超引數(Hyper-parameter)是定義模型或者定義訓練程序的引數,是相對于模型引數(Parameter)來說的,比如目標檢測網路的網路結構,激活函式的選擇,學習率的大小,Anchor的尺寸等等,都屬于超引數.超引數對網路的性能(如目標檢測網路的mAP等)有很大的影響,因此需要找到性能最優的引陣列合,也就是超引數優化(Hyper-parameter Optimization,HPO),通俗的說就是調參.
調參有很多方法,比如說網格搜索(Grid Search)、隨機搜索(Random Search),各種進化計算演算法,如遺傳演算法(Genetic Algorithm, GA)、粒子群優化(Paticle Swarm Optimization, PSO)等等,但是這些方法都不適用于超引數優化,因為超引數評估一個引陣列合的性能,需要用這個引陣列合訓練神經網路,再評估網路的性能,而訓練神經網路計算量很大,需要很長的時間,因此評估的引陣列合的數量不能太多,只能評估少數的引陣列合的性能.最適合的方法就是貝葉斯優化(Bayesian Optimization)了.
貝葉斯優化只需要幾個引陣列合以及它們的性能,再進行高斯程序回歸(Gaussian Process Regression, GPR),然后就可以計算出很多引陣列合取值點的期望值和方差,期望值表明這個點最優可能的性能,方差表明這個點性能的不確定性.
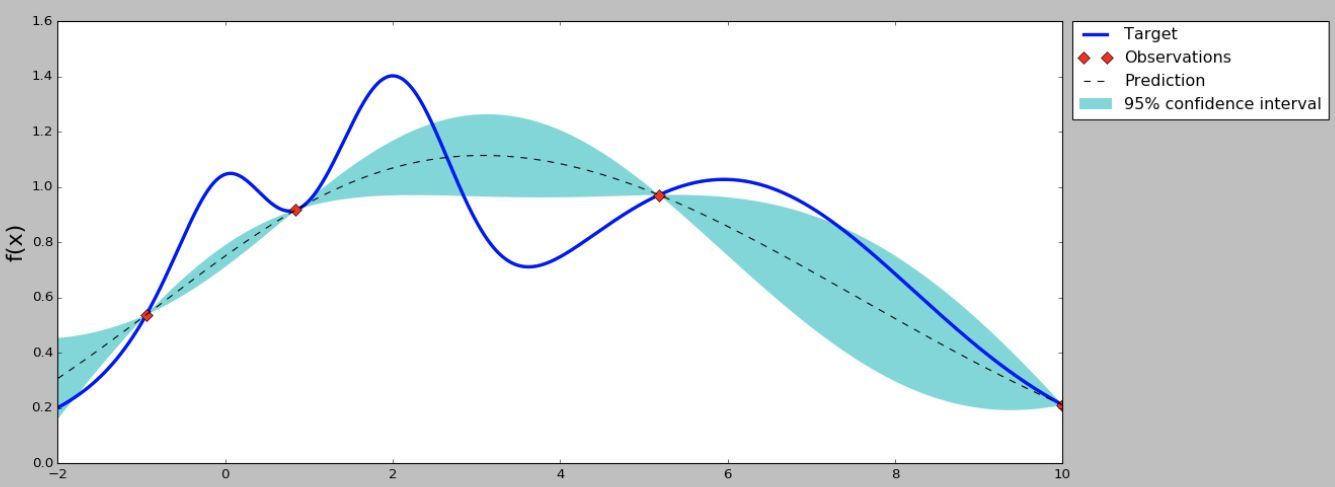
如上圖所示,用4個點的值進行高斯程序回歸,然后可以計算出很多點的期望值和方差,有的點期望值高,有的點方差大,到底選擇哪些點,就涉及到開發(exploritation)和探索(exploration)均衡的問題了.期望值高的點是我們需要的,但是方差大的點也是需要的,因為方差大的點雖然期望值不是很高,但是不確定性較大,有可能出現更高的值.究竟選哪些點,就要用到采集函式(Acquisition Function)了,最簡單的采集函式是期望值加上方差的n倍(n可以是整數、小數、正數、負數).如下圖所示,選擇采集函式最大的點.
