·低密度人群代碼說明中文檔案及補充說明
·代碼串列

·代碼使用說明
這套代碼的使用只針對低密度的人群密度,即人群密度的統計的滿足能夠分辨單個的人,即視頻中不存在多個人疊加的情況,
代碼MATLAB2007b,運行![]() 即開始運行本代碼,
即開始運行本代碼,
·設計方案說明
第一步:讀取圖片視屏序列
function [n_frames,I3] = func_readvedio(folder,list);
n_frames = 0;
for i=1:length(list)
I = imread(fullfile(folder,list(i).name));
I2 = rgb2gray(uint8(I));
I3(:,:,i) = I2;
n_frames = n_frames + 1;
end
這樣寫可以專門用來讀取連續編號的圖片序列作為視屏,

第二步:提取背景
這個部分的方法參考您提供的論文的這個部分:

對應的代碼如下所示:
function back3 = func_getbackground(image,frames,T);
rows = size(image,1);
cols = size(image,2);
d(1:rows,1:cols,1) = image(1:rows,1:cols,1);
for k = 2:frames
d(1:rows,1:cols,k) = image(1:rows,1:cols,k) - image(1:rows,1:cols,k-1);
end
//以上就是求解影像的差分
CDM(1:rows,1:cols,2:frames) = d(1:rows,1:cols,2:frames);
CDM(abs(CDM) < T)=0;
CDM(abs(CDM) >= T)=255;
//求CDM值
m=0;
for i=1:rows
for j=1:cols
for k=2:frames
if CDM(i,j,k) == 0
m(k)=1;
end
if CDM(i,j,k) == 255
m(k)=rand(1);
end
end
position(i,j) = func_position(m);
end
end
//求解CDM中最大的連0的坐標
for i=1:rows
for j=1:cols
back3(i,j) =image(i,j,position(i,j));
end
end
//獲得背景

第三步:當前圖片與背景的差
function images2 = func_subbackground(image,back,frames,T2);
rows = size(image,1);
cols = size(image,2);
for k=1:frames
images(1:rows,1:cols,k) = back(1:rows,1:cols)-image(1:rows,1:cols,k);
images2(1:rows,1:cols,k) = im2bw(images(1:rows,1:cols,k),T2);
end
這里求解差,并將得到的結果求二值圖

第四步:形態學處理
rows = size(image,1);
cols = size(image,2);
for k=1:frames
images3(1:rows,1:cols,k)=bwareaopen(image(1:rows,1:cols,k),10);
end
這里我們主要將視屏中的個別噪點去掉使畫面更加’干凈’;

第五步:邊緣檢測
function images = func_edgecheck(image,frames);
rows = size(image,1);
cols = size(image,2);
for k = 1:frames
for i=2:rows
for j=2:cols
if image(i,j,k)==1 &&(image(i+1,j,k)==0||image(i-1,j,k)==0||image(i,j+1,k)==0||image(i,j-1,k)==0)
images(i,j,k)=255;
else
images(i,j,k)=0;
end
end
end
end
普通邊間求解法

