程序性編程和面向物件編程的區別
之前在那篇博客上看到這個比喻,覺得特別恰當,挺容易讓人理解的,現在分享一下:
用面向程序的方法寫出來的程式是一份蛋炒飯,而用面向物件寫出來的程式是一份蓋澆飯,所謂蓋澆飯,北京叫蓋飯,東北叫燴飯,廣東叫碟頭飯,就是在一碗白米飯上面澆上一份蓋菜,你喜歡什么菜,你就澆上什么菜,我覺得這個比喻還是比較貼切的,
蛋炒飯制作的細節,我不太會做飯,不太清楚,但最后的一道工序肯定是把米飯和雞蛋混在一起炒勻,蓋澆飯呢,則是把米飯和蓋菜分別做好,你如果要一份紅燒肉蓋飯呢,就給你澆一份紅燒肉;如果要一份青椒土豆蓋澆飯,就給澆一份青椒土豆絲,
蛋炒飯的好處就是入味均勻,吃起來香,如果恰巧你不愛吃雞蛋,只愛吃青菜的話,那么唯一的辦法就是全部倒掉,重新做一份青菜炒飯了,蓋澆飯就沒這么多麻煩,你只需要把上面的蓋菜撥掉,更換一份蓋菜就可以了,蓋澆飯的缺點是入味不均,可能沒有蛋炒飯那么香,
到底是蛋炒飯好還是蓋澆飯好呢?其實這類問題都很難回答,非要比個上下高低的話,就必須設定一個場景,否則只能說是各有所長,如果大家都不是美食家,沒那么多講究,那么從飯館角度來講的話,做蓋澆飯顯然比蛋炒飯更有優勢,他可以組合出來任意多的組合,而且不會浪費,
蓋澆飯的好處就是”菜”“飯”分離,從而提高了制作蓋澆飯的靈活性,飯不滿意就換飯,菜不滿意換菜,用軟體工程的專業術語就是”可維護性“比較好,”飯” 和”菜”的耦合度比較低,蛋炒飯將”蛋”“飯”攪和在一起,想換”蛋”“飯”中任何一種都很困難,耦合度很高,以至于”可維護性”比較差,軟體工程追求的目標之一就是可維護性,可維護性主要表現在3個方面:可理解性、可測驗性和可修改性,面向物件的好處之一就是顯著的改善了軟體系統的可維護性,
面向物件的特點
面向物件技術充分體現了分解、抽象、模塊化、資訊隱藏等思想,可有效提高軟體生產率,縮短 軟體開發時間,提高軟體質量,是控制復雜度的有效途徑,
面向物件不僅適合普通人員,也適合經理人員,降低維護開銷的技術可以釋放管理者的資源,將 其投入到待處理的應用中,在經理們看來,面向物件不是純技術的,它既能給企業的組織也能給經理 的作業帶來變化,
當一個企業采納了面向物件,其組織將發生變化,類的重用需要類別庫和類別庫管理人員,每個程式 員都要加入到兩個組中的一一個:- 一個是 設計和撰寫新類組,另一個是應用類創建新應用程式組,面向 物件不太強調編程,需求分析相對地將變得更加重要,
面向物件編程主要有代碼容易修改、代碼復用性高、滿足用戶需求3個特點,
(1)代碼容易修改
面向物件編程的代碼都是封裝在類里面,如果類的某個屬性發生變化,只需要修改類中成員函式 的實作即可,其他的程式函式不發生改變,如果類中屬性變化較大,則使用繼承的方法重新派生新類,(2)代碼復用性高面向物件編程的類都是具有特定功能的封裝,需要使用類中特定的功能,只需要宣告該類并呼叫 其成員函式即可,如果需要的功能在不同類,還可以進行多重繼承,將不同類的成員封裝到一一個類中, 功能的實作可以像積木樣隨意組合,大大提高了代碼的復用性,
(3)滿足用戶需求
由于面向物件編程的代碼復用性高,用戶的要求發生變化時,只需要修改發生變化的類,如果用 戶的要求變化較大時,就對類進行重新組裝,將變化大的類重新開發,功能沒有發生變化的類可以直 接拿來使用,面向物件編程可以及時地回應用戶需求的變化,
優點:性能比面向物件高,因為類呼叫時需要實體化,開銷比較大,比較消耗資源;比如單片機、嵌入式開發、 Linux/Unix等一般采用面向程序開發,性能是最重要的因素,
缺點:沒有面向物件易維護、易復用、易擴展
什么是類
面向物件編程(OOP)是一種特殊的、設計程式的概念性方法,C++通過一些特性改進了C語言,使 得應用這種方法更容易,下面是最重要的OOP特性:
抽象;
封裝和資料隱藏;
多型;
繼承;
代碼的可重用性,
為了實作這些特性并將它們組合在一起,C++所做的最重要的改進是提供了類,本篇介紹類, 將解釋抽象、封裝、資料隱藏,并演示類是如何實作這些特性的,本章還將討論如何定義類、如何為 類提供公有部分和私有部分以及如何創建使用類資料的成員函式,另外,還將介紹建構式和析構函 數,它們是特殊的成員函式,用于創建和洗掉屬于當前類的物件,最后介紹this指標,對于有些類編 程而言,它是至關重要的,后面還將把討論擴展到運算子多載(另一種多型)和繼承,它們是 代碼重用的基礎,
類是C++中面向物件編程(OOP)的核心概念之一
