先看一下下面的這張圖(哈希表的一種實作)(奇丑無比0.0)
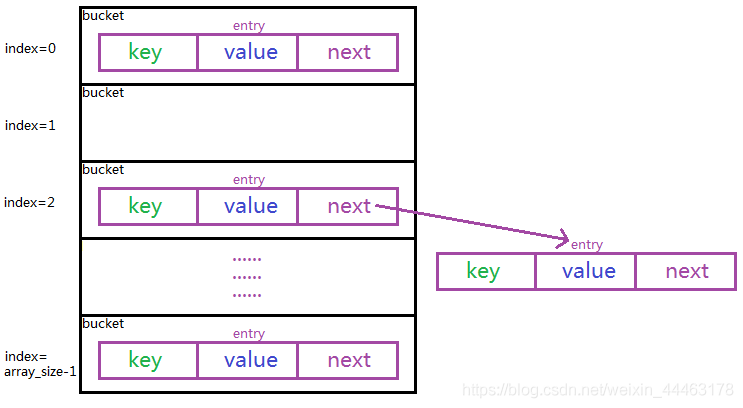
散列(Hash):散列的思想是將條目(鍵/值對)分布在一系列存盤桶(bucket)中,給定一個鍵(key),再通過演算法計算出索引(index),該索引顯示條目的位置,通常可以分為兩步完成:
hash = hashfunc(key) //計算key對應hash值
index = hash % array_size //通過取模"%"使index始終位于0~array_size-1(即索引范圍始終位于陣列中)
負載因子(factor):負載因子=已經插入的資料數量/可以插入的資料總量,對于固定數量的桶,查找時間會隨著條目數量的增加而增加,因此無法實作所需的恒定時間,為了實作這個恒定時間,可以在達到負載因子時進行擴容,
擴容:強制散列所有條目,array_size變大了(通常是兩倍),從而使index的范圍變廣了,hash值不同但index相同的概率減小了(如17、33對16取模結果為1、1;而17、33對32取模結果為17、1,entry分布在bucket中分布更均勻了是不是),那index依然相同該怎么辦呢,這里(僅)介紹一下鏈地址法
System.out.println(17%32);
鏈地址法:長得像上面圖示那樣,哈希表操作的時間是找到bucket的時間(是常數)加上串列操作的時間,bucket里可以放第一個條目(entry)的索引,也可以放第一個條目,HashMap屬于后者,這樣做是因為在大多數情況下,指標遍歷的次數可以減少1,從而提高訪問的快取效率(該快取指的是記憶體,因為鏈表無法使用CPU快取,鏈表無法使用CPU快取是因為CPU快取需要連續的地址空間)但缺點是空bucket與entry占用相同的空間(網上是這么說的,但是根據HashMap的情況來看,HashMap會初始化entry陣列,但存盤在陣列內的entry沒有空參建構式,所以最終的結果為null而非初始化的entry,所以缺點方面還是不要太鉆牛角尖0.0)
時鐘周期(有點跑題了0.0):時鐘周期是CPU作業的最小時間單位,1 / 時鐘周期 =作業頻率,而CPU快取作業所需要的時鐘周期少,記憶體需要的時鐘周期多,由此可見CPU在處理CPU快取和記憶體中的相同任務時,所用的時間是不一樣的(這也是為什么訪問陣列比訪問鏈表快的原因之一!詳見陣列、鏈表對于記憶體及CPU訪問快取機制)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/152698.html
標籤:其他