本文為圖神經網路的學習筆記,講解圖卷積網路 GCN,歡迎在評論區與我交流👏
前言
傳統卷積方式在非歐式的資料空間無法保持“平移不變性”,因此將卷積推廣到 Graph 等非歐式資料空間的拓撲圖上,
先給出 GCN 的公式:
H
(
l
+
1
)
=
D
^
?
1
/
2
A
^
D
^
?
1
/
2
H
l
W
l
H^{(l+1)}=\hat{D}^{-1/2}\hat{A}\hat{D}^{-1/2}H^lW^l
H(l+1)=D^?1/2A^D^?1/2HlWl
- 卷積和傅里葉變換關系緊密,數學上的定義是兩個函式的卷積等于各自傅里葉變換的乘積的逆傅里葉變換,此時卷積與傅里葉變換產生了聯系
- 傳統的傅里葉變換可通過類比推廣到圖上的傅里葉變換,此時傅里葉變換又與 Graph 產生了聯系
- 由傅里葉充當橋梁,卷積與 Graph 產生聯系
【論文鏈接】,
拉普拉斯矩陣與 GCN
拉普拉斯矩陣及其變體
拉普拉斯矩陣
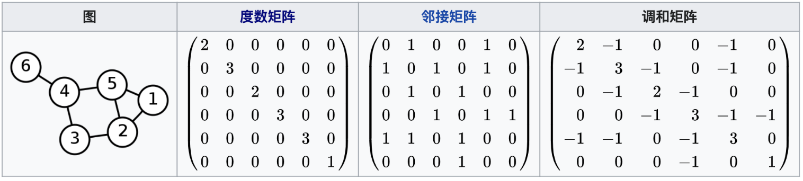
簡單圖 G G G 的節點數為 n n n, D D D 是 G G G 的度矩陣, A A A 是 G G G 的鄰接矩陣,則 G G G 的拉普拉斯矩陣可以表示為 L = D ? A L=D-A L=D?A,
度矩陣 D D D 定義為:
d i , j : = { d e g ( v i ) if i = j 0 o t h e r w i s e d_{i,j}:=\left\{ \begin{array}{rcl} deg(v_i) & & \text{if }{i=j}\\ 0 & & otherwise\\ \end{array} \right. di,j?:={deg(vi?)0??if i=jotherwise?
L
L
L 中各元素表示:
L
i
,
j
:
=
{
d
e
g
(
v
i
)
i
=
j
?
1
if
i
=?
j
and
v
i
鄰接
v
j
0
o
t
h
e
r
w
i
s
e
L_{i,j}:=\left\{ \begin{array}{rcl} deg(v_i) & & {i=j}\\ -1 & & \text{if } i\not=j \text{ and } v_i \text{鄰接} v_j\\ 0 & & otherwise\\ \end{array} \right.
Li,j?:=????deg(vi?)?10??i=jif i?=j and vi?鄰接vj?otherwise?
示意圖(拉普拉斯矩陣也稱為調和矩陣):
拉普拉斯矩陣變體
對稱歸一化的拉普拉斯矩陣:
L
s
y
s
=
D
?
1
/
2
L
D
?
1
/
2
=
I
?
D
?
1
/
2
A
D
?
1
/
2
L^{sys}=D^{-1/2}LD^{-1/2}=I-D^{-1/2}AD^{-1/2}
Lsys=D?1/2LD?1/2=I?D?1/2AD?1/2
L i , j s y s : = { 1 i = j ? 1 d e g ( v i ) d e g ( v j ) if i =? j and v i 鄰接 v j 0 o t h e r w i s e L_{i,j}^{sys}:=\left\{ \begin{array}{rcl} 1 & & {i=j}\\ \frac{-1}{\sqrt{deg(v_i)deg(v_j)}} & & \text{if } i\not=j \text{ and } v_i \text{鄰接} v_j\\ 0 & & otherwise\\ \end{array} \right. Li,jsys?:=??????1deg(vi?)deg(vj?) ??1?0??i=jif i?=j and vi?鄰接vj?otherwise?
隨機游走歸一化的拉普拉斯矩陣:
L
r
w
=
D
?
1
L
=
I
?
D
?