類是用戶定義的一種資料型別, 要定義類,需要描述它能夠表示什么資訊和可對資料執行哪些操作,類之于物件就像型別之于變數,也就是說,類定義描述的是資料格式及其用法,而物件則是根據資料格式規范創建的物體,換句話說,如果說類就好比所有著名演員,則物件就好比某個著名的演員,如蛙人Kermit,我們來擴展這種類比,表示演員的類中包括該類可執行的操作的定義,如念某一角色的臺詞, 表達悲傷、威脅恫嚇,接受獎勵等,如果了解其他OOP術語,就知道C++類對應于某些語言中的物件型別,而C++物件對應于物件實體或實體變數,
下面更具體一一些,前文講述過下面的變數宣告:
int carrots;
上面的代碼將創建一個型別為int 的變數(carrots), 也就是說,carrots 可以存盤整數,可以按特定的 方式使用例如,用于加和減,
注意:類描述了一種資料型別的全部屬性(包括可使用它執行的操作),物件是根據這些描述創建的物體,
知道類是用戶定義的型別,但作為用戶,并沒有設計ostram和itrem類,就像函式可以來自兩 數庫一樣,類也可以來自類別庫,ostream 和istreaem 類就屬于這種情況,從技術上說,它們沒有被內置 到C++語言中,而是語言標準指定的類,這些類定義位于iostraem檔案中,沒有被內置到編譯器中,如 果愿意,程式員甚至可以修改這些類定義,雖然這不是一個好主意 (準確地說,這個主意很糟),iostream 系列類和相關的fstream 或檔案I/O)系列類是早期所有的實作都自帶的唯一兩組類定義.然而,ANSI/ISO C++委員會在C++標準中添加了其他些類別庫, 另外,多數實作都在軟體包中提供了其他類定義,事實上,C++當前之所以如此有吸引力,很大程度上是由于存在大量支持UNIX、Macintosh和Windows編程的類別庫,
類的宣告與定義
//類可以看做是結構體的升級版,
類的宣告格式如下:
class 類名
{
public:
公有的資料成員和成員函式
protected:
保護的資料成員和成員函式
private:
私有的資料成員和成員函式
};
private: 只能由該類中的函式、其友元函式訪問,不能被任何其他訪問,該類的物件也不能訪問.
protected: 可以被該類中的函式、子類的函式、以及其友元函式訪問,但不能被該類的物件訪問
public: 可以被該類中的函式、子類的函式、其友元函式訪問,也可以由該類的物件訪問
建構式和解構式
建構式和解構式是類體定義中比較特殊的兩個成員函式,因為它們兩個都沒有回傳值,而且
建構式名識別符號和類名識別符號相同,解構式名識別符號就是在類名識別符號前面加“~”符號,
建構式主要是用來在物件創建時,給物件中的一些資料成員賦值,主要目的就是來初始化物件,
解構式的功能是用來釋放一個物件的,在物件洗掉前,用它來做一些清理作業,它與建構式的功能正好相反,
類中的成員函式
類中如果有成員函式,則宣告是必須的,而定義是可選的,什么意思呢,請看下例:
在類內部定義函式體
class 類名
{
回傳型別 函式名(形參串列)
{
函式體
}
};
在類外部定義函式體
class 類名
{
回傳型別 函式名(形參串列);
};
回傳型別 類名 :: 函式名(形參串列)
{
函式體
}
看到這里會產生一個問題,那就是這兩種定義方法到底有什么區別,或者根本沒有區別,
其實它們還是有區別的,類內部定義的函式,程式在要呼叫它的時候會把它當作是一個行內函式,行內函式的好處是呼叫速度更快,但是會占用額外的記憶體空間,每呼叫一次都相當于定義一次,而外部定義的函式,就不會被當作行內函式,對于一些要用到遞回的函式,定義成行內函式肯定是不合理的,因此建議使用第二種方法定義成員函式,
類的定義一般放在程式檔案開頭,或者放到頭檔案中被程式檔案包含,當然也可以放在區域作用域里,這里有必要提一下,c++規定,在區域作用域中宣告的類,成員函式必須是函式定義形式,不能是原型宣告,
類相當于一種新的資料型別,資料型別不占用存盤空間,用型別定義一個物體的時候,才會為它分配存盤空間,
類的成員函式和普通函式一樣,也可以進行多載,設定默認引數,顯式的指定為行內函式等,
注意:C++中對于特定的某個函式,設定默認形參這個動作只能有一次,只能在宣告或定義時設定默認引數
請看下例:
class AA
{
void Sum(int a=0,int b=0);
};
void AA::Sum(int a=0,int b=0)
{
...
}
這是一個設定了默認引數的類成員函式,但這是錯誤的,下面這樣則是正確的:
class AA
{
void Sum(int a=0,int b=0);
};
void AA::Sum(int a,int b)
{
...
