差異最小,而不是損壞的輸入,編碼器的目標是只編碼有用的特征,因此,隨機噪聲應在重建程序中丟失,
- 降維:通過使用輸出層比輸入層有更少維數的“不完全”自動編碼器,自動編碼器能夠在更低維數的情況下非線性地表示資料,這與有限的線性變換的PCA(主成分分析)方法形成對比,
? 但是,如果我們想讓我們的自動編碼器生成新的資料,而不是僅僅給出一個類似的輸出作為輸入呢?我們將在下一節討論這個問題,
自動編碼器生成新的資料
? 使用Autoencoder生成新資料背后的想法是通過修改編碼的資料(潛在向量),我們應該能夠得到不同于輸入的資料,為了簡化這一點,讓我們想象一下這樣的場景:您試圖將一些影像編碼為2d編碼,如下所示,
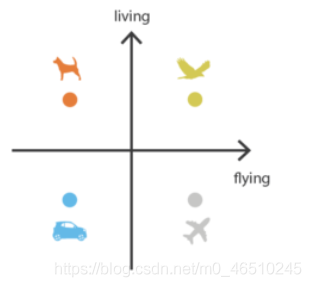
? 現在,為了生成一個新的影像,我們可以簡單地從上面的潛在空間中采樣一個點,例如,如果我們對狗和鳥之間的一個點進行采樣,我們可能能夠得到一張鳥和狗雜交的影像,或者一種新的動物,
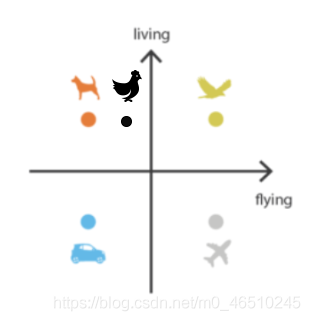
? 然而,編碼器生成的向量(編碼)往往是不規則的、無組織的或不可解釋的,因為它的目的只是重構盡可能相似的輸入,而本身沒有任何約束,因此,它不關心如何編碼資料,只要它能完美地重構輸入,
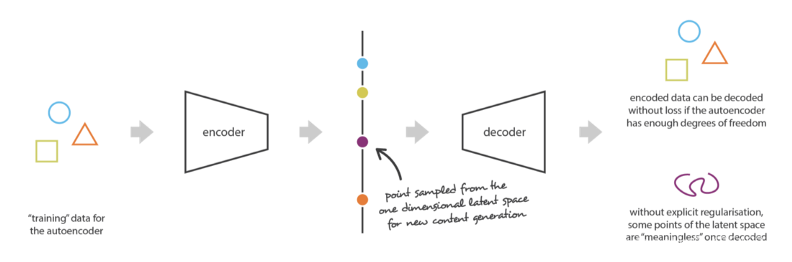
? 由于自動編碼器模型可以自由地編碼潛在向量,潛在空間可能會有很多區域,其中的空白區域會產生隨機/不可解釋的輸出,如圖中的空白區域所示,相反,我們希望具有有意義輸出的潛在空間區域是連續的,而不是像下圖那樣是分開的,這樣可以方便地在不同屬性之間進行插值,
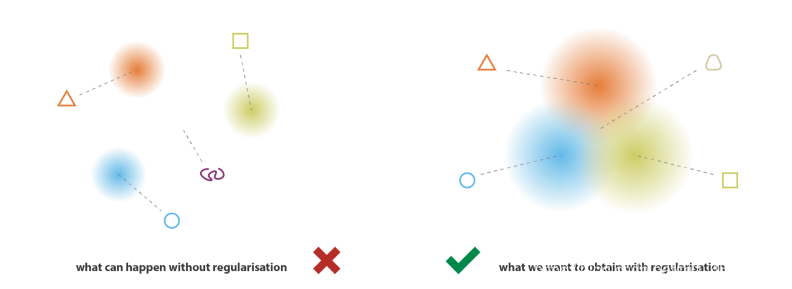
? 因此,可變自動編碼器試圖通過添加調節器來解決這一問題,避免過擬合,并確保潛在空間具有良好的連續性特征,使生成程序成為可能,
可變自動編碼器(VAE)
? 可變自動編碼器能夠通過正則化潛在空間,使其像下面這樣連續地生成新的資料,因此,允許在不同屬性之間實作平滑的插值,并消除可能回傳不理想輸出的間隙,

? 但是VAE是如何將模型優化成這樣的呢?

