基于深度學習的三維語意理解(分割)綜述串列
文章目錄
- 基于深度學習的三維語意理解(分割)綜述串列
- 前言
- 基于深度學習的三維語意理解(分割)綜述串列
- 一、 從三維模型中進行深度學習
- 1.1基于點云的方法
- 1.2基于體素的方法
- 1.3基于mesh的方法
- 二、多模態融合的方法
- Frustum-based Mthods
- 2.1緊耦合
- 2.2松耦合
- 總結
前言
隨著2016年pointnet的發表,三維空間中的語音理解逐漸進入了爆發式的增長,本文對至今一些優秀的文章進行部分整理,
注:文中表示的被引次數均為2020年10月3日差得結果
基于深度學習的三維語意理解(分割)綜述串列
一、 從三維模型中進行深度學習
1.1基于點云的方法
- 基于多視圖
(1)MVCNN(Su et al )(2015)(被引121)
(2)MHBN(Yu et al)(2018)
(3)View-GCN(Wei et al)(2020)
(4)SnapNet(Boulch et al)(2017)(可分割)(被引72)
(5)DeepPr3SS(Lawin et al)(2017)(可分割)
(6)TangentConv(Tatarchenko ta al)(2018)(可分割)
(7)MV3D(Chen et al.)(2017)
(8)RT3D(Zeng et al )(2018)
(9)ContFuse(Liang et al)(2018)
(10)AVOD(Ku et al)(2018)
(11)SCANet(Lu et al )(2019)
(12)MMF(Liang et al)(2019)
注:
基于BEV的方法: (且是single shot methods)
(1)PIXOR(Yang et al)(2018) (被引271)(實時)
(2)HDNET(Yang et al)(2018) (被引92)
(3)BirdNet(Beltran et al.)(2018) (被引66)
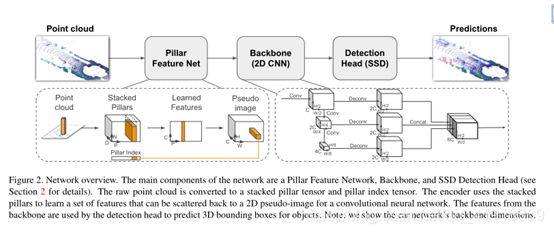
(4)PointPillars(Lang et al.)(2019) (被引250+)
工業界的文章,速度極快的提升了 ,
作者寫作的出發點: 對三維點云進行實時檢測的一種方法,
本文貢獻:
提出了一種端到端的網路,利用原始的三維點云資料,,在不丟失三維資訊的同時,將點云資料轉換為pillars,然后通過一種新穎的編碼器,將這種資料轉換為一種偽二維影像(一種三維張量)然后再這種偽二維資料中,進行大量的CNN,來完成高速,實時的檢測任務,
關鍵點:在三維點云上的BEV轉換成的pillars;將pillars轉換為偽二維影像;利用CNN進行深度學習;速度極快,可以達到105Hz,
網路架構:
三大步驟:
(1) Pillar Feature Net(生成偽影像)
首先在俯視圖的平面上打網格(H x W)的維度;然后對于每個網格所對應的柱子中的每一個點都取(x,y,z,r,x_c,y_c,z_c,x_p,y_p)9個維度,其中前三個為每個點的真實位置坐標,r為反射率,帶c下標的是點相對于柱子中心的偏差,帶p下標的是對點相對于網格中心的偏差,每個柱子中點多于N的進行采樣,少于N的進行填充0,于是就形成了一種三維張量pillars(D,N,P),其中D=9, N為點數(設定值),P為HW,
然后通過本文的編碼器,將pillars中的資料,進行資料轉換,用一個簡化的PointNet將D維轉換為C維(學習特征的一個小程序),變成(C,N,P)讓對N維方向上進行最大池化操作,使得其變為(C,P),此時P是HW(BEV的網格解析度),此時我們又成了一個三維張量(H,W,C)一種偽二維影像,
(2)在偽影像上進行成熟的2維CNN操作,速度比三維卷積快了相當多,
(3)基于SSD的目標檢測頭進行bbox回歸,
(5)Point-GNN(Shi et al )(2020)(被引14)
- 基于球形投影(Spherical)

圖片上方為球形投影的結果,下方是點云,
上方影像的每一行對應于從激光雷達的每個激光獲得的點,在此,影像中的最低行對應于激光雷達中的最低激光,是激光雷達附近最接近的環,如上所示,
投影不是及那個曲面進行簡單地展開,而是一個基于坐標系變換的程序,(將三維的點用圖片的形式來表示)