第六步:求解前景像素數
function Num = func_pixel(image,frames);
rows = size(image,1);
cols = size(image,2);
Num(1:frames) = 0;
for k = 1:frames
for i=2:rows
for j=2:cols
if image(i,j,k)>0
Num(k) = Num(k)+1;
end
end
end
end
plot(Num,'r-*');
grid;
ylabel('????êy');
xlabel('??êy??');
title('μí?ü?èè??ú?ü?è');
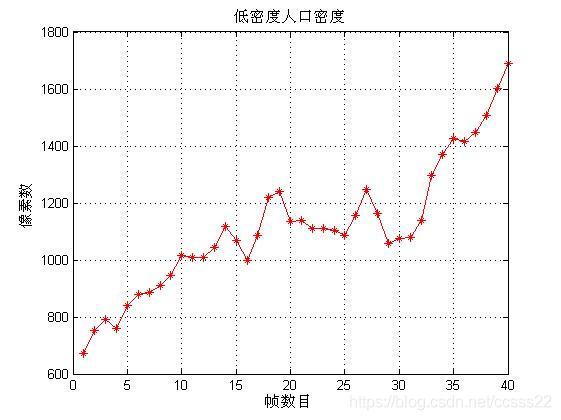
第七步:擬合說明
這個步驟主要是通過求的的像素值與實際存在的人數進行擬合,其擬合效果如下所示:
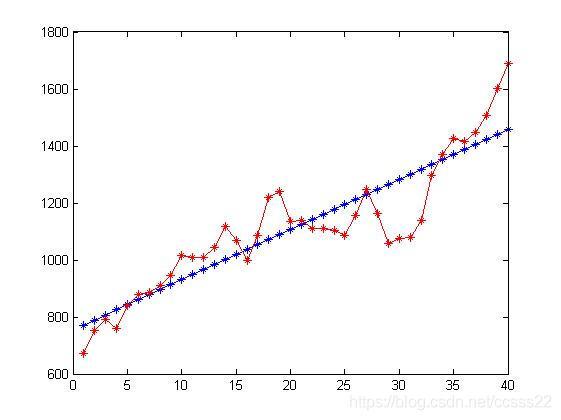
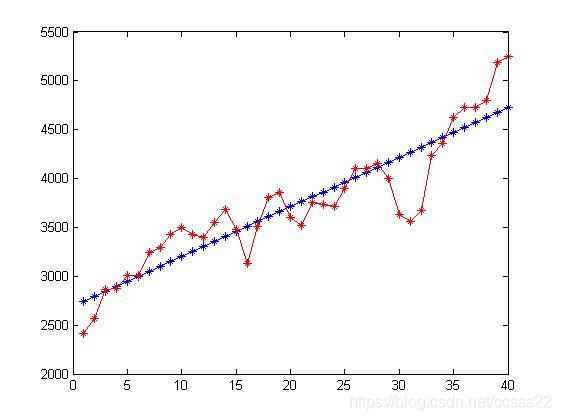
通過擬合得到人數和像素數的關系曲線為:
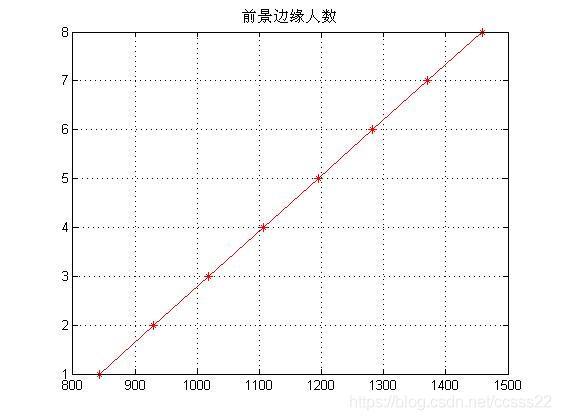
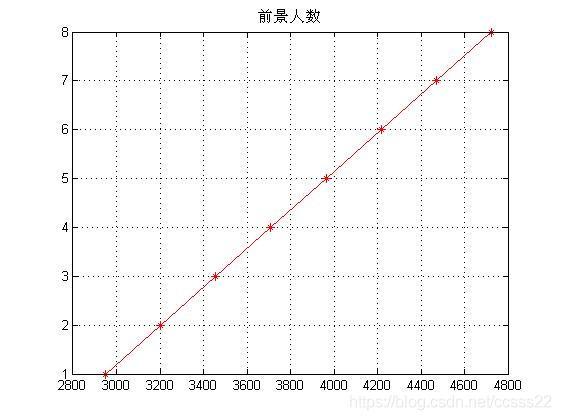
即在低密度的條件下,像素數和人數的關系曲線,
·高密度人群代碼說明中文檔案
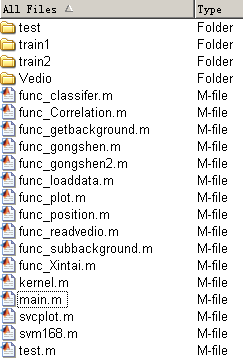
里面的代碼的說明如下所示:
Test:測驗視屏中提取的視屏特征引數保存的檔案夾;
Train1:高密度訓練視屏中提取的視屏特征引數保存的檔案夾;
Train2:中密度訓練視屏中提取的視屏特征引數保存的檔案夾;
Vedio:保存視屏的檔案;
|
| 分類函式 |
| 灰度共生矩陣的相關性引數 | |
| 求背景 | |
| 求灰度共生矩陣函式 | |
| 灰度共生矩陣子函式 | |
| 加載資料 | |
| 畫圖函式 | |
| 計算CDM最長0點位置函式 | |
| 讀取視屏函式 | |
| 背景相減函式 | |
| 形態學處理還輸 | |
| SVM分類核函式 | |
| 系統運行主函式 | |
| SVM分類畫圖 | |
| SVM子函式 | |
| 測驗檔案,無用,, |
系統包括如下幾個部分:



其中前面三個部分均為特征提取函式,這里以高密度特征提取為例子:

前面的四個步驟都是相同的,
然后是步驟五,灰度共生矩陣特征引數的提取,
其步驟為:
其主函式為:
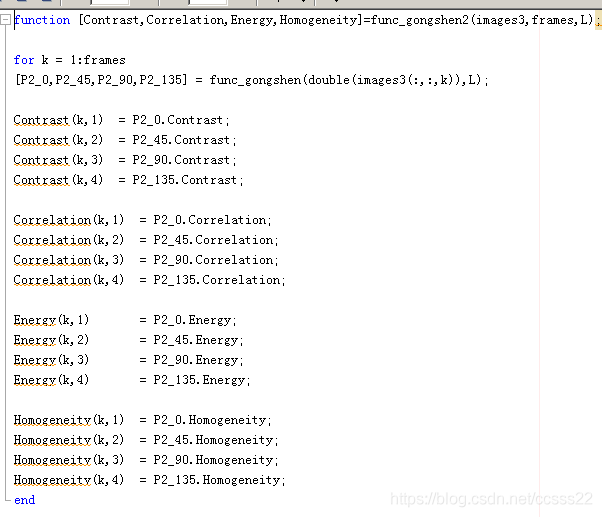
其中的主要函式為


這里主要利用到了MATLAB的內置函式graycomatrix進行求解灰度共生矩陣;
然后利用函式graycoprops求其每個角度的特征引數
然后通過如下的代碼求的0,45,90,135四個角度的共生矩陣的各個特征引數;
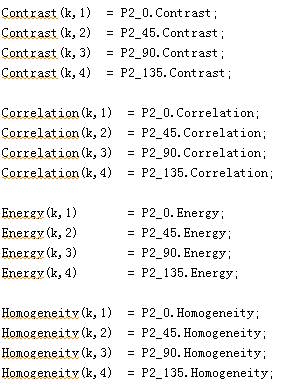

這個代碼段就是將灰度共生矩陣引數保存到相應的檔案中,
然后后幾個視屏的灰度共生矩陣的特征引數的提取也是同樣的步驟進行,

注意,在計算特征引數的時候,有四種情況,就是分別計算了灰度等級為8,16,32,64四種情況下的特征引數,
這里首先選擇灰度等級,8,16,32,64等等,
然后進行資料加載,
然后這里的high_low就是進行識別測驗資料是高密度還是中密度的選中函式,
最后兩個就是通過0度和90度的特征引數進行分類,
測驗步驟:
假設不知道測驗的視頻的人口密度情況;
然后首先輸入high_low = 1;
然后運行代碼:
得到如下的運行結果:
這個說明輸入的測驗視頻和低密度的特征引數是一類的,則說明測驗引數是低密度視頻
加入認為輸入的視頻是高密度,那么high_low = -1;然后運行代碼;
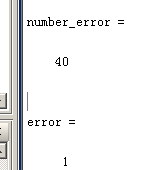
這是錯誤的,這說明輸入的不是高密度,是低密度,
通過這樣對比,完成一組視頻的測驗,判斷輸入的視頻是中密度還是高密度,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/155630.html
標籤:AI
上一篇:新手報道,只求三個贊
下一篇:音視頻開發技術的進階路線