? 可變自動編碼器以概率方式(分布)編碼輸入的潛在屬性,而不是像普通的自動編碼器那樣以確定性方式(單值)編碼,

? 想象一下上面的例子,自動編碼器將影像編碼為表示照片中的微笑的潛在屬性(注意,在真實的訓練中,我們不知道每個屬性實際表示什么),普通的自動編碼器將為潛屬性提供一個值,但變分自動編碼器將潛屬性存盤為屬性的概率分布,如上面的右圖所示,
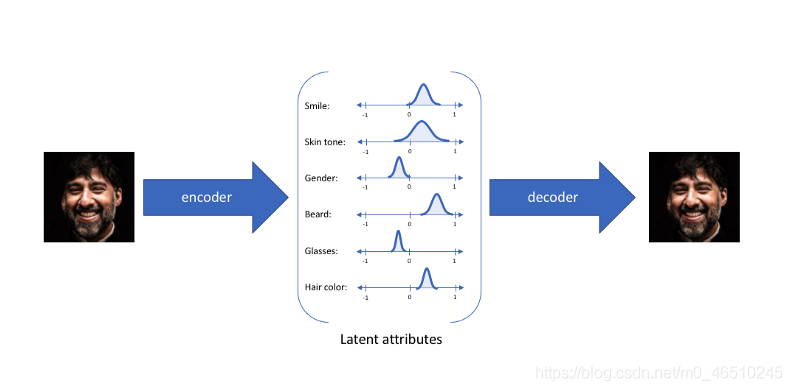

? 現在,由于我們有了每個屬性的概率分布,我們可以簡單地從分布中抽取任何值來生成一個新的輸出,
如何存盤分布?
? 當我知道VAE將潛在變數存盤為概率分布時我首先想到的問題是如何存盤一個分布,
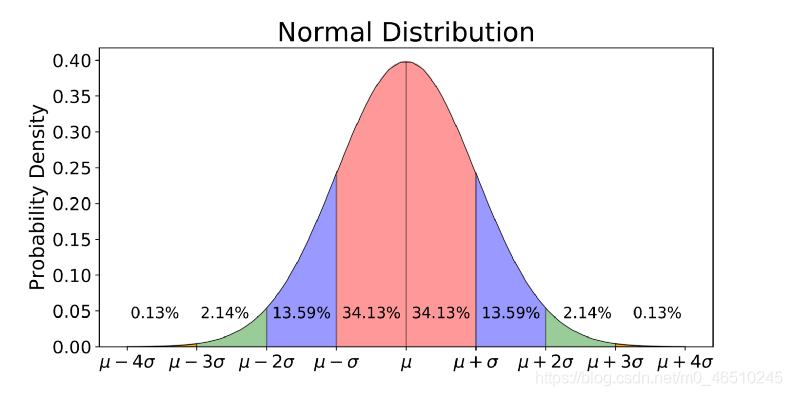
? 我們做了一個重要的假設來簡化這個程序,我們假設潛在分布總是高斯分布,高斯分布可以很容易地用兩個值來描述,即均值和方差或標準差(您可以從方差計算出標準差),
? 現在,我們的編碼器將輸出我們想要的每個潛在維度的均值和方差,并從分布中抽取z來生成新的資料,
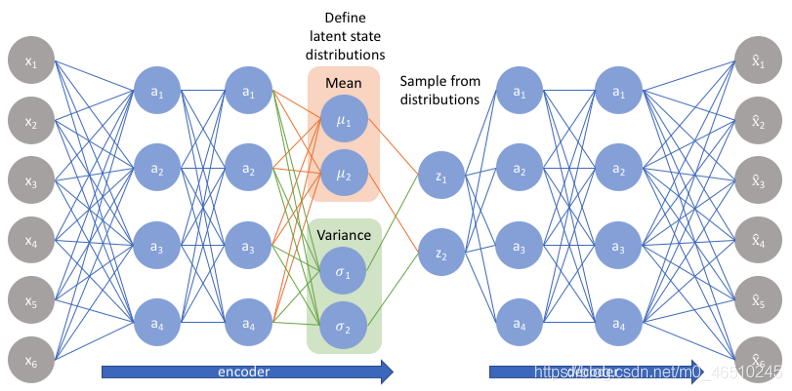
數學細節
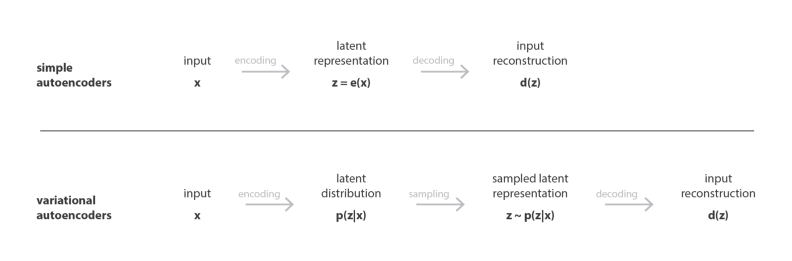
? 現在我們將深入研究VAE的實施,我們將把x表示為輸入資料,把z表示為潛在變數(編碼表示),在普通的自編碼器中,編碼器將輸入x轉換為潛在變數z,而解碼器將z轉換為重構的輸出,而在可變自編碼器中,編碼器將x轉換為潛在變數p(z|x)的概率分布,然后對潛在變數z隨機采樣,再由解碼器解碼成重構輸出,