具體如何進行球面投影,可以參考https://blog.csdn.net/weixin_43199584/article/details/105260463
(1)SqueezeSeg(wu et al 2017)(可分割)(被引206)
本文的核心貢獻,是對三維的點云進行預處理,將點云資料變換成圖片的形式來表示,然后利用成熟的二維卷積的方法來完成分割任務,
(2)SqueezeSeg22(Wu et al 2018)(可分割)(被引93)
(3)RangeNet++(Milioto et al 2019)(可分割)(被引48)
RangeNet++是以SqueezeSeg和SqueezeSegV2為基礎,都使用了點云的球面投影的方法,可以將點云資料轉換為可以支持很多成熟的二維影像處理方法的資料,(用圖片的方式來表示點云)(有效的將點云資料進行降維的方法),同時該方案計算量相對較小,適合于自動駕駛等領域進行實時處理,
處理流程:
- 將三維點云資料通過球投影的方式轉換為二維的表示方法,
- 在該二維的iamge上進行2D全卷積語意分割,
- 將分割成功的2D資訊轉換到3D點云上
- 對分割結果進行優化,
- MLP
(1)PointNet(Qi et al)(2016)(可分割)(被引3000+)
見https://blog.csdn.net/qq_41918369/article/details/108075239
(2)PointNet++(Qi et al)(2017)(可分割)(被引1800+)
見https://blog.csdn.net/qq_41918369/article/details/108075239
(3)3DContextNet(Zeng et al.)(2017)(可分割)(被引17)
(4)A-SCN(xie et al.)(2018)(可分割)
(5)PointSIFT(Jiang et al )(2018)(可分割)(被引91)
(6)Engelman(Engleman et al)(2018)(可分割)
(7)PAT(Yang et al.)(2019)(可分割)
(8)LSANet(chen et al)(2019)(可分割)(被引8)
(9)PointWeb(Zhao et al)(2019)(可分割)(被引58)
(10)ShellNet(Zhang et al )(2019)(可分割)(被引40)
(11)RandLA-Net(Hu et al)(2019)(可分割)
(12)Mo-Net(Joseph-Rivlin et al)(2018)
(13)SRN(Duan et al)(2019)
(14)JustLookUp(Lin et al)(2019)(被引3)
(15)PointASNL(Yan et al)(2020)(被引7)
(16)PointRCNN(Shi et al)(2019)(被引262)
作者提出了一種三維物體檢測器pointRCNN,可以直接從原始的點云中檢測三維物體,(該網路為two-stage網路),stage-1直接從點云中生成多個粗略的3Dbox,stage-2,優化一階段的3Dbox并對每個box中的物體進行class分類,
stage-1:
先通過pointnet++對每個點的特征進行提取,然后通過點的特征,將所有的點分為前景點和背景點,并將背景點洗掉,同時在前景點上,對每個點都生成一個box,然后通過部分優化,留下,部分得分最高的box,
stage-2:
將stage-1中生成的部分精準的box進行標準化坐標變換,然后再通過區域的pointnet,進行區域特征的學習,得到區域的特征向量,再和全域的特征向量進行拼接,然后優化每個點的特征,然后重新生成一個最優的3D-box,同時完成class任務,
- 基于圖卷積網路的方法
(1)SPG(Landrieu and Simonovski)(2018)(可分割)(被引296)
(2)SSP(Landrieu and Bussaha)(2019)(可分割)(被引28)
(3)DGCNN(Wang et al)(2018)(可分割)(被引700+)
Dynamic Graph CNN for Learning on Point Clouds
本文貢獻:(1)EdgeConv在保證置換不變性的同事捕獲區域幾何資訊,
(2)DGCNN可以在動態更新圖的同事,在語意上將點聚合起來,
(3)EdgeConv可以遷入多個已有的多個點云處理框架中,
本文提出了一個新的神經網路模塊——EdgeConv.