1
A
L^{rw}=D^{-1}L=I-D^{-1}A
Lrw=D?1L=I?D?1A
L i , j r w : = { 1 i = j ? 1 d e g ( v i ) if i =? j and v i 鄰接 v j 0 o t h e r w i s e L_{i,j}^{rw}:=\left\{ \begin{array}{rcl} 1 & & {i=j}\\ \frac{-1}{\sqrt{deg(v_i)}} & & \text{if } i\not=j \text{ and } v_i \text{鄰接} v_j\\ 0 & & otherwise\\ \end{array} \right. Li,jrw?:=??????1deg(vi?) ??1?0??i=jif i?=j and vi?鄰接vj?otherwise?
拉普拉斯矩陣性質
半正定矩陣:是正定矩陣的推廣,對于任意不為 0 的實列向量 X X X,都有 X ’ A X ≥ 0 X’AX\ge0 X’AX≥0,二次型 X ’ A X X’AX X’AX 半正定,則實對稱矩陣 A A A 為半正定,
性質:
- 半正定矩陣的行列式非負
- 兩個半正定矩陣的和是半正定
- 非負實數與半正定矩陣的數乘矩陣是半正定
拉普拉斯矩陣是半正定對稱矩陣
對稱矩陣有 n n n 個線性無關的特征向量 ? \rArr ? 拉普拉斯矩陣可以特征分解
半正定矩陣的特征值非負
對稱矩陣的特征向量構成的矩陣為正交陣 ? U T U = E \rArr U^TU=E ?UTU=E
GCN 為什么要用拉普拉斯矩陣
拉普拉斯矩陣可以譜分解(特征分解),GCN 是從譜域的角度提取拓撲圖的空間特征的
拉普拉斯矩陣只在中心元素和一階相鄰元素處有非零元素
傳統傅里葉變換公式中基函式是拉普拉斯算子,借助拉普拉斯矩陣,通過類比可以推匯出 Graph 上的傅里葉變換公式
算子:一個函式空間到函式空間上的映射 O O O: X → X X\to X X→X,廣義上算子可以推廣到任何空間,如內積空間
傅立葉變換與 GCN
傳統的傅里葉變換
F ( ω ) = F [ f ( t ) ] = ∫ f ( t ) e ? i ω t d t F(\omega)=F[f(t)]=\int f(t)e^{-i\omega t}dt F(ω)=F[f(t)]=∫f(t)e?iωtdt
當變換物件為離散變數時,求積分相當于求內積,即 F ( f ( t ) ) = < f ( t ) , e ? i ω t > F(f(t))=<f(t),e^{-i\omega t}> F(f(t))=<f(t),e?iωt>,這里的 e ? i ω t e^{-i\omega t} e?iωt 為拉普拉斯算子的特征函式,拉普拉斯算子是歐氏空間中的二階微分算子: ? ? 2 f = ? ? ? ( ? ? f ) \vec{\nabla}^2f=\vec{\nabla}\cdot(\vec{\nabla}f) ? 2f=? ?(? f),
因為從廣義的特征方程定義看,
A
V
=
λ
A
AV=\lambda A
AV=λA,
A
A
A 本身是一種變換,
V
V
V 是特征向量或特征函式,
λ
\lambda
λ 是特征值,我們對基函式
e
?
i
w
t
e^{-iwt}
e?iwt 求二階導:
Δ
e
?
i
ω
t
=
?
2
?
t
2
e
?
i
ω
t
=
?
w
2
e
?
i
ω
t
=
k
e
?
i
ω
t
\Delta e^{-i\omega t} = \frac{\vartheta ^2 }{\vartheta t^2}e^{-i\omega t}= -w^2e^{-i\omega t} = ke^{-i\omega t}
Δe?iωt=?t2?2?e?iωt=?w2e?iωt=ke?iωt
可以看出
e
?
i
ω
t
e^{-i\omega t}
e?iωt 是變換
Δ
\Delta
Δ 的特征函式,
在 Graph 中,拉普拉斯矩陣
L
L
L 可以譜分解(特征分解),其特征向量組成矩陣
U
U
U,根據特征方程的定義我們可以得到
L
U
=
λ
U
LU=\lambda U
LU=λU,通過對比可以發現
L
L
L 相當于
Δ
\Delta
Δ,
U
U
U 相當于
e
?
i
ω
t
e^{-i\omega t}
e?iωt,因此在 Graph 上的傅里葉變換可以寫為:
F
[
f
(
λ
k
)
]
=
f
^
(
λ
k
)
=
<
f
,
U
k
>
=
∑
i
=
1
n
f
(
i
)
?