}
下面的代碼將詳細講解上述內容:
#include<iostream>
#include<cstring>
using namespace std;
class Student //定義學生類
{
private: //定義私有成員變數
char *Id; //學號
char *Name; //姓名
int Age; //年齡
public: //定義公有介面
//為了方便讀者了解建構式與解構式的執行順序和次數,我在建構式和解構式每一次執行完畢之后輸出一行提示資訊
Student() //建構式:在物件創建時自動呼叫,如果沒有定義編譯器會自動補一個沒有用的建構式,作用:初始化物件
{
//分配記憶體
Id = new char[20];
Name = new char[20];
//添加內容
strcpy(Id, "無");
strcpy(Name, "無");
Age = 10;
cout << "建構式執行完畢!" << endl; //建構式執行完畢后的提示資訊
}
/*函式采用類內宣告,類外定義的方式實作,方便讀者了解這種寫法*/
//提供默認引數
void Set(char* In = (char*)"00000000", char* name = (char*)"學生", int age = 0); //設定學生資訊
void Show(); //顯示學生資訊
~Student() //解構式的功能是用來釋放一個物件的,在物件洗掉前,它將被自動呼叫來做一些清理作業,它與建構式的功能正好相反,
{
delete[]Id; //釋放掉Id和Nmae所占的記憶體
delete[]Name;
cout << "建構式執行完畢!" << endl; //解構式執行完畢后的提示資訊
}
};
//注意在類外定義時函式名前需要加 “ Student:: ” 表示這個Set()函式是類Student的成員函式
void Student::Set(char* id, char* name, int age) //設定學生學號
{
strcpy(Id, id);
strcpy(Name, name);
Age = age;
}
void Student::Show() //顯示學生資訊
{
cout << "學生編號為:" << Id << " " << "姓名為:" << Name << " " << "年齡為:" << Age << endl << endl;
}
int main(void)
{
//創建兩個Student物件
Student A, B;
cout << "A的輸出為:" << endl;
A.Show(); //A使用建構式提供的內容
cout << "B的輸出為:" << endl;
B.Set((char*)"20200910", (char*)"李小明", 66); //B使用用戶提供的內容
B.Show();
return 0;
}
C++ 類中八個默認的函式
1、默認建構式;
2、默認解構式;
3、默認拷貝建構式;
4、默認多載賦值運算子函式;
5、默認多載取址運算子函式;
6、默認多載取址運算子const函式;
7、默認移動建構式(C++11);
8、默認多載移動賦值運算子函式(C++11),
class A
{
public:
// 默認建構式;
A();
// 默認拷貝建構式
A(const A&);
// 默認解構式
~A();
// 默認多載賦值運算子函式
A& operator = (const A&);
// 默認多載取址運算子函式
A* operator & ();
// 默認多載取址運算子const函式
const A* operator & () const;
// 默認移動建構式
A(A&&);
// 默認多載移動賦值運算子
A& operator = (const A&&);
};
前兩個前面已經講過了,現在講后面六個
拷貝建構式(Copy Constructor)
1.拷貝建構式實際上是建構式的多載,具有一般建構式的所有特性,用此類已有的物件創建一個新的物件,一般在函式中會將已存在物件的資料成員的值復制一份到新創建的物件中,用類的一個已知的物件去初始化該類的另一個物件時,會自動呼叫物件的拷貝建構式;
2.函式名與類名相同,第一個引數是對某個同類物件的參考,且沒有其他引數或其他引數都有默認值,回傳值是類物件的參考,通過回傳參考值可以實作連續構造,即類似A(B?)這樣;
3.如果沒有顯式定義,編譯器會自動生成一個默認的拷貝建構式,默認的拷貝建構式會依次拷貝類的資料成員完成初始化;
4.淺拷貝和深拷貝:編譯器創建的默認拷貝建構式只會執行"淺拷貝",也就是通過賦值完成,如果該類的資料成員中有指標成員,也只是地址的拷貝,會使得新的物件與拷貝物件該指標成員指向的地址相同,delete該指標時則會導致兩次重復delete而出錯,如果指標成員是new出來就是“深拷貝”,
多載賦值運算子函式(Copy Assignment operator)
1.它是兩個已有物件,一個給另一個賦值的程序,當兩個物件之間進行賦值時,會自動呼叫多載賦值運算子函式,它不同于拷貝建構式,拷貝建構式是用已有物件給新生成的物件賦初值的程序;
2.賦值運算子多載函式引數中const和&沒有強制要求,回傳值是類物件的參考,通過回傳參考值可以實作連續賦值,即類似a=b=c這樣,回傳值型別也不是強制的,可以回傳void,使用時就不能連續賦值;
3.賦值運算子多載函只能定義為類的成員函式,不能是靜態成員函式,也不能是友元函式,賦值運算子多載函式不能被繼承,要避免自賦值;
4.如果沒有顯式定義,編譯器會自動生成一個默認的賦值運算子多載函式,默認的賦值運算子多載函式實作將資料成員逐一賦值的一種淺拷貝,會導致指標懸掛問題,
多載取址運算子(const)函式
1.多載取址運算子函式沒有引數;
2.如果沒有顯式定義,編譯器會自動生成默認的多載取址運算子函式,函式內部直接return this,一般使用默認即可,
移動建構式和多載移動賦值運算子函式
1.C++11 新增move語意:源物件資源的控制權全部交給目標物件,可以將原物件移動到新物件, 用于a初始化b后,就將a析構的情況;
2.移動建構式的引數和拷貝建構式不同,拷貝建構式的引數是一個左值參考,但是移動建構式的初值是一個右值參考;
3.臨時物件即將消亡,并且它里面的資源是需要被再利用的,這個時候就可以使用移動構造,移動構造可以減少不必要的復制,帶來性能上的提升,
討論
1.建構式為什么不能有回傳值?