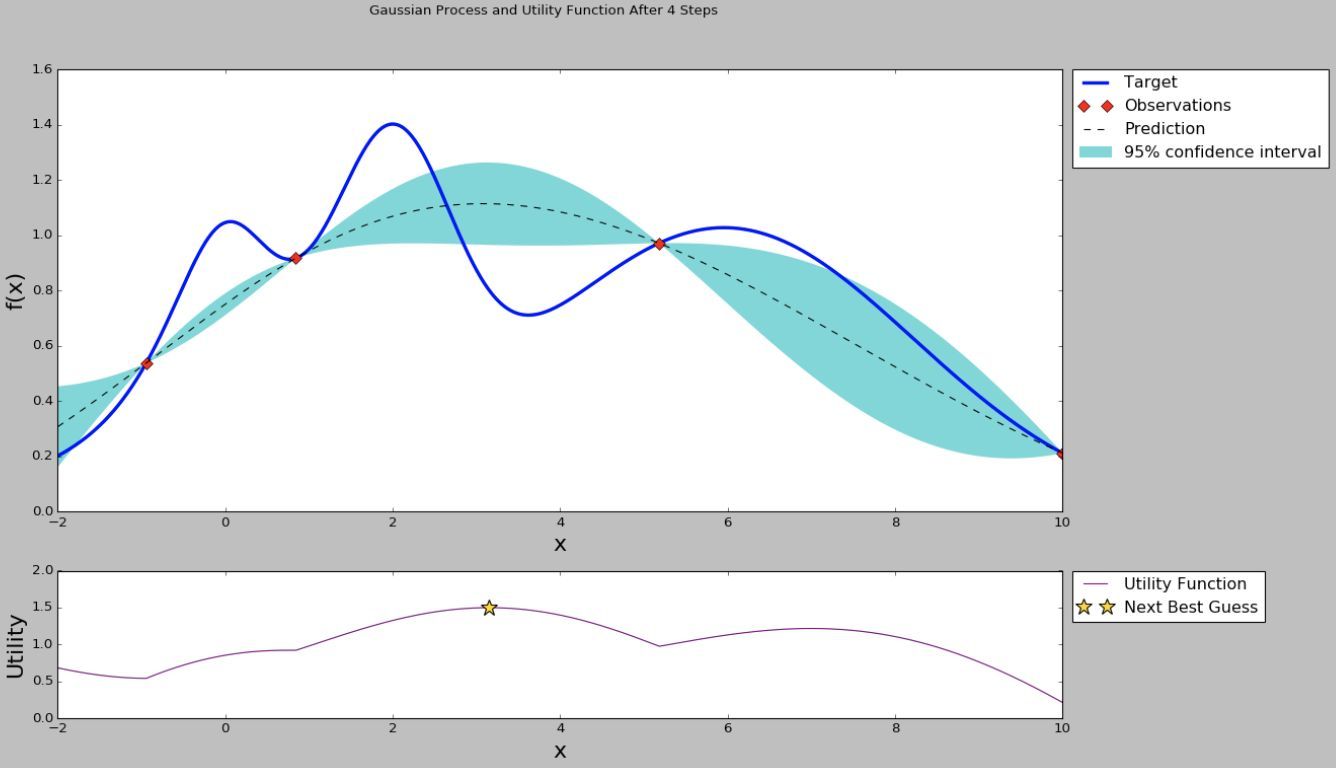
根據選擇的點的引陣列合,又進行一次模型訓練,再評估模型的性能,這樣就有了5個點的值,于是又可以進行一次高斯程序回歸,選擇采集函式最大的點,再訓練模型和評估,得到第6個點的值,如下圖所示.
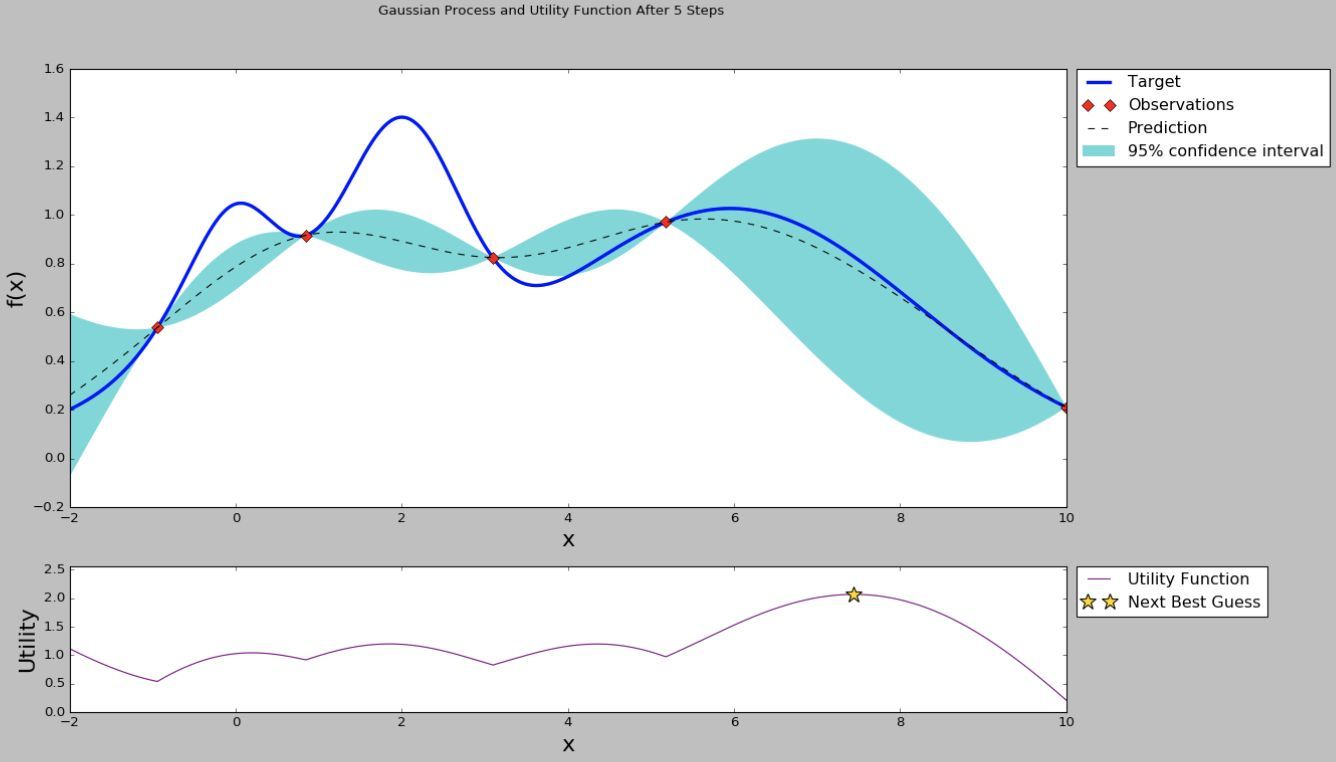