U
k
(
i
)
F[f(\lambda_k)]=\hat{f}(\lambda_k)=<f,U_k>=\sum_{i=1}^nf(i)*U_k(i)
F[f(λk?)]=f^?(λk?)=<f,Uk?>=i=1∑n?f(i)?Uk?(i)
從傅里葉變換的基本思想來看,對
f
(
t
)
f(t)
f(t) 進行傅里葉變換的本質是將
f
(
t
)
f(t)
f(t) 轉換為一組正交基下的坐標表示,進行線性變換,而坐標就是傅里葉變換的結果,下圖中的
f
^
1
\hat{f}_1
f^?1? 就是
f
f
f 在第一個基上的投影分量的大小:
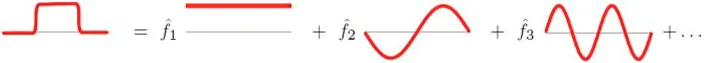
這與拉普拉斯矩陣特征分解的本質一樣,因此可以類比出 Graph 上的傅里葉變換:
f
^
(
λ
k
)
=
∑
i
=
1
n
f
(
i
)
?
U
k
(
i
)
\hat{f}(\lambda_k)=\sum_{i=1}^nf(i)*U_k(i)
f^?(λk?)=i=1∑n?f(i)?Uk?(i)
f
^
(
λ
k
)
\hat{f}(\lambda_k)
f^?(λk?) 是在
U
k
U_k
Uk? 這個基下的投影,
通過矩陣乘法將 Graph 上的傅里葉變換推廣到矩陣形式:
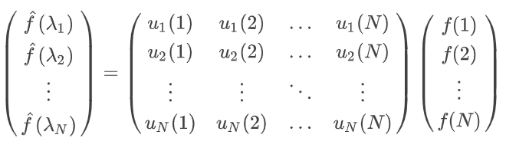
f
(
N
)
f(N)
f(N) 是 Graph 上第
N
N
N 個節點的特征向量,可得到 Graph 上的傅里葉變換形式:
f
^
(
λ
)
=
U
T
f
\hat{f}(\lambda)=U^Tf
f^?(λ)=UTf
因為
U
U
U 為正交陣,滿足
U
U
T
=
E
UU^T=E
UUT=E,因此 Graph 的逆傅里葉變換形式為:
f
=
U
f
^
(
λ
)
f=U\hat{f}(\lambda)
f=Uf^?(λ)
矩陣形式如下:
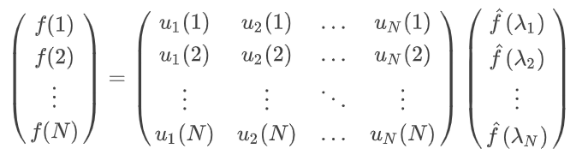
我們已經通過類比從傳統的傅里葉變換推廣到了 Graph 上的傅里葉變換,接下來借助傅里葉變換這個橋梁來研究卷積與 Graph,
卷積與 GCN
卷積定理:函式卷積的傅里葉變換是其傅里葉變換的乘積,對于 f ( t ) f(t) f(t) 和 h ( t ) h(t) h(t),兩者的卷積是其傅里葉變換的逆變換:
( f ? h ) G = F ? 1 ( f ^ ( ω ) h ^ ( ω ) ) (f*h)_G=F^{-1}(\hat{f}(\omega)\hat{h}(\omega)) (f?h)G?=F?1(f^?(ω)h^(ω))
將上一節得到的 Graph 的傅里葉變換帶入得到:
(
f
h
)
G
=
F
?
1
(
(
U
T
f
)
⊙
(
U
T
h
)
)
=
U
(
(
U
T
f
)
⊙
(
U
T
h
)
)
(fh)_G = F^{-1}((U^Tf)\odot(U^Th)) = U((U^Tf)\odot(U^Th))
(fh)G?=F?1((UTf)⊙(UTh))=U((UTf)⊙(UTh))
其中
⊙
\odot
⊙ 是 Hamada 積,表示逐點相乘,
我們一般將
f
f
f 看作輸入的 Graph 的節點特征,將
h
h
h 視為可訓練且引數共享的卷積核來提取拓撲圖的空間特征,為了進一步理解卷積核
h
h
h,將上式改寫為:
U
(
(
U
T
f
)
⊙
(
U
T
h
)
)
=
U
(
(
U
T
h
)
⊙
(
U
T
f
)
)
=
U
d
i
a
g
[
h
^
(
λ
1
)
,
.