(1).C++語言規定建構式沒有回傳值;
(2).建構式不作為右值使用,回傳值也沒有用;
(3).就算有回傳值,從基本語意角度來講,也應該回傳的是所構造的物件,所以沒必要多此一舉來指定回傳型別了;
(4).假如有回傳值,討論下面代碼
class A
{
public:
A():m_iTest(0) { }
A(int i):m_iTest(i) { }
private:
int m_iTest;
};
按照C++的規定,A a = A();是用默認建構式創建一個臨時物件,并用這個臨時物件初始化a,此時,a.m_iTest的值應該是0,現在如果A::A()有回傳值,并且回傳了1(表示構造成功),則C++會用1去初始化a,即呼叫有引數建構式A::A(int i),得到的a.m_iTest便會是1,于是,語意產生了歧義,使得C++原本已經非常復雜的語法,進一步混亂不堪,
建構式的呼叫之所以不設回傳值,是因為建構式的特殊性決定的,當然,上面的討論,也是基于C++語言規定,如果規定建構式可以有回傳值,上面用法也許就不一樣了,是先有雞還是先有蛋,這是一個神奇的問題,總之,現在C++語法體系是這樣的,如果設計建構式可以有回傳值,可能整個C++語言更難實作了,
2.物件創建和銷毀程序是怎樣的?
物件創建(new)程序:
(1).通過operator new申請記憶體;
(2).使用placement new呼叫建構式(簡單型別忽略此步);
(3).回傳記憶體指標,
new和malloc的比較:
(1).new失敗時會呼叫new_handler處理函式,malloc不會,失敗時回傳NULL;
(2).new能通過placement new自動呼叫物件的建構式,malloc不會;
(3).new出來的東西是帶型別的,malloc是void*,需要強制轉換;
(4).new是C++運算子,malloc是C標準庫函式,
new的三種形態:new operator,operator new,placement new
(1).new operator:上面所說的new就是new operator,共有三個步驟組成(申請記憶體,呼叫建構式,回傳記憶體指標),對于申請記憶體步驟是通過運算子new(operator new)完成的,對于呼叫什么建構式,可以由placement new決定;
(2).operator new:像普通運算子一樣可以被多載,operator new會去申請記憶體,申請失敗的時候會呼叫new_handler處理,這是一個回圈的程序,如果new_handler不拋出例外,會一直回圈申請記憶體,直到成功;
(3).placement new:用于定位建構式,在指定的記憶體地址上用指定型別的建構式構造物件,
物件銷毀(delete)程序:
(1).呼叫解構式(簡單型別忽略此步);
(2).釋放記憶體,
delete和free比較
(1).delete能自動呼叫物件的解構式,free不會;
(2).delete是C++運算子,free是C標準庫函式,
3.拷貝建構式引數為什么必須使用型別別物件參考傳遞?
傳參的位置如果一直呼叫拷貝建構式,也就是會遞回參考,導致堆疊溢位,
4.賦值運算子多載函式為什么要避免自賦值?
(1).提高效率,自賦值無意義,如果自賦值,可以立即return *this;
(2).如果不避免,當類的資料成員中如果含有指標,自賦值時會造成記憶體泄漏,
this指標
1.一個類中的不同物件在呼叫自己的成員函式時,其實它們呼叫的是同一段函式代碼,那么成員函式如何知道要訪問哪個物件的資料成員呢?
沒錯,就是通過this指標,每個物件都擁有一個this指標,this指標記錄物件的記憶體地址,當我們呼叫成員函式時,成員函式默認第一個引數為T* const register this,大多數編譯器通過ecx暫存器傳遞this指標,通過 this 這個隱式引數可以訪問該物件的資料成員,
2.類的成員函式為什么不能用static和const同時修飾?
類中用const修飾的函式通常用來防止修改物件的資料成員,函式末尾的const是用來修飾this指標,防止在函式內對資料成員進行修改,而靜態函式中是沒有this指標的,無法訪問到物件的資料成員,與C++ static語意沖突,所以不能,
二、this指標注意點
1.C++中this關鍵字是一個指向物件自己的一個常量指標,不能給this賦值;
2.只有成員函式才有this指標,友元函式不是類的成員函式,沒有this指標;
3.同樣靜態函式也是沒有this指標的,靜態函式如同靜態變數一樣,不屬于具體的哪一個物件;
4.this指標作用域在類成員函式內部,在類外也無法獲取;
5.this指標并不是物件的一部分,this指標所占的記憶體大小是不會反應在sizeof運算子上的,
三、this指標的使用
1.在類的非靜態成員函式中回傳類物件本身的時候,直接使用 return this,比如類的默認取址運算子多載函式,另外,也可以回傳this的參考,這樣可以像輸入輸出流那樣進行“級聯”操作;
2.修改類成員變數或引數與成員變數名相同時,如this->a = a (寫成a = a編譯不過);
3.在class定義時要用到型別變數自身時,因為這時候還不知道變數名,就用this這樣的指標來使用變數自身,
四、this指標探討
1.this指標是什么時候創建的?