? 為了計算潛在分布p(z|x),可以利用貝葉斯公式得到
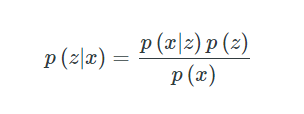
其中
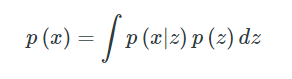
? 不幸的是,計算p(x)是困難的,它通常是一個棘手的分布,這意味著它不能以封閉形式表示,這個問題不能用多項式演算法來解決,
? 因此,我們將用可變推理方法來近似分布,基本上,我們將選擇一些其他易于處理的分布q來近似分布p,為了做到這一點,我們希望q(z|x)的引數與p(z|x)非常相似,
Kullback Leibler散度(kl -散度)
? 為了使q(z|x)與p(z|x)相似,我們使用Kullback Leibler散度(kl -散度)最小化并計算兩個分布之間的差值,kl散度是兩個分布之間差異的度量,理解kl散度最簡單的方法是通過可視化下圖,
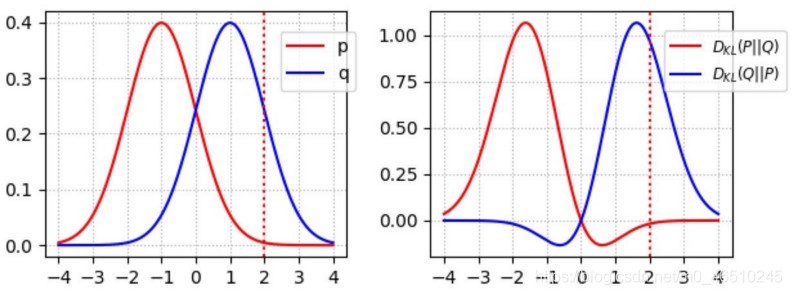
? 從圖中可以看出,在相同分布的交點處,kl -散度為0,因此,通過最小化kl散度,我們使這兩個分布盡可能地相似,
? 最后,我們可以定義我們的損失函式如下,
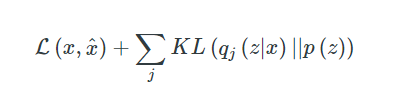
? 第一項是重構損失,即重構輸出與輸入之間的差值,通常使用均方誤差(MSE),第二項是真實分布p(z)與我們選擇的分布q(z|x)之間的kl散度,其中q通常是一個均值和單位方差為零的正態分布N(0,1),鼓勵分布q(z|x)在訓練中接近真實分布p(z),
為什么同時使用重構損失和kl散度?