EdgeConv的優點:(1)包含了區域鄰域的資訊,
(2)可以通過EdgeConv模塊的回圈使用,提取全域的形狀特征,
(3)在多層系統中,特征空間中的相對關系包含了語意特征,
EdgeConv的不足:EdgeConv考慮了點的坐標與領域點的距離,但是忽略了相鄰點之間的向量方向,最侄訓是損失了一部分的區域幾何資訊,
EdgeConv:
首先提取中心點與臨近店之間的邊特征,再進行卷積操作,
具體步驟:
(1)先利用MLP對每個點提取一遍特征
(2)再利用多種方式將點和周圍點的特征進行融合,本文提出了四種融合方式,此處介紹一種,我個人認為最合理的一種方式:將中心點的特征,與中心點與K個臨近點之間的特征差進行串聯,然后輸入MLP中,這樣便融合了點之間的區域關系和點的全域特征,
作者認為PointNet++不足的原因: pointnet++在處理區域區域的點的時候未來保證置換不變性而導致過于獨立,這樣會忽視了點之間的集合相關資訊,導致一部分的資訊丟失,
(4)PyramNet(Kang and Liu.)(2019)(可分割)(被引3)
(5)GACNet(Wang et al)(2019)(可分割)(被引64)
(6)SPH3D-GCN(Lei et al)(2019)(可分割)(被引9)
(7)HEPIN(Jiang et al )(2019)(可分割)
(8)DPAM(Liu et al.)(2019)(可分割)
(9)ECC(Simonovsky et al)(2017)
(10)KCNet(Shen et al.)(2017)(被引155)
(11)FoldingNet(Yang et al.)(2017)(被引235)
(12)AGCN(Li et al.)(2018)
(13)LocalSpecGCN(Wang et al )(2018)
(14)RGCNN(Te et al .)(2018)(被引60)
(15)3DTI-Net(Pan et al )(2018)(被引1)
(16)ClusterNet(Chen et al.)(2019)(被引21)
(17)DPAM(Liu et al.)(2019)
(18)Grid-GCN(Xu et al.)(2020)(被引7)
(19)DeepGCNs(2019)(可分割)(被引84)
本文作者認為CNN(完美的應用歐氏距離的資料中)成功的原因在于:CNN可以設計并使用深層的網路結構,,但現在GCN(用來處理拓撲結構的資料)現階段只能處理2-3層的資料,(由于深層的GCN的Aggregate容易造成over
smooth問題,即節點間的feature難以區分),本文來探究能否也生成一個深層的GCN網路模型,本文解決深度GCN出現的問題的方法,使用residual/dense connections 和DGCNN中的 edge conv
三種方法方法一同來克服了深度GCN中出現的問題,
- 基于點的卷積的方法
(1)PointCNN(Li et al)(2018)(可分割)(被引400+)
本文的主要貢獻是:引入了一個新的運算方法X-Conv
本作者想要解決對無序的點云的卷積問題,作者的解決核心思路是:將無序的點云進行有序化變換,然后使用卷積的方法,進行特征提取,
作者的解決方案:使用空間變換網路(STN)從前一層的資料中提取K個點,預測一個K*K大小的轉置矩陣(X-transformation),用轉置矩陣對前一層的特征做變換,然后對變換后的特征用卷積,此外,同樣也在提取出k個近鄰后,將各個點轉換到區域坐標系,
PointCNN的優點:引數少,訓練時間短,比較優美但pointconv作者認為該篇文章沒有實作置換不變性
X-Conv的具體程序看見周報筆記,
(2)MCCN(Hermosilla et al)(2018)(可分割)
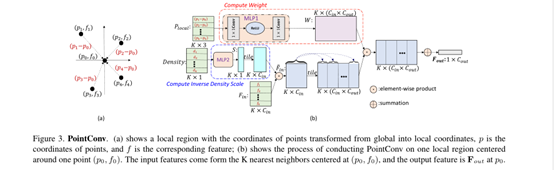
(3)PointConv(Wu et al)(2018)(可分割)(被引150+)