物件new的程序中創建的,具體哪個階段有待進一步深入了解,
- this指標存放在何處?
this指標會因編譯器不同而有不同的放置位置,可能是堆疊,也可能是暫存器,甚至全域變數,在匯編級別里面,一個值只會以3種形式出現:立即數、暫存器值和記憶體變數值,不是存放在暫存器就是存放在記憶體中,它們并不是和高級語言變數對應的,
3.為什么C++ NULL物件指標可以呼叫非虛成員函式,而Java中卻不行?
C++語言是靜態系結的,這也是C++語言和Java語言的一個顯著區別,類的成員函式并不與特定物件系結,所有成員函式共用一份成員函式體,當程式編譯后,成員函式的地址即已經確定,另外,C++只關心你的指標型別,不關心指標指向的物件是否有效,C++要求程式員自己保證指標的有效性,況且在有些系統上,地址0也是有效的,理論上完全可以構造一個在地址0上的物件,所以C++中nullptr物件呼叫成員函式并無不可 ,
nullptr物件呼叫成員函式時,只要不訪問此物件獨有的記憶體部分,則程式正常運行,因為不會使用this,一旦訪問此物件的成員變數,則程式崩潰,當然nullptr呼叫虛方法是不能正常運行的(虛函式有虛表,會占用記憶體空間),虛方法呼叫是依賴于this指標的,可以這樣理解,你給函式傳遞了錯誤的引數,但在該函式內部并沒有使用該引數,所以其不影響函式的運行,可以參考下面代碼:
#include <iostream>
using namespace std;
class CPeople
{
public:
CPeople(const std::string& name, int age)
: mName(name), mAge(age){}
~CPeople();
void Print()
{
std::cout << "show people info:" << std::endl;
}
void PrintInfo()
{
std::cout << "name:" << mName << std::endl;
std::cout << "age:" << mAge << std::endl;
}
private:
std::string mName;
int mAge;
};
int main()
{
CPeople* jon = NULL;
jon->Print(); // 程式正常運行
jon->PrintInfo(); // 程式崩潰,訪問非法地址,此時mName和mAge并沒有分配空間
return 0;
}
總結
參考網上關于this指標的一個經典回答:
當你進入一個房子后,
你可以看見桌子、椅子、地板等,
但是房子你是看不到全貌了,
對于一個類的實體來說,
你可以看到它的成員函式、成員變數,
但是實體本身呢?
this是一個指標,它時時刻刻指向你這個實體本身,
繼承
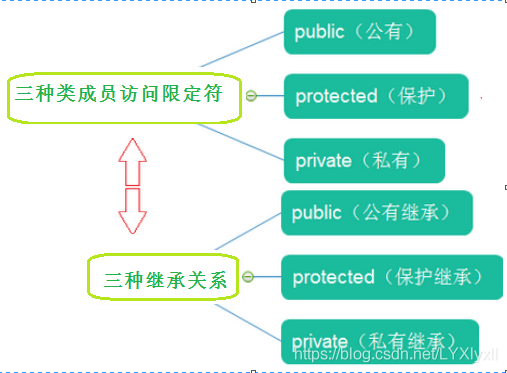
繼承是使代碼可以復用的重要手段,也是面向物件程式設計的核心思想之一,簡單的說,繼承是指一個物件直接使用另一物件的屬性和方法,繼承呈現了 面向物件程式設 計的層次結構, 體現了 由簡單到復雜的認知程序,C++中的繼承關系就好比現實生活中的父子關系,繼承一筆財產比白手起家要容易得多,原始類稱為基類,繼承類稱為子類,它們是類似于父親和兒子的關系,所以也分別叫父類和子類,繼承的方式有三種分別為公有繼承(public),保護繼承(protect),私有繼承(private),
定義格式如下:
1.公有繼承(public)
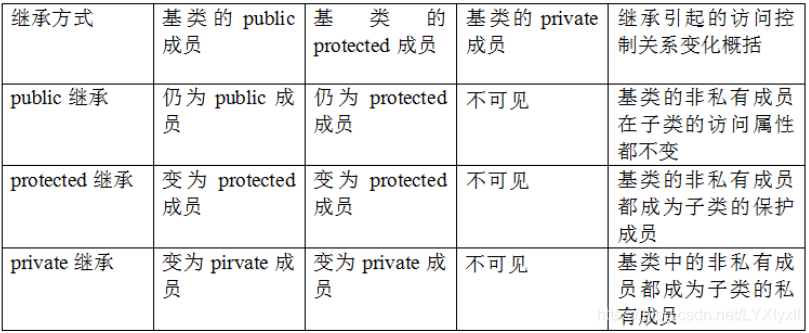
公有繼承的特點是基類的公有成員和保護成員作為派生類的成員時,它們都保持原有的狀態,而基類的私有成員仍然是私有的,不能被這個派生類的子類所訪問,
2.私有繼承(private)
私有繼承的特點是基類的公有成員和保護成員都作為派生類的私有成員,并且不能被這個派生類的子類所訪問,
3.保護繼承(protected)
保護繼承的特點是基類的所有公有成員和保護成員都成為派生類的保護成員,并且只能被它的派生類成員函式或友元訪問,基類的私有成員仍然是私有的,
private能夠對外部和子類保密,即除了成員所在的類本身可以訪問之外,別的都不能直接訪問,protected能夠對外部保密,但允許子類直接訪問這些成員,public、private和protected對成員資料或成員函式的保護程度可以用下表來描述:
class Base //父類
{
private:
int _priB;
protected:
int _proB;
public:
int _pubB;
};
class Derived : public Base //子類,繼承自base,繼承型別為公有繼承
{
private:
int _d_pri;
protected:
int _d_pro;
public:
void funct()
{
int d;
d = _priB; //error:基類中私有成員在派生類中是不可見的
d = _proB; //ok: 基類的保護成員在派生類中為保護成員