? 在討論了kl散度之后,為什么我們仍然在整體損失函式中使用重構損失呢?為了理解損失函式背后的原理,以及重構損失和KL散度對潛在空間的影響,讓我們看看下面的圖表,
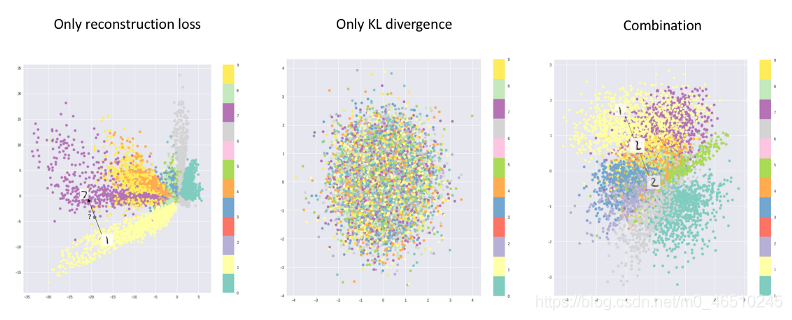
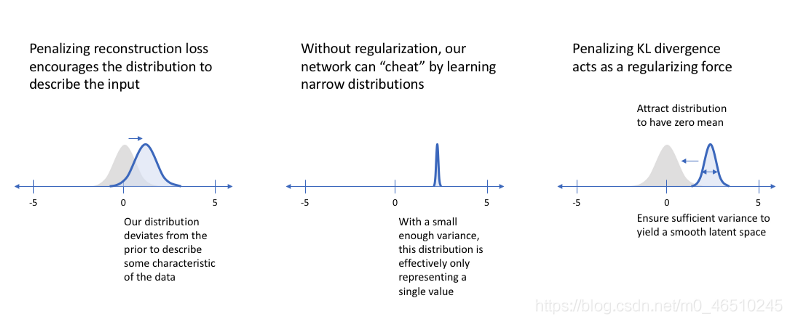
? 只使用重構損失時潛在空間內部將有空隙,不真正代表任何有意義的資料,因此,可變自動編碼器使用分布而不是最小的差異與kl -散度,但是,如果我們只專注于用我們的kl -散度損失項模擬先驗分布,我們將會將每個單位描述為單位正態分布,而不能描述原始資料,
? 因此,通過使用兩者的組合,我們將獲得一個平衡,即擁有一個接近先驗分布但仍然描述輸入的某些特征的潛在表示,
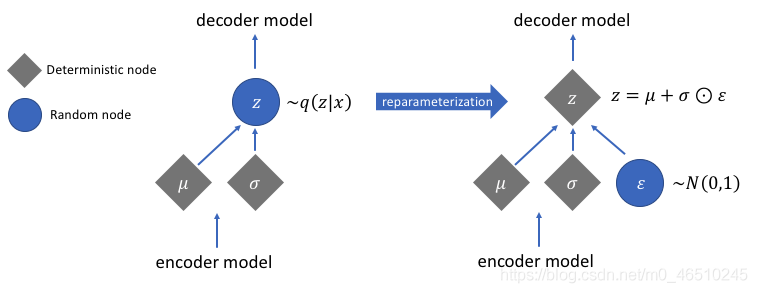
重新引數化
? 在實作變分自動編碼器時,您可能面臨的一個問題是實作采樣程序,在訓練模型時,由于隨機采樣,不能進行反向傳播,但是,我們可以使用一種稱為“重新引數化”的技巧,通過分離隨機行程來允許反向傳播發生,
? “再引數化技巧”是一種從單位正態分布中隨機抽取單位的方法,將其與方差相乘,然后將其移至平均值,如下圖所示,
最近與VAE相關的作業
? 雖然可變自編碼器網路能夠產生新的內容,但輸出往往是模糊的,生成對抗網路(GAN)是構建生成模型的另一種方法,由于它能夠生成更清晰的影像,盡管它在訓練程序中可能相當不穩定,但它已經更受歡迎,
? 然而,最近從 NVIDIA發表的論文,NVAE:一個深度分級變分自動編碼器,介紹了一種使用CelebA HQ的新的架構設計的VAE和管理生產高質量的面,

? 此外,還有一種將自動編碼器與GAN(如VAE-GAN和AAE)結合起來的想法,對抗式自動編碼器(AAE)是一種類似于VAE的方法,但將kl -散度損失替換為對抗式損失,并已用于某些方面,如例外檢測,總之,VAE仍然值得研究,并且在某些用例中非常適用,
鳴謝
? 我非常感謝Joseph Rocca和Jeremy Jodan,他們的文章解釋了可變自動編碼器的原理,他們的可視化輔助在幫助我理解和形象化概念方面非常有用,這些是我希望在未來能夠制作的視覺輔助和清晰度,
參考
[1] Joseph Rocca. (2019). Understanding Variational Autoencoders (VAEs). Towards Data Science.
[2] Jeremy Jodan. (2018). Variational autoencoders. Jeremy Jodan.
[3] Jonothan Hui. (2018). GAN — Why it is so hard to train Generative Adversarial Networks!. Medium.
[4] Vahdat, A., & Kautz, J. (2020). NVAE: A Deep Hierarchical Variational Autoencoder. arXiv preprint arXiv:2007.03898.
本文演示地址:https://houxianxu.github.io/assets/project/dfcvae
VAE代碼:https://github.com/udacity/deep-learning/blob/master/autoencoder/Simple_Autoencoder_Solution.ipynb
作者:Fathy Rashad
deephub翻譯組:孟翔杰
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/151005.html
標籤:其他