作者的寫作出發點:作者通過對一維卷積和二維卷積的理解中,認為卷積主要由兩部分組成,(1)將目標點和周圍點都考慮進來,(K近鄰)(2)不同位置的點的輸入權重是不一樣的,所以本文是要解決如何得到一個關于不同K近鄰點的權重系數問題,(求解權重函式)
本文貢獻:
(1) 提出了一種新的三維卷積運算,pointconv,一種考慮密度的不斷跟新權重的網路,該網路最重要的創新是:可以有效地計算權重函式,
(2) 該網路能夠完全近似任何一組3D點上的3D連續卷積,
(3) 本文還提出了相應的反卷積操作PointDeconv,將特征傳播回原始解析度,像二維空間中一樣,使用全卷積網路能夠更精確的完成分割任務,
網路架構:
(a) 是將全域坐標系下的全部點的坐標,轉換為以P為中心點后,轉化為區域坐標的程序,
(b) 中的上部分,是將(a)中轉化后的K近鄰點的區域坐標當做輸入,然后通過區域的多層感知器進行權重的訓練;下部分是將點的密度考慮進來,主要是處理點云采樣不均的問題.
注:(1)Pointconv中的MLP的權重在所有點之間是共享的,來保證排列不變性,
(2)作者為了證明pointconv是真正的卷積運算,作者還將2D影像中的所有像素轉換為具有2D坐標以及RGB值的點云格式,其分類結構可以和正常的影像的CNN媲美,
所以作者認為本篇文章既可以是三維場景中的CNN方法,
(4)ConvPoint(Boulch et al.)(2019)(可分割)(被引10)
(5)A-CNN(Komarichev et al)(2019)(可分割)(被引36)
(6)KPConv(Thomas et al)(2019)(可分割)(被引139)
(7)InterpCNN(Mao et al)(2019)(可分割)(被引35)
(8)DPC(Engelmann et al.)(2019)(可分割)
(9)SphericalCNN(Spherical)(2017)(被引277)
(10)Point wise CNN(Hua et al)(2017)
(11)Tensor field Network(Thomas et al)(2018)(被引90)
(12)Flex-Convolution(Groh et al.)(2018)(被引15)
(13)PCNN(Matan et al.)(2018)
(14)SpiderCNN(Xu et al)(2018)(被引181)
(15)MCCNN(Hermosilla et al)(2018)
(16)Geo-CNN(Lan et al)(2018)(被引32)
(17)Ψ-CNN(Lei et al)(2019)(被引26)
(18)LP-3DCNN(Kumawat et al.)(2019)(被引18)
(19)RS-CNN(Liu et al.)(2019)(被引87)
(20)KPConv(Thomas . Charles R. QI et al )(facebook ai )(2019)(被引150+)
(21)SFCNN(Rao et al.)(2019)
(22)DensePoint(Liu et al)(2019)(被引25)
(23)ConvPoint(Boulch et al.)(2020)(被引10)
- (24) Associatively Segmenting Instances and Semantics in Point(被引49)
Clouds.(Wang et al.)(2019)(可分割)(被引50+)
(26)4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks(choy et al )(2019)(被引50+)
(27)Deep Hough Voting for 3D Object Detection in Point Clouds(Qi,et al. )(2019)(被參考100+)
(28) Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds(semon et al)(2019)(被引32)
- 基于RNN的方法