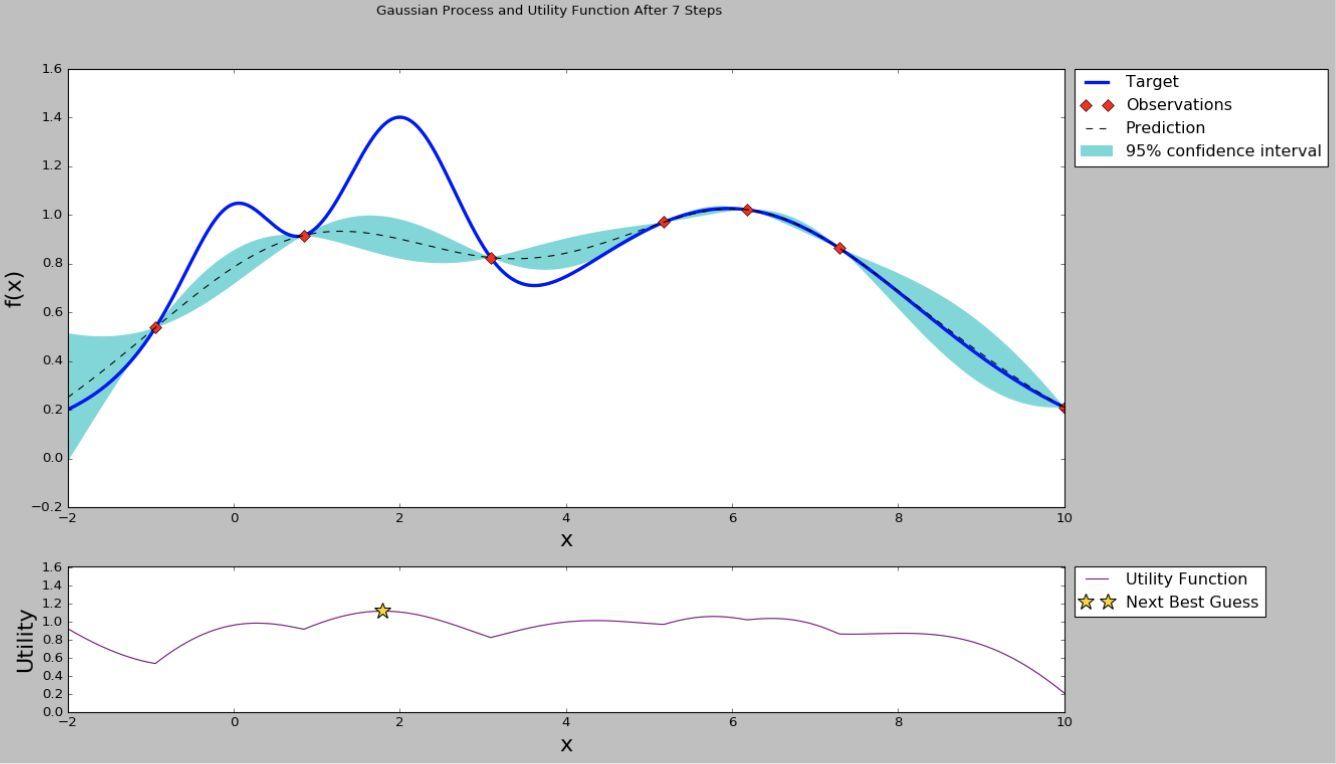
以上程序反復進行,通過計算有限的點的性能,可以使曲線逐漸逼近真實曲線,從而可以選擇性能最優,或者說接近最優的超引陣列合,取得不錯的模型性能.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/155056.html
標籤:其他