.
.
,
h
^
(
λ
N
)
]
U
T
f
U((U^Tf)\odot (U^Th)) = U((U^Th)\odot (U^Tf)) = Udiag[\hat{h}(\lambda _1),...,\hat{h}(\lambda _N) ]U^Tf
U((UTf)⊙(UTh))=U((UTh)⊙(UTf))=Udiag[h^(λ1?),...,h^(λN?)]UTf
證明見【GCN 中的等式證明】,
至此,我們已經推匯出來 GCN 的雛形,
GCN 的進階之路
第一代 GCN
卷積操作核心是可訓練且引數共享的卷積核,所以第一代 GCN 直接將上式中的 d i a g [ h ^ ( λ 1 ) , . . . , h ^ ( λ N ) ] diag[\hat{h}(\lambda _1),...,\hat{h}(\lambda _N)] diag[h^(λ1?),...,h^(λN?)] 中的對角線元素 h ^ ( λ n ) \hat{h}(\lambda_n) h^(λn?) 替換為引數 θ \theta θ,先初始化賦值,然后通過反向傳播誤差來調整引數 θ \theta θ,
所以第一代 GCN 為:
y
=
σ
(
U
d
i
a
g
[
h
^
(
λ
1
)
,
.
.
.
,
h
^
(
λ
N
)
]
U
T
f
)
=
σ
(
U
g
θ
U
T
x
)
y = \sigma (Udiag[\hat{h}(\lambda _1),...,\hat{h}(\lambda N) ]U^Tf) = \sigma (Ug\theta U^Tx)
y=σ(Udiag[h^(λ1?),...,h^(λN)]UTf)=σ(UgθUTx)
x
x
x 是 Graph 中每個節點特征的表示向量,
y
y
y 是每個節點經過 GCN 卷積后的輸出,Graph 中的每個節點都要經過卷積核卷積來提取相應的拓撲空間,然后經過激活函式
σ
\sigma
σ 傳播到下一層,
第一代 GCN 的缺點:
- 需要對拉普拉斯矩陣進行特征分解,每次前向傳播程序中都要計算矩陣乘法,當 Graph 規模較大時,時間復雜度為 O ( n 2 ) O(n^2) O(n2),十分耗時
- 卷積核的個數為 n n n,當 n n n 很大時,節點特征更新緩慢,
第二代 GCN
由于 Graph 上的傅里葉變換時關于特征值的函式
F
(
λ
k
)
F(\lambda_k)
F(λk?),
g
θ
g_\theta
gθ? 可以寫作
g
θ
(
Λ
)
g_\theta(\Lambda)
gθ?(Λ),用
k
k
k 階多項式對卷積核進行改進:
g
θ
(
Λ
)
≈
∑
k
=
0
K
θ
k
Λ
k
g_\theta(\Lambda ) \approx \sum_{k=0}^K\theta _{k}\Lambda ^k
gθ?(Λ)≈k=0∑K?θk?Λk
將其代入到傅里葉變換中有:
(
g
θ
?
x
)
G
≈
U
∑
k
=
0
K
θ
k
Λ
k
U
T
x
=
∑
k
=
0
K
θ
k
(
U
Λ
k
U
T
)
x
=
∑
k
=
0
K
θ
k
(
U
Λ
U
T
)
k
x
=
∑
k
=
0
K
θ
k
L
k
x
(g_\theta * x)_G \approx U\sum_{k=0}^K\theta_{k}\Lambda ^kU^Tx = \sum_{k=0}^K\theta_{k}(U\Lambda ^kU^T)x = \sum_{k=0}^K\theta_{k}(U\Lambda U^T)^kx = \sum_{k=0}^K\theta_{k}L^kx
(gθ??x)G?≈Uk=0∑K?θk?ΛkUTx=k=0∑K?θk?(UΛkUT)x=k=0∑K?θk?(UΛUT)kx=k=0∑K?θk?Lkx
所以第二代 GCN 形式為:
y
=
σ
(
∑
k
=
0
K
θ
k
L
k
x
)
y=\sigma(\sum_{k=0}^K\theta_{k}L^kx)
y=σ(k=0∑K?θk?Lkx)
第二代 GCN 的最侄訓簡結果不需要進行矩陣分解,而是直接對拉普拉斯矩陣進行變換,引數為
θ
k
\theta_k
θk?,一般
k
<
<
n
k<<n
k<<n,因此第二代 GCN 的引數量明顯減少,降低了模型的復雜度,對于引數
θ
k
\theta_k
θk?,先對其初始化,然后根據誤差反向傳播來更新引數,但是仍舊需要計算
L
k
L^k
Lk,時間復雜度為
O
(
n
2
)
O(n^2)
O(n2),
對于矩陣的 k k k 次方,可以得到與中間節點 k-hop 相連的節點,即 L k L^k Lk 中元素是否為 0 表示 Graph 中的節點經過 k k k 跳是否能到達另一節點,這里 k k k 其實表示卷積核感受野的大小,通過將每個中心節點 k-hop 內的鄰接節點聚合來更新中心節點的特征表示,而引數 θ k \theta_k θk? 就是第 k-hop 鄰接的權重,
用切比雪夫多項式展開近似圖卷積核
在第二代 GCN 基礎上用 ChebShev 多項式展開對圖卷積核進行近似,即令:
{
g
θ
≈
∑
k
=
0
K
?