回圈神經網路的本質是:像人一樣擁有記憶的能力,使得機器能夠聯系背景關系的陳述句,理解當 前單詞或者預陳述句的意思 現階段的RNN的各種變形還可以學習二維視頻資訊和三維視頻的資訊,
RNN與CNN的本質區別:CNN沒有記憶功能,它的輸出僅依賴于輸入和網路的權重值,但 RNN有記憶功能,他的輸出不僅依賴于當前的輸入,還依賴當前的記憶,
CNN的輸入是單一的圖片等單一性質的資料,而RNN的輸入是一個序列,一個隨時間變化的序列
(1)G+RCU(Engelam et al)(2018)(可分割)
(2)RSNet(Huang et al)(2018)(可分割)(被引153)
(3)3P-RNN(Ye et al )(2018)(可分割)(被引72)
本文的3P(Pointwise Pyramid Pooling)
也是先通過MLP來提取點云的特征,然后設定一個金字塔模型,對不同大小的區域的點云分別提取區域資訊(大區域,小區域,等)和全域資訊,然后獲得每個點的全部資訊,(此時每個點的特征為特征向量,)
再將特征向量放入雙向的RNN中,進行學習,然后通過全連接層來完成分割任務
(4)DARNet(Zhao et al )(2019)(可分割)(被引2)
(5)PointRNN(Fan et al)(2018)(被引7)
一個用來處理動態點云的深度學習網路,主要貢獻:本提出了PointRNN和其兩個變體,PointGRU、PointLSTM 都可以應用于移動點云的預測(結合給定點的歷史運動軌跡來預測點云的未來軌跡)動態點云學習
注:傳統的RNN是以一維向量作為輸入的,RNN的一些變體如Cubic
ConvLSTM可以用來對二維視頻進行深度學習,本文PointRNN是進一步的變體,可以對三維點云視頻(動態三維點云)進行深度學習
- 基于晶格的方法(Lattice)
(1)LatticeNet(Rosu et al.)(2019)(可分割)(被引12)
該網路可以在 (2)中晶格的基礎上可以實作大點云的有效處理
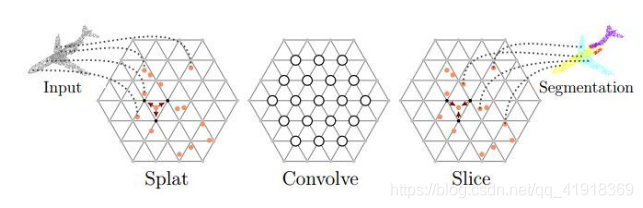
(2)SPLATNet(Su et al.)(2018)(被引272)
本篇文章方法小眾,且文章難度
且同時pointNet、pointcnn處理起來復雜了一些,但相比于基于樹的點云處理網路相比,(樹的網路如OCNN都是講點云進行高效的組織化,然后再套用成熟的神經網路進行處理,一般不是end-to-end網路)但是本篇文章的方法把對點云的組織者一步驟放到了每一次卷積操作中,實作了end-to-end,
注;本文應用的bilateral convolution lays(BCLs)和permutohedra lattice 并非作者首創,
文章中BCL平滑地將輸入點映射到稀疏的格子上,在稀疏的點陣上執行卷積,然后將過濾后的信號平滑地插入到原始的輸入點上,主要分為: Splat、Convolve、Slice:
1.Splat: BCL首先將輸入特征結合到晶格
2.Convolve: BCL在這些點陣上進行卷積操作,(就像標準CNN一樣)
3.Slice:經過卷積后的信號插值(barycentric interpolation)投影回輸入信號,
注:該網路可以靈活地聯合處理處理多視圖影像和點云,
- 有待閱讀后進行進一步分類
(1)ShapeContexNet(Xie et al.)(2018)
(2)PVNet(You et al.)(2018)(被引51)
(3)Point2Sequence(Liu et al )(2018)(被引52)
(4)PVRNet(You et al )(2018)(被引12)
(5)3DPointCapsNet(Zhao et al)(2018)
(6)RCNet(Wu et al.)(2019)(被引2)
(7)PointDAN(Qi et al)(2019)(被引6)
(8)3D FCN(Li et al.)(2017)
(9)Vote3Deep(Li et al.)(2017)
(10)VoxelNet(Zhou et al.)(2018)