d = _pubB; //ok: 基類的公共成員在派生類中為公共成員
}
int _d_pub;
};
//總結:1.public繼承是一個介面 繼承, 保持is - a原則, 每個父類可用的成員 對子類也可用, 因為每個子類 物件也都是一個父類物件,
class C :private A //基類Base的派生類C(私有繼承)
{
public:
void funct()
{
int c;
c = _priB; //error:基類中私有成員在派生類中是不可見的
c = _proB; //ok:基類的保護成員在派生類中為私有成員
c = _pubB; //ok:基類的公共成員在派生類中為私有成員
}
};
class E :protected A //基類Base的派生類E(保護繼承)
{
public:
void funct()
{
int e;
e = _priB; //error:基類中私有成員在派生類中是不可見的
e = _proB; //ok:基類的保護成員在派生類中為保護成員
e = _pubB; //ok:基類的公共成員在派生類中為保護成員
}
};
/*
總結:
基類的private成員 在派生類中是不能被訪問的, 如果基類成員 不想在類外直接被訪問, 但需要 在派生類中能訪問, 就定義為protected, 可以看出保護成員 限定符是因繼承才出現的,
protected / private繼承是一個實作繼承, 基類的部分成員 并非完全成為子類介面 的一部分, 是 has - a 的關系原則, 所以非特殊情況下不會使用這兩種繼承關系, 在絕大多數的場景下使用的 都是公有繼承, 私有繼承以為這is - implemented - in - terms - of(是根據……實作的) , 通常比組合(composition) 更低級, 但當一個派生類需要訪問 基類保護成員 或需要重定義基類的虛函式時它就是合理的,
*/
int main()
{
int a;
D d;
a = D._priB; //error:公有繼承基類中私有成員在派生類中是不可見的,對物件不可見
a = D._proB; //error:公有繼承基類的保護成員在派生類中為保護成員,對物件不可見
a = D._pubB; //ok:公有繼承基類的公共成員在派生類中為公共成員,對物件可見
B b;
a = c._priB; //error:私有繼承基類中私有成員在派生類中是不可見的,對物件不可見
a = c._proB; //error:私有繼承基類的保護成員在派生類中為私有成員,對物件不可見
a = c._pubB; //error:私有繼承基類的公共成員在派生類中為私有成員,對物件不可見
C c;
a = e._priB; //error:保護繼承基類中私有成員在派生類中是不可見的,對物件不可見
a = e._proB; //error:保護繼承基類的保護成員在派生類中為保護成員,對物件不可見
a = e._pubB; //error:保護繼承基類的公共成員在派生類中為保護成員,對物件不可見
return 0;
}
4.不管是哪種繼承方式, 在派生類內 部都可以訪問基類的公有成員 和保護成員 基類的私有成員 存在但是在子類中不可見( 不能訪問),
5.使用關鍵字class時默認的繼承方式是private,不過最好顯示的寫出繼承方式,
6.在實際運用中一般使用都是public繼承, 極少場景下才會使用protetced/private繼承,
繼承關系&訪問限定符
友元
概述
在C++中,我們使用類對資料進行了隱藏和封裝,類的資料成員一般都定義為私有成員,成員函式一般都定義為公有的,以此提供類與外界的通訊介面,但是,有時需要定義一些函式,這些函式不是類的一部分,但又需要頻繁地訪問類的資料成員,這時可以將這些函式定義為該函式的友元函式,除了友元函式外,還有友元類,兩者統稱為友元,友元的作用是提高了程式的運行效率(即減少了型別檢查和安全性檢查等都需要時間開銷),但它破壞了類的封裝性和隱藏性,使得非成員函式可以訪問類的私有成員,
知識點
友元關系不能被繼承,
友元關系是單向的,不具有交換性,若類B是類A的友元,類A不一定是類B的友元,要看在類中是否有相應的宣告,
友元關系不具有傳遞性,若類B是類A的友元,類C是B的友元,類C不一定是類A的友元,同樣要看類中是否有相應的宣告
如果將類的封裝比喻成一堵墻的話,那么友元機制就像墻上了開了一個門,那些得到允許的類或函式允許通過這個門訪問一般的類或者函式無法訪問的私有屬性和方法,友元機制使類的封裝性得到消弱,所以使用時一定要慎重,
通常對于普通函式來說,要訪問類的保護成員是不可能的,如果想這么做那么必須把類的成員都宣告為public(共用的),然而這做帶來的問題遍是任何外部函式都可以毫無約束的訪問它操作它,c++利用friend修飾符,可以讓一些你設定的函式能夠對這些保護資料進行操作,避免把類成員全部設定成public,最大限度的保護資料成員的安全,