1
θ
k
T
k
(
Λ
^
)
Λ
^
=
2
λ
m
a
x
Λ
?
I
N
\begin{cases} g_ {\theta}\approx \sum_{k=0}^{K-1}\theta k T_k(\hat \Lambda ) \\ \hat \Lambda = \frac{2}{\lambda {max}}\Lambda -I_N \end{cases}
{gθ?≈∑k=0K?1?θkTk?(Λ^)Λ^=λmax2?Λ?IN??
切比雪夫多項式的遞回定義為:
{ T 0 ( x ) = 1 T 1 ( x ) = x T n + 1 ( x ) = 2 x T n ( x ) ? T n ? 1 ( x ) \begin{cases} T_0(x) = 1 \\ T_1(x) = x \\ T_{n+1}(x) = 2xT_n(x) -T_{n-1}(x) \end{cases} ??????T0?(x)=1T1?(x)=xTn+1?(x)=2xTn?(x)?Tn?1?(x)?
用切比雪夫多項式近似圖卷積核的好處:
- 卷積核的引數從原先一代 GCN 的 n n n 個減少到 k k k 個,從原先的全域卷積到現在區域卷積,即將距離中心節點 k-hop 的節點作為鄰接節點
- 通過迭代定義降低了計算復雜度
則切比雪夫圖卷積公式為:
{
y
=
σ
(
∑
k
=
0
K
θ
k
T
k
(
L
^
)
x
)
)
L
^
=
2
λ
m
a
x
L
?
I
N
\begin{cases} y = \sigma(\sum_{k=0}^{K}\theta _k T_k(\hat L)x))\\ \hat L = \frac{2}{\lambda {max}}L -I_N \end{cases}
{y=σ(∑k=0K?θk?Tk?(L^)x))L^=λmax2?L?IN??
構建 TensorFlow 的 ChebNet 模型教程見【切比雪夫多項式近似圖卷積核】,
GCN
GCN 是在 ChebNet 基礎上繼續化簡得到的,在 ChebNet 卷積公式中令
k
=
1
k=1
k=1,只使用一階切比雪夫多項式,此時:
y
=
σ
(
∑
k
=
0
1
θ
k
T
k
(
L
^
)
x
)
)
=
σ
(
θ
0
T
0
(
L
^
)
x
+
θ
1
T
1
(
L
^
)
x
)
y=\sigma(\sum_{k=0}^{1}\theta_k T_k(\hat L)x)) = \sigma(\theta_0T_0(\hat L)x + \theta_1T_1(\hat L)x)
y=σ(k=0∑1?θk?Tk?(L^)x))=σ(θ0?T0?(L^)x+θ1?T1?(L^)x)
由切比雪夫迭代定義有:
T
0
(
x
)
=
1
,
T
1
(
x
)
=
x
T_0(x) = 1, T_1(x) = x
T0?(x)=1,T1?(x)=x
所以:
σ
(
θ
0
T
0
(
L
^
)
x
+
θ
1
T
1
(
L
^
)
x
)
=
σ
(
θ
0
x
+
θ
1
L
^
x
)
\sigma(\theta_0T_0(\hat L)x + \theta_1T_1(\hat L)x) = \sigma(\theta_0x + \theta_1\hat Lx)
σ(θ0?T0?(L^)x+θ1?T1?(L^)x)=σ(θ0?x+θ1?L^x)
令
λ
m
a
x
=
2
\lambda{max}=2
λmax=2,則:
L
^
=
L
?