(11)SECOND(Yan et al.)(2018)
(12)3DBN(Li et al)(2019)
(13)3DSSD(Yang et al.)(2020)
single shot methods(14)LaserNet(Meyer et al)(2019)
(15)3D iou loss(Zhou et al)(2019)
(16)Part-A^2(Shi et al.)(2019)
(17)Fast Point RCNN(Chen et al.)(2019)
(18)VoteNet(QI et al.)(2019)(被引97)
(19)LaserNet++(Mayer et al .)(2019)
(20)PV-RCNN(Shi et al )(2019)(被引20)
(21)OHS(Chen et al.)(2019)
(22)ImVoteNet(Qi et al.)(2020)(被引10)
(23)SA-SSD(He et al.)(2020)
1.2基于體素的方法
SECOND,PointPillar,Part-A^2
1.3基于mesh的方法
二、多模態融合的方法
(1)3DMV(Dai and NieBner)(2018)(被引90)
(2)UPB(Chiang et al.)(2018)
(3)MVPNet(Jaritz et al.)(2019)(被引11)
Frustum-based Mthods
(1)F-PointNets(QI et al )(2018)(被引656)
(2)PointFusion(XU et al.)(2018)(被引167)
(3)RoarNet(Shin et al.)(2018)(被引50)
(4)SIFRNet(Zhao et al.)(2019)(被引8)
(5)F-ConvNet(Wang et al.)(2019)
(6)Patch Refinement(Zhao et al )(2019)(被引9)
2.1緊耦合
- voxel-based
(1)CD-CVF( Yoo et al 韓國)(2020)
將雷達的點云體素化后 ,通卷積層進行預處理,生成在BEV下的特征地圖,然后對多視角(構成閉合環形)的image進行FPN(CNN的一種網路)進行預處理,生成特征地圖,然后用auto-calibrated
feature projection將多幅圖進行融合,生成BEV下的feature,再利用adaptive gated fusion
network來融合雷達和image預處理后的BEV圖,再進行正常的RPN,
- point-based
(1) PI-RCNN(Xie et al)(2019)
point分支和image分支分別做3D目標檢測任務和語意分割任務,然后對每個點搜尋K臨近點,對這些點結合相機的內外參反向投入二維的語意地圖中,得出這幾個點對應二維中的像素的語意特征,然后將這幾個點的幾何特征和語意特征進行聯合積分,得到聯合特征;最后將幾何特征,語意特征,聯合特征進行拼接,更新該點的特征,從而完成二次優化的任務,實作點云資料和RGB資料的融合,
(2)PointPainting(cvpr2020)(被引11)
該作業的fusion方式是采用二維語意分割資訊通過lidar資訊和image資訊的變換矩陣融合到點上,再采用baseline物體檢測;可以理解為對于語意分割出的物體多了一些資訊作為引導,得到更好的檢測精度,和上面的pi-rcnn的不同之處是該融合是一個串聯的網路結構,將語意分割后的特征和原始點云一起送入深度學習網路中.
2.2松耦合
(1)CLOCs
該網路經歷了三個主要的階段(1)2D和3D的目標檢測器分別提出proposals(2)將兩種模態的proposals編碼成稀疏張量(3)對于非空的元素采用二維卷積做對應的特征融合,
總結
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/153998.html
標籤:AI
上一篇:機器學習筆記(3)
下一篇:畢業設計問題求解