友元能夠使得普通函式直接訪問類的保護資料,避免了類成員函式的頻繁呼叫,可以節約處理器開銷,提高程式的效率,但所矛盾的是,即使是最大限度大保護,同樣也破壞了類的封裝特性,這即是友元的缺點,在現在cpu速度越來越快的今天我們并不推薦使用它,但它作為c++一個必要的知識點,一個完整的組成部分,我們還是需要討論一下的, 在類里宣告一個普通數學,在前面加上friend修飾,那么這個函式就成了該類的友元,可以訪問該類的一切成員
友元函式
友元函式是可以直接訪問類的私有成員的非成員函式,它是定義在類外的普通函式,它不屬于任何類,但需要在類的定義中加以宣告
友元函式的宣告可以放在類的私有部分,也可以放在公有部分,它們是沒有區別的,都說明是該類的一個友元函式,
一個函式可以是多個類的友元函式,只需要在各個類中分別宣告,
友元函式的呼叫與一般函式的呼叫方式和原理一致,
友元分為三種:友元函式、友元類、友元成員函式,
宣告在類中加上friend,定義在類外,不可加friend、以及類名::,
下面轉載的一個代碼:
#ifndef A_H
#define A_H
#include <iostream>
using std::cout;
using std::endl;
class B;//前向宣告
class A
{
public:
void dis(const B &b);//只是一個成員函式宣告,故B無需現在創建,可以用前向宣告 class B;
};
#endif
#ifndef B_H
#define B_H
//class A;//因先 #include "A.h" ,再包含 #include "B.h" ,故可以省略前向宣告(A已先定義)
class B
{
private:
int i;
public:
B(int v):i(v){}
B():i(0){}
//友元宣告
friend void A::dis(const B &a);//其它類的成員函式作為友元函式
friend void test(const B& b);//普通的非成員函式作為友元函式
};
#endif
#ifndef C_H
#define C_H
class C
{
private:
int c;
public:
C(int v):c(v){}
friend class D;//友元類,只是一個宣告,不作為成員一部分,故無需先創建D的定義
};
#endif
#ifndef D_H
#define D_H
#include <iostream>
using std::cout;
using std::endl;
//class C;//因先 #include "C.h" ,再包含 #include "D.h" ,故此陳述句可以省略
class D
{
public:
void dis(const C& c)//dis成員函式定義,這里要用到形參C,故C必須先定義完整,所以先#include "C.h"
{
cout<<c.c<<endl;
}
};
#endif
#include <iostream>
#include "A.h"
#include "B.h"
#include "C.h"
#include "D.h"
using namespace std;
void A::dis(const B &b)//必須最后定義,因需要兩個類完整定義后,才能定義該成員函式
{
cout<<b.i<<endl;
}
void test(const B &b)//普通的非成員函式作為友元函式
{
cout<<b.i<<endl;
}
int main()
{
//其他類的成員函式作為友元函式
A a;
B b(9);
a.dis(b);
//普通的非成員函式作為友元函式
test(b);
//友元類舉例
C c(10);
D d;
d.dis(c);
system("pause");
return 0;
}
說明:友元的引入,為了正確地構造類,需要注意友元宣告與定義之間的相互依賴,否則會導致編譯出錯,以上為實體代碼,可以借鑒,
虛函式
C++的特性使得我們可以使用函式繼承的方法快速實作開發,而為了滿足多型與泛型編程這一性質,C++允許用戶使用虛函式 (virtual function) 來完成 運行時決議 這一操作,這與一般的 編譯時決定 有著本質的區別,
虛函式表實作原理
虛函式的實作是由兩個部分組成的,虛函式指標與虛函式表,
虛函式指標
虛函式指標 (virtual function pointer) 從本質上來說就只是一個指向函式的指標,與普通的指標并無區別,它指向用戶所定義的虛函式,具體是在子類里的實作,當子類呼叫虛函式的時候,實際上是通過呼叫該虛函式指標從而找到介面,
虛函式指標是確實存在的資料型別,在一個被實體化的物件中,它總是被存放在該物件的地址首位,這種做法的目的是為了保證運行的快速性,與物件的成員不同,虛函式指標對外部是完全不可見的,除非通過直接訪問地址的做法或者在DEBUG模式中,否則它是不可見的也不能被外界呼叫,
只有擁有虛函式的類才會擁有虛函式指標,每一個虛函式也都會對應一個虛函式指標,所以擁有虛函式的類的所有物件都會因為虛函式產生額外的開銷,并且也會在一定程度上降低程式速度,與JAVA不同,C++將是否使用虛函式這一權利交給了開發者,所以開發者應該謹慎的使用,
虛函式表:
看的我頭都歪了,哈哈