I
N
\hat L = L - I_N
L^=L?IN?
代入后為:
σ
(
θ
0
x
+
θ
1
L
^
x
)
=
σ
(
θ
0
x
+
θ
1
(
L
?
I
N
)
x
)
\sigma(\theta_0x + \theta_1\hat Lx) = \sigma(\theta_0x + \theta_1(L - I_N)x)
σ(θ0?x+θ1?L^x)=σ(θ0?x+θ1?(L?IN?)x)
又因為
L
L
L 是對稱歸一化的拉普拉斯矩陣,即
L
=
D
?
1
/
2
(
D
?
A
)
D
?
1
/
2
L = D^{-1/2}(D-A)D^{-1/2}
L=D?1/2(D?A)D?1/2,因此上式:
σ
(
θ
0
x
+
θ
1
(
L
?
I
N
)
x
\sigma(\theta_0x + \theta_1(L - I_N)x
σ(θ0?x+θ1?(L?IN?)x
= σ ( θ 0 x + θ 1 ( D ? 1 / 2 ( D ? A ) D ? 1 / 2 ? I N ) x ) = \sigma(\theta_0x + \theta_1(D^{-1/2}(D-A)D^{-1/2} - I_N)x) =σ(θ0?x+θ1?(D?1/2(D?A)D?1/2?IN?)x)
= σ ( θ 0 x + θ 1 ( I N ? D 1 / 2 A D ? 1 / 2 ? I N ) x ) = \sigma(\theta_0x + \theta_1(I_N - D^{1/2}AD^{-1/2} - I_N)x) =σ(θ0?x+θ1?(IN??D1/2AD?1/2?IN?)x)
= σ ( θ 0 x + θ 1 ( ? D 1 / 2 A D ? 1 / 2 ) x ) = \sigma(\theta_0x + \theta_1(- D^{1/2}AD^{-1/2} )x) =σ(θ0?x+θ1?(?D1/2AD?1/2)x)
再令
θ
=
θ
0
=
?
θ
1
\theta = \theta _0 = -\theta_1
θ=θ0?=?θ1?:
σ
(
θ
0
x
+
θ
1
(
?
D
1
/
2
A
D
?
1
/
2
)
x
)
=
σ
(
θ
(
I
N
+
D
?
1
/
2
A
D
?
1
/
2
)
x
)
\sigma(\theta_0x + \theta_1(- D^{1/2}AD^{-1/2})x) = \sigma(\theta(I_N + D^{-1/2}AD^{-1/2})x)
σ(θ0?x+θ1?(?D1/2AD?1/2)x)=σ(θ(IN?+D?1/2AD?1/2)x)
若令
A
^
=
I
N
+
A
\hat A = I_N +A
A^=IN?+A,則:
σ
(
θ
(
I
N
+
D
?
1
/
2
A
D
?
1
/
2
)
x
)
=
σ
(
θ
D
?
1
/
2
A
^
D
?
1
/
2
x
)
\sigma(\theta(I_N + D^{-1/2}AD^{-1/2})x) = \sigma(\theta D^{-1/2}\hat A D^{-1/2}x)
σ(θ(IN?+D?1/2AD?1/2)x)=σ(θD?1/2A^D?1/2x)
將其推廣到矩陣形式得到 GCN 卷積公式:
H
(
l
+
1
)
=
D
^
?
1
/
2
A
^
D
^
?
1
/
2
H
l
W
l
H^{(l+1)} = \hat{D} ^{-1/2}\hat{A} \hat{D} ^{-1/2}H^lW^l
H(l+1)=D^?1/2A^D^?1/2HlWl
譜域卷積 VS 空域卷積
譜域卷積
對圖的拉普拉斯矩陣進行特征分解,通過在傅里葉空間進行特征分解有助于我們理解潛在的子圖結構,ChebyNet,GCN 是使用譜域卷積的典型深度學習架構,
空域卷積
空域卷積作用在節點的鄰域上,通過節點的 k-hop 領域聚合得到節點的特征表示,空域卷積相比譜域卷積更加簡單高效,GraphSAGE 和 GAT 是空域卷積的典型代表,
有幫助的話點個贊加關注吧 😃
參考
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/153717.html
標籤:其他
下一篇:【2020】09 研究生