請參考這位大佬的文章
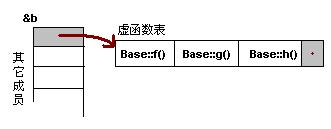
上文已經提到,每個類的實體化物件都會擁有虛函式指標并且都排列在物件的地址首部,而它們也都是按照一定的順序組織起來的,從而構成了一種表狀結構,稱為虛函式表 (virtual table) ,
我們先來規定一個基類
class Base
{
public:
virtual void f(){cout<<"Base::f"<<endl;}
virtual void g(){cout<<"Base::g"<<endl;}
virtual void h(){cout<<"Base::h"<<endl;}
};
首先對于基類Base它的虛函式表記錄的只有自己定義的虛函式
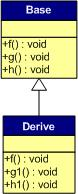
接下來我們來看看子類的情況
class Derived:public Base
{
public:
virtual void f(){cout<<"Derived::f"<<endl;}
virtual void g1(){cout<<"Derived::g1"<<endl;}
virtual void h1(){cout<<"Derived::h1"<<endl;}
}
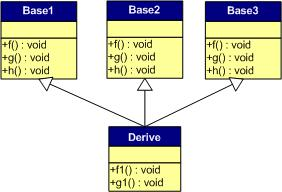
·一般覆寫繼承
首先是最常見的繼承,子類Derived對基類的虛函式進行覆寫繼承,在這個例子中僅設計了一個函式繼承的情況以此推廣情況,
那么此時情況是這樣的:
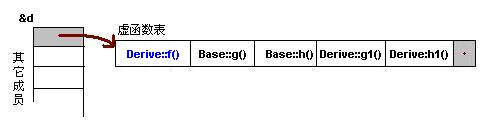
首先基函式的表項仍然保留,而得到正確繼承的虛函式其指標將會被覆寫,而子類自己的虛函式將跟在表后,
而當多重繼承的時候,表項將會增多,順序會體現為繼承的順序,并且子函式自己的虛函式將跟在第一個表項后,

C++中一個類是公用一張虛函式表的,基類有基類的虛函式表,子類是子類的虛函式表,這極大的節省了記憶體
同名覆寫原則與const修飾符
如果繼續深入下去的話我們將會碰見一個有趣的狀況
class Base
{
public:
virtual void func()const
{
cout << "Base!" << endl;
}
};
class Derived :public Base
{
public:
virtual void func()
{
cout << "Derived!" << endl;
}
};
void show(Base& b)
{
b.func();
}
Base base;
Derived derived;
int main()
{
show(base);
show(derived);
base.func();
derived.func();
return 0;
}
在上述程式中我們將Base類中的虛函式base定義為const型別,我們知道const后綴的目的是為了限定該函式不對類內成員做出修改,然后我們分別宣告base與derived并且通過show函式呼叫它們的func函式,子類傳參給父類也是非常正常的一個操作,但是結果可能卻令人不解:
Base!
Base!
Base!
Derived!
這里有一個很大的問題,因為當我們將derived傳過去的時候并沒有呼叫derived的虛函式!也就是說虛函式不再是多型的了,
但是的話我們只需要簡單的修改任意一項:將line4結尾的const限定符去掉或者將Derived的func1后加上const便可以使一切正常,這是為什么呢?
很多其他的博客將其解釋為是const符號作用的原因,但實際上這樣的解釋并不正確,正確的原因是:
虛函式的宣告與定義要求非常嚴格,只有在子函式中的虛函式與父函式一模一樣的時候(包括限定符)才會被認為是真正的虛函式,不然的話就只能是多載,這被稱為虛函式定義的同名覆寫原則,意思是只有名稱完全一樣時才能完成虛函式的定義,
因此在上述的例子中,將Derived型別的子類傳入show函式時,實際上型別轉化為了Base,由于此時虛函式并未完成定義,Derived的func()此時僅僅是屬于Derived自己的虛函式,所以在show中b并不能呼叫,而呼叫的是Base內的func,而當沒有發生型別轉換的時候,Base型別與Derived型別就會各自呼叫自己的func函式,
參考資料:
C++ Primer Plus 作者:Stephen Prata
C程式設計 作者:潭浩強
Essential C++ 作者:Stanley B.Lippman
參考文章鏈接,作者:KeepHopes
參考文章鏈接,作者:唐世光
參考文章鏈接,作者:A彡安靜氵
參考文章鏈接,作者:haoel
本篇到此結束,有什么需要補充的歡迎在評論區留言哦~
群內有各種學習資料,歡迎大家一起來學習!
如果大家遇到什么問題也歡迎大家進群討論~
qq群:759252814
期待你的關注~
感謝大家的支持,謝謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/15162.html
標籤:其他